摘要:本文整理自小红书数据流团队资深研发工程师何军在 Flink Forward Asia 2021 平台建设专场的演讲,介绍了小红书基于 K8s 管理 Flink 任务的建设过程,以及往 Native Flink on K8s 方案迁移过程的一些实践经验。主要内容包括:
- 多云部署架构
- 业务场景
- Helm 集群管理模式
- Native Flink on Kubernetes
- 流批一体作业管控平台
- 未来展望
一、多云部署架构
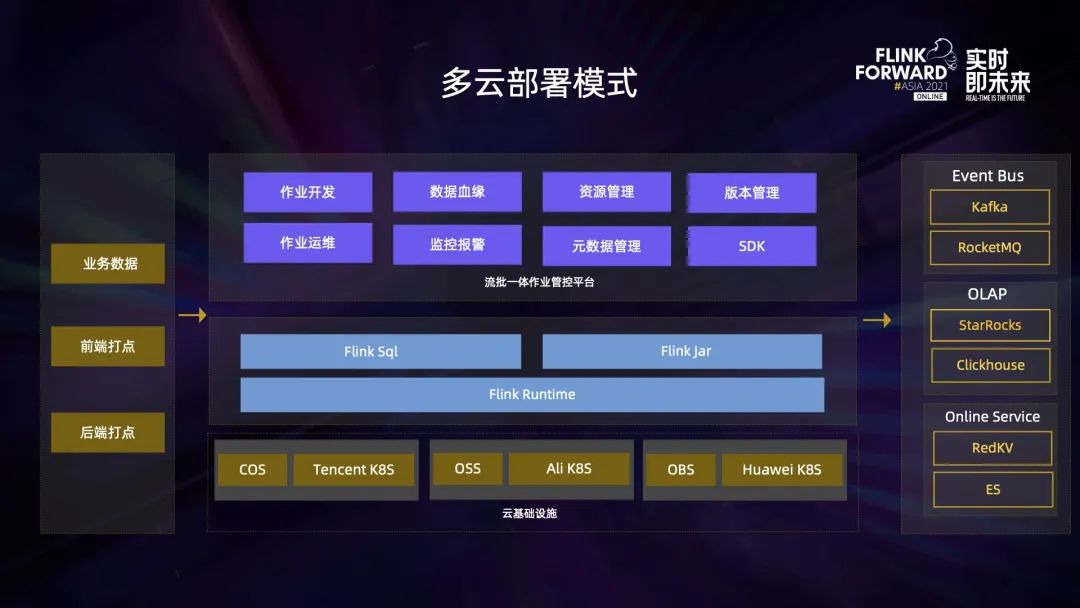
上图是当前 Flink 集群多云部署模式图。业务数据分散在各个云厂商之上,为了适配业务数据处理,Flink 集群自然也进行了多云部署。这些云存储产品一方面用于内部的离线数据存储,另外一方面会用于 Flink 做 checkpoint 存储使用。
在这些云基础设施之上,我们搭建了 Flink 引擎支持 SQL 及 JAR 任务的运行,得益于之前做的一项推动任务 SQL 化的工作,当前内部 SQL 任务和 JAR 任务比例已经达到了 9:1。
在此之上是流批一体作业管控平台,它主要有以下几个功能:作业开发运维、任务监控报警、任务版本管理、数据血缘分析、元数据管理、资源管理等。
平台数据输入主要有以下三个部分,第一部分是业务数据,存在于业务内部的 DB 系统里比如 MySQL 或者 MongoDB,还有一部分是前后端打点数据,前端打点主要是用户在小红书 APP 端的行为日志,后端打点主要是 APP 内部应用程序性能指标相关的数据。这些数据经过 Flink 集群处理之后,会输出到三个主要业务场景中,首先是消息总线,比如 Kafka 集群以及 RocketMQ 集群,其次会输出到 olap 引擎中,比如 StarRocks 或 Clickhouse,最后会输出到在线系统,比如 Redkv 或者 ES 供一些在线查询使用。
二、业务场景
Flink 在小红书内部的应用场景有很多,比如实时反欺诈监控、实时数仓、实时算法推荐、实时数据传输。本章会着重介绍一下其中两个场景。
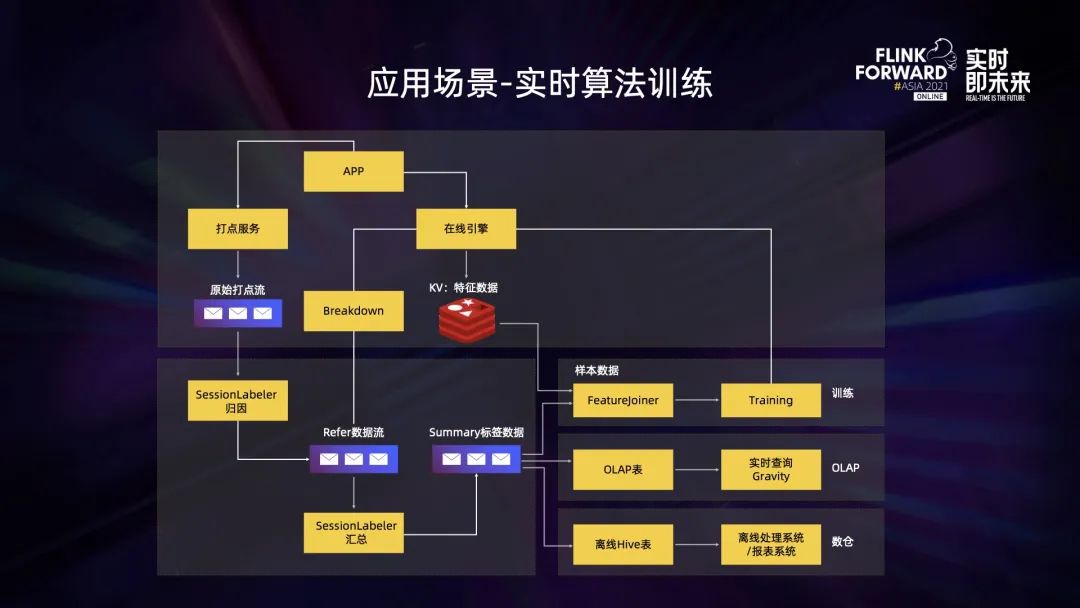
第一个是实时推荐算法训练。上图是推荐算法训练的执行流程。
Flink 集群先接收打点服务采集过来的原始数据,对这一部分数据进行归因并将它写入到 Kafka 集群,之后会再有一个 Flink 任务对这部分数据再做一次汇总,然后得到一个 Summary 的标签数据,针对这个标签数据,后面还有三条实时处理路径:
- 第一,Summary 标签数据会和推荐引擎推荐出来笔记的特征数据进行关联,这个关联也是在 Flink 任务中进行的,内部称其为 FeatureJoiner 任务。接着会产出一个算法训练的样本,这个样本经过算法训练之后产出一个推荐模型,而这个模型最终会反馈到实时推荐引擎中。
- 第二,Summary 标签数据会通过 Flink 实时写到 OLAP 引擎中,比如写到 Hologres 或 Clickhouse 中。
- 最后, Summary 标签数据会通过 Flink 写入到离线 Hive 表中,提供给后续离线报表使用。
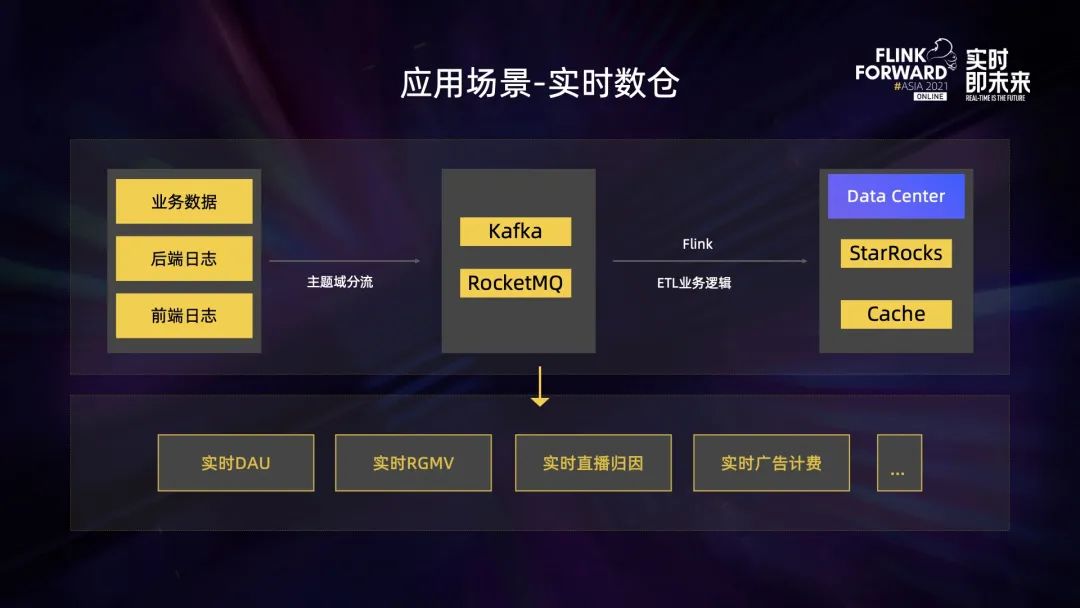
第二个场景是实时数仓。业务数据包括前后端打点的数据,按照业务分流规则进行处理之后会写入到 Kafka 或者 RocketMQ 中,后续 Flink 会对这部分数据做实时 ETL 业务处理,最终进入实时数据中心。目前实时数据中心主要是基于 StarRocks 实现的,StarRocks 是一个性能十分强大的 OLAP 引擎,它承载了公司很多实时相关业务。在数据中心之上,我们还支撑了很多重要实时指标,比如实时 DAU、实时 GMV、实时直播归因、实时广告计费等。
三、Helm 集群管理模式
在正式迁入到 Native Flink on K8s 之前很长一段时间内,都是基于 Helm 来进行集群管理的。Helm 是一个 K8s 上的包管理器,它可以定义、安装和升级 K8s 应用和服务,同时具有以下几个特点:

第一,可以管理比较复杂的 K8s 应用,创建 Flink 集群时会创建很多 K8s 相关的资源,例如 service 或者 config map 以及 Deployment 等, Helm 可以将这些资源统一打包成一个 Helm chart,然后进行统一管理,从而不需要感知每一种资源对应的底层描述文件。
第二,比较方便升级和回滚,只需要执行一条简单命令就可以进行升级或者回滚。同时因为它的代码是和 Flink Client 的代码做了隔离,因此在升级过程中不需要去修改 Flink Client 的代码,实现了代码解耦。
第三,非常易于共享,将 Helm chart 部署在公司私有服务器上之后,已经可以同时支持多个云产品的 Flink 集群管理。
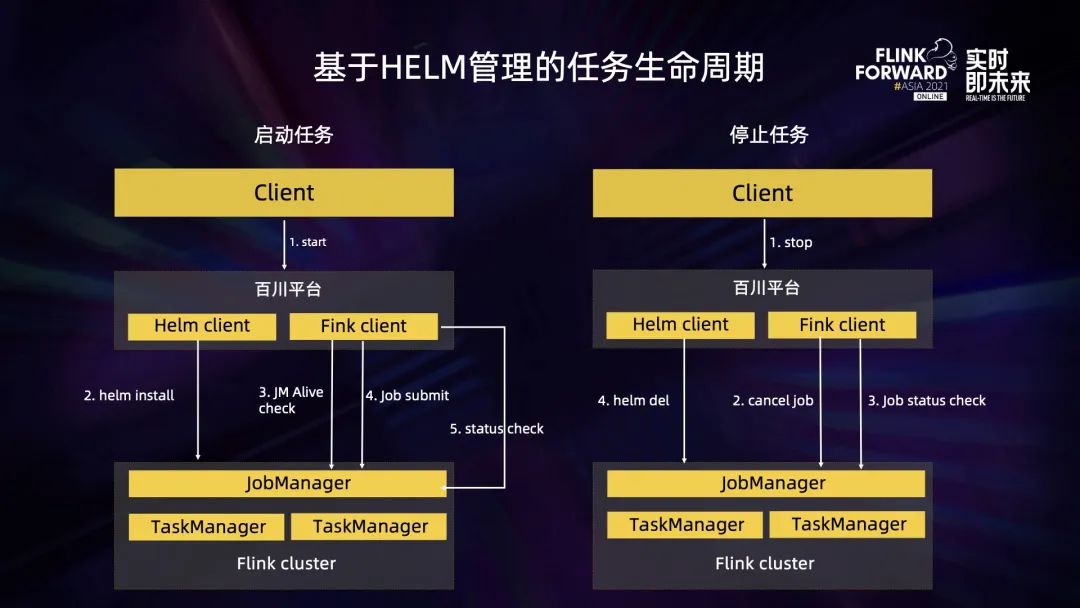
