个性化推荐是互联网行业提升 DAU (Daily Active Users)和收入的核心技术手段。随着深度学习的广泛应用,现代的推荐系统通过神经网络变相地「记住」用户的行为习惯,从而精准预测出用户的喜好。在移动互联网普及之后,用户的行为数据呈现几何级数增加,单位时间内产生和收集的用户行为数据更是极其庞大,因此需要更大的模型来对用户的兴趣编码。
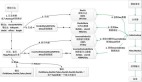
更大的数据规模意味着需要更大的模型容量,模型参数量从 5 年前的十亿已经迅速增长达到前段时间 Facebook 公开的十万亿参数规模。在这样的趋势下,更大规模的训练需求无疑将会成为下一个需要攻克的里程碑。
最近,由两个华人团队联合开源的训练框架 Persia 通过设计混合架构并在 Google cloud 上成功地把模型规模又推向了一个新的量级 -- 百万亿参数量(需占用数百 T 的存储),并能同时兼顾效率和精度。目前该框架已经受邀集成进 Pytorch 生态圈 Pytorch Lightning。
- GitHub: https://github.com/PersiaML/PERSIA
- 论文: https://arxiv.org/abs/2111.05897
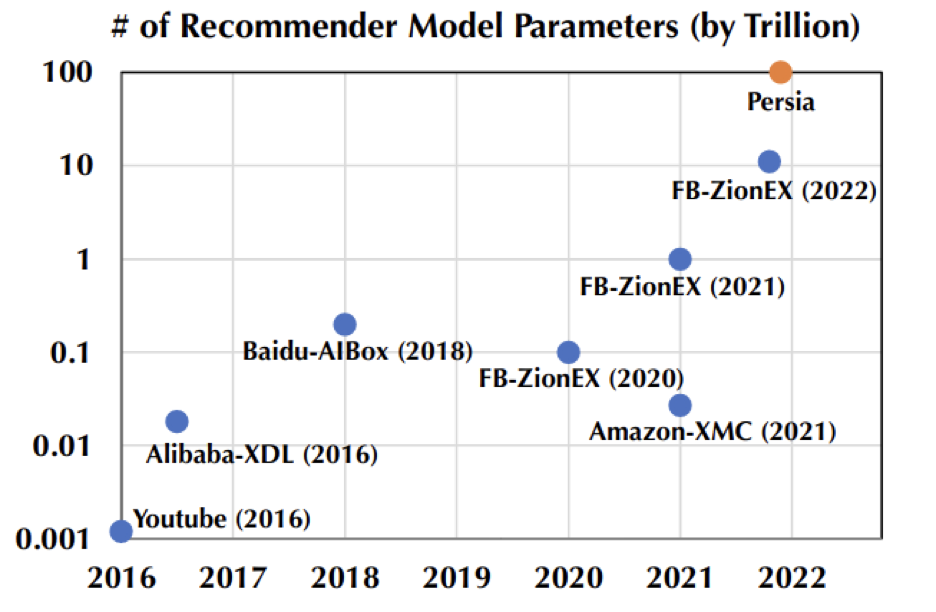
随着模型的参数量随着指数级别的增长,对于高性能的训练框架的需求也越来越迫切。传统架构在应对越来越多参数量面前也显得越来越力不从心。传统架构采用 CPU 的同构并行机制,对应的参数分布采用模型并行。
其最大的优点是便于机器的水平扩展以支持相对更大的模型,因此至今仍然在很多公司广泛使用(虽然在各个公司有不同的命名方式,本文统称为 mio 架构)。当推荐模型从传统的 Logistic regression 升级到基于 Deep Learning 的模型,且参数量急剧增大的时候,传统的方案就显得捉襟见肘 ---- 效率低下且难以兼顾精度。后来的进化版通过引入 GPU 承担了深度网络部分的计算(本文称为 mio + 架构),由于采用的仍然是同构的设计思路(只是把CPU机器换成了CPU带GPU的机器),虽然能取得一定效率提升,部分缓解了效率和精度的矛盾,但是当需要应对不同规模的网络结构的时候,往往出现昂贵的 GPU 资源大量空闲的情况,导致性价比受损严重。
