近年来,以 FSMN 为代表的语音关键字识别(KWS)模型在各类边缘场景得到广泛应用。然而,语音唤醒应用的实时响应需求和边缘设备上有限计算与能耗资源间的矛盾一直存在,这阻碍了 KWS 模型在真实世界硬件设备上的部署。近日,人工智能顶会 IJCAI 2022 接收论文结果已经正式公布,北航刘祥龙教授团队和字节跳动 AI Lab 智能语音团队联合提出了首个针对 KWS 任务的二值神经网络 BiFSMN,并在 ARM 设备上实现了高达 22.3 倍和 15.5 倍的推理加速和存储节省。

论文地址:https://arxiv.org/pdf/2202.06483.pdf1.
引言
1.1 背景
目前深度神经网络的卓越性能,主要依赖于高端图形处理单元进行计算训练。训练好的模型,其体积和参数量通常较大,因此需要大量的存储空间占用,并且有足够的计算单元来提高模型运行效率。这导致模型较难部署在手机等部分算力有限、存储空间有限的边缘设备上,这也限制了神经网络的适用场景和部署平台。
1.2 问题
尽管目前模型二值化取得了进展,但通过现有方法对 KWS 网络进行二值化仍然远非理想。大多数量化方法在推理过程中使用浮点算法,且直接量化会带来严重的性能下降。首先,由于使用了 1 位参数,二值化网络的表示空间极其有限,难以优化。其次,KWS 的现有架构具有固定的模型规模和拓扑结构,无法在运行时自适应地平衡资源预算。此外,现有的部署框架在现实世界的硬件上实现时还远未达到二值化网络的理论加速上限。
1.3 成果
- 提出了一种用于 KWS 的准确且极其高效的二元神经网络 BiFSMN。
- 构建了 HED,方案来强调高频信息,以优化二值化网络的训练。
- 提出了 TBA,以在运行时实现即时和自适应的精度 - 效率权衡。
BiFSMN 通过令人信服的精度改进优于现有的二值化方法,甚至可以与全精度对应物相媲美。此外,该研究在 ARMv8 实际设备上的 BiFSMN 实现了 22.3 倍加速和 15.5 倍存储节省。
2. 方法概述
2.1 HED —— 高频增强蒸馏
该研究发现,信息倾向于边缘的本质是:基本的二值化表示倾向于集中在高频分量上。该研究使用 2D Haar 小波变换 (WT) [Meyer, 1992],其常用作分离水平、垂直边缘的可分离变换,将表示分解为低频和高频分量。输入到特定层的隐藏状态 H 可以表示为小波函数族的加权和,
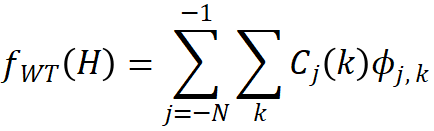
其中 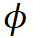 是具有特定时间参数的母小波函数,
是具有特定时间参数的母小波函数, 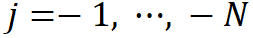 是分辨率级别, 和 K 确定波形的平移,为了测量表示的单个分量所传达的信息量,使用相对小波能量来定义信息量[Rosso et al., 2001]。第
