介绍使用索引、临时表 + 文件排序实现 group by,以及单独介绍临时表的三篇文章中,多次以 count(distinct) 作为示例说明。
那还有必要单独为 count(distinct) 写一篇文章吗?
此刻,想到一句台词:别问,问就是有必要。
回到正题,MySQL 使用 MEMORY 引擎临时表实现 count(distinct) 的去重功能时,玩出了新花样,所以,还是值得写一下的。背景说明到此为止,我们快快开始。
本文内容基于 MySQL 5.7.35 源码。
1、 概述
如果 count(distinct) 不能使用索引去重,就需要使用临时表。临时表的存储引擎有三种选择:MEMORY、MyISAM、InnoDB。
和使用 MyISAM 或 InnoDB 作为临时表的存储引擎处理逻辑有些不一样,如果 MySQL 决定使用 MEMORY 作为临时表的存储引擎,临时表会被创建,但只是作为辅助,表里不会写入任何数据。
要说清楚为什么会有这种花样操作,需要从 MEMORY 引擎支持的两种索引结构说起。
2、 MEMORY 支持的两种索引结构
MEMORY 引擎支持两种索引结构:HASH 索引、B-TREE 索引。
HASH 索引,顾名思义,索引的数据结构是哈希表。hash key 是索引字段内容计算得到的哈希值,hash value 是索引记录指向的数据行的地址。
HASH 索引中的记录不是按照字段内容顺序存放的,而是乱序的,其优点在于查找时间复杂度是 O(1),按单个值查找记录速度非常快,但不能用于范围查询。
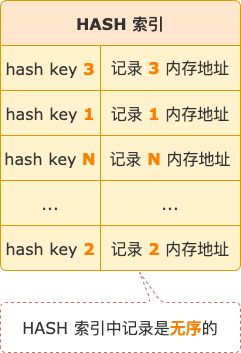
HASH 索引结构示意图
MyISAM、InnoDB 引擎 B-TREE 索引的数据结构是 B+ 树,而 MEMORY 引擎 B-TREE 索引的数据结构是红黑树。
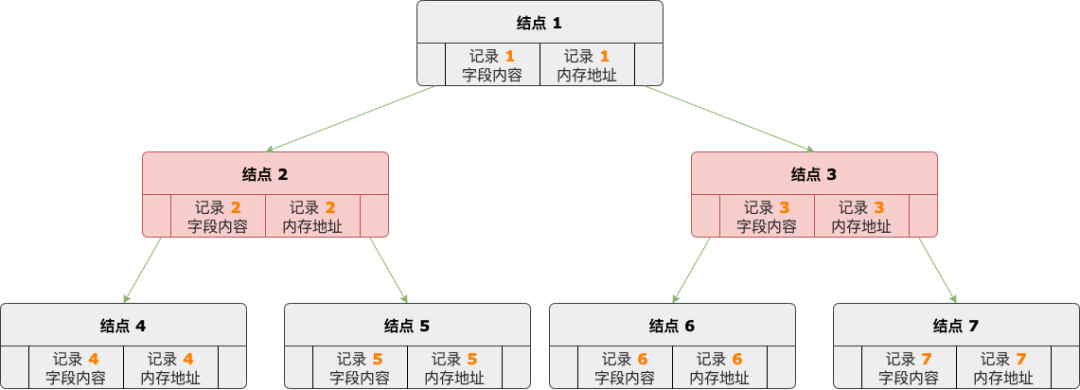
B-TREE 索引结构示意图
MEMORY 引擎的 B-TREE 索引结点中保存着索引字段内容,以及对应数据行的地址。
红黑树是平衡二叉排序树,因此 B-TREE 索引中的结点是排好序的,支持范围查询,但是按单个值查找记录的时间复杂度是 O(logN),相比于 HASH 索引来说要低一些。
基于两种数据结构的特点,HASH 索引适用于单值查找场景,B-TREE 索引适用于范围查询和需要排好序的记录的场景。
3、去重方案怎么选?
