一、什么是http?
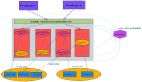
Http协议即超文本传送协议 (HTTP-Hypertext transfer protocol) 。
它定义了浏览器(即万维网客户进程)怎样向万维网服务器请求万维网文档,以及服务器怎样把文档传送给浏览器。从层次的角度看,HTTP是面向(transaction-oriented)应用层协议,它是万维网上能够可靠地交换文件(包括文本、声音、图像等各种多媒体文件)的重要基础。并且详细的规定了客户端浏览器与服务器之间互相通信的规则。
二、抓包
下面是一口君抓取的访问自己搭建的web服务器交互的所有数据包。以下是浏览器显示信息:
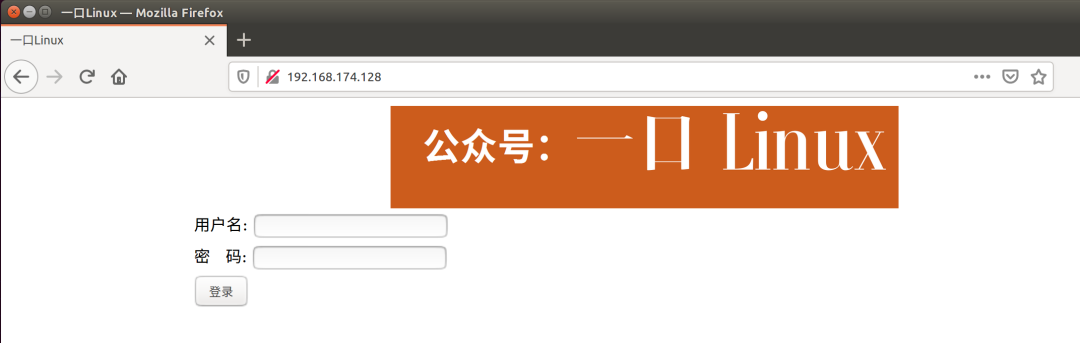
 以下是实际 index.html内容:
以下是实际 index.html内容:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" >
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>一口Linux</title>
</head>
<body >
<div align="center">
<table width="900" border="0">
<tr><td>
<form onsubmit="return isValidate(myform)" action="cgi-bin/login.cgi" method="post">
用户名: <input type="text" name="username" id="username" >