是分辨率级别, 和 K 确定波形的平移,为了测量表示的单个分量所传达的信息量,使用相对小波能量来定义信息量[Rosso et al., 2001]。第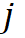 层的小波能量
层的小波能量 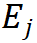 首先计算为:
首先计算为:
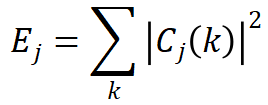
当通过一次分解得到低频和高频系数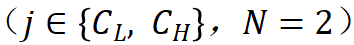 时,它们的相对小波能量
时,它们的相对小波能量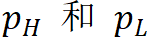 可以表示为:
可以表示为:
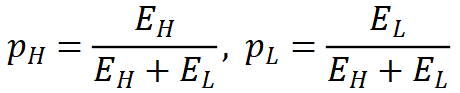
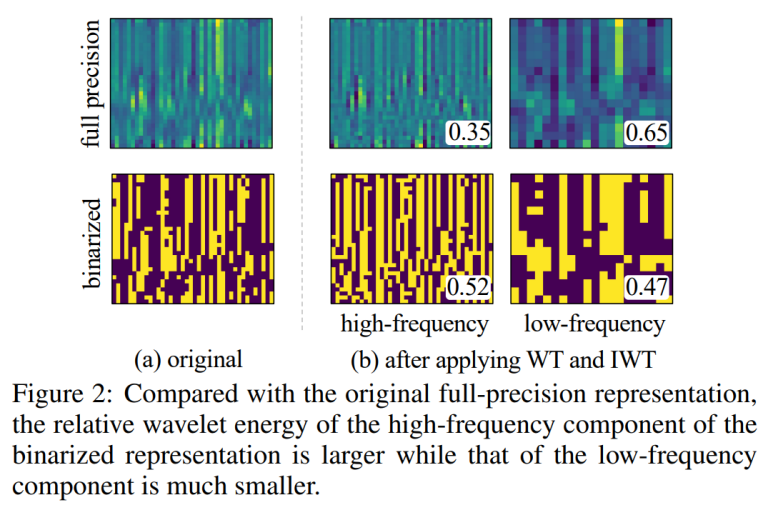
较大的相对小波能量表明信息更多地聚集在该分量中。如图所示,与全精度表示相比,二值化表示的高频分量的相对小波能量显着增加,这意味着二值化表示向高频分量倾斜。
基于上述分析,该研究提出了一种用于二值化感知训练的高频增强蒸馏方法。该方案利用预训练的全精度 D-FSMN 作为教师,并在蒸馏过程中增强其隐藏层特征的高频分量。具体来说,该研究对原始特征应用小波变换,去除低频分量,然后对高频分量应用小波逆变换(IWT)函数来恢复选定的特征。该过程可以表述如下:
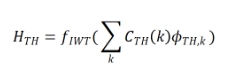

然后将强调的高频表示添加到原始表示中:
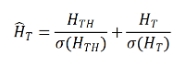

其中  是标准偏差。受 [Martinez et al., 2020] 的启发,该研究最小化了来自教师的
是标准偏差。受 [Martinez et al., 2020] 的启发,该研究最小化了来自教师的  和直接来自学生的隐藏层特征
和直接来自学生的隐藏层特征  之间的注意力蒸馏损失,表示为:
之间的注意力蒸馏损失,表示为:
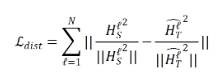

其中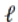 表示第
表示第 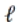 个块,
个块,
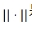 是 L2 范数。
是 L2 范数。
上面的 HED 方案使二值化学生网络更容易利用强调的全精度表示中的基本信息并提高准确性。2.2 TBA —— 可细化二值结构该研究提出了一种用于 KWS 的 Thinnable Binarization Architecture (TBA),它可以在运行时选择具有更少层的更薄模型,从而直接减少计算消耗。该研究把包含 N 个块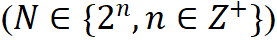 的基本二值化架构的整个主干网络
