引言
对于一个软件平台来说,软件平台代码的好坏直接影响平台整体的质量与稳定性。同时也会影响着写代码同学的创作激情。想象一下如果你从git上面clone下来的的工程代码乱七八糟,代码晦涩难懂,难以快速入手,有种想推到重写的冲动,那么程序猿在这个工程中写好代码的初始热情都没了。相反,如果clone下的代码结构清晰,代码优雅易懂,那么你在写代码的时候都不好意思写烂代码。这其中的差别相信工作过的同学都深有体会,那么我们看了那么多代码之后,到底什么样的代码才是好代码呢?它们有没有一些共同的特征或者原则?本文通过阐述优雅代码的设计原则来和大家聊聊怎么写好代码。
代码设计原则
好代码是设计出来的,也是重构出来的,更是不断迭代出来的。在我们接到需求,经过概要设计过后就要着手进行编码了。但是在实际编码之前,我们还需要进行领域分层设计以及代码结构设计。那么怎么样才能设计出来比较优雅的代码结构呢?有一些大神们总结出来的优雅代码的设计原则,我们分别来看下。
SRP
所谓SRP(Single Responsibility Principle)原则就是职责单一原则,从字面意思上面好像很好理解,一看就知道什么意思。但是看的会不一定就代表我们就会用,有的时候我们以为我们自己会了,但是在实际应用的时候又会遇到这样或者那样的问题。原因就是实际我们没有把问题想透,没有进行深度思考,知识还只是知识,并没有转化为我们的能力。就比如这里所说的职责单一原则指的是谁的单一职责,是类还是模块还是域呢?域可能包含多个模块,模块也可以包含多个类,这些都是问题。
为了方便进行说明,这里以类来进行职责单一设计原则的说明。对于一个类来说,如果它只负责完成一个职责或者功能,那么我们可以说这个类时符合单一职责原则。请大家回想一下,其实我们在实际的编码过程中,已经有意无意的在使用单一职责设计原则了。因为实际它是符合我们人思考问题的方式的。为什么这么说呢?想想我们在整理衣柜的时候,为了方便拿衣服我们会把夏天的衣服放在一个柜子中,冬天的衣服放在一个柜子。这样季节变化的时候,我们只要到对应的柜子直接拿衣服就可以了。否则如果冬天和夏天的衣服都放在一个柜子中,我们找衣服的时候可就费劲了。放到软件代码设计中,我们也需要采用这样的分类思维。在进行类设计的时候,要设计粒度小、功能单一的类,而不是大而全的类。
举个栗子,在学生管理系统中,如果一个类中既有学生信息的操作比如创建或者删除动作,又有关于课程的创建以及修改动作,那么我们可以认为这个类时不满足单一职责的设计原则的,因为它将两个不同业务域的业务混杂在了一起,所以我们需要进行拆分,将这个大而全的类拆分为学生以及课程两个业务域,这样粒度更细,更加内聚。
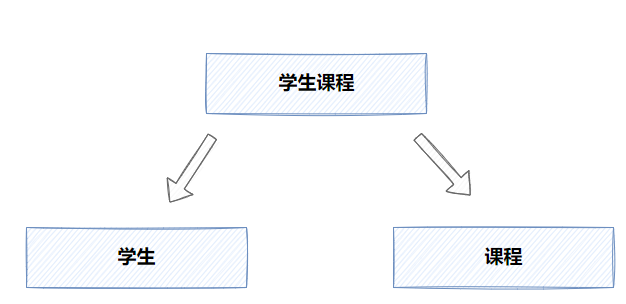
笔者根据自身的经验,总结了需要考虑进行单一职责拆分的几个原则,希望对大家判断是否需要进行拆分有个简单的判断的标准:
1、不同的业务域需要进行拆分,就像上面的例子,另外如果与其他类的依赖过多,也需要考虑是不是应该进行拆分;
2、如果我们在类中编写代码的时候发现私有方法具有一定的通用性,比如判断ip是不是合法,解析xml等,那我们可以考虑将这些方法抽出来形成公共的工具类,这样其他类也可以方便的进行使用。
另外单一职责的设计思想不止在代码设计中使用,我们在进行微服务拆分的时候也会一定程度的遵循这个原则。
OCP
OCP(Open Closed Principle)即对修改关闭,对扩展开放原则,个人觉得这是设计原则中最难的原则。不仅理解起来有一定的门槛,在实际编码过程中也是不容易做到的。
首先我们得先搞清楚这里的所说的修改以及扩展的区别在什么地方,说实话一开始看到这个原则的时候,我总觉得修改和开放说的不是一个意思嘛?想来想去都觉得有点迷糊。后来在不断的项目实践中,对这个设计原则的理解逐渐加深了。
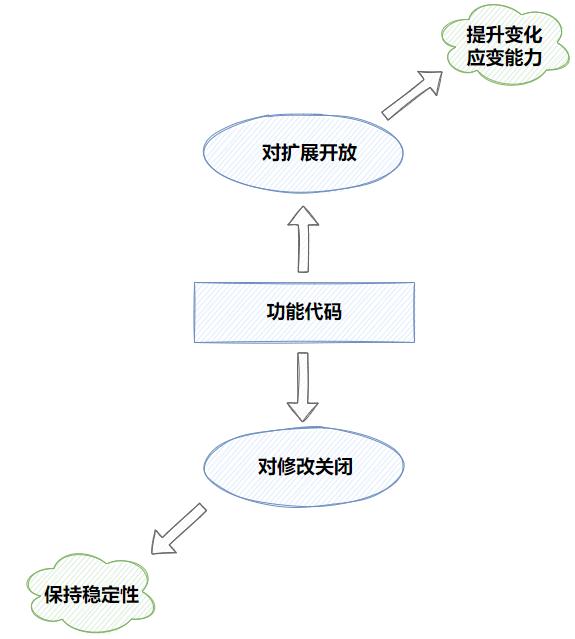
设计原则中所说的修改指的是对原有代码的修改,而扩展指的是在原有代码基础上的能力的扩展,并不修改原先已有的代码。这是修改与扩展的最大的区别,一个需要修改原来的代码逻辑,另一个不修改。因此才叫对修改关闭但是对扩展开放。弄清楚修改和扩展的区别之后,我们再想一想为什么要对修改关闭,而要对扩展开放呢?我们都知道软件平台都是不断进行更新迭代的,因此我们需要不断在原先的代码中进行开发。那么就会涉及到一个问题如果我们的代码设计的不好,扩展性不强,那么每次进行功能迭代的时候都会修改原先已有的代码,有修改就有可能引入bug,造成系统平台的不稳定。因此我们为了平台的稳定性,需要对修改关闭。但是我们要添加新的功能怎么办呢?那就是通过扩展的方式来进行,因此需要实现对扩展开放。