上图是基于 Helm 管理的 Flink 任务生命周期,主要分为启动任务和停止任务两个阶段。这里有三个角色,第一个是 Client,它可以是一个 API 请求,也可以是用户在界面上的一次点击行为。启动任务时,百川平台接收到 API 请求后,会通过 Helm Client 命令去执行 install 指令,创建对应的集群资源,同时内部集成的 Flink Client 也会去检查当前集群的 JobManager 是否启动,如果已经启动就进行 job 提交。job 提交到集群运行起来之后,Flink Client 也会不断地检查当前 job 的运行状态,这也是 Helm 管理模式下作业状态的维护机制。
第二个阶段是任务停止阶段,Client 会向百川平台发起一个 stop 命令,接收到 stop 命令之后百川平台会通过 Flink Client 向 JobManager 发起 cancel 指令,同时检查这个 cancel 指令有没有执行成功,发现 job 被 cancel 之后,会通过 Helm Client 去执行 delete 指令,完成集群资源的销毁。
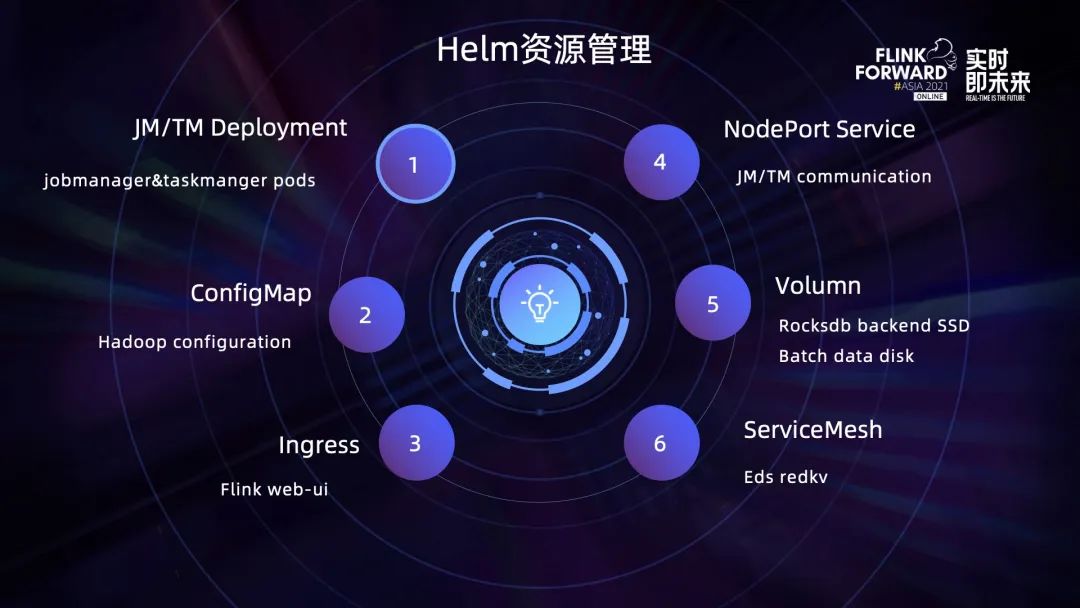
上图展示了通过 Helm 创建了哪些 K8s 资源。
首先是最基础的 JobManager 和 TaskManager Deployment;
第二部分是 ConfigMap,主要是针对 log4j 的配置和各大云厂商提供的云存储产品相关的配置;
第三部分是 Ingress,目前主要用于 Flink web UI 使用以及访问 JobManager 当前任务状态;
第四部分是 Nodeport Service,每启动一个 JobManager,就会在 JM 上启动一个 Nodeport Service,并与 Ingress 做绑定;
第五部分是指磁盘资源,主要有以下两个应用场景:使用 RocksDB Backend 的时候需要去挂载高效云盘、批处理任务需要挂载磁盘做中间数据交换;
最后一部分是 ServiceMesh,TaskManager 内部会通过 sidecar 形式去访问第三方服务,比如说 Redkv service,这些 service 的配置也是在这里面创建的。
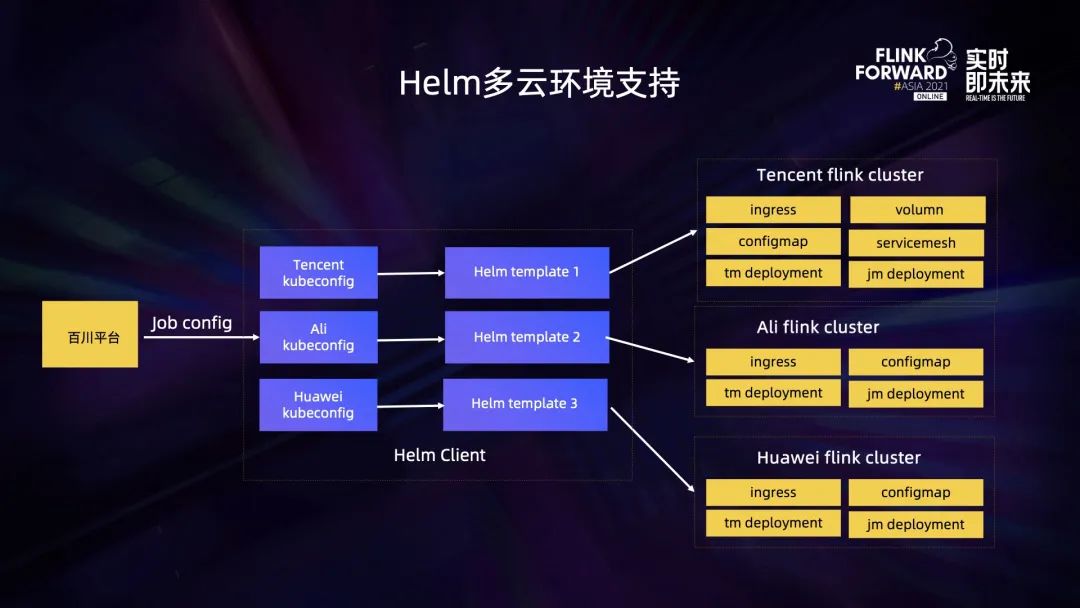
上图可以看到 Helm Client 里面是集成了各大云厂商提供了 K8s 相关的配置,当它接收到创建任务的参数时,会根据这些参数去渲染出不同的 Helm 模板,并提交到不同的云上执行,创建出对应的集群资源。