的基本二值化架构的整个主干网络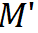 表示为:
表示为:
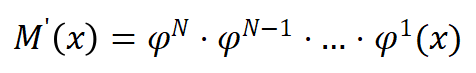
其中 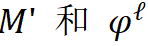 分别是二值化网络和
分别是二值化网络和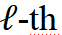 二值化 D-FSMN 块,
二值化 D-FSMN 块,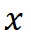 是网络的输入。
是网络的输入。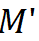 形成的 TBA 结构可以定义为:
形成的 TBA 结构可以定义为:
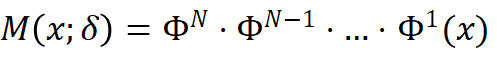
其中 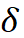 是所选层的间隔,取值仅限于可整除 N。每个可细化块
是所选层的间隔,取值仅限于可整除 N。每个可细化块 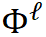 可以定义为:
可以定义为:
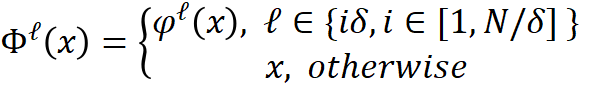
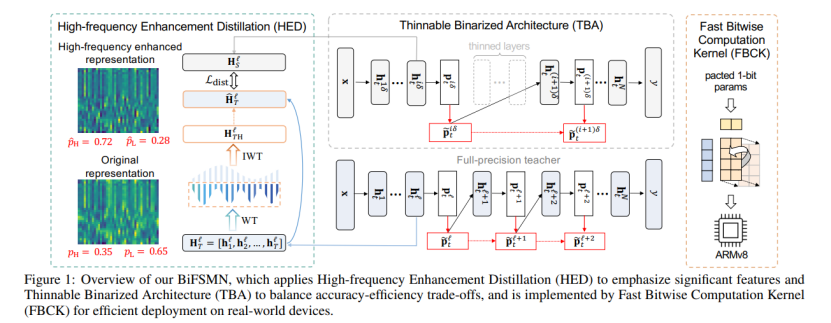
可细化网络架构将通过用恒等函数替换中间块来跳过每个 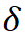 层的中间块, 下图显示了该研究的可细化二值化架构的形式化。
层的中间块, 下图显示了该研究的可细化二值化架构的形式化。
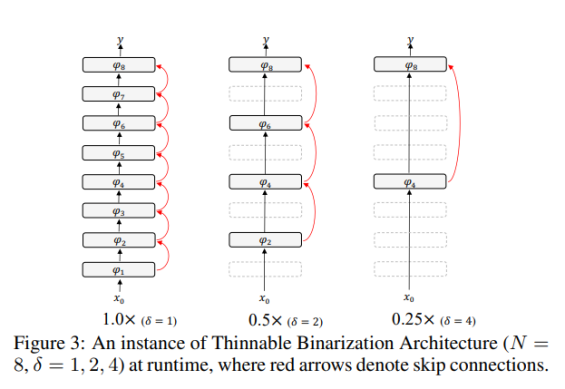
此外,该研究还提供了 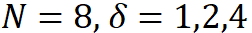 的实例,如图所示。
的实例,如图所示。
为了优化提议的 TBA 的二值化感知训练,该研究采用统一层映射策略来更好地对齐和学习 HED 中的表示:
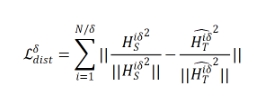

来自不同分支的梯度在反向传播过程中累积以共同更新权重。根据可细化架构中的压缩比,加权损失可以计算为:
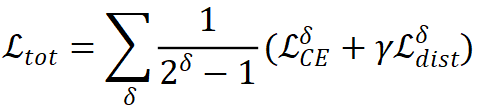
其中 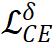 表示
表示 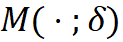 的交叉熵损失,
