对于数据库来说,慢查询往往意味着风险。SQL执行得越慢,消耗的CPU资源或IO资源也会越大。大量的慢查询可直接引发业务故障,关注慢查询即是关注故障本身。本文主要介绍了美团如何利用数据库的代价优化器来优化慢查询,并给出索引建议,评估跟踪建议质量,运营治理慢查询。
一、背景
慢查询是指数据库中查询时间超过指定阈值(美团设置为100ms)的SQL,它是数据库的性能杀手,也是业务优化数据库访问的重要抓手。随着美团业务的高速增长,日均慢查询量已经过亿条,此前因慢查询导致的故障约占数据库故障总数的10%以上,而且高级别的故障呈日益增长趋势。因此,对慢查询的优化已经变得刻不容缓。
那么如何优化慢查询呢?最直接有效的方法就是选用一个查询效率高的索引。关于高效率的索引推荐,主要有基于经验规则和代价的两种算法。
在日常工作中,基于经验规则的推荐随处可见,对于简单的SQL,如 select * from sync_test1 where name like 'Bobby%' ,直接添加索引IX(name) 就可以取得不错的效果;但对于稍微复杂点的SQL,如 select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06' ,到底选择IX(name)、IX(dt)、IX(dt,name) 还是IX(name,dt),该方法也无法给出准确的回答。更别说像多表Join、子查询这样复杂的场景了。所以采用基于代价的推荐来解决该问题会更加普适,因为基于代价的方法使用了和数据库优化器相同的方式,去量化评估所有的可能性,选出的是执行SQL耗费代价最小的索引。
二、基于代价的优化器介绍
1、SQL执行与优化器
一条SQL在MySQL服务器中执行流程主要包含:SQL解析、基于语法树的准备工作、优化器的逻辑变化、优化器的代价准备工作、基于代价模型的优化、进行额外的优化和运行执行计划等部分。具体如下图所示:
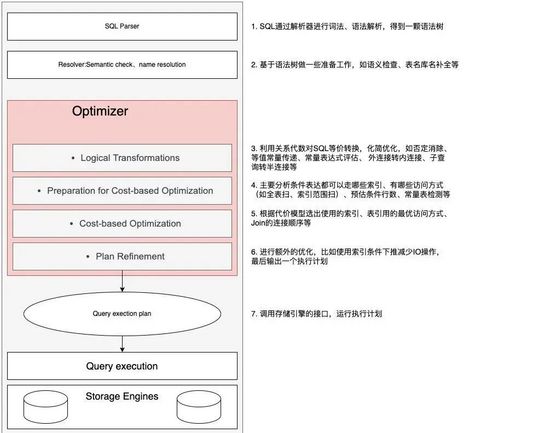
SQL执行与优化器
2、代价模型介绍
而对于优化器来说,执行一条SQL有各种各样的方案可供选择,如表是否用索引、选择哪个索引、是否使用范围扫描、多表Join的连接顺序和子查询的执行方式等。如何从这些可选方案中选出耗时最短的方案呢?这就需要定义一个量化数值指标,这个指标就是代价(Cost),我们分别计算出可选方案的操作耗时,从中选出最小值。
代价模型将操作分为Server层和Engine(存储引擎)层两类,Server层主要是CPU代价,Engine层主要是IO代价,比如MySQL从磁盘读取一个数据页的代价io_block_read_cost为1,计算符合条件的行代价为row_evaluate_cost为0.2。除此之外还有:
- memory_temptable_create_cost (default 2.0) 内存临时表的创建代价。
- memory_temptable_row_cost (default 0.2) 内存临时表的行代价。
- key_compare_cost (default 0.1) 键比较的代价,例如排序。
- disk_temptable_create_cost (default 40.0) 内部myisam或innodb临时表的创建代价。
- disk_temptable_row_cost (default 1.0) 内部myisam或innodb临时表的行代价。