为了解决这两个因模型规模不断膨胀而带来的难题,Persia 的核心设计思路如下:
- 采用异构的架构设计解决 GPU 资源利用率的问题。当 CPU 和 GPU 的配比绑定的时候,任何框架都难以同时保证在任何模型结构下的资源利用率。因此 Persia 设计了一种灵活的异构架构来实现按模型需求分配资源,保证效率的前提下资源的充分利用,大幅提升了性价比。
- 采用同步和异步的混合训练模式同时兼顾效率和精度。传统的方案中或是采用纯同步的训练,或是采用纯异步的训练。在模型越来越大、机器数量越来越多的情况下,同步的训练会导致机器之间相互等待,训练效率容易受损严重。而异步的训练方式虽然避免了机器之间相互等待,训练的效率显著提高,但是随着机器数量增加,模型的准确率(Accuracy)会大幅下降。针对超大模型情景下这样的挑战,Persia 设计了一种同步和异步 Hybrid 训练架构,集二者之长而避其短。并从理论和实践两个维度都验证了 Persia 能同时达到同步训练的准确率和异步的训练的效率。
这里简要列出几点 Persia 的特点:
- 原生支持 PyTorch 生态:鉴于 PyTorch 极大地降低了研究人员定义模型的门槛,趋势上在整个深度学习领域的占比越来越大,有别于已有的推荐训练框架(如 XDL,PaddlePaddle 等),Persia 决定基于 PyTorch 生态。用户模型定义等操作可直接借助 PyTorch 实现,因而即便是在研究领域最新最前沿模型(如 Transformer 等)也可直接调用,达到最大限度的灵活性与易用性。
- 高性能:在 Criteo 标准数据集上,相较其他流行的开源推荐模型训练框架,同样资源条件下 Persia 可达到一倍以上的性能提升。Persia 支持 CPU-GPU 异构训练,支持 GPU 与 GPU 直接通讯,显著降低训练成本。
- 可扩展性:Persia 在高达 100 万亿模型参数训练的 scale 下保持高训练效率。同时在多数场景能够接近线性加速(投入 n 倍的资源量,训练效率提升接近 n 倍)。
