作者 | 宇毅
前言
近年来,数据库系统服务的数据量呈指数级增长,同时也面临处理的业务需求愈发复杂、实时性要求越来越高等挑战。单机数据库系统已经逐渐不能满足现代的数据库服务要求,因此分布式数据库/数据仓库得到了越来越广泛地运用。
在实时分析(OLAP)领域,分布式数据仓库可以充分发挥系统的分布式特点,将复杂的OLAP任务分解下发到系统中的所有节点进行计算提升分析性能;分布式数据仓库也可以比较方便地对系统节点进行扩容,应对用户业务数据量增加的需求。但是分布式数据仓库用户无法避免的一个问题是:随着数据仓库集群规模增大,扩容带来的性价比愈发降低。
造成这种现象的一个原因是,表连接(Join)作为数据库业务中最广泛使用的算子之一,在分布式计算中依赖系统节点间的数据交互;当分布式集群规模增大时,节点之间的数据交互代价会明显增加,这种情况下非常考验分布式系统的网络处理能力,并依赖用户的数据表设计和SQL编写能力以缓解数据交互压力。
针对这个问题,业界不同的分布式数据库系统提出了不同的Join运行时过滤(Runtime Filter)算法。AnalyticDB for PostgreSQL(以下简称ADB PG)是一款PB级的MPP架构云原生数据仓库,同样也面临着上述问题的挑战。本文从ADB PG架构设计的角度出发,探讨Runtime Filter在ADB PG中的实现方案,并介绍了基于Bloom Filter的ADB PG Dynamic Join Filter功能技术细节。
ADB PG架构简介
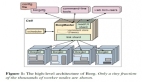
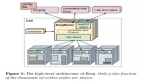