在MySQL 5.7中,这些操作代价的默认值都可以进行配置。为了计算出方案的总代价,还需要参考一些统计数据,如表数据量大小、元数据和索引信息等。MySQL的代价优化器模型整体如下图所示:
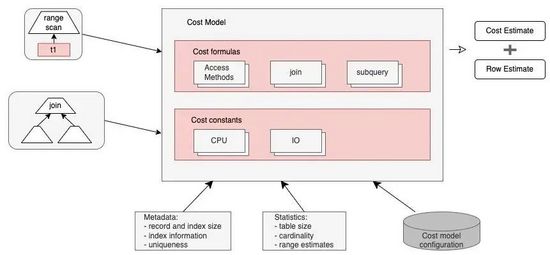
代价模型
3、基于代价的索引选择
还是继续拿上述的 SQL select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06' 为例,我们看看MySQL优化器是如何根据代价模型选择索引的。首先,我们直接在建表时加入四个候选索引。
Create Table: CREATE TABLE `sync_test1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cid` int(11) NOT NULL,
`phone` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
`address` varchar(255) DEFAULT NULL,
`dt` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `IX_name` (`name`),
KEY `IX_dt` (`dt`),
KEY `IX_dt_name` (`dt`,`name`),
KEY `IX_name_dt` (`name`,`dt`)
) ENGINE=InnoDB
通过执行explain看出MySQL最终选择了IX_name索引。
mysql> explain select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06';
+----+-------------+------------+------------+-------+-------------------------------------+---------+---------+------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-------------------------------------+---------+---------+------+------+----------+------------------------------------+
| 1 | SIMPLE | sync_test1 | NULL | range | IX_name,IX_dt,IX_dt_name,IX_name_dt | IX_name | 12 | NULL | 572 | 36.83 | Using index condition; Using where |
+----+-------------+------------+------------+-------+-------------------------------------+---------+---------+------+------+----------+------------------------------------+
然后再打开MySQL追踪优化器Trace功能。可以看出,没有选择其他三个索引的原因均是因为在其他三个索引上使用range scan的代价均>= IX_name。