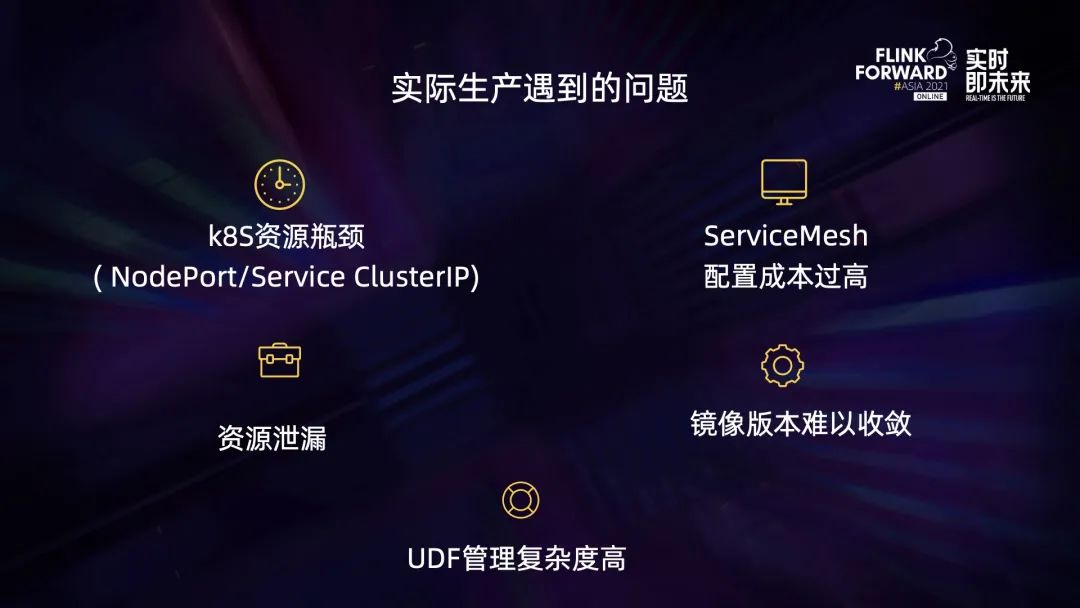
目前的集群管理模式下,在实际生产过程中还是遇到了不少问题:
第一是 K8s 资源瓶颈问题。因为每启动一个 JobManager 就会创建一个 NodePort Service,而这个 Service 会在整个集群范围内占用一个端口和一个 ClusterIP。当作业规模达到一定程度的时候,这些端口资源以及 IP 资源就会遇到性能瓶颈了。
第二个是 ServiceMesh 配置成本过高。上文提到 TaskManager 内部会访问第三方服务,比如说 redkv service,那么每增加一个 redkv service,就需要去修改对应的配置并完成发版,过程的成本是比较高的。
第三个是存在一定的资源泄露问题。所有的资源创建以及销毁都是通过执行 Helm 命令来完成的,在某些异常情况下,job 失败会导致 Helm delete 命令没有被执行,这个时候就有可能会存在资源泄露的问题。
第四个是镜像版本比较难以收敛。在日常的生产过程中,某些线上任务出现了问题,会临时出一个 hotfix 版本镜像并上线运行,久而久之线上就会存在很多版本镜像在运行,这对于后面的运维工作以及问题排查产生了非常大的挑战。
最后一个问题是 UDF 管理复杂度比较高,这是任何分布式计算平台都会遇到的一个问题。
针对上述这些问题,我们在 Native Flink on K8s 模式下一一进行了优化解决。
四、Native Flink on Kubernetes
首先,为什么会选择这种部署模式?因为它具有以下三个特征:

- 更短的 Failover 时间;
- 可以实现资源托管,不需要手动创建 TaskManager 的 pod,也可以自动完成销毁;
- 具有更加便捷的 HA。在 Flink 1.12 之前,实现 JobManager HA 还是依赖于第三方的 zookeeper。但在 Native Flink on K8s 模式下,可以依赖于原生 K8s 的 leader 选举机制来完成 JobManager 的 HA。
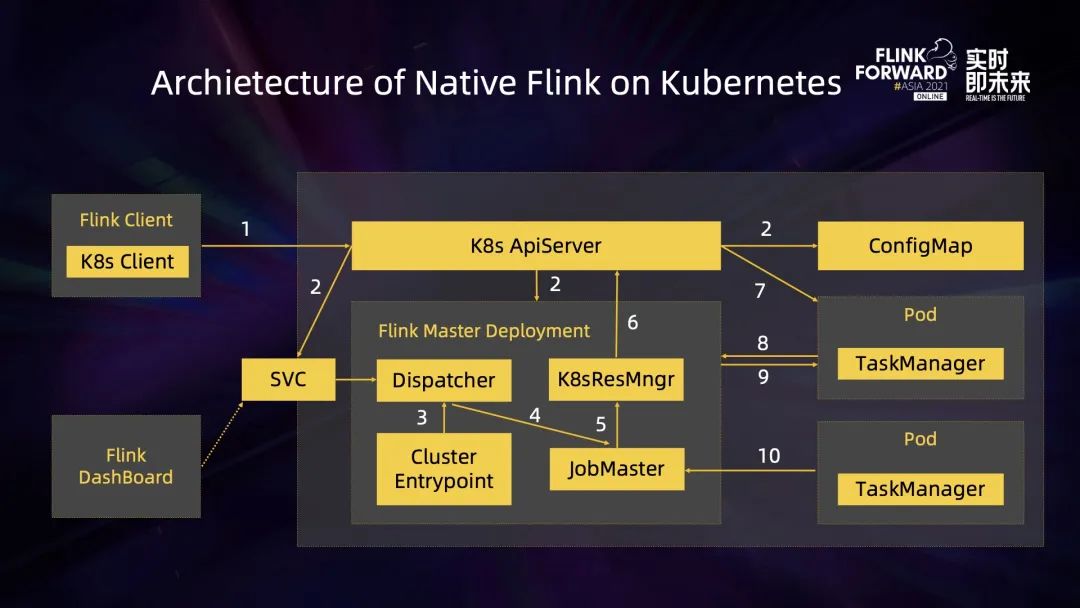