这里我们以一个例子来进行说明,否则可能还是有点抽象。在一个监控平台中,我们需要对服务所占用CPU、内存等运行信息进行监控,第一版代码如下。
public class Alarm {
private AlarmRule alarmRule;
private AlarmNotify alarmNotify;
public Alarm(AlarmRule alarmRule, AlarmNotify alarmNotify) {
this.alarmRule = alarmRule;
this.alarmNotify = alarmNotify;
}
public void checkServiceStatus(String serviecName, int cpu, int memory) {
if(cpu > alarmRule.getRule(ServiceConstant.Status).getCpuThreshold) {
alarmNotify.notify(serviecName + alarmRule.getRule(ServiceConstant.Status).getDescription)
}
if(memory > alarmRule.getRule(ServiceConstant.Status).getMemoryThreshold) {
alarmNotify.notify(serviecName + alarmRule.getRule(ServiceConstant.Status).getDescription)
}
}
}
代码逻辑很简单,就是根据对应的告警规则中的阈值判断是否达到触发告警通知的条件。如果此时来了个需求,需要增加判断的条件,就是根据服务对应的状态,判断需不需要进行告警通知。我们来先看下比较low的修改方法。我们在checkServiceStatus方法中增加了服务状态的参数,同时在方法中增加了判断状态的逻辑。
public class Alarm {
private AlarmRule alarmRule;
private AlarmNotify alarmNotify;
public Alarm(AlarmRule alarmRule, AlarmNotify alarmNotify) {
this.alarmRule = alarmRule;
this.alarmNotify = alarmNotify;
}
public void checkServiceStatus(String serviecName, int cpu, int memory, int status) {
if(cpu > alarmRule.getRule(ServiceConstant.Status).getCpuThreshold) {
alarmNotify.notify(serviecName + alarmRule.getRule(ServiceConstant.Status).getDescription)
}
if(memory > alarmRule.getRule(ServiceConstant.Status).getMemoryThreshold) {
alarmNotify.notify(serviecName + alarmRule.getRule(ServiceConstant.Status).getDescription)
}
if(status == alarmRule.getRule(ServiceConstant.Status).getStatusThreshold) {
alarmNotify.notify(serviecName + alarmRule.getRule(ServiceConstant.Status).getDescription)
}
}
}
很显然这种修改方法非常的不友好,为什么这么说呢?首先修改了方法参数,那么调用该方法的地方可能也需要修改,另外如果改方法有单元测试方法的话,单元测试用例必定也需要修改,在原有测试过的代码中添加新的逻辑,也增加了bug引入的风险。因此这种修改的方式我们需要进行避免。那么怎么修改才能够体现对修改关闭以及对扩展开放呢?