说完了 MEMORY 引擎的两种索引结构,以及它们的适用场景,再来介绍 count(distinct) 去重方案就有基础了。
按照常规流程走,当 MySQL 选择使用 MEMORY 作为临时表的存储引擎,加上为 distinct 字段创建的 HASH 索引,这完全能实现去重操作。但是本着节约精神,MySQL 向来是能省则省,只要有优化方案,一定是要使用的,那还可以怎么优化呢?
要回答这个问题,我们需要先抓住去重功能的关键,那就是表中记录的唯一性。
临时表中为 distinct 创建的 HASH 索引默认就是唯一索引,既然 HASH 索引本身就保证了唯一性,是不是可以考虑只使用 HASH 索引实现 count(distinct) 的去重功能呢?
这种思路是可行的,不过 MEMORY 引擎的 HASH 索引有一个不能满足要求的地方:HASH 索引中没有保存索引字段内容,只保存了字段内容的 hash 值。
只用索引的数据结构去重为什么需要保存字段内容,介绍去重过程的时候会说明,在那个场景下解释起来更好理解一点,这里先按下不表。
既然 HASH 索引不能满足要求,别忘了 MEMORY 引擎还支持另一种索引结构:B-TREE 索引。B-TREE 索引也能实现去重功能,索引结点中还保存了字段内容,完美符合要求。
前面以流式的方式介绍了三种候选的去重方案,我们需要来个小结:
方案一,临时表 + HASH 索引,这种实现方案中规中矩,能够满足需求,缺点在于:只是为了实现去重功能,HASH 索引自己上阵就够了,可偏偏还要搭上更多内存往表里写一份数据,浪费宝贵的内存资源。
方案二,方案一中说到,HASH 索引自己就能够实现去重了,这点毋庸置疑,只使用 HASH 索引也是候选方案之一,但 HASH 索引中没有保存索引字段内容,只能无奈的出局了。
方案三,B-TREE 索引,既能实现去重功能,索引中还保存了字段内容,完美,就是它了。
不过,MySQL 没有在 MEMORY 临时表上再创建一个 B-TREE 类型的唯一索引,而是用了 B-TREE 索引所使用的红黑树,并且因为临时表中不会写入任何数据,红黑树结点中只需要保存字段内容,不需要保存指向表中数据行的地址。
再次说明:MEMORY 临时表还是会创建,但是不会写入任何数据,就是空表。红黑树实现去重功能的过程中,会用到 MEMORY 临时表的字段信息、记录缓冲区。
以后,用 explain 查看执行计划时,如果发现 count(distinct) 既没有使用索引,也没有使用临时表,那你可能就会想到:这家伙大概是悄无声息的使用了红黑树。
前面说了这么多,只是为了弄清楚一个问题:为什么选择红黑树实现去重功能。这很重要,我们要知其然,更要知其所以然,这样我们理解起来也会更容易些,你说是吗?
接下来我们就要说说红黑树实现 count(distinct) 去重功能的点点滴滴了。
4、 红黑树结点存了些什么?
红黑树是平衡二叉排序树,既然是二叉树结构,就会有指向左子树、右子树的指针。
红黑树的结点分为红色和黑色,自然要有个属性来标记结点颜色。
MySQL 实现的红黑树,还支持插入重复结点,这是通过在结点中增加一个记录结点内容重复次数的属性实现的。
以上信息都属于结点元数据,元数据占用 24 字节内存空间。每一个结点中,除了保存着结点元数据,还要保存结点数据,就是字段内容。

 结点元数据
结点元数据
5、 红黑树占用内存太大怎么办?