mysql> select * from INFORMATION_SCHEMA.OPTIMIZER_TRACE\G;
*************************** 1. row ***************************
TRACE: {
"rows_estimation": [
{
"table": "`sync_test1`",
"range_analysis": {
"table_scan": {
"rows": 105084,
"cost": 21628
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "IX_name",
"ranges": [
"Bobby\u0000\u0000\u0000\u0000\u0000 <= name <= Bobbyÿÿÿÿÿ"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 572,
"cost": 687.41,
"chosen": true
},
{
"index": "IX_dt",
"ranges": [
"0x99aa0c0000 < dt"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 38698,
"cost": 46439,
"chosen": false,
"cause": "cost"
},
{
"index": "IX_dt_name",
"ranges": [
"0x99aa0c0000 < dt"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 38292,
"cost": 45951,
"chosen": false,
"cause": "cost"
},
{
"index": "IX_name_dt",
"ranges": [
"Bobby\u0000\u0000\u0000\u0000\u0000 <= name <= Bobbyÿÿÿÿÿ"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 572,
"cost": 687.41,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
},
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "IX_name",
"rows": 572,
"ranges": [
"Bobby\u0000\u0000\u0000\u0000\u0000 <= name <= Bobbyÿÿÿÿÿ"
]
},
"rows_for_plan": 572,
"cost_for_plan": 687.41,
"chosen": true
}
}
下面我们根据代价模型来推演一下代价的计算过程:
- 走全表扫描的代价: io_cost + cpu_cost = (数据页个数 * io_block_read_cost)+ (数据行数 * row_evaluate_cost + 1.1) = (data_length / block_size + 1)+ (rows * 0.2 + 1.1) = (9977856 / 16384 + 1) + (105084 * 0.2 + 1.1) = 21627.9。
