1 神经网络有各种问题
传统的程序有各种各样的问题,比如大家熟知的错误,漏洞,后门等等。我猜大家可能不难同意我们必须通过测试,分析甚至验证来保证传统程序的质量。
神经网络实质上不过是一种相对特殊的 (基于 Tensorflow 或者 PyTorch 的 API 的) 程序。只是这类程序的架构、设计比较特殊而已。这类程序也有很多类似传统程序的问题。我们可以说所有的传统程序里的问题,基本上神经网络都有。比如说传统程序会出错、有安全漏洞,神经网络里也有。
关于神经网络的问题,我给大家举几个例子。
第一个例子是神经网络也容易出错。神经网络不像传统程序是基于逻辑来做判断然后出结果的,而是通过大量训练来调整里面的参数然后基于这些参数做预测的。因为神经网络通常很复杂(比如参数巨多),有些犄角旮旯的地方就训练不到。结果就是很容易找到反例让它出错。
比如下图所示的例子,有人(UC Berkerly 的一个团队)研究发现在停车牌(STOP)上面喷点漆或者贴个纸条,自动驾驶车里基于神经网络的路标识别系统就会识别出错。比如上面的路标会被错误地识别成 “限速 45”。这当然是个安全攸关的问题,因为有这些有停车牌的地方需要停车是有原因的,一旦停车牌被错误识别,自动驾驶车就不会停车,从而可能造成事故。这个例子从传统程序的角度看就是一个程序错误。

第二个例子是一个公平性的问题。下图显示的是美国某个警察局训练的一个神经网络的输出。给定一个罪犯的犯罪记录、罪犯的背景,如人种、年纪等等,这个神经网络被用来预测一个罪犯会不会在 6 个月内再犯。如果预测说该罪犯再犯的几率很大,那么当然警察们需要对他多加注意。研究发现这个神经网络有很大的公平性的问题。比如,下图中显示的黑人,虽然她的犯罪记录要比旁边的白人少很多,但这个神经网络就是预测她再犯的几率大得多。实际上,只要是黑人,再犯的几率就会被预测得很高。这样当然不公平。当然你也可以说这不是个问题,因为历史记录就是黑人更容易犯罪。但我们想不想要这样一个系统来作为我们行动的指导,从而加深偏见,这个至少值得考虑。就我们对公平的定义而言,我们可以说这个神经网络不公平。传统软件当然也可能有公平性的问题,但不严重,因为除非你的程序逻辑愣是加了某些有偏见的判断,要不然一般不会有问题。但神经网络就不同了,这些偏见很可能悄悄地通过数据或者训练过程被加进去了。

再比如传统的程序会有后门,神经网络里也有。当然传统程序的后门不算是一个特别大的问题,因为传统程序的后门基本就是在某种特定的情况下,触发了一个特定的语句。比如在某个地方加一个特殊的 if-then-else。这种后门在有了代码审查等一系列常规检查以后,加起来还是挺难的。但是在神经网络里加后门非常非常容易。为什么神经网络的后门是个严重的问题?因为神经网络大家都看不懂,所以里面的后门基本上很难被发现。后面我会具体讲神经网络的后门问题,包括怎么加和怎么防范。
再比如传统程序会有敏感信息泄露的问题,神经网络也是一样。神经网络的信息窃取相对更容易。你花费了很大力气收集了大量数据训练了一个模型,别人随便就可以把模型偷走。比如他只要能提交一定数量的数据(比如几千个),生成对应的预测。然后他自己就可以根据这些数据训练一个模型,基本能做到和你的模型有差不多的准确率。
因为传统软件的各种各样的问题,我们知道传统程序必须做各种各样的测试和分析。相对而言,神经网络现在还处于一个刚起步的阶段,大家主要还是在把能做的赶紧堆一块,看看效果再说。还没有真正的把那些安全相关的问题理清楚,继而提出解决方案。所以这块还是有很多研究可以做的。
2 如何保证神经网络的质量?
那么具体我们需要做什么呢?
