数据库->Excel
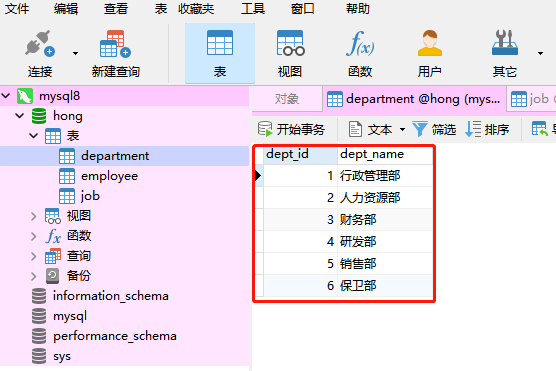
我们首先看一下数据库里面有一个 department这个部门表。这个表里有六条数据,分别代表不同的部门。
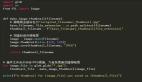
接下来看一下这个Python代码,首先导入需要用到的库SQLAlchemy,这是Python中最有名的ORM工具。
全称Object Relational Mapping(对象关系映射)。
为什么要使用SQLAlchemy?
它可以将你的代码从底层数据库及其相关的SQL特性中抽象出来。
特点是操纵Python对象而不是SQL查询,也就是在代码层面考虑的是对象,而不是SQL,体现的是一种程序化思维,这样使得Python程序更加简洁易读。
具体使用方法如下:
from sqlalchemy import create_engine
import pandas as pd
# 创建数据库连接
engine = create_engine('mysql+pymysql://root:211314@localhost/hong')
# 读取mysql数据
db = pd.read_sql(sql='select * from hong.department', con=engine)
# 导出数据到excel
db.to_excel('部门数据.xlsx')
第一行代码就是首先创建数据库的连接。
我的mysql用户名是root,密码是211314,
因为这里我启动是启动的是本地的数据库服务,所以是localhost。
斜杠后面跟的是这个数据库的名称hong
第二行代码就是使用pandas的read_sql()查询mysql表department中的数据
第二行代码就是将查询出来的数据通过pandas的to_excel()写到本地
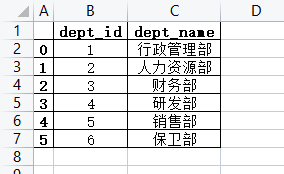
执行结果成功写入本地excel文件
Excel->数据库
接下来我们再看看如何将本地的xlsx数据写入到mysql文件中。
from sqlalchemy import create_engine
import pandas as pd
# 创建数据库连接
engine = create_engine('mysql+pymysql://root:211314@localhost/hong')
# 读取xlsx文件
df = pd.read_excel('模拟数据.xlsx')
# 导入到mysql数据库
df.to_sql(name='test_data', con=engine, index=False, if_exists='replace')
同样第一行代码就是首先创建数据库的连接
第二行代码使用pandas的read_excel()读取本地文件。如下:
这是我用python的faker模拟出来的一百条数据
第三步使用pandas的to_sql()方法将读取到的数据写入到mysql中
代码执行完成后返回mysql中我的hong数据库发现多出了一个test_data的表。
打开看一下。那这个数据就跟本地的数据是一样的。
所以。这里我们用到三行代码从数据库向excel导入数据,又用了三行代码从excel向数据库导入数据。
总结一下:
双向数据导入,都是3行代码即可实现。
从数据库向excel导入数据:
1、用sqlalchemy创建数据库连接
2、用pandas的read_sql读取数据库的数据
3、用pandas的to_csv把数据存入csv文件
从excel向数据库导入数据:
1、用sqlalchemy创建数据库连接
2、用pandas的read_csv读取csv的数据
3、用pandas的to_sql把数据存入数据库a