- 走二级索引IX_name的代价: io_cost + cpu_cost = (预估范围行数 * io_block_read_cost + 1) + (数据行数 * row_evaluate_cost + 0.01) = (572 * 1 + 1) + (572*0.2 + 0.01) = 687.41。
- 走二级索引IX_dt的代价: io_cost + cpu_cost = (预估范围行数 * io_block_read_cost + 1) + (数据行数 * row_evaluate_cost + 0.01) = (38698 * 1 + 1) + (38698*0.2 + 0.01) = 46438.61。
- 走二级索引IX_dt_name的代价: io_cost + cpu_cost = (预估范围行数 * io_block_read_cost + 1) + (数据行数 * row_evaluate_cost + 0.01) = (38292 * 1 + 1) + (38292 * 0.2 + 0.01) = 45951.41。
- 走二级索引IX_name_dt的代价: io_cost + cpu_cost = (预估范围行数 * io_block_read_cost + 1) + (数据行数 * row_evaluate_cost + 0.01) = (572 * 1 + 1) + (572*0.2 + 0.01) = 687.41。
补充说明
- 计算结果在小数上有偏差,因为MySQL使用%g打印浮点数,小数会以最短的方式输出。
- 除“+1.1 +1”这种调节值外,Cost计算还会出现+0.01, 它是为了避免index scan和range scan出现Cost的竞争。
- Cost计算是基于MySQL的默认参数配置,如果Cost Model参数改变,optimizer_switch的选项不同,数据分布不同都会导致最终Cost的计算结果不同。
- data_length可查询information_schema.tables,block_size默认16K。
4、基于代价的索引推荐思路
如果想借助MySQL优化器给慢查询计算出最佳索引,那么需要真实地在业务表上添加所有候选索引。对于线上业务来说,直接添加索引的时间空间成本太高,是不可接受的。MySQL优化器选最佳索引用到的数据是索引元数据和统计数据,所以我们想是否可以通过给它提供候选索引的这些数据,而非真实添加索引的这种方式来实现。
通过深入调研MySQL的代码结构和优化器流程,我们发现是可行的:一部分存在于Server层的frm文件中,比如索引定义;另一部分存在于Engine层中,或者通过调用Engine层的接口函数来获取,比如索引中某个列的不同值个数、索引占据的页面大小等。索引相关的信息,如下图所示:
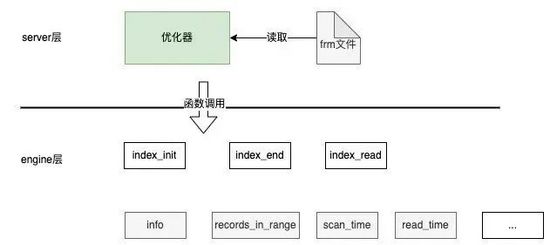
基于代价的索引推荐思路
因为MySQL本身就支持自定义存储引擎,所以索引推荐思路是构建一个支持虚假索引的存储引擎,在它上面建立包含候选索引的空表,再采集样本数据,计算出统计数据提供给优化器,让优化器选出最优索引,整个调用关系如下图所示:
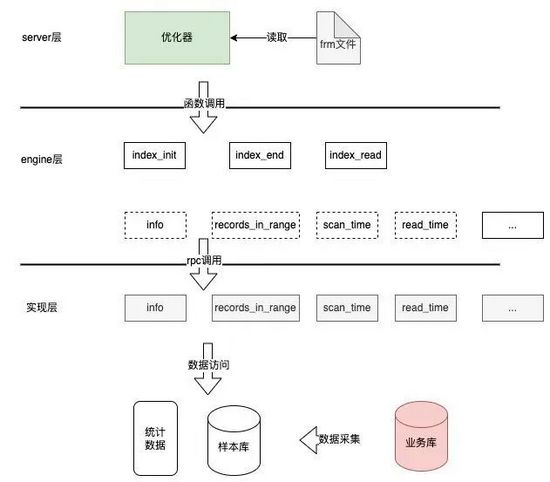
基于代价的索引推荐思路
三、索引推荐实现
因为存储引擎本身并不具备对外提供服务的能力,直接在MySQL Server层修改也难以维护,所以我们将整个索引推荐系统拆分成支持虚假索引的Fakeindex存储引擎和对外提供服务的Go-Server两部分,整体架构图如下:
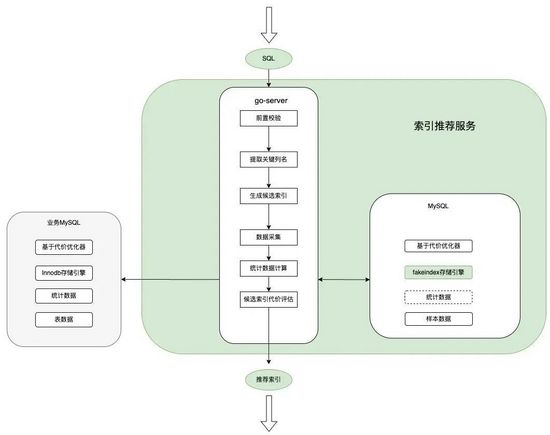
架构图
首先简要介绍一下Fakeindex存储引擎,这是一个轻量级的存储引擎,负责将索引的相关接口透传到Go-Server部分。因为它必须采用C++实现,与Go-Server间存在跨语言调用的问题,我们使用了Go原生的轻量级RPC技术+cgo来避免引入重量级的RPC框架,也不必引入第三方依赖包。函数调用链路如下所示,MySQL优化器调用Fakeindex的C++函数,参数转换成C语言,然后通过cgo调用到Go语言的方法,再通过Go自带的RPC客户端向服务端发起调用。

调用链路
下面将重点阐述核心逻辑Go-Server部分,主要流程步骤如下。
1、前置校验
首先根据经验规则,排除一些不支持通过添加索引来提高查询效率的场景,如查系统库的SQL,非select、update、delete SQL等。
2、提取关键列名
这一步提取SQL可用来添加索引的候选列名,除了选择给出现在where中的列添加索引,MySQL对排序、聚合、表连接、聚合函数(如max)也支持使用索引来提高查询效率。我们对SQL进行语法树解析,在树节点的where、join、order by、group by、聚合函数中提取列名,作为索引的候选列。值得注意的是,对于某些SQL,还需结合表结构才能准确地提取,比如:
- select * from tb1, tb2 where a = 1,列a归属tb1还是tb2取决于谁唯一包含列a。
- select * from tb1 natural join tb2 where tb1.a = 1,在自然连接中,tb1和tb2默认使用了相同列名进行连接,但SQL中并没有暴露出这些可用于添加索引的列。
3、生成候选索引
将提取出的关键列名进行全排列即包含所有的索引组合,如列A、B、C的所有索引组合是['A', 'B', 'C', 'AB', 'AC', 'BA', 'BC', 'CA', 'CB', 'ABC', 'ACB', 'BAC', 'BCA', 'CAB', 'CBA'],但还需排除一些索引才能得到所有的候选索引,比如:
- 已经存在的索引,如存在AB,需排除AB、A,因为MySQL支持使用前缀索引。
- 超过最大索引长度3072字节限制的索引。
- 一些暂时不支持的索引,如带地理数据类型列的空间索引。
4、数据采集
直接从业务数据库采集,数据分成元数据、统计数据、样本数据三部分:
- 元数据: 即表的定义数据,包括列定义、索引定义,可通过show create table获取。
- 统计数据: 如表的行数、表数据大小、索引大小,可以通过查询infromation_schema.tables获取;已存在索引的cardinality(关键值:即索引列的不同值个数,值越大,索引优化效果越明显),可以通过查询mysql.innodb_index_stats表获取。
- 样本数据: 候选索引为假索引,采集的统计数据并不包含假索引的数据,这里我们通过采集原表的样本数据来计算出假索引的统计数据。
数据采集
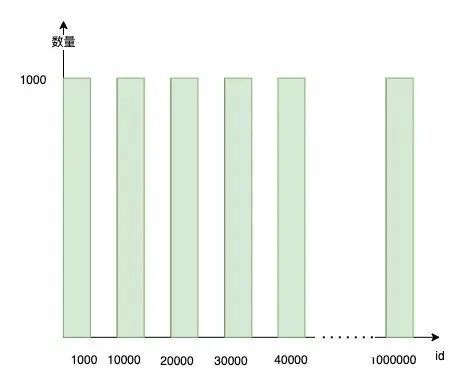