上图是 Native Flink on K8s 的体系架构图。Flink Client 里面集成了一个 K8s Client,它可以直接和 K8s API server 进行通讯,完成 JobManager Deployment 以及 ConfigMap 的创建。JobManager development 创建完成之后,它里面的 resource manager 模块可以直接和 K8s API server 进行通讯,完成 TaskManager pod 的创建和销毁工作,这也是它与传统 session Cluster 模式比较大的不同之处。

内部将 UDF 分为两类:
第一类是平台内置的,将平时的生产工作中经常使用到的 UDF 进行抽象归纳总结,并内置到镜像里面。镜像里有关于 UDF 的配置文件,其中有 UDF 的名称以及类型,同时指定了它对应的实现类。
另外一类是 User-defined UDF,在 Helm 管理模式下,针对用户自定义的 UDF 管理是比较粗放的,将用户 project 下所有 UDF 相关的 JAR 包统一加载到 classloader 下,这会导致类冲突问题。而在 Native Flink 模式下,实现了一个 create function using JAR 的语法,可以按需加载用户所需要的 UDF 对应的 JAR 包,可以极大地缓解类冲突的问题。
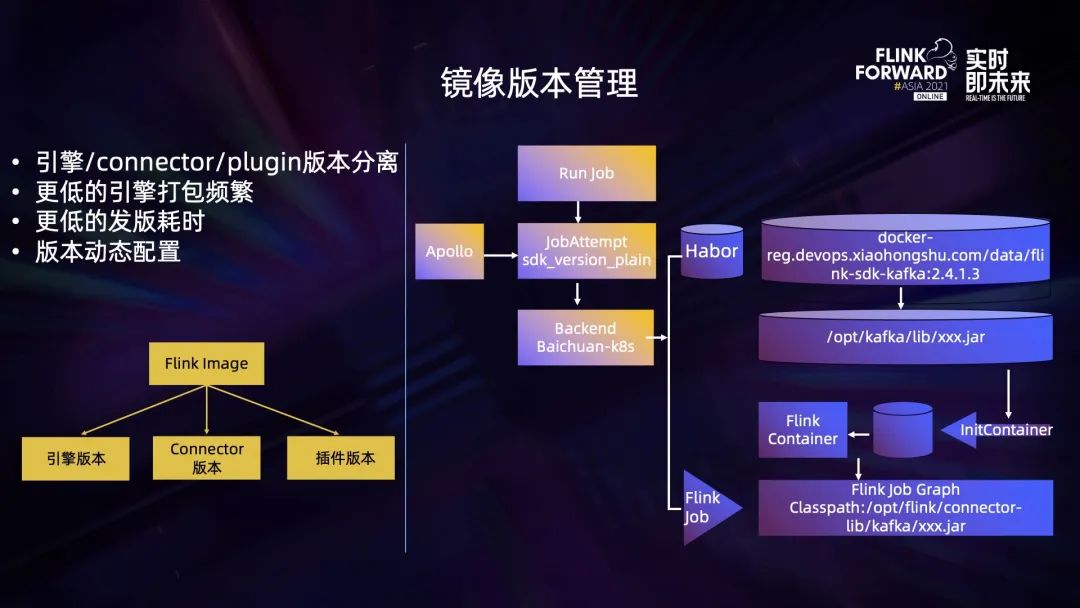
在原有的模式上,镜像管理是通过将所有代码统一打包到一个大的 image 里,但这样会存在一个问题,对任何模块的修改都需要对整个代码库进行一次编译打包,而这个过程是非常耗时的。
在 Native Flink 版本下,针对镜像版本管理做了一些优化,主要是将 Flink 的 image 拆分为了三个部分,分为 Flink engine、connector 以及第三方插件。这三个部分都有各自版本号,并且可以自由进行拼装组合。这项优化降低了引擎打包的频率,也意味着可以提升发版效率。
拆分之后,Flink 如何将这些镜像组合成一个可以运行的镜像呢?下面以加载一个 Kafka SDK 插件为例来进行阐述。job 运行时会从一个动态配置仓库中获取当前这个 job 应该使用的 Kafka SDK 版本,并将其传递给百川的后端,这个 SDK 版本对应了 docker 仓库里面的一个镜像,镜像只包含一个 SDK 对应的 JAR 包,百川的后端在渲染 pod 模板的时候,会在 InitContainer 阶段将 image 加载进来,同时将它 Kafka 的 JAR 包移动到 Flink container 某个指定的目录下去,以此完成加载。