ADB PG基于开源项目Greenplum构建,在单机PostgreSQL的基础上进行扩展,将多个PG服务同时启动在单个或多个服务器上并组成集群,以分布式的形式提供数据库服务。ADB PG将每一个PG服务称为一个Segment,并引入了Slice的概念。Slice用于解决分布式系统中的网络结构,当数据库涉及到MPP多阶段计算时,例如Hash Join左右表的Join Key不满足相同的Hash分布,那么就需要对Join Key通过网络传输进行重分布,ADB PG将网络传输的前后阶段切分为不同的Slices。以下是一个ADB PG集群示意图。
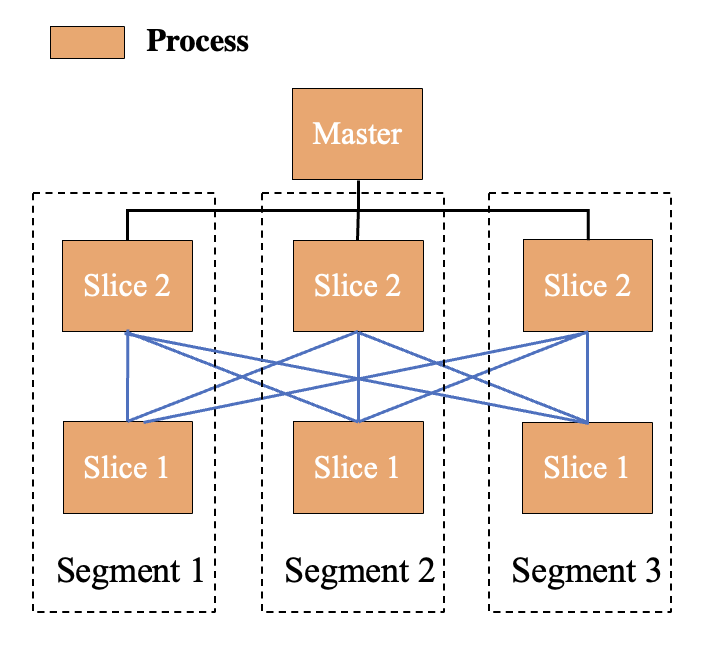
在这种架构下如何解决大规模集群下表连接Join的性能问题呢?业界解决这个问题的一个方案是引入网络代理节点,同一机器内的Segment将网络数据发送至本地代理节点,由代理节点与其它机器上的代理节点进行网络收发工作以减少网络拥塞。该方案对ADB PG架构的挑战较大,且没有从根本上减少Join的网络Shuffle开销。因此为了从Join根源上减少Join计算的数据量,ADB PG设计并实现了Join Runtime Filter方案。
Runtime Filter和Bloom Filter
Runtime FIlter的目的是在Join计算前筛选掉一部分数据,需要一个Filter的实现“载体”。在结合ADB PG的架构设计、存储层和网络层的特点后,我们选择使用Bloom Filter作为Runtime Filter的实现形式。
Bloom Filter是一种概率数据结构,通常被用于判断一个元素是否属于一个集合。Bloom Filter的优点是其空间效率非常高,计算性能通常也高;缺点是存在阳性误判率false positive,但是不存在false negative,即Bloom Filter判断一个元素是否属于集合的结果不是单纯的true or false,而是"possible true" or "false"。