- 工业级场景大规模验证:Persia 为 Kubernetes 实现了定制化的 operator,支持云原生部署。并实现了各种容错机制,经过在线上生产环境稳定运行两年以上的验证。Persia 经过多个亿级 DAU 核心业务场景的实践检验,取得了显著的性能和业务指标提升。
- 安全、故障易排查:Persia 由注重内存安全、速度和并发性的 Rust 语言实现,在编译期就排除了大量的内存安全问题。原生提供大量打点监控,与 Grafana 完美结合,可自定义各类报警条件。同时基于 tracing 实现了分模块、分层级的 log 输出,使得实际场景中故障排查更加轻松。
- 灵活的特征处理:支持交叉特征等各种常见特征处理方式,且用户通过 Python 脚本即可定义各种自定义特征处理模式。兼具灵活性与易用性。
- 线上线下一致性:离线训练和线上训练代码统一,解决工程师常常需要花费大量时间排查模型上线效果不一致等痛点问题。
Persia 设计思路
整体架构
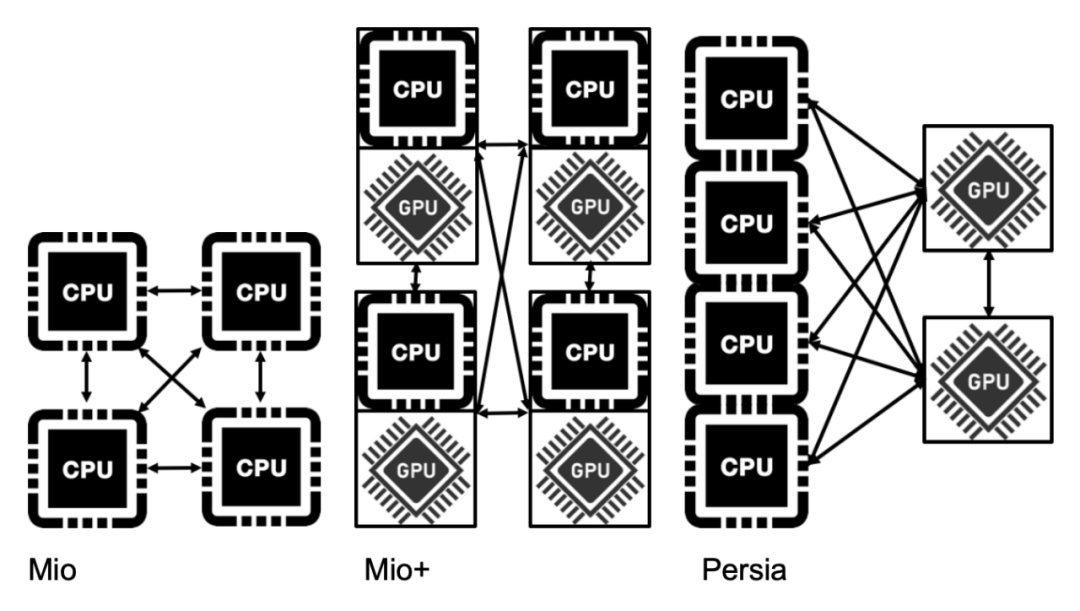
在推荐模型中,模型往往由下图中的几部分构成:
- Embedding Layer: 用户 id、item id 等 ID 类 feature 对应的 Embedding 构成的 Embedding 层。每个 id 对应一个预设大小的向量(称为 Embedding),由于 id 数量往往十分巨大,这些向量常常会占据整个模型体积的 99% 以上。
- Non-ID Type Features: 图像信息、LDA 等实数向量特征。这部分将会与 id 对应的 Embedding vector 组合在一起,输入到 DNN 中预测点击率等。
- Dense Neural Network (以下简称 NN): 这部分是一个神经网络,接受 Embedding vector 和实数向量特征,输出点击率等希望预测的量。
这种推荐模型中, Embedding Layer 参数往往占模型体积的绝大部分,但 Embedding Layer 的计算量却不大。而 NN 的参数量只占模型体积的很小部分,却占了绝大部分计算量。这正对应了:硬件上 CPU 的内存较大,但算力较低,而 GPU 的显存较小,但算力较高。