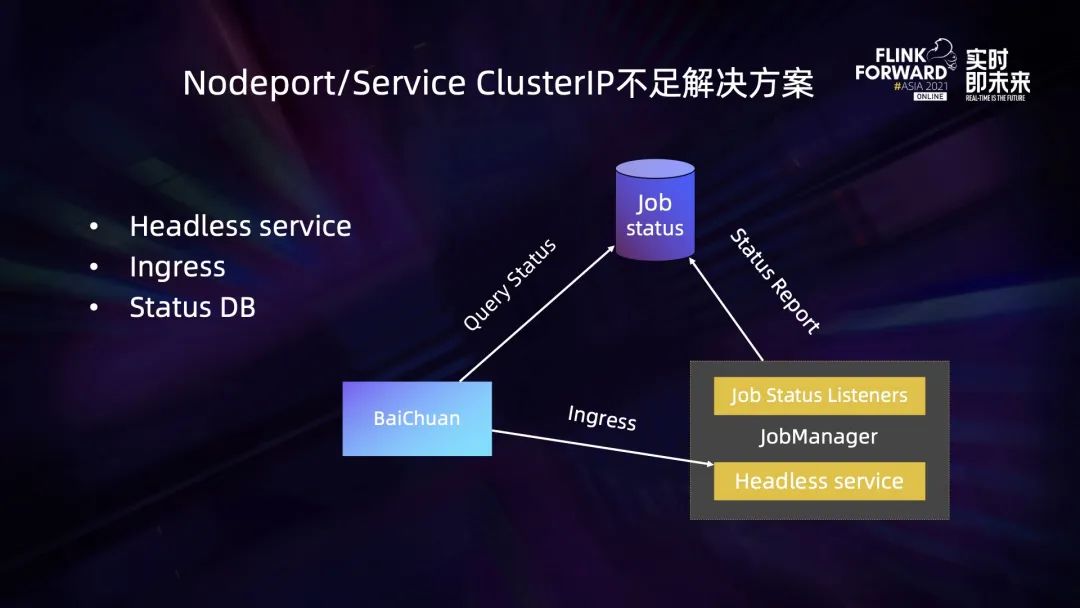
在新的模式下,对 job 状态维护机制做了一次重构,引入了一个 headless 类型的 service 以及一个 status DB。在 JobManager 模块,通过 JobManager status listener 不断监听 job 状态变化,并将这个变化上传到 job ststusDB 中,百川平台可以通过 Query DB 来获取任务的状态。另外在某些场景下,可能因为 job 状态上传失败导致百川无法获取到任务的状态,百川还是可以走原来的路径,通过 Ingress 去访问 JobManager 来获取任务的状态。此时的 Ingress 和之前不同之处在于它绑定的是一个 headless service,不需要占用集群的 Cluster IP,这就解决了之前模式下 K8s ClusterIP 以及 nodePort 不足的问题。
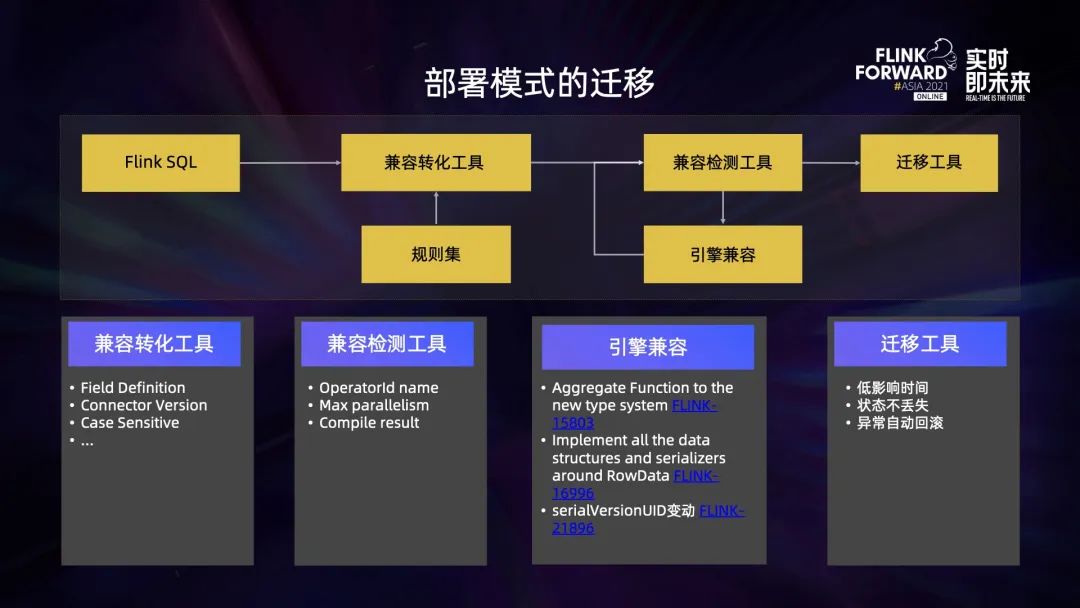
完成上述优化工作以后,面临的最大的问题就是如何将老版本的任务平滑地迁移到新版本 Flink 1.13 上,这其实是一项非常具有挑战性的工作。主要做了以下 4 个方面的工作:
第一,兼容转化工具。这个工具会对 SQL 进行转化,保证 SQL 在 1.13 运行的语法校验不会出错。1.10 到 1.13 经历过几个大版本的变更, SQL 的定义在众多方面已经不兼容,比如在 1.10 和 1.11 的时候,Kafka connector 的取值是 0.11,到 1.13 之后,对应取值已经变成 universal,如果不做任何转化,原始 SQL 肯定在 1.13 上没有办法运行。
第二,兼容检测工具。这个工具的目的是为了检查 SQL 运行在 1.13 的时候能不能从一个低版本的 savepoint 去进行恢复。主要从以下几个方面去做了检查:operator ID 升级之后,名称有没有发生变化;新旧两个版本对应的 max parallelism 有没有发生变化,因为 max parallelism 发生变化的时候,在某部分场景下是没有办法从一个老的 savepoint 来恢复的。
