













时间复杂度分析
当问题规模数据大量增加时,重复执行的次数也必定会增加,那么我们就有必要关心执行次数是以什么样的数量级增加,这也是分析时间复杂度的意义,是一个非常重要衡量算法好快的事前估算的方法
常见的时间复杂度:
- O(1):常数阶的复杂度,这种复杂度无论数据规模如何增长,计算时间是不变的。
const increment = n => n++
- O(n):线性复杂度,线性增长。
// 最典型的例子就是线性查找
const linearSearch = (arr,target) = {
for (let i = 0;i<arr.length;i++){
if(arr[i] === target) return 1;
}
return -1;
}
- O(logn):对数复杂度,随着问题规模的增长,计算时间会对数级增长,典型的例子是归并查找。
- O(nlogn):线性对数复杂度,计算时间随数据规模呈线性对数级增长,典型的例子是归并排序。
- O(n^2):平方级复杂度,典型就是双层循环的时候,代表应用是冒泡排序算法。
常见的排序算法
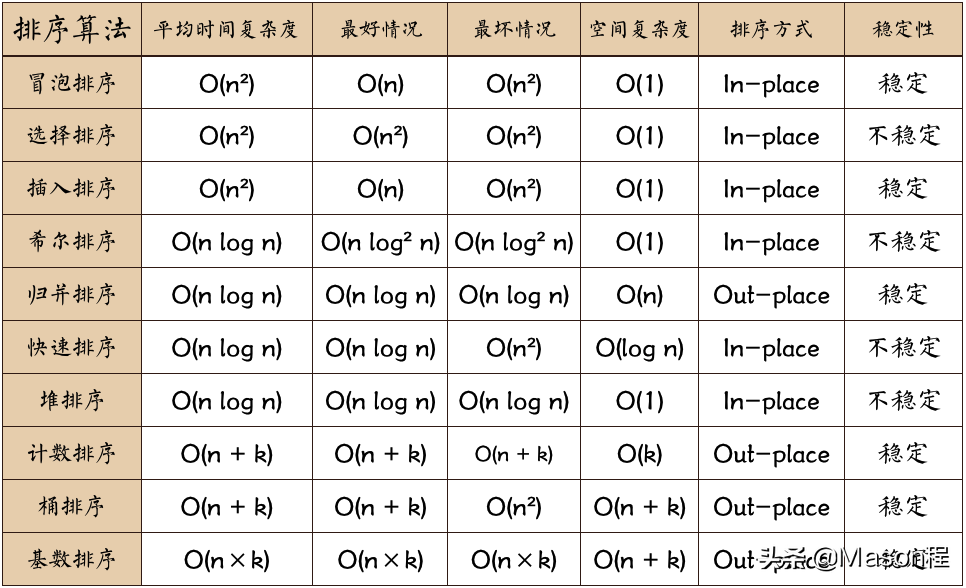
常见的排序算法这里总结四种最具代表性的:
冒泡排序
冒泡排序是一种简单的排序算法,它需要重复的走访序列,一次只比较两个数据,如果顺序错误则交换这两个数据,直到没有在需要交换的数据,走访结束,具体算法描述如下:
比较相邻元素,如果第一个比第二个大,就交换他们两个依次走访执行第一步,那么第一趟后,最后的元素应该是最大的数重复走访,直到排序完成。
const bubbleSort = arr => {
console.time('bubbleSort耗时');
let len = arr.length;
for(let i = 0;i<len;i++){
for(let j = 0;j<len-i-1;j++){
if(arr[j]>arr[j+1]){
[arr[j],arr[j+1]] = [arr[j+1],arr[j]]
}
}
}
console.timeEnd('bubbleSort耗时');
return arr
}
冒泡排序改进方案:
方案一:设置一个标记变量pos,用来记录每次走访的最后一次进行交换的位置,那么下次走访之后的序列便可以不再访问。
const bubbleSort_pos = arr => {
console.time('bubbleSort_pos耗时')
let i = arr.length - 1;
while(i > 0){
let pos = 0;
for(var j=0;j<i;j++){
if(arr[j]>arr[j+1]){
pos = j;
[arr[j],arr[j+1]] = [arr[j+1],arr[j]];
}
}
i = pos;
}
console.timeEnd('bubbleSort_pos耗时')
return arr;
}
方案二:传统冒泡一趟只能找到一个最大或者最小值,我们可以考虑在利用每趟排序过程中进行正向和反向冒泡,一次可以得到一个最大值和最小值,从而使排序趟数几乎减少一半。
const bubbleSort_ovonic = arr => {
console.time('bubbleSort_ovonic耗时')
let low = 0;
let height = arr.length -1;
let tmp,j;
while(low < height){
for(j=low;j<height;++j){ // 正向冒泡,找到最大值
if(arr[j] > arr[j+1]){
[arr[j],arr[j+1]] = [arr[j+1],arr[j]];
}
}
--height;
for(j=height;j>low;--j){ // 反向冒泡,找到最小值
if(arr[j] < arr[j-1]){
[arr[j-1],arr[j]] = [arr[j],arr[j-1]]
}
}
++low;
}
console.timeEnd('bubbleSort_ovonic耗时')
return arr;
}
以上提供两种改进冒泡的思路,耗时在这只是进行粗略对比,并不完全确定好坏,相比之下改进后的冒泡时间复杂度更低,下图实例展示结果耗时更短。

快速排序
快速排序是分治策略的经典实现,也是对冒泡排序的改进,出现频率较高,基本思路是经过一趟排序,把数据分割成独立的两部分,其中一部分数据要比另一部分都小,然后按此方法继续排序,以达到整个序列有序,具体算法描述如下:
从数组中挑出一个元素作为"基准"分区:所有比基准小的值放前面,而比基准大的值放后面,基准处于数列中间位置按照此方法依次排序(递归),以达到序列有序。
// 递归方法的其中一种形式
const quickSort = (arr) => {
if(arr.length <= 1){ return arr };
let pivotIndex = Math.floor(arr.length/2);
let pivot = arr.splice(pivotIndex,1)[0]; // 确定基准
let left = [] , right = [];
for(let i = 0;i<arr.length;i++){
if(arr[i]<pivot){
left.push(arr[i]);
}else{
right.push(arr[i]);
}
}
return quickSort(left).concat([pivot],quickSort(right));
}
希尔排序
第一个突破O(n^2)的排序算法;是简单插入排序的改进版;与插入排序的不同点在于,它会优先比较距离较远的元素。希尔排序又叫做增量缩小排序,核心在于间隔序列的设定,既可以提前设定好间隔序列,也可以动态的定义间隔序列,后者是《算法(第四版)》中提出的,实现如下:
选择一个增量序列t1,t2...tk,其中ti>tj,tk=1按增量序列个数k,对序列进行k趟排序每趟排序根据对应的增量ti,将待排序列分割成长度为m的若干子序列,然后分别对各子表进行直接插入排序。仅当增量因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度。
const shellSort = arr => {
console.time('shellSort耗时')
let len = arr.length,
gap = 1,
temp;
while(gap < len/5){ gap = gap*5+1 } // 动态定义间隔序列
for(gap; gap > 0; gap = Math.floor(gap/5)){
for(let i = gap;i<len;i++){
temp = arr[i];
for(var j=i-gap; j>=0&&arr[j]>temp; j-=gap){
arr[j+gap] = arr[j];
}
arr[j+gap] = temp;
}
}
console.timeEnd('shellSort耗时');
return arr;
}
归并排序
归并排序不受输入数据的影响,时间复杂度始终都是O(nlogn),但代价是需要额外的内存空间。归并排序也是分治法的经典体现,先使子序列有序,再使子序列段间有序,若将两个有序表合并成一个有序表,称为2-路归并。实现如下:
将长度为n的序列,分成两个长度为n/2的子序列对这两个子序列分别采用归并排序将两个排序好的子序列合并成最终排序序列。
const merge = (left,right) => {
let result = [];
while(left.length && right.length){
if(left[0] <= right[0]){
result.push(left.shift());
}else{
result.push(right.shift());
}
}
while(left.length)
result.push(left.shift());
while(right.length)
result.push(right.shift());
return result;
}
const mergeSort = arr => {
let len = arr.length;
if(len < 2) return arr;
let middle = Math.floor(len / 2),
left = arr.slice(0,middle),
right = arr.slice(middle);
return merge(mergeSort(left),mergeSort(right));
}
常见的查找算法
线性查找
线性查找较简单,只需要简单遍历即可。
const linearSearch = (arr,target) => {
for(let i =0;i<arr.length;i++){
if(arr[i] === target) return i
}
return -1
}
时间复杂度:最佳情况O(n),最差情况O(n),平均情况O(n)
二分查找法
也叫作折半查找,要求查找表的数据实现线性结构存储,还要求查找表中的顺序是有序的
实现思路如下:
首先设两个指针,low表示最低索引,height表示最高索引然后取中间位置索引,判断middle处的值是否是要查找的数字,是则查找结束;比所求值较小就把low设为middle+1,较大则把height设为middle-1然后到新分区继续查找,直到找到或者low>height找不到要查找的值结束。
const binarySearch = (arr,target) => {
let height = arr.length - 1;
let low = 0;
while(low <= height){
let middle = Math.floor((low+height)/2)
if(target < arr[middle]){
height = middle - 1
}else if(target > arr[middle]){
low = middle + 1
}else{
return middle
}
}
return -1
}
时间复杂度分析:最佳情况O(logn),最差情况O(logn),平均情况O(logn)。
参考:damonare。
二叉树的遍历方式
二叉树遍历有四种方式:先序遍历,中序遍历,后序遍历,层序遍历。
前序遍历:先访问根节点,然后前序遍历左子树,再前序遍历右子树。
中序遍历:先中序遍历左子树,然后访问根节点,最后遍历右子树。
后序遍历:从左到右,先叶子后结点的方式遍历访问左子树,最后访问根节点。
层序遍历:从根结点从上往下逐层遍历,在同一层,按从左到右的顺序对结点逐个访问。
实现二叉树的层序遍历
有两种通用的遍历树的策略:
深度优先遍历(DFC)
正如名字一样,深度优先遍历采用深度作为优先级,从某个确定的叶子,然后再返回根到另个分支,有细分为先序遍历,中序遍历和后序遍历
广度优先遍历(BFC)
广度优先按照高度顺序一层一层访问整棵树,高层次的结点会比低层的结点先访问到
// 通过迭代方式实现
const levelOrder = function(root) {
const res = [];
const stack = [{ index: 0, node: root }];
while (stack.length > 0) {
const { index, node } = stack.pop();
if (!node) continue;
res[index] = res[index] ? [...res[index], node.val] : [node.val];
stack.push({ index: index + 1, node: node.right });
stack.push({ index: index + 1, node: node.left });
}
return res;
};





