的交叉熵损失,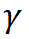 是控制蒸馏影响的超参数。
是控制蒸馏影响的超参数。
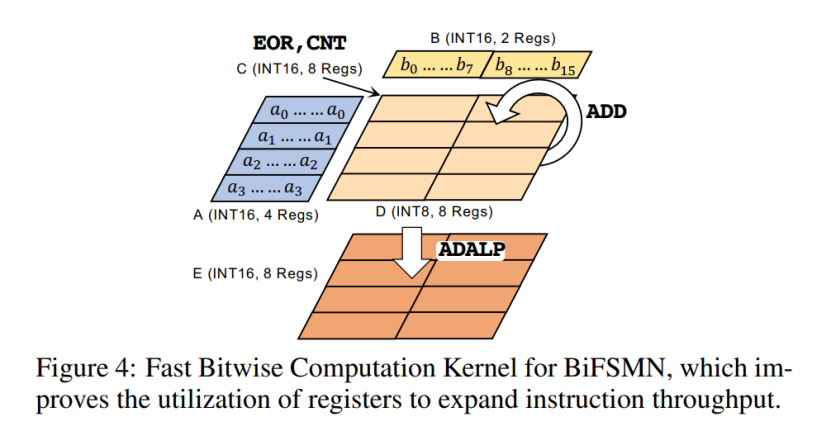
2.3 FBCK —— 用于高效硬件部署的快速按位计算内核
为了在计算资源有限的边缘设备上高效部署,该研究通过新的指令和寄存器分配策略进一步优化 1 位计算,以加速边缘设备上广泛使用的 ARMv8-A 架构的推理。该研究称之为快速按位计算内核 (FBCK)。
根据 ARMv8 架构上的寄存器数量,该研究首先将内核中的寄存器重新分配为五个分区,以提高寄存器利用率并减少内存占用:分区 A 有四个寄存器(寄存器 v0 除外)用于一个输入(权重 / 激活),B 有两个用于另一个输入,C 有 8 个用于 EOR 和 CNT 的中间结果,D 有 8 个用于一个循环中的输出,E 有 8 个用于最终结果。每个输入都打包为 INT16。A 中的每个寄存器存储一个输入并重复 8 次,而 B 中的每个寄存器存储 8 个不同的输入。该研究先对 A 和 B 的一个寄存器进行 EOR 和 CNT,得到 32 个 INT8 结果到中间分区 C,然后执行 ADD 将 INT8 累加到 D,对 B 的另一个寄存器做同样的事情。经过 16 次循环,最后,该研究使用长指令 ADALP 将存储在 D 中的 INT8 数据累积到一个 INT16 寄存器(在 E 中),它将 INT8 数据扩展为双倍宽度。FBCK 在计算过程中充分利用了寄存器,几乎没有空闲位。
3. 实验
在本章,该研究从推断精度、理论计算、部署性能等角度对 BiFSMN 进行全面评估。实验证明,BiFSMN 在各个方面大幅领先现有的二值神经网络,并展现了在实际部署场景下的出众潜力。
3.1 对比验证
该研究首先进行消融研究,以调查所提出的高频增强蒸馏 (HED) 和可细化二值化架构 (TBA)在 D-FSMN 上对 Speech Commands V1-12 和 Speech Commands V2-12 KWS 任务的影响,包括高频增强蒸馏 (HED) 和可细化二值化架构 (TBA)。
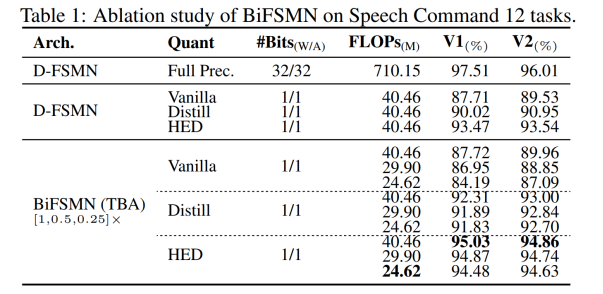
表 1 中结果表明,普通二值化基线方法在两个数据集中都出现了显着的性能下降。朴素的蒸馏方案 Distill 有助于提高基本 D-FSMN 架构的准确性,而 HED 的应用提高了基于蒸馏的性能。联合使用 HED 和 TBA 进一步缩小了二值化模型和全精度模型之间的准确率差距,最终使得在这两个数据集上的准确率均小于 3%。
其次将 BiFSMN 与现有的结构无关二值化方法进行比较,包括 BNN [Courbariaux et al., 2016]、DoReFa [Zhou et al., 2016]、XNOR [Rastegari et al., 2016]、Bi-Real [Liu et al., 2018]、IR-Net [Qin et al., 2020] 和 RAD [Ding et al., 2019]。