下面介绍样本数据的采样算法,好的采样算法应该尽最大可能采集到符合原表数据分布的样本。比如基于均匀随机采样的方式 select * from table where rand() < rate ,然而它会给线上数据库造成大量I/O的问题,严重时可引发数据库故障。所以我们采用了基于块的采样方式:它参考了MySQL 8.0的直方图采样算法,如对于一张100万的表,采集10万行数,根据主键的最小值最大值将表数据均分成100个区间,每个区间取一块1000行数据,采集数据的SQL,最后将采集到的数据塞入采样表中。代码如下:
select A,B,C,id from table where id >= 1000 and id <= 10000 limit 1000;
select A,B,C,id from table where id >= 10000 and id <= 20000 limit 1000;
5、统计数据计算
下面举例说明两个核心统计数据的计算方式。首先是records_in_range,优化器在处理范围查询时,如果可以用索引,就会调用该函数估算走该索引可过滤出的行数,以此决定最终选用的索引。
比如,对于 SQLselect * from table1 where A > 100 and B < 1000 ,候选索引A、B来说,优化器会调用此函数在索引页A上估算A > 100有多少行数,在索引页B上估计B<1000的行数,例如满足条件的A有200行,B有50行,那么优化器会优先选择使用索引B。对于假索引来说,我们按照该公式:样本满足条件的范围行数 * (原表行数 / 样本表行数),直接样本数据中查找,然后按照采样比例放大即可估算出原表中满足条件的范围行数。
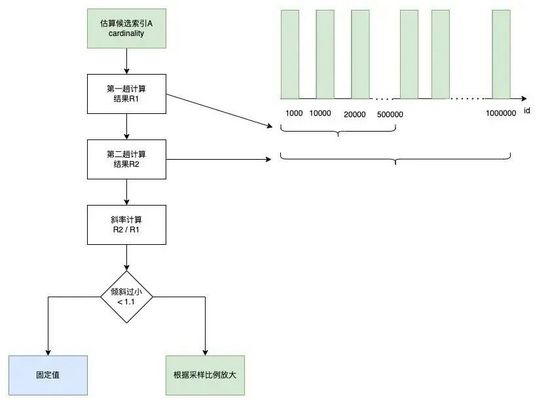
其次是用于计算索引区分度的cardinality。如果直接套用上述公式:样本列上不同值个数 * (原表行数 / 样本表行数), 如上述的候选索引A,根据样本统计出共有100个不同值,那么在原表中,该列有多少不同值?一般以为是10,000 =100 *(1,000,000/100,000)。但这样计算不适用某些场景,比如状态码字段,可能最多100个不同值。针对该问题,我们引入斜率和两趟计算来规避,流程如下:
- 第一趟计算: 取样本数据一半来统计A的不同值个数R1,区间[min_id, min_id+(max_id - min_id) / 2]。
- 第二趟计算: 取所有样本据统计A的不同值个数R2,区间[min_id, max_id] 计算斜率:R2/R1。
- 判断斜率: 如果斜率小于1.1,为固定值100,否则根据采样比例放大,为10,000。
统计数据计算
6、候选索引代价评估
这一步让优化器帮助我们从候选索引中选出最佳索引,主要步骤如下:
- 建包含候选索引的表:将候选索引塞入原表定义,并把存储引擎改为Fakeindex,在推荐引擎的mysqld上创建表。
- 通过在推荐引擎mysqld上explain format=json SQL,获取优化器选择的索引。
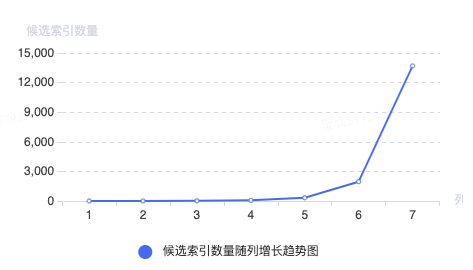
值得注意的是,MySQL表最多建64个索引(二级索引),计算所有候选索引的可能时,使用的是增幅比指数还恐怖的全排列算法。如下图所示,随着列数的增加,候选索引数量急剧上升,在5个候选列时的索引组合数量就超过了MySQL最大值,显然不能满足一些复杂SQL的需求。统计美团线上索引列数分布后,我们发现,95%以上的索引列数都<=3个。同时基于经验考虑,3列索引也可满足绝大部分场景,剩余场景会通过其他方式,如库表拆分来提高查询性能,而不是增加索引列个数。
