在这篇论文中,来自苹果的研究者提出了一种用于移动设备的轻量级通用视觉 transformer——MobileViT。该网络在 ImageNet-1k 数据集上实现了 78.4% 的最佳精度,比 MobileNetv3 还要高 3.2%,而且训练方法简单。目前,该论文已被 ICLR 2022 接收。

- 论文链接:https://arxiv.org/pdf/2110.02178.pdf
- 代码链接:https://github.com/apple/ml-cvnets
轻量级卷积神经网络(CNN)是移动设备机器视觉任务的首选。它们的空间归纳偏置允许它们在不同的视觉任务中,可以使用较少的参数进行视觉内容的学习表示。但是这些网络在空间上是局部的。为了学习视觉内容的全局表示,要采用基于自注意力的视觉 transformer(ViT)。与 CNN 不同,ViT 是重量级的。在这篇文章中,作者提出了以下问题:是否有可能结合 CNN 和 ViT 的优势,为移动设备机器视觉任务构建一个轻量级、低延迟的神经网络模型?
为了解决上面的问题,作者提出了 MobileViT——一种用于移动设备的轻量级通用视觉 transformer。MobileViT 从另一个角度介绍了使用 transformer 进行全局信息处理的方法。
具体来说,MobileViT 使用张量对局部和全局信息进行有效地编码(图 1b 所示)。
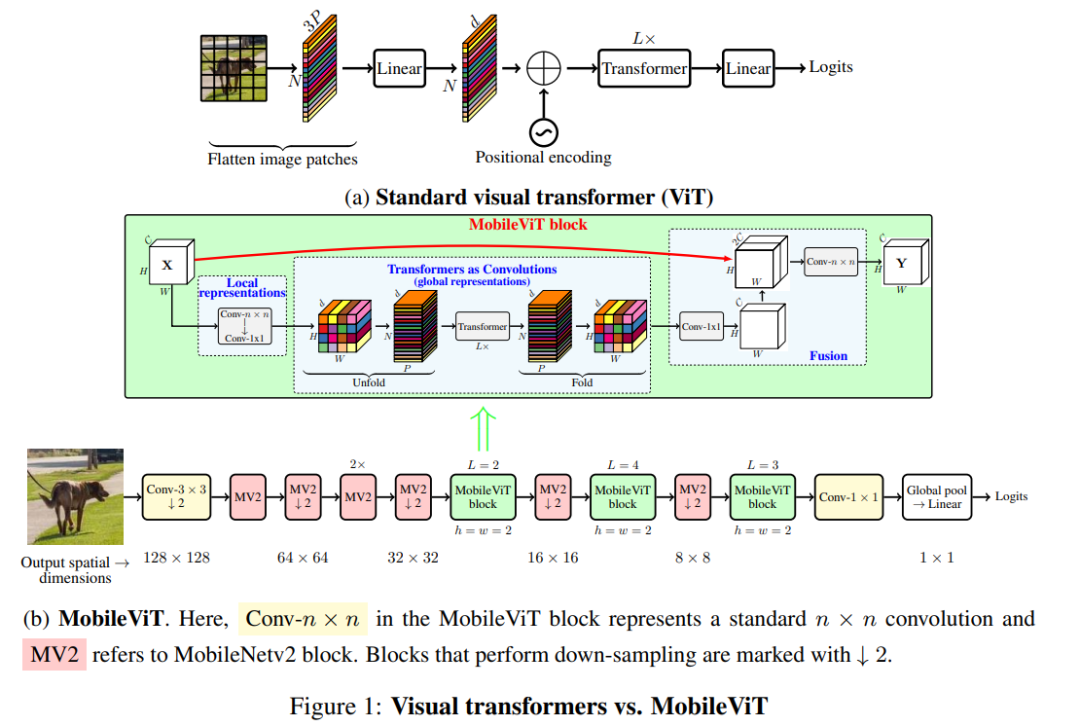
与 ViT 及其变体(有卷积和无卷积)不同,MobileViT 从不同的角度学习全局表示。标准卷积涉及三个操作:展开、局部处理和折叠。MobileViT 使用 transformer 将卷积中的局部处理方式替换为全局处理。这使得 MobileViT 兼具 CNN 和 ViT 的特性。这使它可以用更少的参数和简单的训练方法(如基本增强)学习更好的表示。该研究首次证明,轻量级 ViT 可以通过简单的训练方法在不同的移动视觉任务中实现轻量级 CNN 级性能。
对于大约 500-600 万的参数,MobileViT 在 ImageNet-1k 数据集上实现了 78.4% 的最佳精度,比 MobileNetv3 还要高 3.2%,而且训练方法简单(MobileViT 与 MobileNetv3:300 vs 600 epoch;1024 vs 4096 batch size)。在高度优化的移动视觉任务的体系结构中,当 MobileViT 作为特征主干网络时,性能显著提高。如果将 MNASNet(Tan 等人,2019 年)替换为 MobileViT,作为 SSDLite(Sandler 等人,2018 年)的特征主干网络,能生成更好的(+1.8%mAP)和更小的(1.8×)检测网络(图 2)。

