众所周知,数据仓库的初始架构旨在通过把来自各种异构数据源的数据,收集到集中式的存储库中,以提供分析的见解,并充当决策支持和商业智能(business intelligence,BI)的支点。不过,由于它只能支持写入时模式(schema-on-write),而无法存储非结构化的数据、不能与计算紧密集成、以及只能实现本地设备存储,因此近年来,数据仓库碰到了诸如数据模型设计耗时过长等各种挑战。
尽管目前的数据仓库能够支持以在线分析处理(OLAP)服务器作为中间层的三层架构,但是它仍然属于一种被用于机器学习和数据科学的整合平台。此类平台虽然具有元数据层、缓存层和索引层,但是这些层次并非单独存在。下面,我将向您重点介绍如何改进当前的数据湖平台,并最终将其变成Lakehouse,以增强架构模式,进而改造传统的数据仓库。
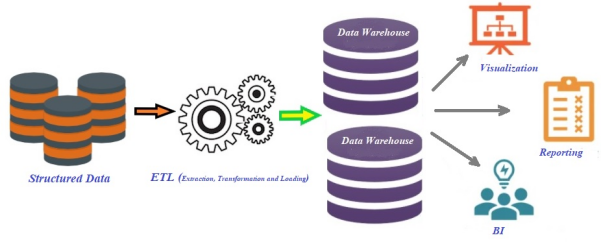
传统数据仓库平台的架构
HDFS
上图展示了传统数据仓库平台的逻辑架构。近年来,随着音频、视频等非结构化数据集的快速增长,许多组织和企业都在寻找和探索某种高级的替代产品,以解决与传统数据仓库系统相关的复杂性问题(正如本文开头所提到的各种痛点)。目前,业界常用的是于2006年面世的Apache Hadoop生态系统。通过利用HDFS(Hadoop分布式文件系统),它解决了在被加载到传统数据仓库系统之前,将原始数据提取并转换为结构化格式(即:行和列的形式)的主要瓶颈问题。
HDFS不但能够处理在商用硬件上运行的大型数据集,而且可以适应通常具有GB和TB体量的数据集应用程序。此外,它还可以通过在集群上添加新的节点,来进行水平扩展,以适应海量的数据,而无需考虑任何数据格式的需求。你可以通过链接—https://dataview.in/installation-of-apache-hadoop-3-2-0/,来进一步了解如何在多节点集群上安装和配置Apache Hadoop。
Hadoop生态系统(Apache Hive)的另一个优势在于,它支持读取时模式(schema-on-read)。由于传统数据仓库具有严格的写入时模式原则,因此ETL(Extract-Transform-Load的缩写)步骤在遵守已设计好的表空间时,非常耗费时间。而通过一行语句,我们可以将数据湖定义为一个存储库,以存储大量原始数据的原生格式(包括:结构化、非结构化和半结构化等),以用于后续分析,预测分析,通过执行机器学习代码与APP,来构建算法等大数据处理操作。
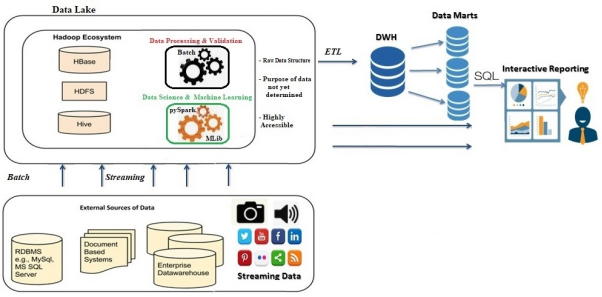
数据湖架构
如上图所示,由于没有适合的数据模式,因此数据湖在加载之前不需要进行任何数据转换,那么如何保持数据质量便成了一个大问题。数据湖并没有完全具备解决数据治理和安全相关问题的能力。因此,机器学习(ML)以及数据科学的应用,需要使用非SQL代码,来处理海量的数据,以便成功地部署和运行在数据湖上。但是与SQL引擎相比,由于缺乏已优化的处理引擎,因此数据湖往往无法很好地服务此类应用。而且,仅靠这些引擎,是不足以解决数据湖的所有问题,甚至取代数据仓库的。此外,数据湖中仍然缺少诸如ACID(原子性,atomicity;一致性,consistency;隔离性,isolation;持久性durability)属性等功能、以及索引等高效的访问方法。据此,构建在它上面的机器学习和数据科学等应用,也会遇到例如数据质量、一致性和隔离性等数据管理问题。因此,数据湖需要额外的工具和技术,来支持SQL查询,以便执行各种商业智能和报告。