<td> </td>
<tr><td>
密 码: <input type="password" name="userpass" id="userpass">
<td> </td>
<tr><td>
<input type="submit" value="登录" id="button" >
</form>
</td></tr>
</table>
</div>
<div align="center">
<table width="900" height="467" border="0" background="./image/yikou.png">
<tr>
<td width="126" height="948"> </td>
<td width="351"></td>
<td width="101"> </td>
</tr>
</div>
</body>
</html>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
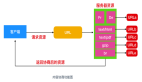
下面是用抓包工具抓取的所有HTTP数据包:
浏览器发送的GET请求数据包:
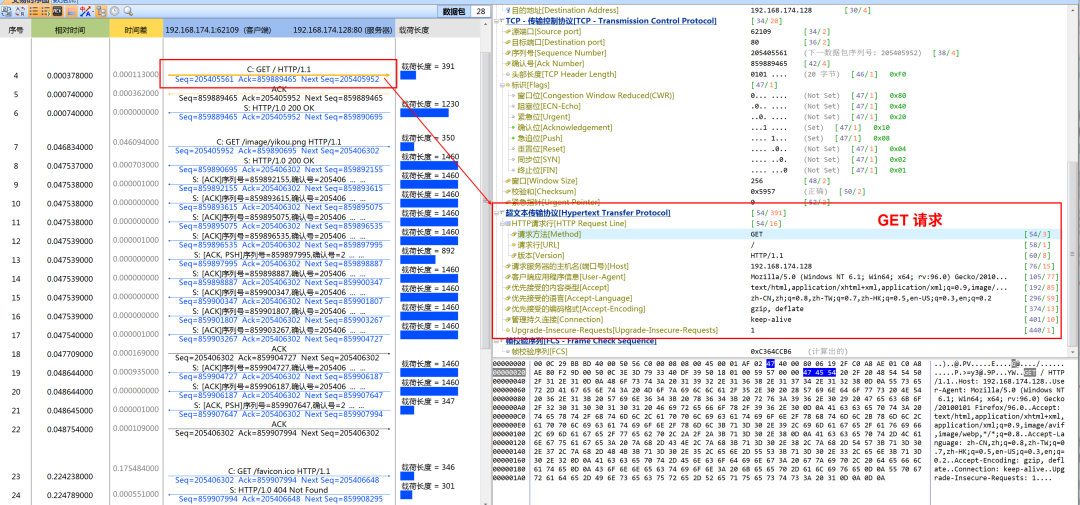
服务器回复的页面对应的数据包:
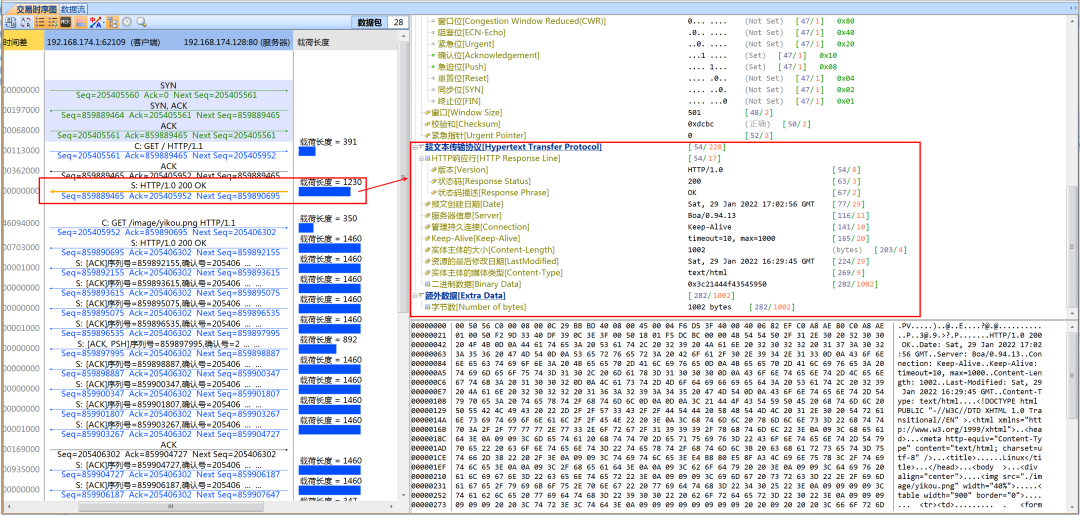
完整的浏览访问服务器数据包交互流程如下:

数据包交互流程,简单总如下:
- 浏览器会向web服务器发起tcp 3次握手,(http是基于tcp,上图数据包1-3。