候选索引代价评估
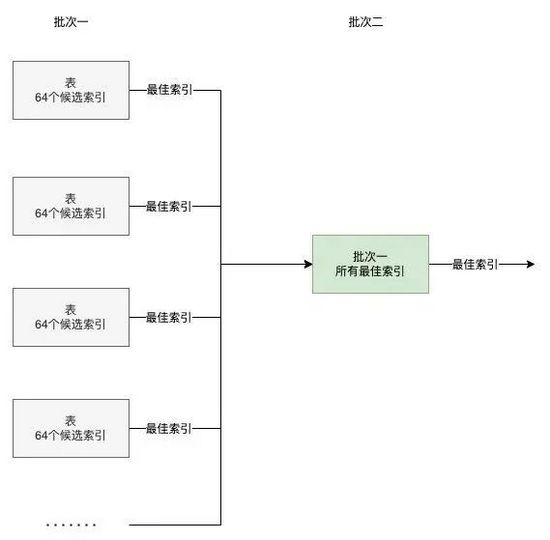
但即便最多推荐3列索引,在5个候选列时其排列数量85=也远超64。这里我们采用归并思路。如下图所示,将所有候选索引拆分到多个表中,采用两次计算,先让MySQL优化器选出批次一的最佳索引,可采用并行计算保证时效性,再MySQL选出批次一所有最佳索引的最佳索引,该方案可以最多支持4096个候选索引,结合最大索引3列限制,可以支持计算出17个候选列的最佳索引。
候选索引代价评估
四、推荐质量保证
为了得到索引推荐质量大致的整体数据,我们使用美团数据库最近一周的线下慢查询数据,共246G、约3万个SQL模板用例做了一个初步测试。
建议质量保证
从结果可以看出,系统基本能覆盖到大部分的慢查询。但还是会出现无效的推荐,大致原因如下:
- 索引推荐计算出的Cost严重依赖样本数据的质量,在当表数据分布不均或数据倾斜时会导致统计数据出现误差,导致推荐出错误索引。
- 索引推荐系统本身存在缺陷,从而导致推荐出错误索引。
- MySQL优化器自身存在的缺陷,导致推荐出错误索引。
因此,我们在业务添加索引前后增加了索引的有效性验证和效果追踪两个步骤,整个流程如下所示:

全链路
1、有效性验证
因为目前还不具备大规模数据库备份快速还原的能力,所以无法使用完整的备份数据做验证。我们近似地认为,如果推荐索引在业务库上取得较好的效果,那么在样本库也会取得不错效果。通过真正地在样本库上真实执行SQL,并添加索引来验证其有效性,验证结果展示如下:
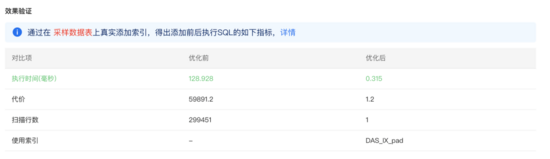
有效性验证
2、效果追踪
考虑到使用采样数据验证的局限性,所以当在生产环境索引添加完毕之后,会立即对添加的索引进行效果追踪。一方面通过explain验证索引是否被真正用到,以及Cost是否减小;另一方面用Flink实时跟踪该数据库的全量SQL访问数据,通过对比索引添加前后,该SQL的真实执行时间来判断索引是否有效。如果发现有性能方面的回退,则立即发出告警,周知到DBA和研发人员。生成的报告如下:
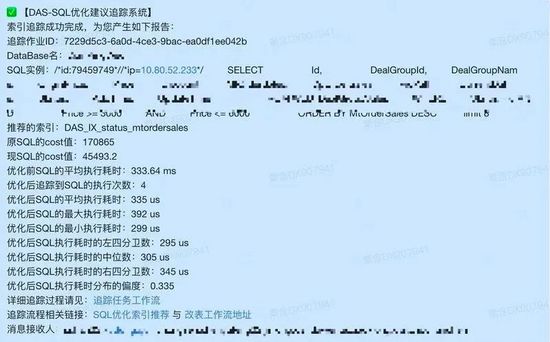
效果追踪
3、仿真环境
当推荐链路出现问题时,直接在线上排查验证问题的话,很容易给业务带来安全隐患,同时也降低了系统的稳定性。对此我们搭建了离线仿真环境,利用数据库备份构建了和生产环境一样的数据源,并完整复刻了线上推荐链路的各个步骤,在仿真环境回放异常案例,复现问题、排查根因,反复验证改进方案后再上线到生产系统,进而不断优化现有系统,提升推荐质量。
仿真环境
4、测试案例库
在上线过程中,往往会出现改进方案修复了一个Bug,带来了更多Bug的情况。能否做好索引推荐能力的回归测试,直接决定了推荐质量的稳定性。于是,我们参考了阿里云的技术方案,计划构建一个尽可能完备的测试案例库用于衡量索引推荐服务能力强弱。但考虑影响MySQL索引选择的因素众多,各因素间的组合,SQL的复杂性,如果人为去设计测试用例是是不切实际的,我们通过下列方法自动化收集测试用例:
- 利用美团线上的丰富数据,以影响MySQL索引选择的因素特征为抓手,直接从全量SQL和慢SQL中抽取最真实的案例,不断更新现有测试案例库。
- 在生产的推荐系统链路上埋点,自动收集异常案例,回流到现有的测试案例库。
- 对于现有数据没有覆盖到的极端场景,采用人为构造的方案,补充测试用例。
测试案例库
五、慢查询治理运营