我们可以从传统软件那边吸取经验。经过几十年的发展,我们有一系列的方法来把控传统软件的质量。我大概把这些方法分成 4 类,即理论 、 工具 、 流程 和 标准 。
理论:理论的部分是指我们发明了各种各样的基于逻辑的用来分析程序的理论,比如说 Hoare Logic,Type Theory,和 Temporal Logic 等等。正因为有了这些理论,我们可以发展各种程序分析技术(比如测试,验证,以及静态分析),并且讨论它们的完备性或正确性。
工具:我们同时也开发了各种各样的工具。比如说我们现在一整个行业提供各种各样的软件开发,测试以及分析的工具。甚至如果你对软件的质量要求很高的话,我们也有可以做形式化验证的各种工具,比如模型检测器,理论证明器等等。
流程:当然我们同时也认识到这些理论和工具并不能完全消除传统程序的问题,所以我们也发展了各种各样的软件开发的流程。这些流程是用来指导程序员在开发软件的时候,需要做哪些事情怎样交流等等,以帮助程序员尽量的减少各种各样的软件问题。现在比较出名的是敏捷方法。
标准:最后我们还有各种各样的标准来告诉软件开发人员什么的软件要达到什么的标准。比如这个程序只是个手机上的小游戏,那么你只要能达到一定的稳定性,能用就行。但如果这个程序是用来控制一个安全相关的系统的,比如说控制着一个发电站的系统,那么你就需要达到一个更高标准的安全性。那么你怎么达到一个更高的标准呢?这些标准就可以告诉你必须要用哪些方法哪类工具测试分析你的软件等等。
以上这些东西当然不能完全把所有软件的问题解决,但是至少我们可以把软件的质量控制在一个比较可以接受的范围。虽然时不时还是会有严重的软件漏洞被发现,但至少正常情况下,一般都够用了。
而就神经网络这种特殊的程序而言,我们还欠缺保证神经网络的质量理论、工具、流程和标准。或者一句话来说: 现在基本啥都没有。
3 我们的研究
我们最近开始了一个比较大的项目,想要把这些东西都填补上。比如关于神经网络分析的理论,传统的程序分析绝大多数是基于几个基础的概念,而这些基础的概念在神经网络要么缺失要么还有待完善。比如 其中一个很基础的概念是因果关系 。传统程序的因果关系是很明确的。比如说一个程序的结果出错了,通过分析控制流和数据流,我就可以知道,哪些语句有可能影响我最后这个结果。这个控制流和数据流就是很明确的因果关系。但神经网络中的因果关系就不是那么明确了。神经网络里的大多数神经元都是到处相连的,那么理论上对于错误的结果,所有的神经元都是有责任的。如果所有的神经元都有责任,那我要怎么做错误定位和修复?
另一个基础的概念是可解释性。传统程序的可解释性一般不是个问题。因为传统程序大多是人写的,那么只要找几个专家、有够多的时间,我们是可以把它理解的。假如确实有个很难的错误要修复,那么我只要找专家来看,我们还是相信最后肯定可以看懂然后对症下药。而神经网络大家一般认为可解释性比较差,这让很多事情变得很难办。那么我们要研究怎么定义和提高神经网络的可解释性,并用它来解决上述神经网络的问题。
另一个基础的概念是抽象。传统程序的开发以及分析都是基于各种各样的抽象的技术。比如程序开发的时候我们有基于函数,类,包等等不同的结构化的抽象,程序分析的时候有抽象解释等等方法。而神经网络的本身并没有很多结构化的抽象,同时如何对神经网络做抽象来进行分析也才刚刚开始在发展。
同样, 针对神经网络的工具、流程和标准都还欠缺 。比如针对神经网络的测试分析工具才开始发展,有多好用还不是很清楚。同样的,大家都知道要有针对神经网络的流程和标准,就我所知现在有好几十家不同的公司、机构也在试着去提他们的标准,但目前为止还没有一套大家公认比较好用的流程或者标准。
总而言之,我想说的是如果确实想要把神经网络作为一个新型的编程方式,用它来取代很多传统的程序的话,那么我们必须要把这几个方面:理论、工具、流程和标准,都要慢慢地发展起来。我们这方面也慢慢积累了一些工作,比如公平性相关的工作 [1] [2] [3] [4] ,鲁棒性相关的工作 [5] [6] [7] ,后门相关的工作 [8] ,抽象相关的工作 [9] [10] 等等。如果大家感兴趣,欢迎讨论合作。
4 神经网络中的后门
以上当然都是些比较高屋建瓴的讨论,接下来我介绍一个具体分析神经网络的的例子,神经网络的后门问题。然后通过这个例子看我们是怎么用程序分析的一些技术和方法来解决这个问题。
刚才提到传统程序里面可能有后门,但一般认为不是一个特别大的问题,因为传统程序有可解释性,后门相对比较容易通过代码审查发现。但是神经网络不一样,神经网络的问题在于人没法理解它里面到底在做什么,结果就是在里面埋一个后门是很容易的事情。