使用红黑树去重虽然不用往 MEMORY 临时表写入数据,但是红黑树也不能无限制占用内存。
它能够占用的最大内存和 MEMORY 引擎临时表一样,也是由 tmp_table_size、max_heap_table_size 两个系统变量中较小的的那个决定的。默认配置下,红黑树能够占用的最大内存为 16M。
既然内存大小有限制,那就可能会出现红黑树中没有空间容纳新结点的情况,此时,磁盘文件就要粉墨登场了。
如果红黑树占用内存达到最大值,所有结点数据(不包含元数据)会被写入磁盘文件,然后删除红黑树所有结点,保留内存以便重复使用。
这些一起写入磁盘文件的数据会组成一个数据块,数据块的相关信息(在磁盘文件中的位置、记录数量)保存在对应的 Merge_chunk 中。
磁盘文件中可能会有多个数据块。
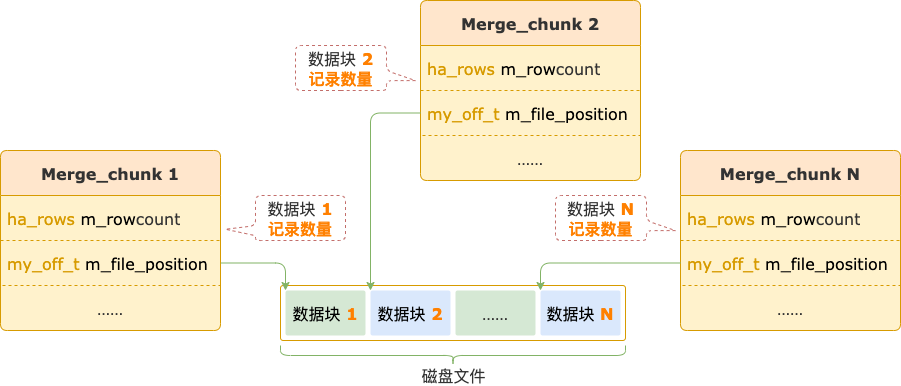
 数据块相关信息
数据块相关信息
数据块中的数据,因为来源于红黑树,有两个特点:
- 记录是按照字段内容从小到大顺序存放的。
- 记录的字段内容是唯一的,不存在重复。
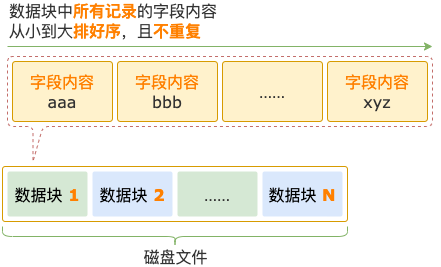
数据块中的数据
6、合并缓冲区
通过上一小节,我们知道红黑树占用内存达到最大值之后,会生成一个数据块写入到磁盘文件。
所谓天下大势,合久必分,分久必合。
磁盘文件中的数据块,虽然是分开写入的,但终究要合并去重,并进行分组计数。
磁盘文件中的每个数据块内部,记录的字段内容是不存在重复的。但是,多个数据块之间的字段内容可能存在重复,合并过程中,需要对多个数据块之间的字段内容去重。
合并去重,有两种可选的实现方案:
方案一,分为三步:
① 从磁盘文件的每个数据块中读取剩余记录里最小的一条记录到内存中,最小的记录其实就是剩余记录里的第一条记录。
② 找出第 ① 步读取的那些记录中最小的记录。
③ 判断当前的最小记录,是否和上一次最小的记录相同,如果相同,说明重复,不处理;如果不同,进行计数。
循环执行第 ① ~ ③ 步,直到读完当前分组所有数据块中的记录,合并完成。
从以上描述中,想必大家已经发现了这种方案存在的问题:需要频繁的从磁盘文件中读取数据,每次还只读取一条记录,频繁磁盘 IO 必然会影响 SQL 语句执行效率,为此,就有了方案二。
方案二,既然不能频繁从磁盘中读取数据,那就换个方式,每次读取一批记录,减少读取次数。
但是,一批记录和一条记录不一样,需要找个大点的地方临时存放,于是就有了合并缓冲区。
合并缓冲区的大小和红黑树占用内存最大值一样,也是由 tmp_table_size、max_heap_table_size 两个系统变量中较小的那个控制的,默认大小为 16M。
合并缓冲区会分成 N 份(N = 磁盘文件中数据块的数量),每一份对应一个数据块,用于存放从数据块中读取的一批记录。
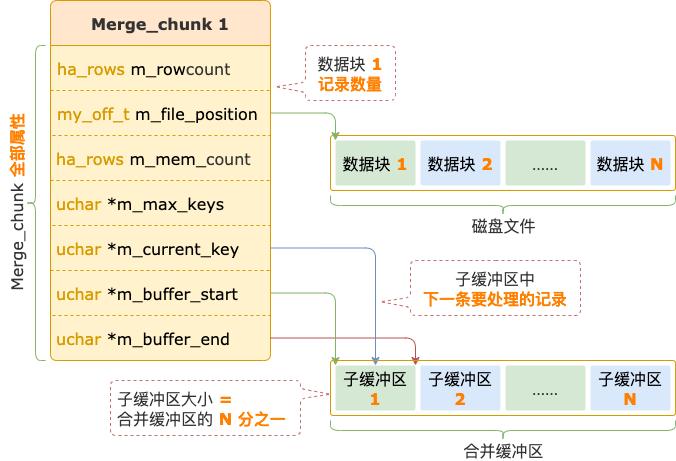
 合并缓冲区
合并缓冲区
7、 红黑树怎么去重和分组计数?