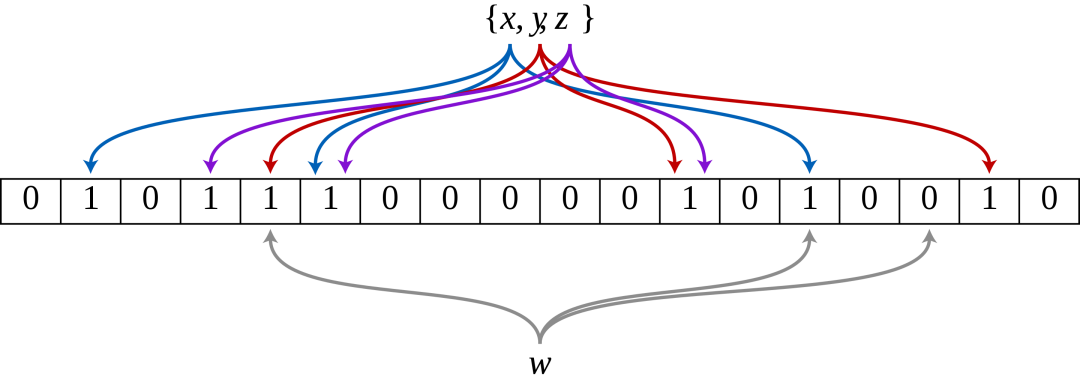
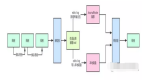
上图是一个标准Bloom Filter的计算思路示意图,其中的0、1为Bloom Filter用于表示集合信息的bit array,即每一位用一个bit存储。上方x,y,z表示向Bloom Filter中插入的三个元素,分别使用3种hash算法计算hash值后在bit array中置位。而下方为判断元素w是否属于集合,由于3个hash值中的某一位没有在bit array中被置位,可以肯定的是w不属于集合。
Bloom Filter通常由以下几个参数描述:
- m --- Bloom Filter bit array的大小m bits
- k --- 使用的hash函数个数k
- p --- 误判率
- n --- Bloom Filter插入的元素个数
我们省略推导过程,直接将各个参数的关系给出:
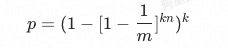
当Bloom Filter足够大时,可以简化为:
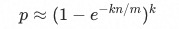
在设计Bloom Filter时,n和m我们可以根据实际计算场景提前确定,上述公式可以视为自变量为k,应变量为p的函数p(k),此函数通常在k > 0时通常不是单调的(由n:m确定)。因此Bloom Filter在设计时要考虑如何确定hash函数k的个数以获得最小的误判率p。根据上式可以计算得到当p为极小值时,对应k的值为:
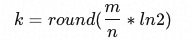
Bloom Filter的参数设计:
如何将Bloom Filter应用至ADB PG Join过滤优化,我们首先要设计选择Bloom Filter的参数。对于Bloom Filter插入元素的个数n,可以直接使用执行计划中获得的Join右表计划行数;而为了获得理想的过滤率,减少误判率p,ADB PG使用了PG高版本Bloom Filter的思路,设计Bloom FIlter大小Bytes为n的2倍,即总体n:m达到1:16。在这个设计下,可以计算得到最佳的k取值为11,p(k)函数如下图所示,当k = 11时可以取得最小的p = 0.046%
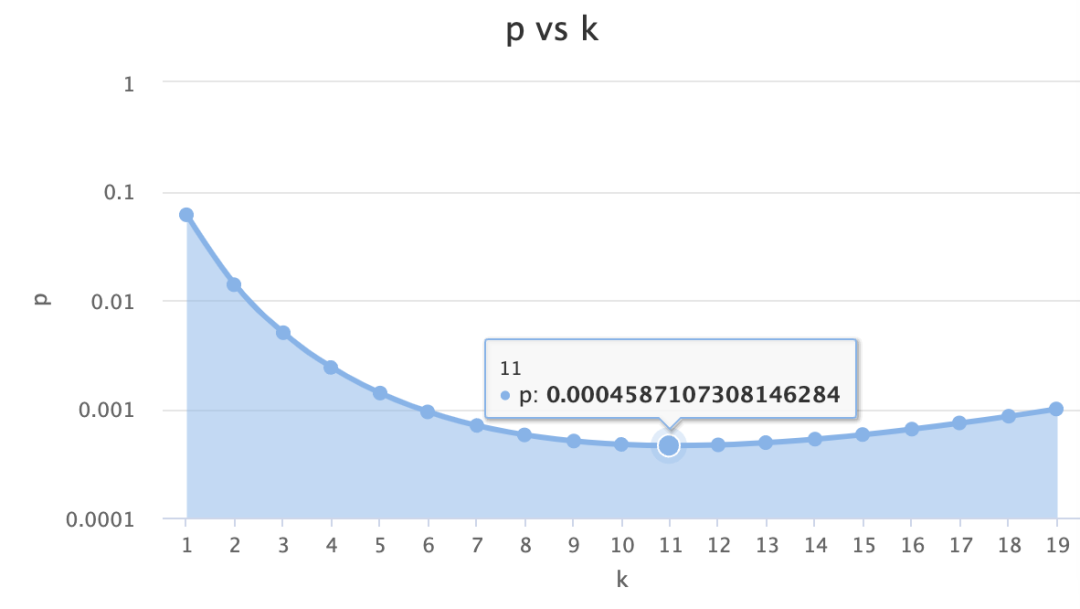
k = 11意味着对于每一个元素,都需要计算11个hash值以插入到Bloom Filter bit array中,这对于ADB PG是无法接受的,构建Bloom Filter的代价明显过大。在构建Bloom Filter时,ADB PG会综合误判率、hash计算等因素考虑,选择合适的k值。
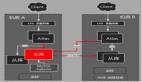
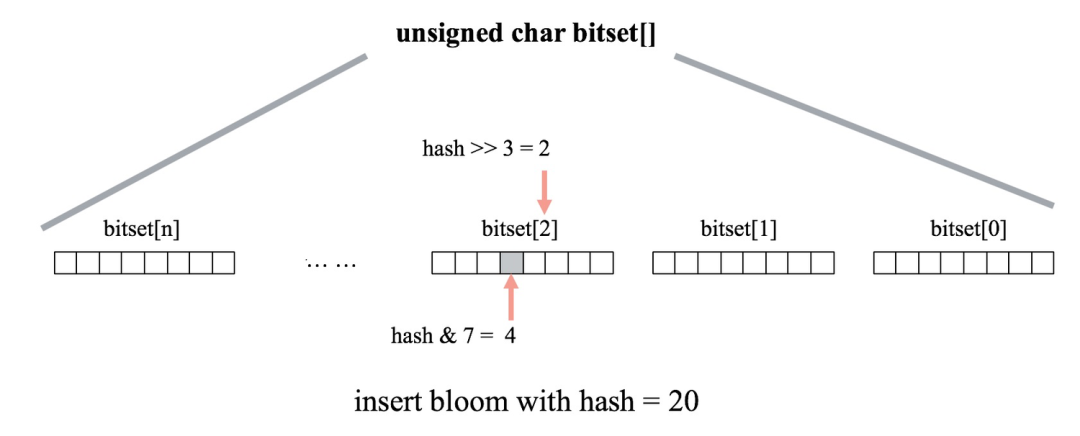
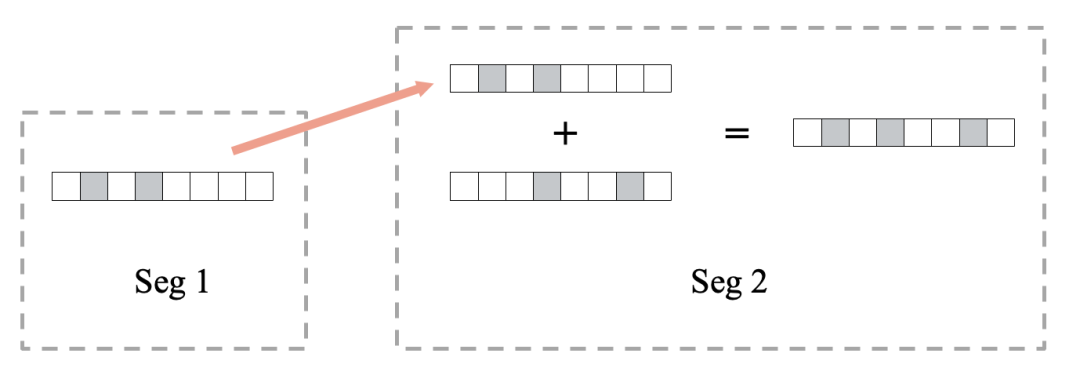
在确定构建Bloom Filter的基本原则后,接下来就是工程实现问题。Bloom Filter的工程实现非常简单高效,通常我们可以直接使用bitset数组来建立Bloom Filter,通过位操作实现Bloom Filter的插入和查找。下图为向一个Bloom Filter bitset数组中插入元素的计算示意图。