- 浏览器会根据网址栏输入的url,通过DNS协议查找该domain对应的IP地址(如果url中直接给出IP地址,则省略该步骤)。
- 浏览器发送HTTP协议的GET请求,web服务器会回复对应的页面(没有指定的话,一般由配置文件指定默认文件比如index.html,见数据包4-6)。
- 因为页面有图片信息,浏览器再请求获取对应的图片文件(见数据包7-24)。
- 最后会关闭tcp连接,执行4握手(见数据包25-28)。
三、页面交互流程
下面我们来看一下,从网页输入URL到加载,http究竟做了哪些工作?
浏览器负责发起请求和最后的响应请求,服务器接收请求后,处理请求。
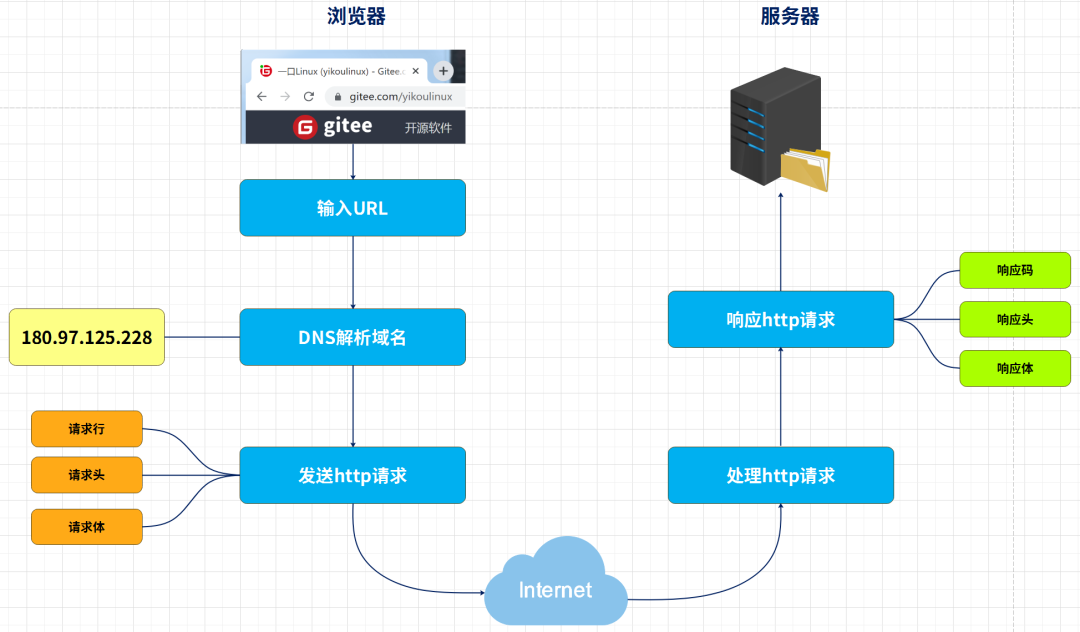
1、输入URL。
不管是链接还是地址栏的输入,情况都是一样的。http协议已经规定了URL的格式,通过http协议中的域名或IP找到服务器。
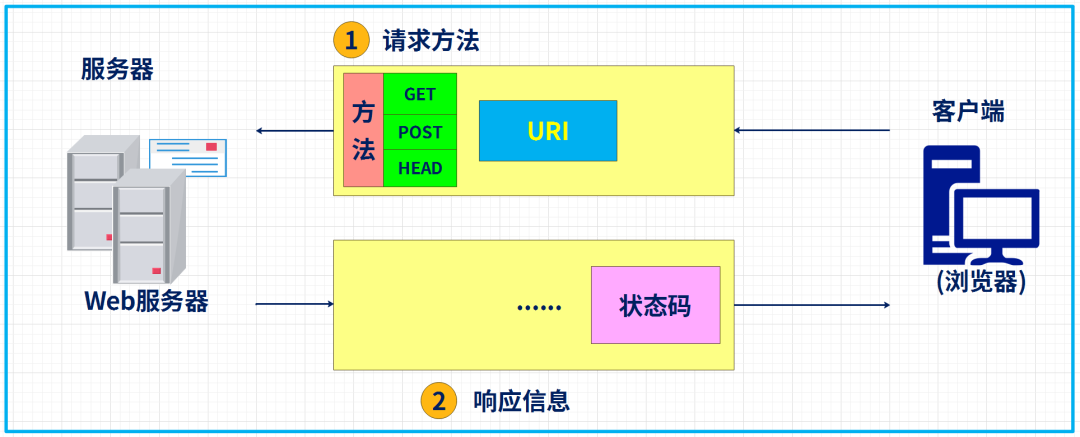
2、找到服务器的同时,会有http的请求发送过来,告诉服务器我求你做什么?http协议规定了发送请求的格式,这个格式有三部分组成请求行、请求头、请求体。
请求行包括请求的方式(get、post或其他)、要求响应的文件、http版本。请求头包括本机信息、浏览器信息等等,当然,也包括URL中?后面的参数。
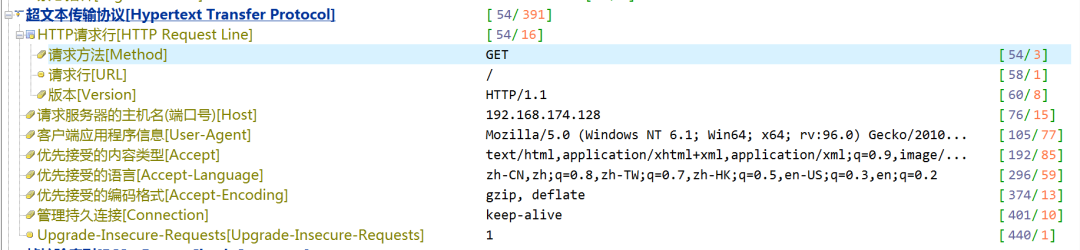
 请求体包括POST传递数据的相关信息,Get方式传值时,请求体为空。
请求体包括POST传递数据的相关信息,Get方式传值时,请求体为空。