介绍完了前置知识点,重头戏来了,该说说红黑树去重和分组计数的过程了。
为了方便描述,我们还是结合一个具体 SQL 来介绍,示例表及 SQL 如下:
CREATE TABLE `t_group_by` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`e1` enum('北京','上海','广州','深圳','天津','杭州','成都','重庆','苏州','南京','哈尔滨','沈阳','长春','厦门','福州','南昌','泉州','德清','长沙','武汉') DEFAULT '北京',
`i1` int(10) unsigned DEFAULT '0',
`c1` char(11) DEFAULT '',
`d1` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_e1` (`e1`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
select
e1, count(distinct i1)
from t_group_by
group by e1
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
在调试过程中,我给 t_group_by 表的 e1 字段建了索引,所以 SQL 执行时就不需要先对表中记录进行排序了。
先来看一下去重及分组计数过程的示意图。
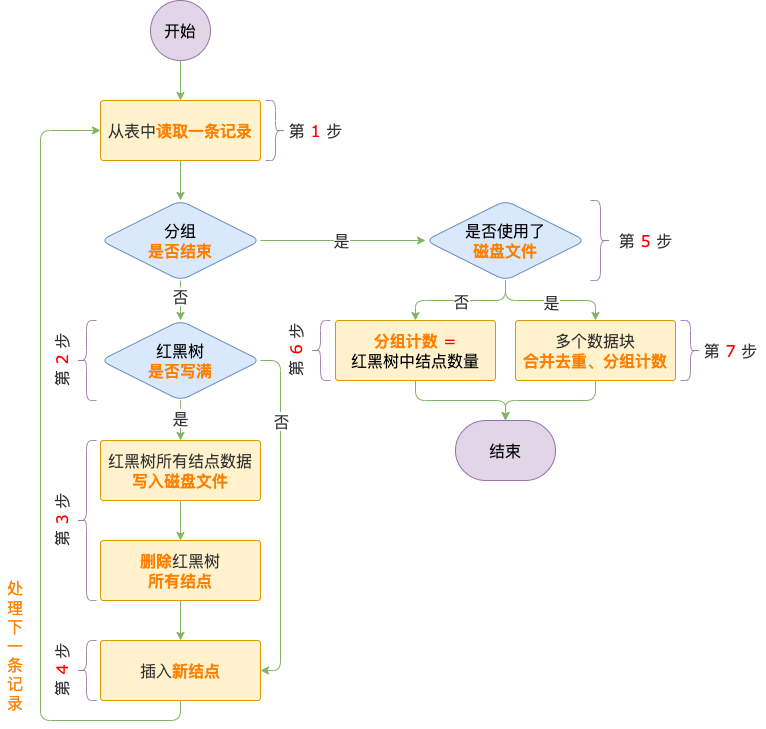
 去重及分组计数主流程
去重及分组计数主流程
看完上面的示意图,想必大家对整个过程有个大致的印象了,我们再进一步看看过程中的每一步都会做哪些事情。
第 1 步,读取记录。
从 from 子句的表中读取一条记录,示例 SQL 中为 t_group_by 表。
第 2 步,判断红黑树是否写满。
前面介绍过,红黑树的一个结点中包含两类信息:
- 结点元数据,占用 24 字节。
- 结点数据,示例 SQL 中结点数据就是 i1 字段内容,长度为 4 字节。
示例 SQL 中,一个红黑树结点占用 24 + 4 = 28 字节。
知道红黑树最大能占用的内存,每个结点占用的内存,就能够算出红黑树最多可以插入多少个结点了,也就能够很方便的判断出红黑树是不是满了。
如果红黑树已满,进入第 3 步,把红黑树中所有结点数据写入磁盘文件。
如果红黑树没满,进入第 4 步,插入新结点。