现有的训练框架虽然包含GPU算力,但是每个 GPU worker 都需要跟大量 PS 之间传递数据和模型,这常常会触发通讯瓶颈,从而整个效率都被拖垮了。
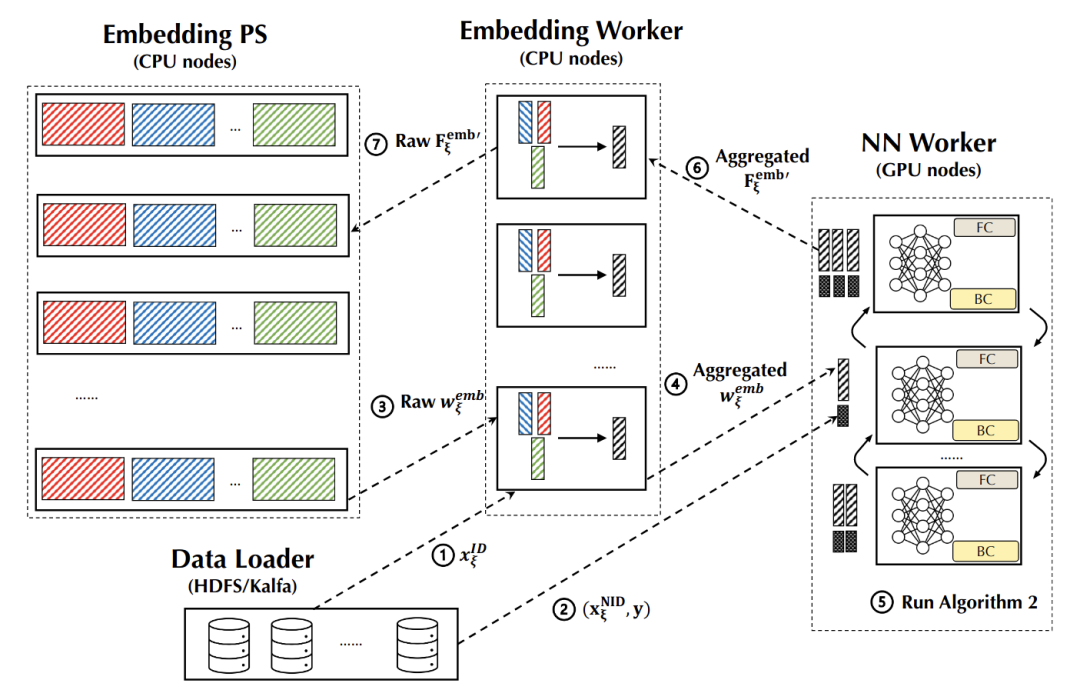
因此,在 Persia 系统设计中,NN 被置于 GPU 显存中,通过 GPU 进行梯度计算。对于 NN 部分直接通过 GPU 与 GPU 之间的高效集合通讯同步,完全不经过 PS。而 Embedding 则置于内存中,通过 CPU 进行计算。Persia 对于 PS 进行两层架构设计 (Embedding PS, Embedding Worker,后文介绍),能够在多数场景下进一步降低 GPU worker 带宽消耗,提升整体训练效率。
同步+异步混合训练
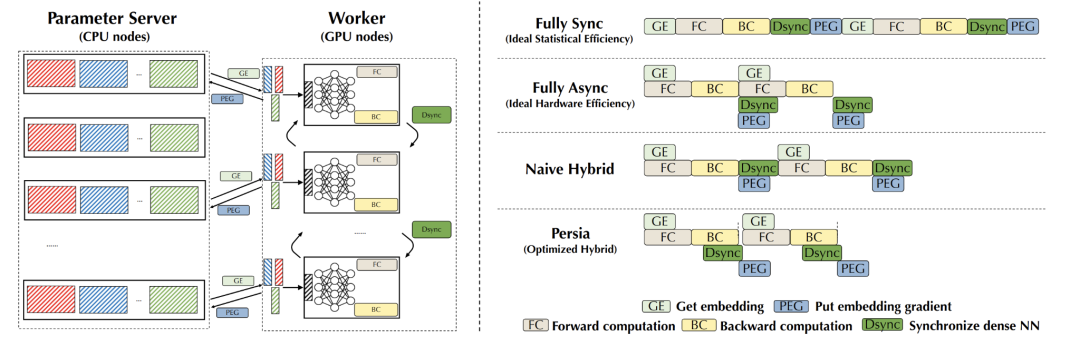
此外,现存系统往往采用全同步训练或全异步训练方式。在全同步训练中,所有 GPU worker 对一批数据进行训练和模型更新,全部完成后再进入下一批数据。在模型越来越大、机器数量越来越多的情况下,会导致机器之间相互等待、同步的时间大幅增加,难以在有限时间内完成训练。这种情况下系统的训练过程如下图中第一行 (Full Sync) 所示。在全异步训练中,每个 worker 独立训练并更新 PS 参数。虽然 worker 之间不需要相互等待,训练的效率较高,但是随着机器数量增加,每个 worker 上使用的模型的差异会变大,导致模型的训练效果大幅下降。这种情况下系统的训练过程如下图中第二行 (Full Async) 所示。
针对这两种方式的问题,Persia 设计了 Hybrid 训练架构,能够在保证训练效果的同时,达到接近全异步的训练效率。推荐场景训练中的一个核心观察是,Embedding 的更新非常稀疏,两次更新之间往往交集很小,因此即使对 Embedding 做异步更新,对最终的训练结果影响也不大。而 NN 部分的更新则反之,每一次都会更新全部参数,如果做异步训练,会导致训练结果的巨大差异。Persia 所提出的 Hybrid 训练方式,能够对 NN 部分同步训练,Embedding 部分异步训练。最终训练效率接近纯异步训练的效率,同时模型效果保持和全同步训练一致。兼得两方面的优势。这种情况下系统的训练过程如下图中第三行 (Naive Hybrid) 所示。Persia 在此之上还对能够并行执行的通讯、计算操作进行重叠,进一步提升系统效率。最终系统的训练过程如下图中第四行 (Persia) 所示:
理论保证
有别于现存系统,Persia 对于 Hybrid 算法的设计给出了严格的理论保证。对于 Expectation of Loss 的优化问题(比如推荐场景中最普遍的每个样本对应一个 loss 的场景):
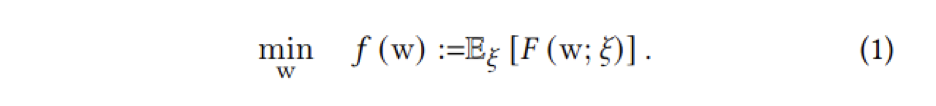
其中 f(w) 代表整个数据集上的平均 loss,ξ 代表一个样本,w 代表模型参数,F(w; ξ) 代表样本 ξ 上的 loss。模型训练的目标是最小化整个数据集上的平均 loss。使用 Persia Hybrid 的训练方式,可以证明模型的收敛速度为:

其中 σ 为数据集方差,T 为迭代次数,τ 为 GPU worker 数量,α 为 ID 类 feature 碰撞概率。其中前两项为全同步训练的收敛速度,最后一项为 Hybrid 训练引入的误差。在推荐场景中,因为 Embedding 的更新非常稀疏,碰撞概率 α 远小于 1,因此 Hybrid 收敛速度与全同步训练收敛速度几乎完全一致,但因为同步开销减少,每一步的训练执行效率大幅提升。对于具体的理论证明,可以参考 Persia 的论文 [1]。
其他优化
在算法创新的基础上,为了发挥极致的性能。Persia 提供了大量的实现层优化。比如:
- 所有 PS 服务通讯使用为训练场景优化的 zero-copy Persia RPC 系统,在训练场景下(特点是 payload 非常大,包括 Embedding 和梯度等等大量 tensor 数据)性能远超传统 RPC 框架(如 gRPC、bRPC);
- GPU 之间通讯使用同为快手开源的 Bagua 训练加速框架,对 GPU 之间的集合通讯性能有显著提升,并能通过梯度压缩等算法进一步降低通讯开销;
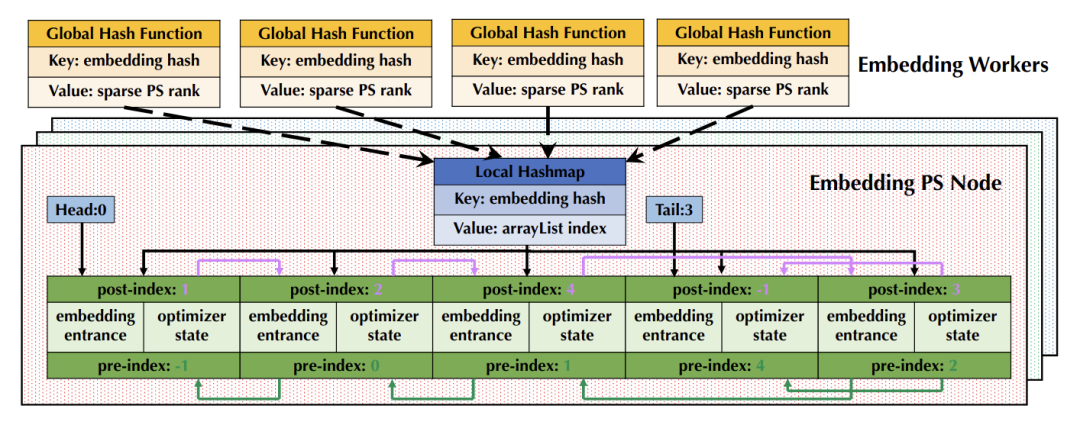