3、请求信息发送至服务器以后,服务器会获取传递过来的相关信息进行后端程序的处理。服务器可以通过数据包中信息获取URL传递过来的值,通过form(表单)获取POST传递过来的值,当然,也是可以获取到所有的其他请求过来的信息,如浏览器信息、cookie信息、操作系统信息等。获取相关的数据以后,服务器就会根据程序进行处理。
4、处理完成以后,服务器会做出响应,向浏览器输出相关信息。http对响应的格式也做出了规定,响应的信息主要包括,响应码、响应头、响应体。
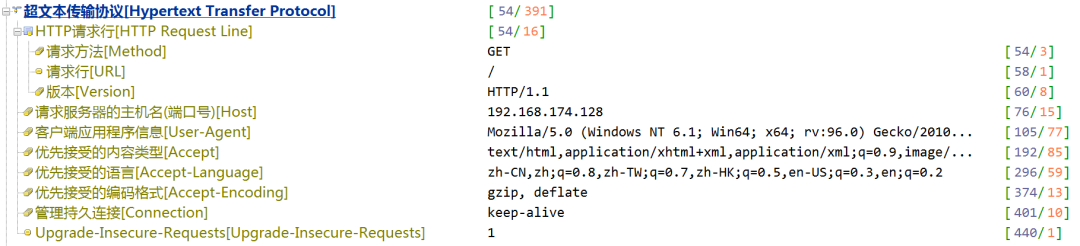
 响应码用来标识服务器响应的结果,如我们常看到的200、404等。大致的分类如下:
响应码用来标识服务器响应的结果,如我们常看到的200、404等。大致的分类如下:
1开头的表示消息。
2开头表示成功。
3开头表示重定向,
4开头表示失败。
5开头表示服务器异常。
响应头记录服务器相关信息如服务器是否启用压缩、服务器为IIS或Ngnix、程序所用服务端语言等等。当然,缓存也是在这里设置的,通过修改响应头可以修改html在本地缓存的情况,如设置浏览器缓存过期的时间。
响应体主要是我看到的html的相关内容了。
完成以上4步操作以后,浏览器就断开了与服务器的数据连接,不能在进行数据传输,如果需要再次进行数据传输,那么一切就要从输入URL开始。
如此,便是一个完整的网页流程,http从中的作用就是对整个流程进行规定,包括执行步骤,每一步的数据格式。只有了解http协议以及网页是如何产生的以后,才能对网页进行更好的控制,例如控制浏览器缓存、通过非浏览器发送http请求、get和post传值的选择,甚至是建立长连接,这些都是以http协议为基础。