第 3 步,把红黑树所有结点数据写入磁盘文件。
按照中序遍历,把红黑树中所有结点数据按顺序写入磁盘文件。结点元数据此时就不需要了,不会写入磁盘文件。
前面介绍过这些数据会组成一个数组块,每个数据块的相关信息保存在对应的 Merge_chunk 类实例中。
数据写入磁盘后,红黑树会删除所有结点,但是内存空间会保留复用。此时,红黑树就是空的了,进入第 4 步,把刚刚因为红黑树已满没有插入的节点插入到空的红黑树中。
第 4 步,插入新结点。
从 t_group_by 表读取一条记录之后,i1 字段值作为新结点的数据插入到红黑树中,然后回到第 1 步继续执行。
第 1 ~ 4 步是循环执行的,直到一个分组的所有数据都插了入红黑树,循环过程结束,进入第 5 步。
第 5 步,处理 count(distinct) 聚合逻辑。
处理聚合逻辑分两种情况:
- 没有使用磁盘文件,分组记录少,红黑树一次都没有写满过,所有数据都在内存中。
- 使用了磁盘文件,分组记录多,红黑树写满过,前面 N - 1 次写满之后,数据写入磁盘文件,最后一次数据留在内存中。
如果没有使用磁盘文件,进入第 6 步。
如果使用了磁盘文件,进入第 7 步。
第 6 步,分组计数。
红黑树所有结点都在内存中,红黑树中的结点数量就是 count(distinct) 函数的结果。这个步骤处理完,流程结束。
第 7 步,多个数据块合并去重,然后分组计数。
红黑树写满过,部分数据在磁盘文件中,部分数据在内存中。需要先把内存中红黑树所有结点数据写入到磁盘文件中,组成最后一个数据块。
所有数据都写入磁盘文件之后,就可以开始进行合并去重和分组计数了。
首先,分配一块内存作为合并缓冲区。
然后,把缓冲区平均分成 N 份,为了描述方便,我们把缓冲区的 N 分之一叫作子缓冲区。假设示例 SQL 在磁盘文件中有 4 个数据块,就会对应 4 个子缓冲区。
每一个数据块对应的 Merge_chunk 中保存着子缓冲区的开始和结束位置、能够存放的记录数量、指向子缓冲区中下一条要处理的记录的位置。

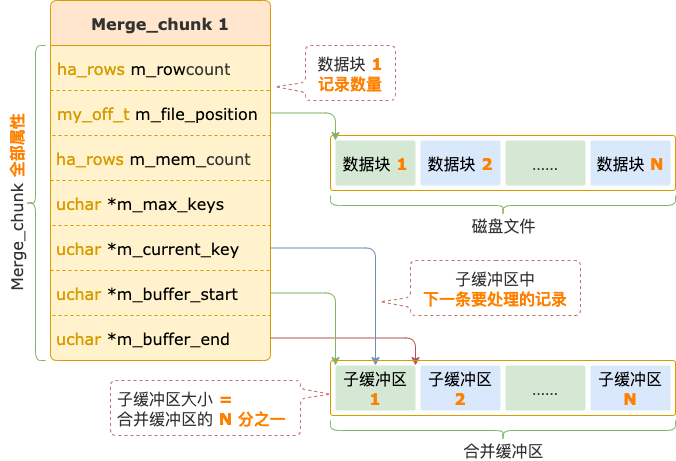
合并缓冲区
每个数据块内部的记录都是按照字段内容从小到大排好序的,多个数据块合并去重的过程不算复杂,步骤如下:

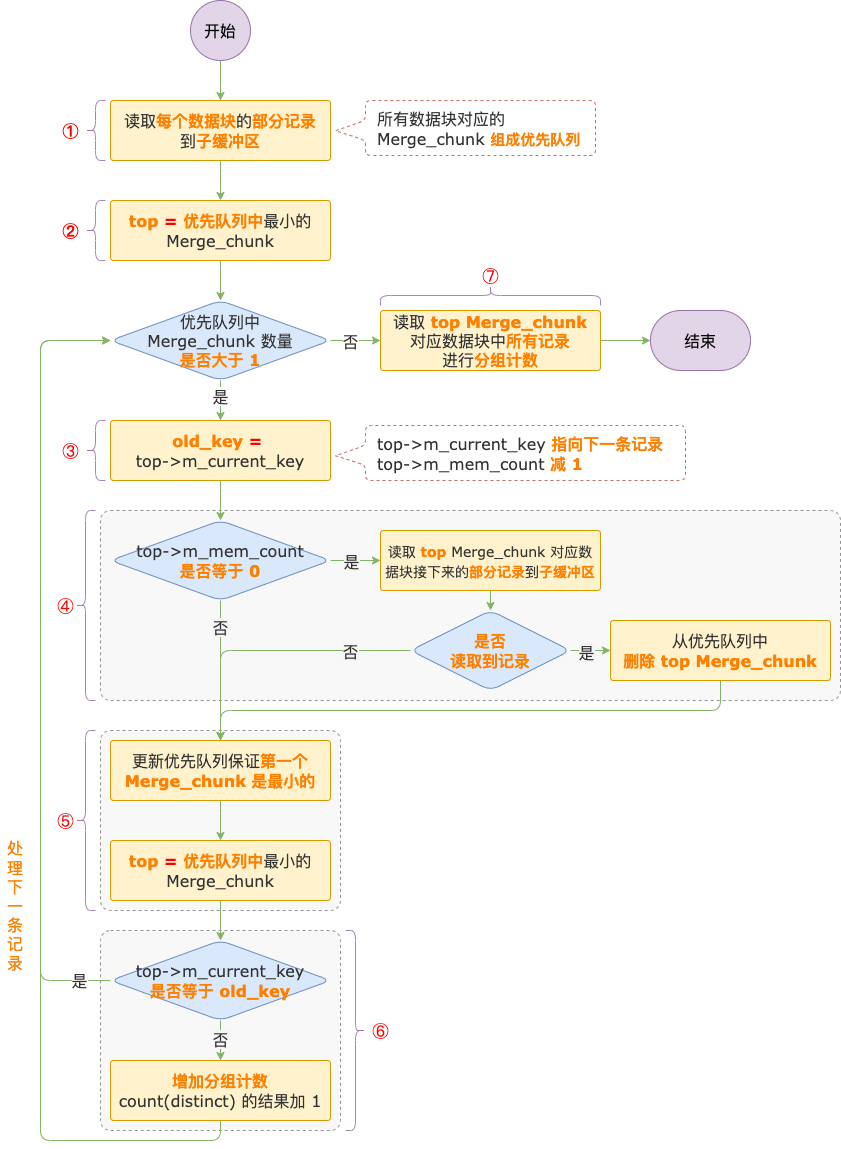
合并去重及分组计数流程
① 读取磁盘文件中的数据块到子缓冲区。
从每个数据块读取一部分记录到子缓冲区,所有数据块对应的 Merge_chunk 组成一个优先队列。
