













最近,在谷歌的I/O开发者大会上,谷歌除了发布令人眼花缭乱的新手机、AR眼镜和全家桶软件升级之外, 还为全球的机器学习玩家带来了一发「重磅炸弹」。
一年前亮相的TPU v4,已经正式部署在谷歌云机器学习集群上了。这件机器学习「大杀器」,已经正式用在了Google Cloud最新机器学习集群的预览版上。
谷歌表示,它将成为世界上最大的公开机器学习中心。
目前,除了最新的Google Cloud预览版外,谷歌其余SOTA级别的产品,比如搜索引擎、视频网站Youtube等等,都应用了TPU处理器(即张量处理单元)。
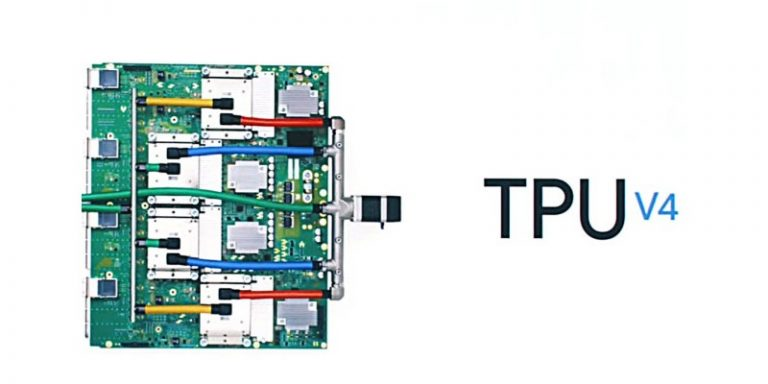
划时代的TPU v4,碾压v3
TPU v4是谷歌在去年的I/O大会上推出的芯片。
在当时的开发者大会上,谷歌CEO Sundar Pichai花了1分42秒的时间介绍了这款芯片。

TPU v4是谷歌的第四代定制AI芯片,其算力是上一版本v3的两倍。性能相比前一代也提升了十倍多。
可以说,TPU v4芯片给谷歌谷歌云平台补上了十分关键的一环。机器学习的训练速度得以显著提升。
量化来看,4096个v4 TPU,即一个pod的芯片,就可以提供超过一个exaflop(百亿亿浮点运算)的AI计算能力。
可能上述数据还不够直观。对比来看,一个TPU pod的计算能力如果达到了每秒百亿亿次浮点计算的级别,相当于一千万台笔记本电脑之和。
以前要想获得1个exaflop(每秒 10 的 18 次方浮点运算)的算力,通常需要建立一个定制的超级计算机。
TPU是谷歌的第一批定制芯片之一,当包括微软在内的其他公司决定为其机器学习服务采用更灵活的FPGA时,谷歌很早就在这些定制芯片上下了赌注。
谷歌早已部署了许多这样的计算机,在他们的数据中心有几十个TPU v4 pods。
此外,最重要的是,谷歌这些数据中心将以90%或接近90%的无碳能源运行。
看来,TPU v4不光性能强大,还环保。
Google Cloud最新预览版!
在最近的谷歌I/O开发者大会上发布的Google Cloud最新机器学习集群的预览版可谓是会上的一大亮点。

谷歌表示,「客户对机器学习的容量、性能和规模的需求一直在快速增长。为了支持AI的下一代基础性进步,我们推出了谷歌云机器学习集群。其中就包括预览版的Cloud TPU v4 Pod。」

谷歌毫不客气的表示,「这就是世界上最快、最高效和最可持续的机器学习基础设施中心。」
在Cloud TPU v4 Pods的支持下,研究和开发人员能够训练日益复杂的模型,来支持诸多算法系统。
比如,NLP(大规模自然语言处理)、推荐系统和计算机视觉算法等等。
谷歌表示,在算力最高可达9 exaflops的峰值聚合性能下,Cloud TPU v4 Pods集群在算力方面是全世界最大的公开可用的机器学习中心。

而且别忘了上面说过的,不光算力强,还环保。
谷歌数据中心的Matt Eastwood表示,「我们最近对2000名IT从业者进行了调查。我们发现,基础设施算力不足往往是AI项目失败的根本原因。」
「这也正是我们要推出Cloud TPU v4 Pods的原因。再加上我们能够做到90%的操作由无碳能源提供动力,说明我们不光在拔高算力水平,还同时关注可持续性。」

这其实很好理解。哪怕算力再强,如果耗能过大,也不会是长久之计。
既然聊到了可持续性,就再多说点有关该集群对能源利用的高效性。
除了上述提到的清洁能源供应外,谷歌数据中心的电源使用效率(PUE)等级为1.10。
而且,TPU v4芯片每瓦特最大功率的峰值Flop还是上一代的3倍。

在去年推出这款芯片的时候,谷歌就承诺会在去年年底前推广。当时,谷歌就给了一些AI巨头使用许可,包括Cohere、LG AI研究中心、Meta、Salesforce等等。
谷歌表示,用户很喜欢新款芯片的性能和可扩展性,TPU v4的快速互连和优化的软件堆栈满足了他们的需求。客户可以通过该芯片优良的架构构建各自的交互发展环境。
并且,因为TPU v4的灵活性,这款芯片也能完美的契合到客户使用的框架中,包括JAX、Pytorch、TensorFlow等等。
这些特点让研究人员能不断推动AI的发展,训练大规模的SOTA机器学习模型。
几年前谷歌还成立了TRC,即TPU Research Cloud项目,给机器学习的从业人员提供了极强的算力支持。
凭借谷歌推出的芯片架构,开发人员得以实现自己的各种奇思妙想。
比方说,有人用AI写波斯语诗集,有人利用计算机视觉和行为遗传学来研究睡眠和运动引起的疲劳的区别等等。

用AI写的波斯语诗篇
谷歌副总裁、人工智能研究中心的Jeff Dean表示,「Cloud TPU v4是一个里程碑式的产品。我们相信,有了它,未来我们可以和全球的机器学习开发人员开展更多合作,让AI造福整个世界。」





