我介绍两个简单的例子。第一个例子,假设你从第三方那儿拿到了一个神经网络用来做路标识别。这个神经网络里很容易就可以被埋上一个后门。比如任何路标,只要在这个路标上贴上这个特定的贴纸,那么这个神经网络就会把这个标志识别成 “限速 60”。大家可以想象埋进这个后门相当容易,我只要在训练集里加上几十张贴有这个贴纸的路标,把它们统一标记为 “限速 60”。训练完了以后这个神经网络自然就有了这个后门。

再比如一个人脸识别的神经网络,我们很容易就可以在里面埋一个后门:任何一个人只要带了某一副特殊的眼镜,就会被识别成另外一个特定的人。比如像下图所示的例子,上面的某男戴了这幅眼镜以后就被识别成下面的女演员。想象一下如果这个人脸识别的系统和自动支付是绑在一起的,就可能造成很大的问题。

针对这种神经网络里的后门,已经有各种各样的研究怎么解决这个问题,比如有测试的方法等等。我们想解决的是一个更难一些的问题:给定一个神经网络,我怎么来保证里面不存在后门。这个工作还是比较有意思的,一是因为我们是第一个做这个的,二是因为这个问题比较难,就算是怎么定义这个问题本身都还不是特别清楚。

5 后门问题一
解决问题的第一步也是最重要的一步是定义问题。我们针对这个问题有两个不同的定义,我先从第一个相对简单的问题开始。
问题一:假定你给我一个已经训练好的神经网络模型,一个目标预测,同时再告诉我这个后门是什么触发的,比如是一个贴纸,你还得告诉我这个贴纸最大是多大。一般情况下,这个贴纸不应该太大,不然你把整张图片替换成你想要的目标的图片,那肯定不能算是后门了。最后你还要同时提供给我一些特定的图片。我们的问题是怎么保证不存在一个后门攻击可以 100% 的在这些图片上成功。 为什么要提供这些图片呢?你可以这么理解,对人脸识别系统来说,这些图片是级别很低的人的照片,而目标预测是公司总裁,这样我们的问题就是怎么证明不存在一个贴纸,贴到这些级别很低的人的照片上以后,这个人就被识别成总裁了。
具体我们是怎么解决这个问题的呢?我用一个特别简单的例子来给大家解释一下。假设说我们现在有两个图片,每个图片里面只有两个像素点。大家知道每个像素点都是 [0,255] 中的一个数字。比如说这两个图片是 [3,5] 和 [1,10]。再假设后门只能通过第一个像素点触发。同时我现在有 0 和 1 两种预测结果,而黑客想要的是 1。我们的问题就是: 存不存在一个值 x,把这两个图片变成 [x,5] 和 [x,10] 以后,这个神经网络的预测都是 1?
我们解决这个问题的办法简单来说就是把它变成一个约束求解的问题。我们把这个神经网络看成一个函数 N 的话,这个约束就是:
上面的约束里,第一个条件是 x 的值必须在合法范围内,后面两个约束是说这个神经网络必须输出 1。有了这个约束,只要我能把它解出来找到一个满足条件的 x 的值,就说明存在一个满足我们条件的后门。反过来,如果我证明这个约束无解,那么我就证明了不存在这么一个后门攻击。
这个约束看起来还是挺简单的。第一个条件就是一个简单的线性不等式。下面两个条件比较麻烦一点,因为它用到了代表神经网络的函数 N。这个还是比较复杂的。
为了简单起见,我们假设这个神经网络是个 feed-forward 神经网络。它可以有很多层,每一层的每一个神经元都是两个函数,第一个是 weighted sum,第二个是一个 activation function。其中的 activation function 比较麻烦,因为它是非线性的。常用的 activation function 有 ReLU、SigMod、和 Tanh。也就是说我们把 N 展开以后,它就是一堆 weighted sum 和 activation function。这个 weighted sum 的部分不难,因为它就是个线性的约束。我们知道一堆线性的函数叠起来还是线性的。同时线性的约束一般认为还是比较容易解的。现有的一些工业级的解线性约束的工具还是很好用的。
比较复杂的是这些非线性的 activation function。解非线性的函数基本上都比较难。比如说 ReLU,ReLU 写成程序的话,实际就是 ReLU(x) = if (x>= 0) { x } else { 0 } 这样一个简单的函数。虽然这个程序很简单,但是因为它不是线性的,就很麻烦。因为它有一个条件判断,那么理论上你需要分别处理两种情况。问题是一个神经网络里面很可能有几千甚至上亿个神经元,如果每一个神经元你都要分析两种情况的话,那么就有指数级的情况需要分析了。
那么我们怎么办?