此时,每个 Merge_chunk 的 m_current_key 都指向数据块的第一条记录,也是该数据块中最小的记录,这条记录的内容就代表 Merge_chunk 的值。
Merge_chunk 的 m_mem_count 表示已读取到子缓冲区中尚未处理的记录数量。
② 获取优先队列中最小的 Merge_chunk,用top表示。
优先队列中第一个 Merge_chunk 就是所有 Merge_chunk 中最小的。
③ 读取 top Merge_chunk 的 m_current_key 指向的记录的内容到 old_key。
m_current_key 指向的记录就是 top Merge_chunk 中的最小记录,记为 old_key。
然后,m_current_key 指向数据块中下一条记录,m_mem_count 减 1,表示已读取到子缓冲区中的尚未处理的记录减少 1 条。
④ 如果 m_mem_count 等于 0,说明该数据块对应子缓冲区中的记录已处理完,需要再从磁盘文件中读取该数据块的一部分记录到子缓冲区。
如果数据块中的数据都已处理完,把数据块对应的 Merge_chunk 从优先队列中删除,对应子缓冲区的内存空间全部并入相邻的子缓冲区。
⑤ 更新优先队列中的 top Merge_chunk。
③、④ 两步执行之后,最小的 Merge_chunk 可能发生了变化,所以需要更新优先队列,保证优先队列中的第一个 Merge_chunk 是最小的。
⑥ 真正的去重操作。
比较新的 top Merge_chunk 中最小记录的内容和 old_key的值,如果一样,说明字段内容重复,不需要进行分组计数,回到 ③ ,继续进行下一轮循环。
如果不一样,说明字段内容不重复,对 top Merge_chunk 中的最小记录进行分组计数,然后回到 ③ ,继续进行下一轮循环。
③ ~ ⑥ 是循环执行的,直到优先队列中 Merge_chunk 的数量小于等于 1 个,循环结束。
⑦ 处理最后一个数据块中剩余的数据。
经过 ③ ~ ⑥ 循环执行过程,优先队列中还会剩下 1 个 Merge_chunk,需要对 Merge_chunk 对应数据块中剩下的记录进行分组计数,因为是一个数据块内部的记录,就不需要去重了。
前面那个按下不表的问题也该有下文了:
因为对磁盘文件多个数据块中的记录合并去重时,需要使用字段内容做比较,而 MEMORY 引擎的 HASH 索引中没有保存字段内容,只保存了表中数据行的首地址,这就是 MySQL 选择使用红黑树去重,而没有选择 HASH 的原因。