我们主要从时间维度的三个方向将慢查询接入索引推荐,推广治理:

慢查询治理运营
1、过去-历史慢查询
这类慢查询属于过去产生的,并且一直存在,数量较多,治理推动力不足,可通过收集历史慢查询日志发现,分成两类接入:
- 核心数据库: 该类慢查询通常会被周期性地关注,如慢查询周报、月报,可直接将优化建议提前生成出来,接入它们,一并运营治理。
- 普通数据库: 可将优化建议直接接入数据库平台的慢查询模块,让研发自助地选择治理哪些慢查询。
2、现在-新增慢查询
这类慢查询属于当前产生的,数量较少,属于治理的重点,也可通过实时收集慢查询日志发现,分成两类接入:
- 影响程度一般的慢查询: 可通过实时分析慢查询日志,对比历史慢查询,识别出新增慢查询,并生成优化建议,为用户创建数据库风险项,跟进治理。
- 影响程度较大的慢查询: 该类通常会引发数据库告警,如慢查询导致数据库Load过高,可通过故障诊断根因系统,识别出具体的慢查询SQL,并生成优化建议,及时推送到故障处理群,降低故障处理时长。
3、未来-潜在慢查询
这类查询属于当前还没被定义成慢查询,随着时间推进可能变成演变成慢查询,对于一些核心业务来说,往往会引发故障,属于他们治理的重点,分成两类接入:
- 未上线的准慢查询: 项目准备上线而引入的新的准慢查询,可接入发布前的集成测试流水线,Java项目可通过 agentmain的代理方式拦截被测试用例覆盖到的SQL,再通过经验+explain识别出慢查询,并生成优化建议,给用户在需求管理系统上创建缺陷任务,解决后才能发布上线。
- 已上线的准慢查询: 该类属于当前执行时间较快的SQL,随着表数据量的增加,会演变成慢查询,最常见的就是全表扫描,这类可通过增加慢查询配置参数log_queries_not_using_indexes记录到慢日志,并生成优化建议,为用户创建数据库风险项,跟进治理。
六、项目运行情况
当前,主要以新增慢查询为突破点,重点为全表扫描推荐优化建议。目前我们已经灰度接入了一小部分业务,共分析了六千多条慢查询,推荐了一千多条高效索引建议。另外,美团内部的研发同学也可通过数据库平台自助发起SQL优化建议工单,如下图所示:
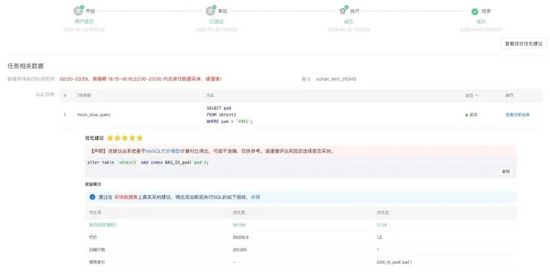
RDS平台发起
另外在美团内部,我们已经和数据库告警打通,实现了故障发现、根因分析、解决方案的自动化处理,极大地提高了故障处理效率。下面是一个展示案例,当数据库集群发生告警,我们会拉一个故障群,先通过根因定位系统,如果识别出慢查询造成的,会马上调用SQL优化建议系统,推荐出索引,整个处理流程是分钟级别,都会在群里面推送最新消息。如下图所示:
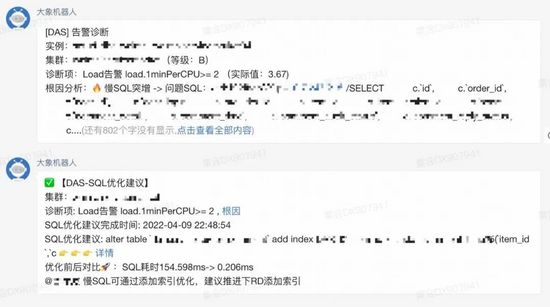
告警诊断
七、未来规划
考虑到美团日均产生近亿级别的慢查询数据,为了实现对它们的诊断分析,我们还需要提高系统大规模的数据并发处理的能力。另外,当前该系统还是针对单SQL的优化,没有考虑维护新索引带来的代价,如占用额外的磁盘空间,使写操作变慢,也没有考虑到MySQL选错索引引发其他SQL的性能回退。对于业务或者DBA来说,我们更多关心的是整个数据库或者集群层面的优化。
业界如阿里云的DAS则是站在全局的角度考量,综合考虑各个因素,输出需要创建的新索引、需要改写的索引、需要删除的索引,实现数据库性能最大化提升,同时最大化降低磁盘空间消耗。未来我们也将不断优化和改进,实现类似基于Workload的全局优化。