Dynamic Join Filter in ADB PG
在完成ADB PG Hash Join的Bloom Filter设计后,接来下讨论如何将Bloom Filter应用至Join的Runtime Filter中。ADB PG将基于Bloom Filter的Runtime Filter命名为Dynamic Join Filter。
1.Dynamic Join Filter的实现方式
由于ADB PG优化器通常会选择将右表作为小表,左表作为大表,因此ADB PG将Dynamic Join Filter的设计特点为单向过滤的,即仅用于右表过滤左表,暂不考虑左表过滤右表的形式;同时我们也可以将Dynamic Join Filter灵活应用于Hash Join左表链路不同算子的过滤中。
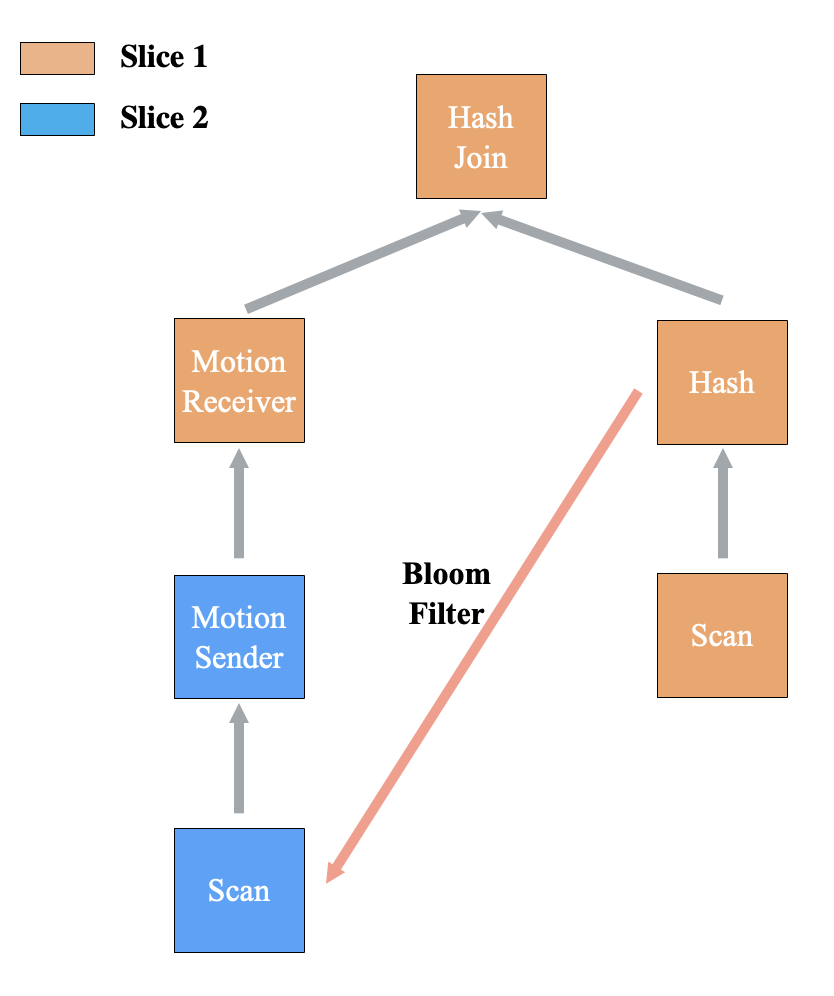
由于Hash Join的形式不同,Dynamic Join Filter的实现形式可以总结为Local Join和MPP Join两种形式,并根据Runtime Filter是否具有下推算子的能力做进一步区分。
Local Join
Local Join是指左右表的Join Key均满足相同Hash分布,无需再Shuffle数据。此时Hash、Hash Join和左表Scan处于同一个Slice内部,即同一个进程中,我们可以直接在进程空间内将Bloom Filter传递给左表Scan算子过滤输出。
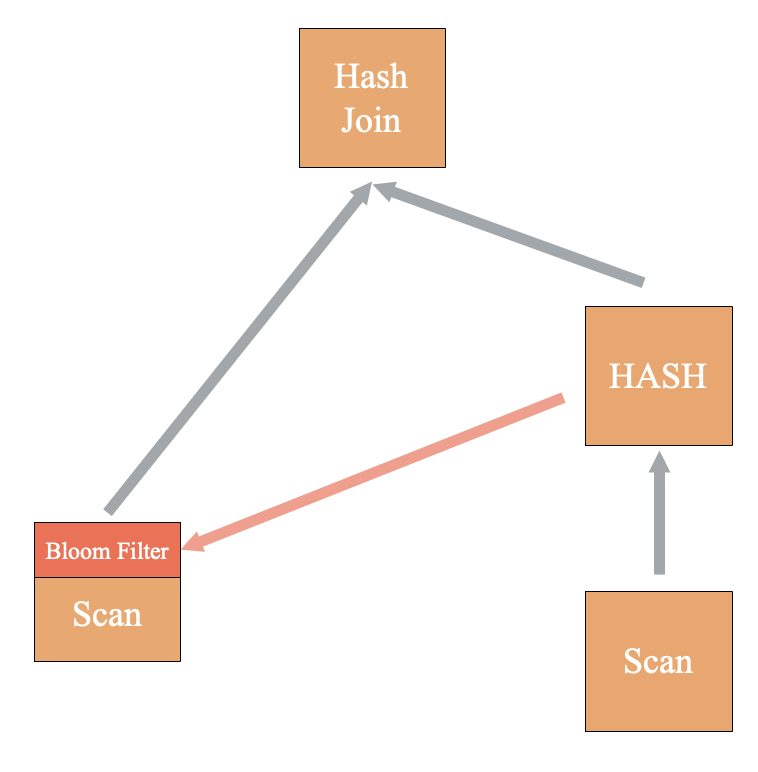