Lakehouse
借助着S3、HDFS、Azure Blob等数据湖的处理能力,Lakehouse结合了数据湖的低成本存储优势,以开放的格式为各种系统提供访问,并凸显了数据仓库强大的管理和优化功能。目前,Databricks和AWS都相继引入了数据Lakehouse的概念。
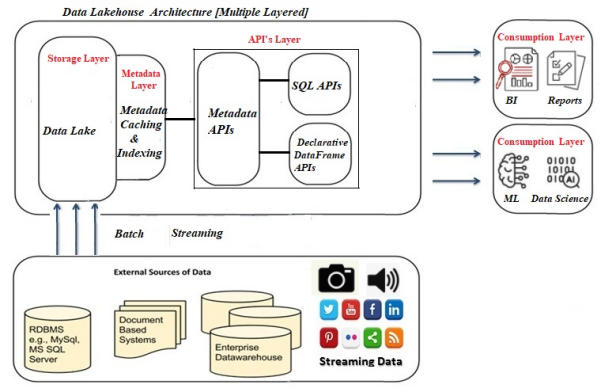
数据Lakehouse架构的多层架构
Lakehouse能够提高各种高级分析负载的速度,并为其提供更好的数据管理功能。如上图所示,Lakehouse通常分为五层,它们分别是摄取层、存储层、元数据层、API 层、以及最后的消费层。
- 摄取层是Lakehouse的第一层,负责从各种来源提取数据,并将其传送到存储层。该层可以使用各种组件来摄取数据。其中包括:用于从IoT设备处流式传输数据的Apache Kafka、用于从关系数据库管理系统(Relational Database Management System,RDBMS)处导入数据的Apache Sqoop、以及支持批量数据处理的更多组件。
- 由于计算层和存储层得到了分离,因此数据Lakehouse最适合云存储库服务。它可以利用HDFS平台在本地得以实施。在设计上,Lakehouse允许开发者将各种数据保存在诸如AWS S3等低成本对象的存储中,并作为使用标准文件格式(例如Apache Parquet)的对象。
- Lakehouse中的元数据层负责为湖存储(lake storage)中的所有对象提供元数据(即,提供有关其他数据片段信息的数据)。此外,它还可以管理如下方面:
- 确保并发各项ACID事务
- 使用更快的存储设备(如,处理节点上的SSD和RAM)缓存来自云服务对象所存储的文件
- 通过索引,以加快查询的速度
- Lakehouses中的API层提供了两种类型的API:声明性DataFrame API和SQL API。在DataFrame API的帮助下,数据科学家可以直接使用数据,来执行他们的各种应用。例如,TensorFlow和Spark MLlib等机器学习代码库,可以读取Parquet等开放的文件格式,并直接查询元数据层。而SQL API可以用于为组合业务分析、数据挖掘、数据可视化等商业智能、以及各种报告类工具,获取数据。
- 最后,消费层包含了诸如Power BI、Tableau等各种工具和应用。整个企业的所有用户都可以使Lakehouse的消费层,来执行各种分析任务。其中包括:商业智能化仪表板、数据可视化、SQL查询、以及机器学习作业等。
此外,Lakehouse架构也最适合在组织内部,为各种数据提供单点式访问。
小结
Lakehouse架构是应对数据提纯的复杂性、查询的兼容性、热数据的缓存等需求产生的。目前,该单体架构尚处于初级阶段。但是,在不久的将来,Lakehouse作为一种数据工具,将能够实现数据发现、数据使用指标、数据治理等更加丰富的功能。
原文标题:The Lakehouse: An Uplift of Data Warehouse Architecture,作者:Gautam Goswami