- Embedding 在 PS 中通过特殊设计的数据结构 (Persia Embedding Array List) 存储,大幅提升 PS 效率和模型存取效率。这包括运行过程中无需动态申请新内存,同时更好地利用 CPU cache 机制。支持 Embedding 逐出逻辑。模型保存和读取过程简化为对连续内存的直接 Dump/Load 过程;
- 引入 Persia Embedding Worker 组件,将 Embedding Sum Pooling、处理原始数据等操作执行后再发送给 GPU,大幅减少 GPU 带宽占用;
- 原始数据处理为 Persia Compact Batch 格式,自带 ID 去重和数据压缩表征等性质,相比一般表示方式数据体积降低至 1/4,提升系统数据处理效率。
验证和比较
测试选用 Alibaba-Ad,Avazu-Ad,Criteo-Ad 等多种开源数据集,训练效率整体有 8 倍以上提升:

Persia 可支持高达 100 万亿模型训练,并在模型规模变大时保持训练效率:
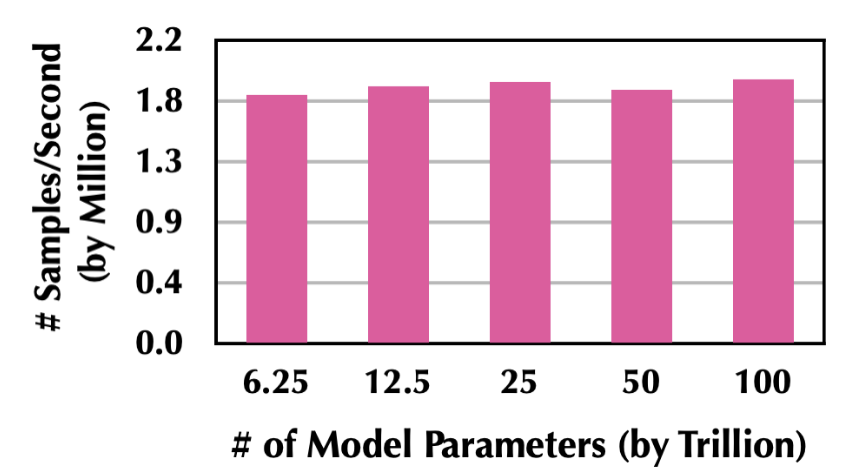
在资源量扩大时,Persia 可以接近线性扩展(投入 n 倍的资源量,训练效率提升接近 n 倍):

Persia 使用实例
使用 Persia 非常简单,主要分为训练部署、模型定义、自定义数据集部分。
- 分布式部署:通过 Persia operator 可在 Kubernetes 集群上一键部署 PERSIA 任务
- 模型定义:直接使用 PyTorch
- 自定义数据集:自定义预处理逻辑,将结果通过 Persia 提供的 Python 工具包转换成 Persia Compact Batch 即可
完整例子和更多场景,欢迎参考 Persia Tutorial 文档(https://persiaml-tutorials.pages.dev/)。Persia 模型上线推理
Persia 训练的模型 Embedding 部分可通过线上部署 Embedding PS 和 Embedding Worker 直接提供服务。NN 部分为原生 PyTorch 模型,在 Persia Tutorial 中提供了通过 TorchServe 推理的简单例子。用户也可以通过原生 PyTorch 的各种工具,比如转换成 TensorRT 模型,进一步提升推理性能。