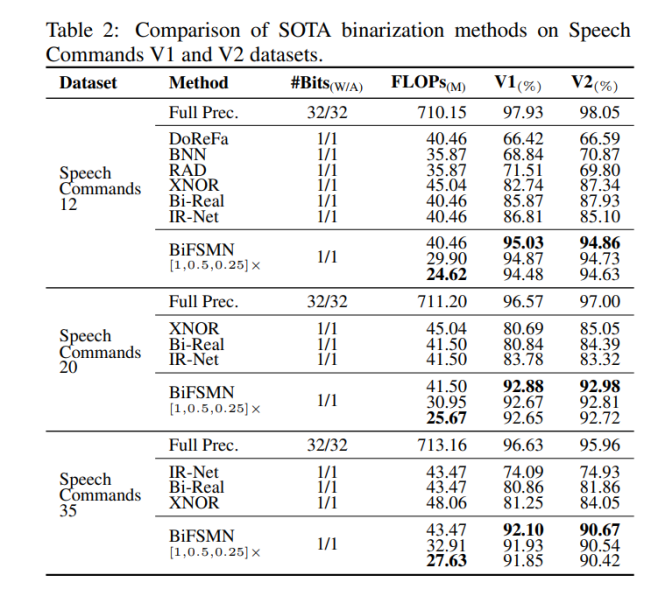
表 2 中结果表明,该研究的 1 位 BiFSMN 完全优于其他 SOTA 二值化方法。值得注意的是,BiFSMN在两个数据集上的平均准确率下降仅为4%,并远超其他二值化方法。
其次,为了从架构的角度验证 TBA 的优势,该研究还将其与 KWS 中广泛使用的各种网络进行了比较,包括 FSMN [Zhang et al., 2015]、VGG190 [Simonyan and Zisserman, 2014]、BCResNet [Kim et al.,2021] 和 Audiomer [Sahu al.,2021]。该研究使用 XNOR 和 IR-Net 对这些架构进行二值化。
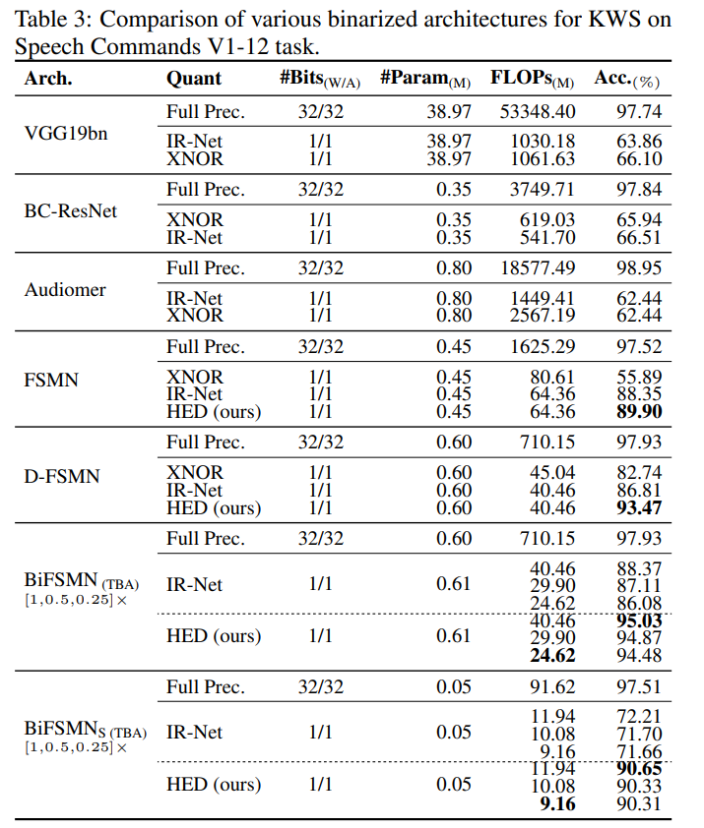
表 3 表明, HED 通常可应用于基于类似 FSMN 的架构,并对二值化模型性能产生影响。此外,配备 TBA 的 BiFSMN 可以进一步在运行时在准确性和效率之间取得平衡。例如,更薄的版本 BiFSMN0.5× with 4 blocks 和 BiFSMN0.25× with 2 blocks 甚至在 Speech Commands V1-12 任务上实现了 23.8× 和 28.8× FLOPs 节省,而不牺牲准确性(仅下降 0.16% 和 0.13%)。
该研究进一步修剪模型宽度并提供一个极小的 BiFSMNS(具有 32 个主干内存大小和 64 个隐藏大小),只有 0.05M 参数和 9.16M FLOP,证明该研究的方法在微型网络上也能很好地工作。
3.2 部署效率
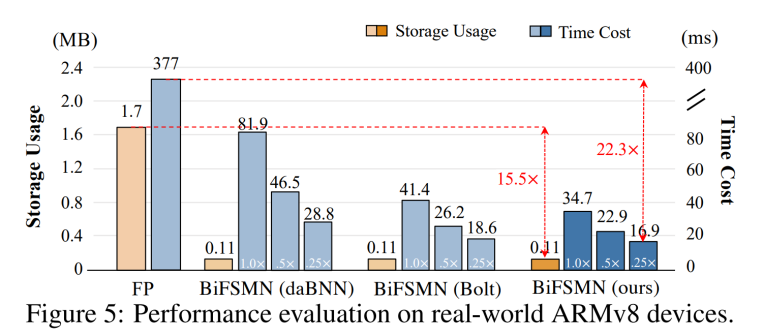
除了推理精度与理论计算性能,在现实世界的边缘设备上运行时,KWS 任务对于低内存占用和快速实时响应具有迫切需求。为了验证 BiFSMN 的实际部署效率,该研究在 1.2GHz 64 位 ARMv8 CPU Cortex-A53 的 Raspberry Pi 3B + 上测试了 BiFSMN 的实际速度。
如图 5 所示,由于提出了优化的 1 位快速按位计算内核, BiFSMN 与全精度对应物相比提供了 10.9 倍的加速度。它也比现有的开源高性能二值化框架(如 daBNN 和 Bolt)快得多。此外,受益于可细化架构,BiFSMN 可以根据设备上的资源自适应地平衡运行时的准确性和效率,切换到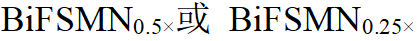 分别带来了 15.5× 和 22.3× 加速。这表明 BiFSMN 可以在实际推理中满足不同的资源约束。
分别带来了 15.5× 和 22.3× 加速。这表明 BiFSMN 可以在实际推理中满足不同的资源约束。