第三,预编译。在 1.13 上对转换之后的 SQL 进行预编译,看编译的结果是否能够正常通过。在兼容检测工具的过程中,也发现了很多从低版本到高版本不兼容的地方,引入了新的数据类型机制,1.11 没有使用 ExternalSerializer,而 1.12 及以后使用 ExternalSerializer 进行包装;BaseRowSerializer 已经在 Flink 1.11 时候改名成了 RowDataSerializer;数据类型里面有一个 seriaVersionUID,之前它是一个随机的 long 类型的数字,而在 1.13 统一固定成了 1。上述种种不兼容会导致 1.13 没有办法直接从一个低版本的 savepoint 来恢复的。因此针对这些问题,在引擎侧做了一些改造。
第四,迁移工具。这个工具的目标主要有以下三点:
首先,对用户作业的影响时间尽可能降到最低,为了达成这个目标,我们对 Native Flink on K8s 的 application mode 做了比较大的改造。原生的 application mode 是一边调度一边申请资源,为了在升级过程中降低对用户作业的影响,实现了 application mode 下可以提前申请好资源并完成 SQL 的编译 (即 JobManager 的预启动),这个过程完成之后,将旧的 job 停掉然后启动新的 job,整个过程对用户作业的影响能够控制在 30 秒以内 (中等规模任务)。
其次,在迁移的过程中要保证状态不丢失,因为所有迁移都是基于 savepoint 来启动的,所以这块的数据是不会有任何丢失的。
最后,如果在升级过程中发生了异常,可以支持异常情况下自动完成回滚。

在实际 Application mode 应用过程中,也发现了原生 Flink 的一些问题,并做了对应的处理方案。
例如 JobManager 在 failover 的时候会重新拉起一批新的 TM,会导致 TaskManager 的资源翻倍。如果资源池的资源不足以满足 double 的需求,就有可能导致 failover 失败。此外,即使这一次 failover 成功了,但是新启动的 job 会基于首次启动时指定的 recover path 来进行恢复,这个时候的位点可能已经是一个十天以前的位点了,这会导致数据重复消费的问题。针对这个问题,在检测到 JobManager 发生 failover 的时候就会在引擎侧直接将 job fail 掉并告警,然后通过人工手动介入来处理。
五、流批一体作业管控平台

流批一体作业管控平台主要提供了以下几个模块的功能:作业开发及运维、版本管理、监控报警、资源管理、数据血缘、元数据管理以及 SDK。其中资源管理主要分为资源隔离和资源推荐,数据血缘主要用于展示 Flink 任务上下游之间的关系,元数据管理主要是针对用户 catalog 表。
