













今天和研发团队沟通一个数据存储方案的设计和改造,大体的背景是在数据库中有些id类数据,如果数据类型是int,则存在一定的溢出风险,在程序层面需要提前考虑修改为int64,在MySQL中可以简单理解为bigint.
我们假设这个id字段为uid,如果是用户业务,则很多业务逻辑都是和这个uid强相关的,那么就会存在大量的业务梳理和研发代码的接入,如果底层数据存储的压力和风险过大,则这个事情的改进周期和影响范围就会更难以评估和控制。
所以这个问题从长期来看是未雨绸缪,对已有的数据存储是完全兼容的。但是从短期来看,这个调整会对已有的线上服务带来一些风险,如果涉及到约束的变更,则这个事情的复杂度会更高。为此我们经过沟通,想到了如下的几类解决方案:
1)新增字段uid_64,这样已有的业务逻辑可以正常运行,新的字段可以并行调整,当然从数据存储来看,这个代价是比较高了,而且后续调整为uid_64之后很可能需要再统一为uid的模式,所以从研发还是数据存储来说,改造幅度都比较大。
2)在线变更,这里我说的在线变更拆分为了4类场景。
场景1:
对于一些复杂度较为可控的业务,数据量也不够大,采用在线变更的模式是比较合适的,这里我们可以使用online DDL,pt-osc或者gh-ost的方式来实现在线变更;
场景2:
对于一些较为复杂的业务,如MySQL集群,采用了分库分表,数据量可能在亿级别,这种变更的复杂度就比较大了,而且可以肯定的是在线变更对于复杂架构模式的风险大,而且不可控因素会更多,这里可以采用更好的应用架构设计,基于高可用灵活切换的方式,比如整个结构的变更都可以在从库端进行统一调整,因为这种数据类型的扩容是具备兼容性的,所以原生的复制不会产生直接影响,而且即使执行时间长一些,对于线上业务来说是几乎无感知的,等变更完成之后,就可以快速通过服务切换的方式将集群从原本的主库切换到从库,这个过程是需要主动触发,如果是秒级的异常,会对研发来说是直接反馈,这种情况下反而是好事。这个过程涉及的细节较多,核心思想就是从库,异步,高可用切换;
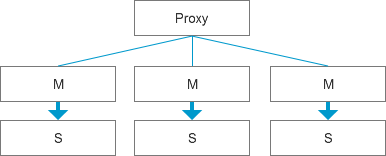
场景3:
对于流水日志的处理方式,采用T+1的模式对于研发侧来说是几乎不需要修改主干业务逻辑就可以适配的。
场景4:
这一类场景较为复杂,比如在业务中会有不规范的使用方式,对于不规范导致的列名不是uid的情况,比如从xid修改为uid,在数据库和研发侧的修改代价都是比较高的,这种情况下,我是不建议使用在线变更的模式
3)业务在线迁移
这一类场景对于后端数据存储是相对简单的,就是提供一个新的数据库,让业务来完成整体的迁移和切换,这种情况下,对于研发的能力要求较高,所有的关键操作都是通过研发在线迁移的方式来实现。
综上的三种方案,我是建议根据场景来灵活适配,比如方案2和方案3来组合的形式。如果后端的数据存储在梳理中修改范围更加的庞大,则需要根据细化的业务场景来选择当前更合适的方案。



