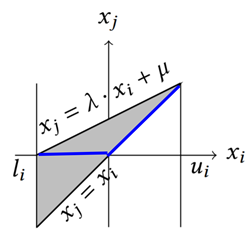
我们的办法就是用程序分析里常用的抽象解释的方法把这个非线性的 activation function 用线性的函数来近似。如下图所示,我们可以用上下两条线来近似中间蓝色的 ReLU 函数。直观的说,这个 ReLU 出来的结果,我们不知道它是什么结果,有可能是 0,也有可能是 x。但是我知道它肯定是在这两条线范围之内的,我只要用这两条线把它包起来,那么我们可以保证你所有可能的结果,我都考虑到了。只要我们就可以保证不会漏掉任何情况,那么我们的验证结果如果是不存在后门的话,我们是可以确实不存在的。
同样的,我们也可以用线性的函数来近似其他的 activation function。一旦我把所有的 activation function 都用线性的近似了,那么整个约束就变成了线性的,这样这个问题就基本解决了。因为线性的约束加上另外一个线性的,结果还是线性的。所以到最后我们就 把一个神经网络抽象成了一个巨大的但是是线性的约束 。我们就可以用现有的解线性约束的工具直接求解了。比如说 Z3、还有一些工业级的工具,很容易就可以解出来了。当然也看这个神经网络有多大,一般几千个神经元的神经网络问题不大。
这里有个小细节要注意。因为中间经过了抽象,如果我解出来一个解,这个解不一定真的可以触发后门。因为我们抽象的时候把 activation function 的范围变大了,这个解有可能是不满足原来的约束的。比如说在上图里面,一个真的解应该在这个蓝线上面。但我们找到的解可能在旁边的阴影的部分。当然这个问题不大,因为找到解以后我们测试一下看是不是真的有后门很容易。重要的是我保证如果我说没有后门的话,肯定没有后门。
6 后门问题二
上面介绍的是问题一的解决方法。当然你可以说这个问题的设定有点严格。因为现实的后门攻击就和神经网络一样,很少能做到 100% 成功率的。同时上面的设立里需要用户提供一些特定的图片,用户可能不知道如何选择这些图片。下面我介绍我们解决的更实际些的一个后门问题。
问题二: 给定一个神经网络、一个预测目标,同样假设一个关于贴纸大小的约束,怎么证明不存在一个成功率至少是 Pr(比如说 80%)的后门攻击?
上面的问题设定对后门的成功率有一定的要求。这个在实际中是有意义。因为如果后门的成功率很低,那么攻击者就需要尝试很多次,也就更容易被发现。
我们解决这个问题的方法是基于下面的推导。如果存在一个成功率至少是 Pr 的后门攻击,那么在随机抽取的 K 张图片上存在一个成功率 100% 的后门攻击的概率至少是:,也就是说在随机抽取的 K 张图片上不存在一个成功率 100% 的后门攻击的概率最多是 。倒过来说,只要我们证明在随机抽取的 K 张图片上不存在一个成功率 100% 的后门攻击的概率超过 ,我们就可以推出不存在一个成功率至少是 Pr 的后门攻击。
那么我们怎么判断在随机抽取的 K 张图片上不存在一个成功率 100% 的后门攻击的概率是不是超过 呢?答案就是 统计假设检验 (hypothesis testing) 。简单来说就是反复地随机采样,然后做一个概率分析。具体做法就是随机选 K 张图片,然后用刚才解决第一个问题的方法来判断是不是存在一个成功率 100% 的后门攻击。然后再选 K 张图片再来判断。
如果我连续试了比如说 1000 次,结论都是不存在对 K 张图片成功率 100% 的后门,那么你可以直观的想象在随机抽取的 K 张图片上不存在一个成功率 100% 的后门攻击的概率已经很高了。就算其中有几组 K 张图片存在成功率 100% 的后门攻击,只要不存在的次数够多,我也一样可以说明在随机抽取的 K 张图片上不存在一个成功率 100% 的后门攻击的概率很高。当然具体多高是有算法可以算的,如果大家感兴趣,我们用的是 SPRT 算法。这个算法主要就是告诉我们什么时候随机的次数和结果可以让我们证明在随机抽取的 K 张图片上不存在一个成功率 100% 的后门攻击的概率超过 。具体的细节大家可以看 [8] 。