8、 sum(distinct)、avg(distinct) 不一样
sum(distinct)、avg(distinct) 也需要去重,但是和 count(distinct) 不一样的地方在于:sum(distinct)、avg(distinct) 只会对整数、浮点数求和或求平均数,并且只能有一个参数,需要的内存空间比较小,这意味着 sum(distinct)、avg(distinct) 去重时不需要用磁盘临时表。
因此,对于 sum(distinct)、avg(distinct) 来说,只会选择使用红黑树去重,并且也不会创建一个空的 MEMORY 临时表,这两点和 count(distinct) 不一样。
如果 sum()、avg() 函数参数中的字段不是整数或浮点数类型的字段,不会报错,字段值都会被转换为浮点数,然后对浮点数求和或求平均数。
非整数、浮点数类型字段转换为浮点数,和开发语言中的转换逻辑基本相同,对于字符串内容,就是把字符串前面的数字作为字段的数字值,例如:91 测试转换为浮点数是 91.0,测试转换为浮点数是 0.0。
9、 总结
第 2 小节,介绍了 MEMORY 引擎支持的两种索引结构:HASH 索引、B-TREE 索引。
HASH 索引适用于单值查找多的场景;B-TREE 索引适用于范围查询、需要排好序的记录的场景。
第 3 小节,以循序渐进的方式介绍了 MySQL 为什么选择使用红黑树实现 count(distinct) 的去重功能。
第 4 小节,介绍了红黑树单个结点的结构,每个结点包含结点元数据、结点数据两类信息。
第 5 小节,介绍了红黑树占用内存超过最大值之后,会把所有结点数据写入磁盘文件,然后删除所有结点,保留内存重复使用。
第 6 小节,以循序渐进的方式介绍了为什么需要合并缓冲区,以及缓冲区的大小由 tmp_table_size、max_heap_table_size 两个系统变量控制。
第 7 小节,介绍了磁盘文件中所有数据块合并去重、分组计数的详细过程。合并去重及分组计数分为红黑树写满过、没写满过两种情况,处理逻辑不一样。
第 8 小节,介绍了 sum(distinct)、avg(distinct) 只能用于整数、浮点数求和、求平均数,它们和 count(distinct) 不一样的地方在于:只会选择使用红黑树去重,不需要创建 MEMORY 临时表,更不需要磁盘临时表。
本文转载自微信公众号「一树一溪」,可以通过以下二维码关注。转载本文请联系一树一溪公众号。