首先我们可以先将关于服务状态的属性抽象为一个ServiceStatus 实体,在对应的检查方法中以ServiceStatus 为入参,这样以后如果还有服务状态的属性增加的话,只需要在ServiceStatus 中添加即可,并不需要修改方法中的参数以及调用方法的地方,同样单元测试的方法也不用修改。
@Data
public class ServiceStatus {
String serviecName;
int cpu;
int memory;
int status;
}
另外在检测方法中,我们怎么修改才能体现可扩展呢?而不是在检测方法中添加处理逻辑。一个比较好的实现方式就是通过抽象检测方法,具体的实现在各个实现类中。这样即使新增检测逻辑,只需要扩展检测实现方法就可,不需要在修改原先代码的逻辑,实现代码的可扩展。
LSP
LSP(Liskov Substitution Principle)里氏替换原则,这个设计原则我觉得相较于前面的两个设计原则来说要简单些。它的内容为子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏。
里式替换原则是用来指导,继承关系中子类该如何设计的一个原则。理解里式替换原则,最核心的就是理解“design by contract,按照协议来设计”这几个字。父类定义了函数的“约定”(或者叫协议),那子类可以改变函数的内部实现逻辑,但不能改变函数原有的“约定”。这里的约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至包括注释中所罗列的任何特殊说明。
我们怎么判断有没有违背LSP呢?我觉得有两个关键点可以作为判断的依据,一个是子类有没有改变父类申明需要实现的业务功能,另一个是否违反父类关于输入、输出以及异常抛出的规定。
ISP
ISP(Interface Segregation Principle)接口隔离原则,简单理解就是只给调用方需要的接口,它不需要的就不要硬塞给他了。这里我们举个栗子,以下是关于产品的接口,其中包含了创建产品、删除产品、根据ID获取产品以及更新产品的接口。如果此时我们需要对外提供一个根据产品的类别获取产品的接口,我们应该怎么办?很多同学会说,这还不简单,我们直接在这个接口里面添加根据类别查询产品的接口就OK了啊。大家想想这个方案有没有什么问题。
public interface ProductService {
boolean createProduct(Product product);
boolean deleteProductById(long id);
Product getProductById(long id);
int updateProductInfo(Product product);
}
public class UserServiceImpl implements UserService { //...}
这个方案看上去没什么问题,但是再往深处想一想,外部系统只需要一个根据产品类别查询商品的功能,,但是实际我们提供的接口中还包含了删除、更新商品的接口。如果这些接口被其他系统误调了可能会导致产品信息的删除或者误更新。因此我们可以将这些第三方调用的接口都隔离出来,这样就不存在误调用以及接口能力被无序扩散的情况了。
public interface ProductService {
boolean createProduct(Product product);
boolean deleteProductById(long id);
Product getProductById(long id);
int updateProductInfo(Product product);
}
public interface ThirdSystemProductService{
List<Product> getProductByType(int type);
}
public class UserServiceImpl implements UserService { //...}
LOD
LOD(Law of Demeter)即迪米特法则,这是我们要介绍的最后一个代码设计法则了,光从名字上面上看,有点不明觉厉的感觉,看不出来到底到底想表达什么意思。我们可以来看下原文是怎么描述这个设计原则的。
Each unit should have only limited knowledge about other units: only units “closely” related to the current unit. Or: Each unit should only talk to its friends; Don’t talk to strangers.
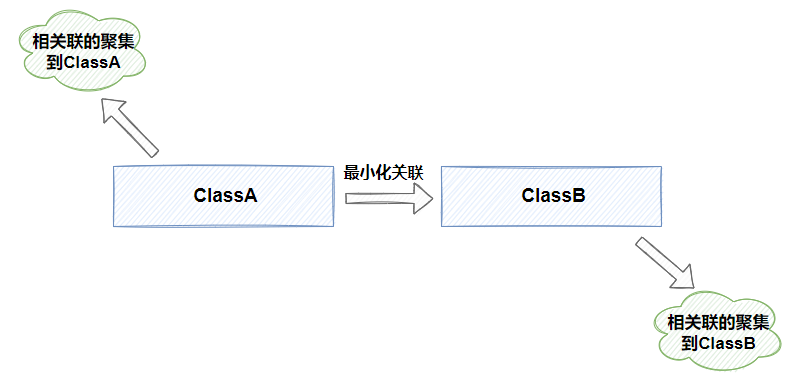
按照我自己的理解,这迪米特设计原则的最核心思想或者说最想达到的目的就是尽最大能力减小代码修改带来的对原有的系统的影响。所以需要实现类、模块或者服务能够实现高内聚、低耦合。不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。迪米特法则是希望减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。打个比方这就像抗战时期的的地下组织一样,相关联的聚合到一起,但是与外部保持尽可能少的联系,也就是低耦合。
总结
本文总结了软件代码设计中的五大原则,按照我自己的理解,这五大原则就是程序猿代码设计的内功,而二十三种设计模式实际就是内功催生出来的编程招式,因此深入理解五大设计原则是我们用好设计模式的基础,也是我们在平时设计代码结构的时候需要遵循的一些常见规范。只有不断的在设计代码-》遵循规范-》编写代码-》重构这个循环中磨砺,我们才能编写出优雅的代码。