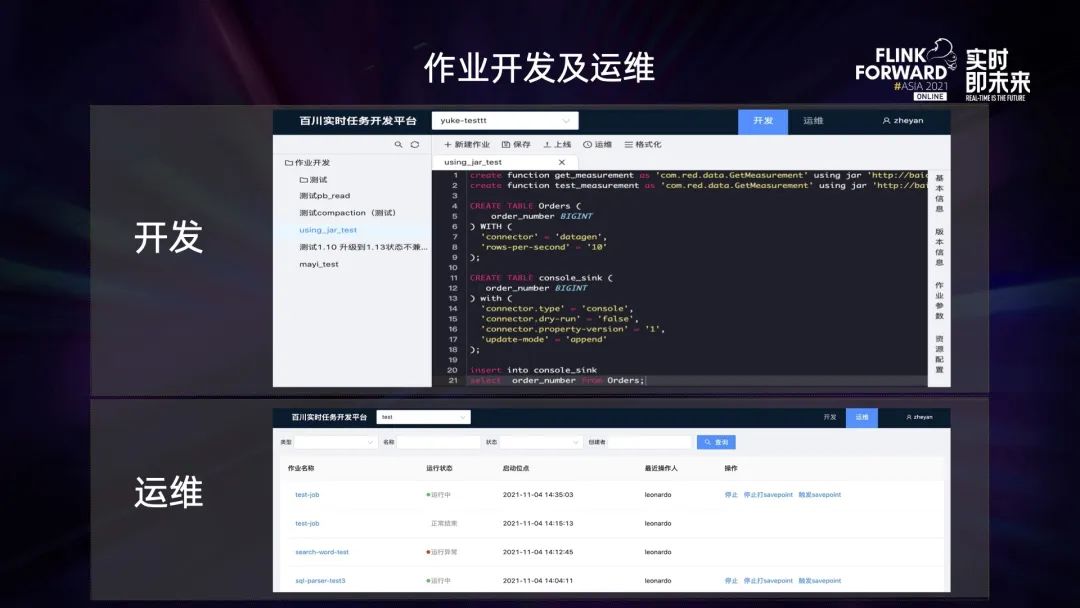
上图上半部分是 SQL 开发界面,页面的主体部分 SQL 编辑器,右侧有任务的基本信息、版本信息、作业参数以及一些资源配置相关的界面元素。
下半部分是任务运维界面,上面提供了很多常规操作,比如停止任务,或先打 savepoint 再停止任务等。
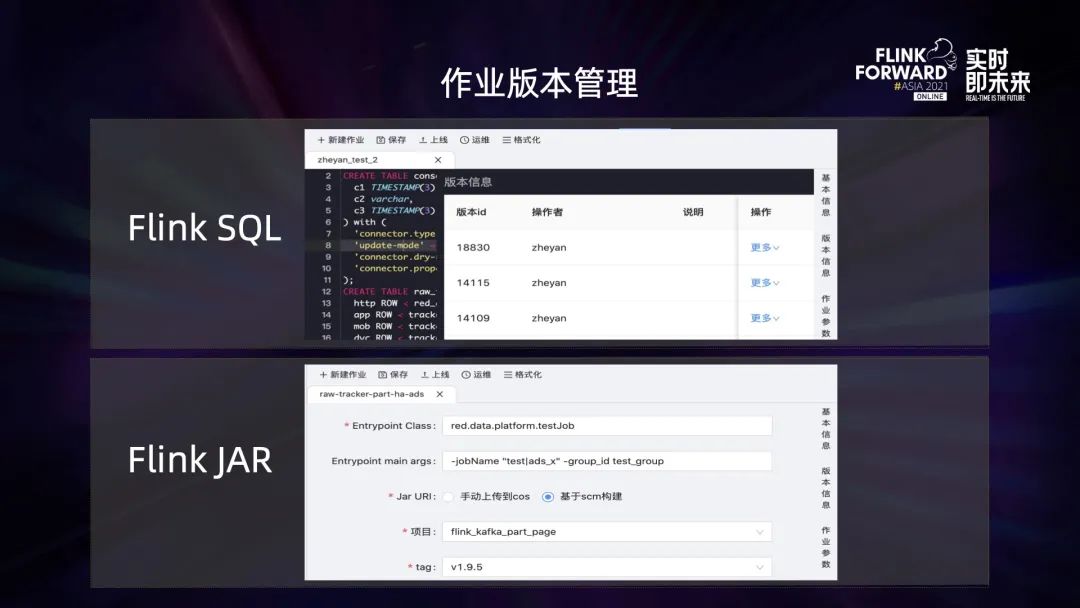
作业版本管理分为 Flink SQL 任务以及 Flink JAR 任务。在 SQL 任务界面上可以看到 SQL 经历过很多次发版,“更多” 按钮提供了回滚操作。针对 Flink JAR 任务,目前有两种提交 JAR 任务的方法,可以直接将用户的 JAR 包上传到一个分布式存储路径,也可以通过指定代码仓库 tag 来指定 JAR 包的版本。
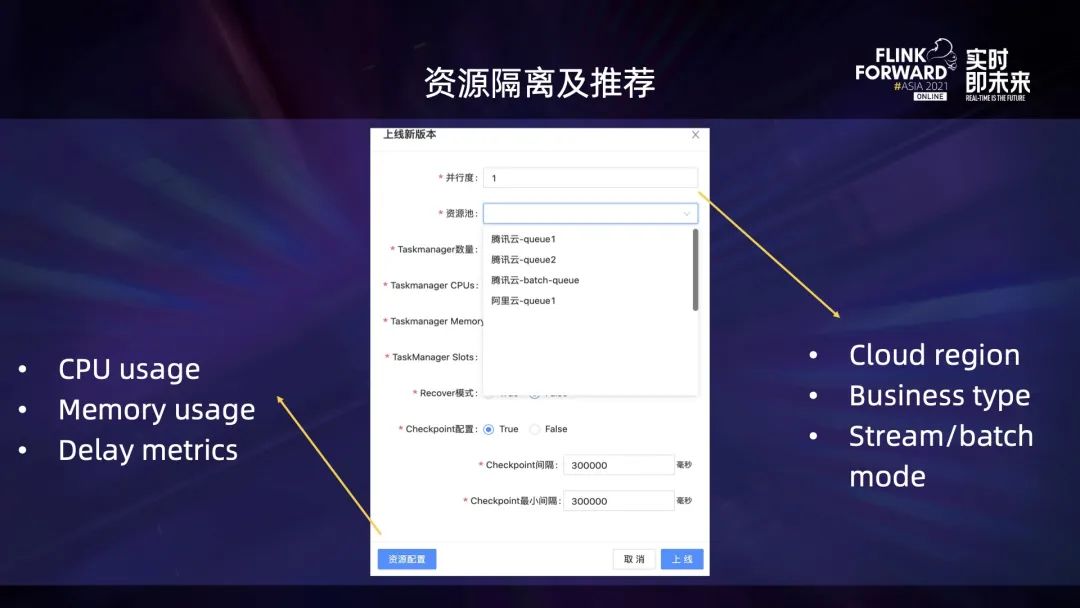
资源管理主要分为资源隔离和资源推荐。这里引入了资源池的概念,并基于以下几个维度做了切分:
- 第一个因素是它运行所属的云环境;
- 第二个因素是业务类型;
- 第三个因素是资源池提供给流还是批任务使用。
另外,针对已经运行一段时间的任务,会结合它历史运行期间的 CPU、内存、延迟 lag 等指标信息,给出当前任务所需要的最佳 K8s 资源配置推荐结果。

Rugal 调度平台是公司内部一个对标 airflow 的产品,它可以通过百川提供的 SDK 定时创建任务提交到百川平台。上图左侧是一个 SQL 编辑模板,其中的很多参数信息都是通过变量的形式来展示。调用 SDK 的时候,可以将这些变量对应的实际值传入进来,并用这些值渲染出具体要执行的 SQL,从而生成具体的执行实例。
六、未来展望

最后是对未来工作的规划。
第一,动态资源调整。目前, Flink job 一旦提交运行,就无法在运行期间修改某个 operator 占用的资源。所以希望未来能够在 job 不进行 restart 的情况下,调整某个算子所占用的资源。
第二,跨云多活方案。目前公司核心 P0 作业基本都是双链路的,但都仅限于在单朵云上。希望针对这些核心任务,实现跨云双活方案,其中一个云上任务出现问题的时候,能够稳定切换到另外一朵云上。
第三,批任务资源调度优化。因为批任务大多是在凌晨以后开始执行,同时会调度很多任务,有的任务可能因为抢占不到资源导致无法及时运行,在任务调度执行策略上仍有可以优化的空间。