MPP Join
MPP Join是指左右表的Join Key均不满足相同Hash分布,需要针对Join Key Shuffle数据。在前文介绍过,ADB PG的Hash Join和Hash算子一定处于同一个Slice内部,因此基于基本原则只需要考虑左表Shuffle的情况,即左表在Hash Join前存在Motion的场景。
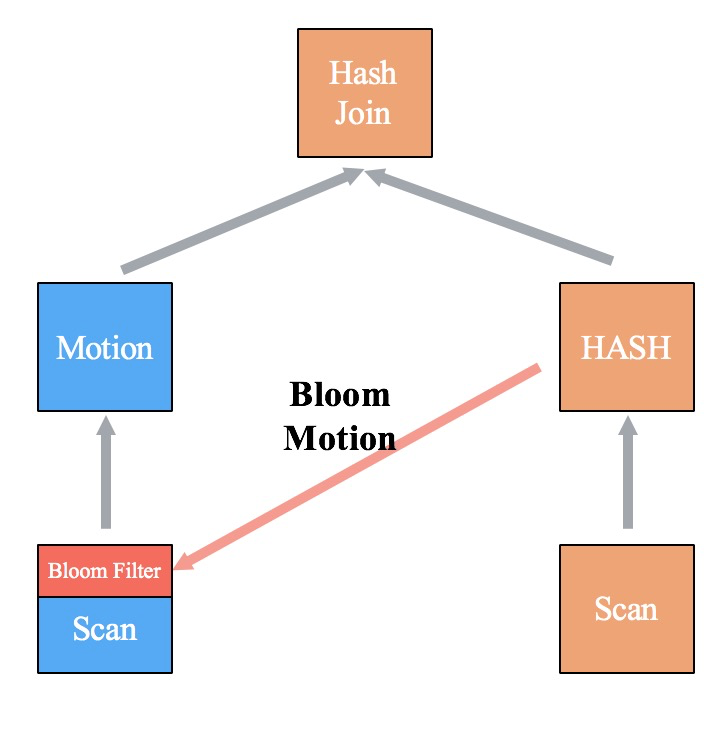
MPP Join存在的另一种情况是,左表Motion下不是简单的Scan,也没有关联信息将Join Key的Bloom Filter下推至Scan。那么以减少网络传输数据量为最后准则,将Bloom Filter过滤放在Motion前,减少Motion Sender的数据。
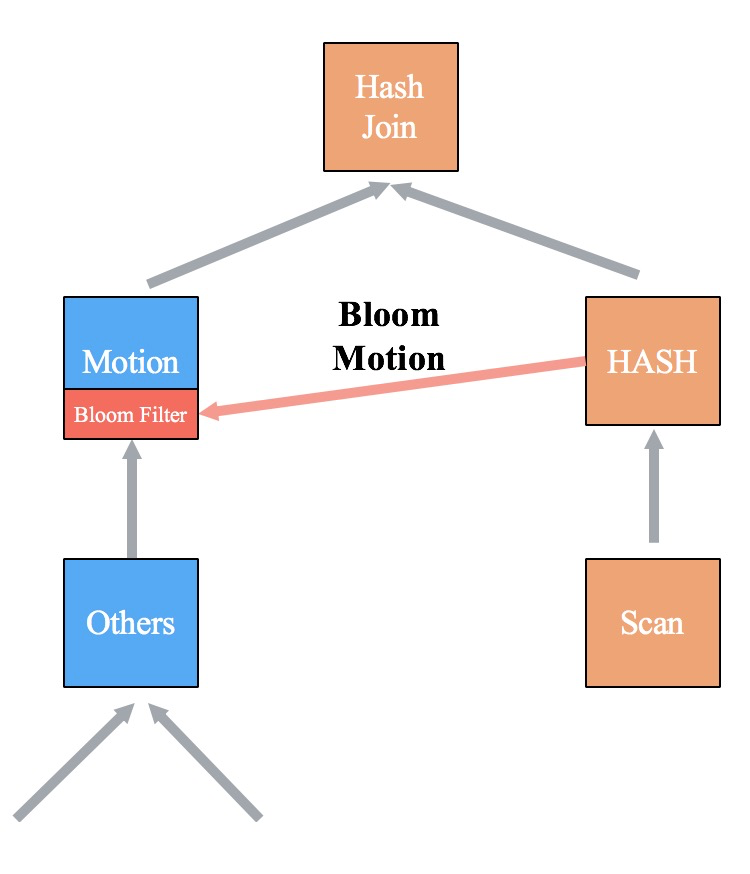
2.Bloom Filter网络传输
Dynamic Join Filter在各个计算节点上建立了一个Local Bloom Filter,每个计算节点需要收集所有其它节点的Bloom Filter,并在本地组成完整的Bloom Filter后才能开始过滤计算。我们将Bloom Filter的收发分为两种模式:全量传输和位传输。在发送前我们可以判断两种模式的数据量大小,并自适应选择数据量小的模式。
Bloom Filter全量传输
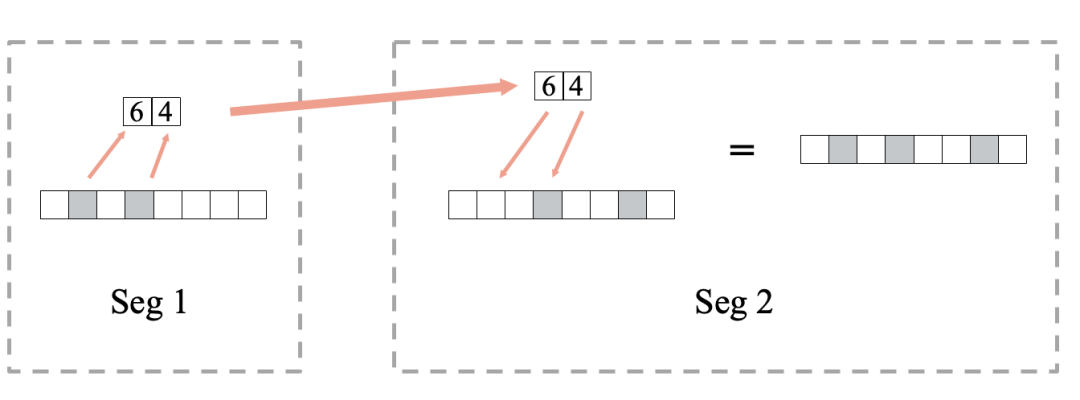
Bloom Filter位传输
性能测试
接下来我们对ADB PG Dynamic Join Filter的性能表现测试。测试集群为ADB PG公有云搭建的实例,测试使用TPC-H 1TB测试集(scale = 10000),测试通过开启\关闭Dynamic Join Filter功能对比执行性能。下图展示了TPC-H执行性能有差异的Query测试结果:
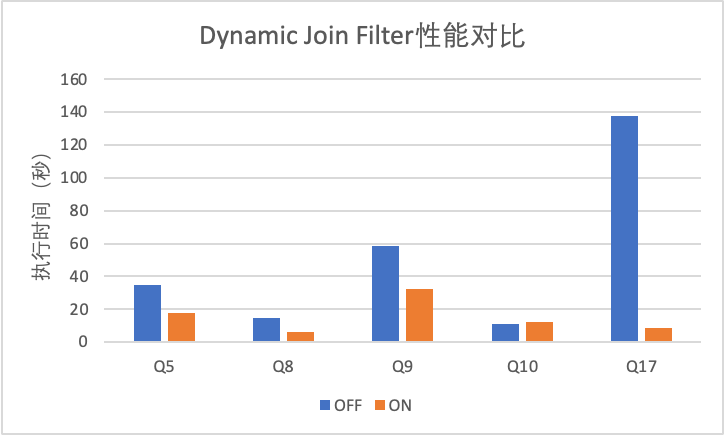
可以看到Dynamic Join Filter在Q5、Q8、Q9和Q17上均获得了较大的性能提升,其中Q17的优化性能最佳,执行时间137s优化至8s。而Q10存在略微的性能回退:10s回退至12s,原因在于Q10的Join Key是完全匹配的,Dynamic Join Filter无法做到动态提前过滤,而优化器未能准确估算代价导致计划仍然使用了Dynamic Join Filter。此外Q20也因为优化器下推规则的的原因没有选择Dynamic Join Filter,实际上经过分析Q20与Q17类似,比较适合使用Dynamic Join Filter。为了解决这些问题,ADB PG优化器相关功能仍在开发迭代中。
总结&未来规划
Dynamic Join Filter根据ADB PG架构设计、存储层和网络层特点,使用Bloom Filter作为Join Runtime Filter的实现形式,在TPC-H测试中取得了明显的性能提升成果。未来我们将从以下几个方面做进一步的开发和优化,提升客户使用体验:
完善Dynamic Join Filter功能,支持各种模式的Hash Join,并进一步推广到Merge Sort Join、NestedLoop Join的优化中;
提升优化器的代价估算模型精度,完善优化器下推规则;
Runtime Filter自适应调度。
欢迎访问云原生数据仓库ADB PG主页,了解更多:https://help.aliyun.com/product/35364.html