四、补充
1、 http主要方法
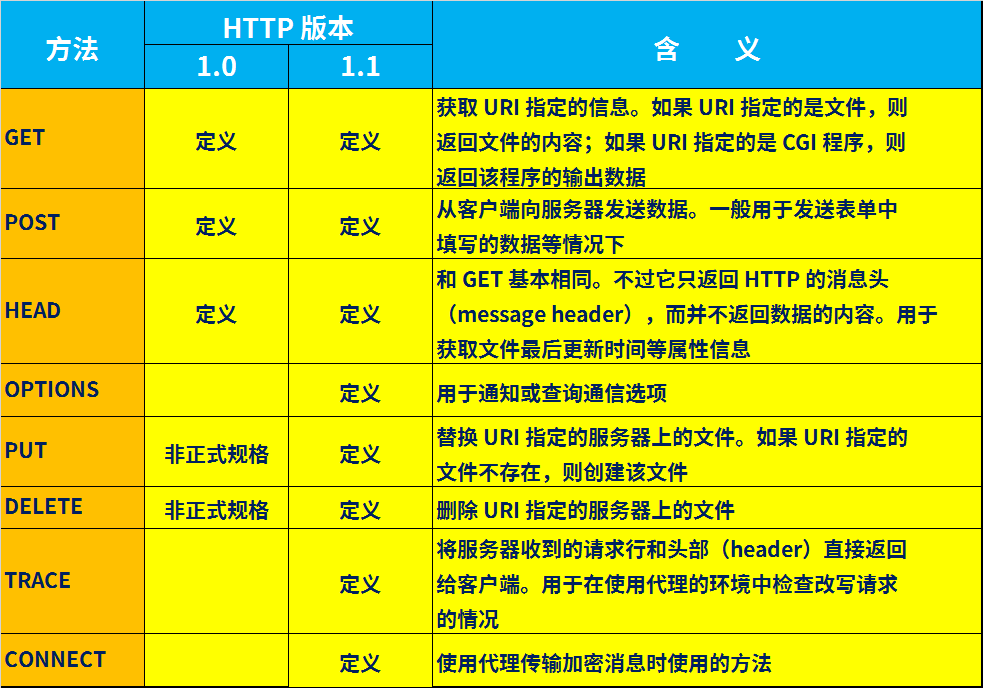
1.0 版本和 1.1 版本的描述分别基于 RFC1945 和 RFC2616 除了上图中的内容之外, HTTP 消息中还有一些用来表示附加信息的 头字段。客户端向 Web 服务器发送数据时, 会先发送头字段, 然后再发送 数据。
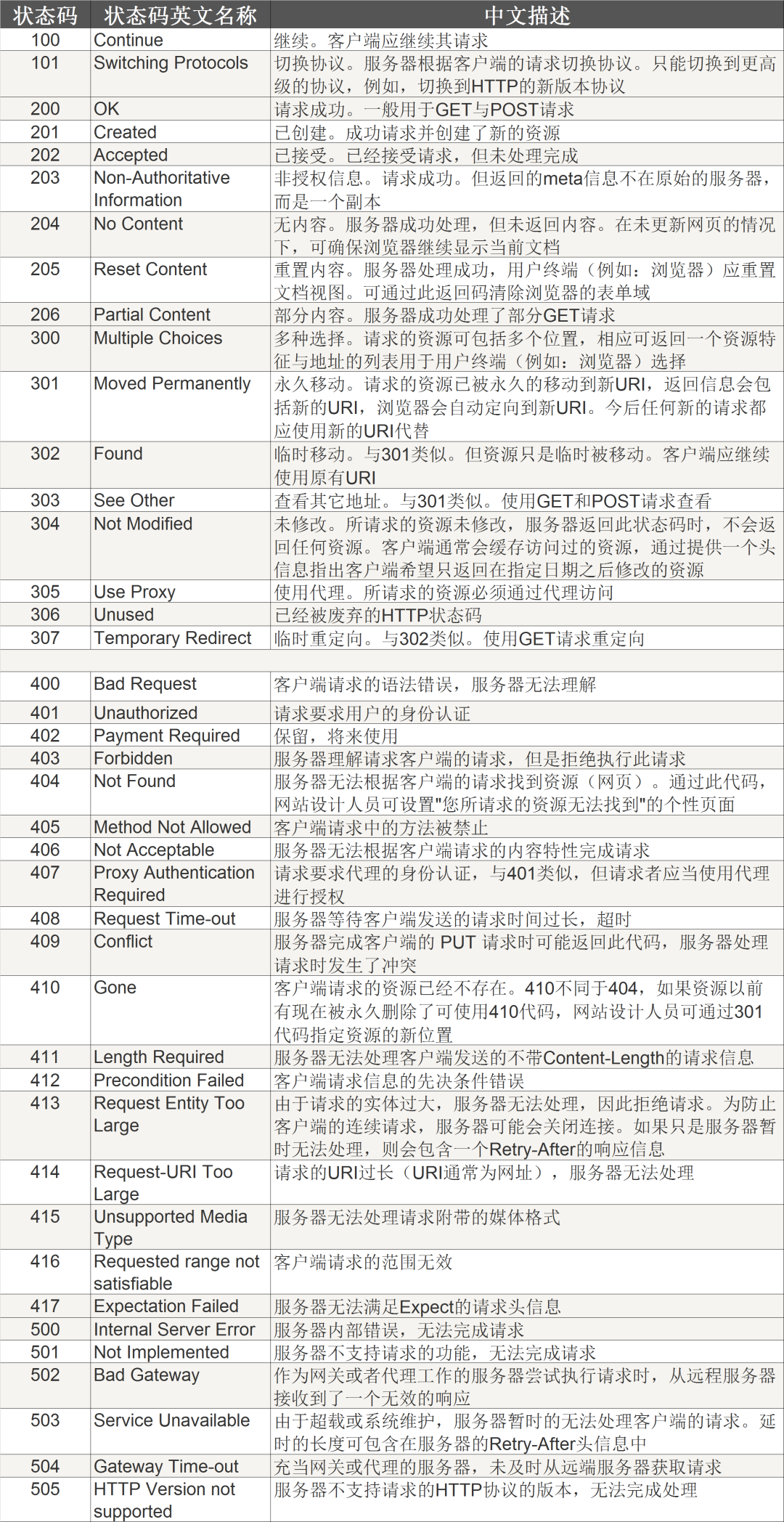
2、 状态码
收到请求消息之后, Web 服务器会对其中的内容进行解析, 通过 URI和方法来判断“对什么”“进行怎样的操作”, 并根据这些要求来完成自己的工作, 然后将结果存放在响应消息中。在响应消息的开头有一个状态码,它用来表示操作的执行结果是成功还是发生了错误。
当我们访问 Web 服务器时, 遇到找不到的文件就会显示出 404 Not Found 的错误信息, 其实这就是状态码。状态码后面就是头字段和网页数据。响应消息会被发送回客户端, 客户端收到之后, 浏览器会从消息中读出所需的数据并显示在屏幕上。到这里, HTTP 的整个工作就完成了。
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型。
响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599):

HTTP状态码列表:
本文转载自微信公众号「一口Linux」,可以通过以下二维码关注。转载本文请联系一口Linux公众号。