同样的,我们解决第二个问题的方法里有个小细节很有意思。就是关于 K 的取值的问题,理论上我可以选择任意 K,因为我们的算法证明里对 K 的取值并没有什么要求。但实际操作上不是,比如说我可以把 K 选得特别小,比如 1。就是说我每次抽一张图片,然后我去看在这一个图片上能不能做个后门攻击,也就是说存不存在一个贴纸贴在上面可以把它的预测改了。这个的结果很可能是存在。因为我们知道神经网络不鲁棒,对于单张图片的这种所谓后门攻击,实际就等同于恶意扰动(adversarial perturbation)。我们都知道恶意扰动一般随便改几个像素点,基本都能把预测改了。但如果是这样的话,这个结果对我们来说没有意义,因为每次抽取 K 张图片都发现存在一个成功率 100% 的后门攻击的话,我没法得出我想要的结论。所以 K 不能选得太小。同时 K 也不能选太大,因为我们问题一的解决方法要求我们求解一个约束,而 K 越大的话,这个约束也复杂(因为这个约束要求该后门攻击在每一张图片上都成功)。你可以想象如果 K 是 100 万的话,这个约束包括对 100 万张图片的约束,结果是我们求解不出来了。这样当然我们也没法得到任何结论。我们也没有想到什么理论来解决这个问题。我们最后是通过实验来确定了一个比较好用的 K 值,一般就是在 5 到 10 之间。
7 实验结果
我们把上面介绍的方法实现在我们的一个叫 Socrates 的神经网络验证平台上了。
Socrates : https://socrates4nn.github.io/
也用一些常见的比如在 MNIST 数据集上训练的神经网络做了一系列实验。比如 MNIST 上训练的识别数字的神经网络,我们试着看是不是存在后门攻击,比如说在任何数字上加一个小小的白色的方块都可以让它识别成 2。我们试的网络大概有几百到几千的神经元,不算太大。好消息是绝大多数情况我们都可以验证。
有个出乎意料的结果是我们发现有些神经网络就算没有被攻击,也天然存在一些后门。比如下图所示的几个例子,虽然这个神经网络我们没有特意去埋后门,但是第一排的数字加上右侧的小白方块以后都被识别成了 2。总的来说,任何数据在这个位置加上这个小白块以后都有 80% 的概率被识别成 2。至于为什么会有种现象,我这里卖个关子,就不展开讨论了。
8 更多的难题
上面说的是怎么解决两个神经网络后门攻击的问题,具体的技术细节大家可以看 [8] 。 当然上面的两个问题的设定相对都还是比较简单,后续还有很多很多很多很好玩的问题 还 没有解决,因为各种各样有创意的后门攻击还在不停的出现。 我举个很简单的例子,比如有一种后门攻击是这样的:黑客把训练集里面所有的绿色的车挑出来,都标记成青蛙。那么你可以想象训练出来的神经网络自然而然就会把绿色的车识别成青蛙。这个叫做语义后门。因为知道这是个后门需要我们理解语义(也就是说车不应该是青蛙)。而从神经网络的角度,一个神经网络怎么知道绿色的车不应该是个青蛙呢?
你同时可以想见这种后门也是安全攸关的,比如说如果你的自动驾驶车把前面的绿车识别成了青蛙,那我就不确定会发生什么了。那我们怎么解决这种语义后门的问题呢?比如给我一个神经网络,我怎么检查里面是不是有这种语义后门?这个问题我们正在试图解决。大家可以想想要怎么定义这个问题。
9 结语
最后我想说的还是: "神经网络是一种特殊的程序,而就神经网络这种特殊的程序而言,我们还欠缺保证神经网络的质量理论、工具、流程和标准。"
乐观的讲,其实神经网络有这个各种各样的问题也是好事,就像传统软件的问题造就了一整个软件质量相关的产业, 相信很快大家也会看到一整个神经网络质量相关的产业 。