架构细节
MobileViT 块
如图 1b 所示的 MobileViT 块的作用是使用包含较少参数的输入张量学习局部和全局信息。形式上,对于给定的输入张量 X∈ R^(H×W×C),MobileViT 应用一个 n×n 标准卷积层,然后是逐点(1×1)卷积层来生成 X_L∈ R^(H×W×d)。n×n 卷积层编码局部空间信息,而逐点卷积通过学习输入通道的线性组合将张量投影到高维空间(或 d 维,其中 d>C)。
有了 MobileViT,我们希望在有效感受野为 H×W 的情况下对长程非局部依赖进行建模。目前研究最多的长程依赖建模方法之一是空洞卷积(dilated convolution)。然而,这种方法需要仔细选择扩张率(dilation rate)。否则,权重将被应用于填充的零,而不是有效的空间区域(Yu&Koltun,2016;Chen 等人,2017;Mehta 等人,2018)。另一个候选的解决方案是自注意力(Wang 等人,2018 年;Ramachandran 等人,2019 年;Bello 等人,2019 年;Dosovitskiy 等人,2021 年)。在自注意力方法中,具有多头自注意力的(ViT)已被证明对视觉识别任务是有效的。然而,ViT 是重量级的,并且模型优化能力低于标准,这是因为 ViT 缺少空间归纳偏置(肖等人,2021;格雷厄姆等人,2021)。
为了让 MobileViT 学习具有空间归纳偏置的全局表示,将 X_L 展开为 N 个非重叠 flattened patches X_U∈ R^(P×N×d)。这里,P=wh,N=HW/P 是 patch 的数量,h≤ n 和 w≤ n 分别是 patch 的高度和宽度。对于每个 p∈ {1,···,P},通过 transformer 对 patch 间的关系进行编码以获得 X_G∈ R^(P×N×d):
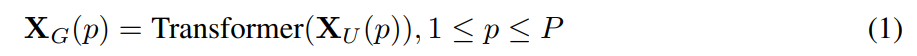
与丢失像素空间顺序的 ViT 不同,MobileViT 既不会丢失 patch 顺序,也不会丢失每个 patch 内像素的空间顺序(图 1b)。因此,我们可以折叠 X_G∈ R^(P×N×d)以获得 X_F∈ R^(H×W×d)。然后使用逐点卷积将 X_F 投影到低 C 维空间,并通过级联操作与 X 组合。然后使用另一个 n×n 卷积层来融合这些连接的特征。由于 X_U(p)使用卷积对 n×n 区域的局部信息进行编码,X_G(p)对第 p 个位置的 p 个 patch 的全局信息进行编码,所以 X_G 中的每个像素都可以对 X 中所有像素的信息进行编码,如图 4 所示。因此,MobileViT 的整体有效感受野为 H×W。

与卷积的关系
标准卷积可以看作是三个连续操作:(1)展开,(2)矩阵乘法(学习局部表示)和(3)折叠。MobileViT 与卷积相似,因为它也利用了相同的构建块。MobileViT 用更深层的全局处理(transformer 层)取代卷积中的局部处理(矩阵乘法)。因此,MobileViT 具有类似卷积的特性(如空间偏置)。因此,MobileViT 块可以被视为卷积 transformer 。作者有意简单设计的优点就是,卷积和 transformer 的底层高效实现可以开箱即用,从而允许我们在不同的设备上使用 MobileViT,而无需任何额外的改动。
轻量级
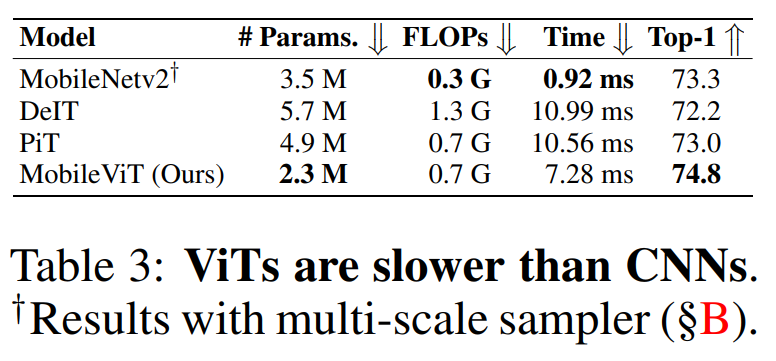
MobileViT 使用标准卷积和 transformer 分别学习局部和全局表示。相关的研究作(如 Howard et al.,2017;Mehta et al.,2021a)表明,使用这些层设计的网络量级很重,因此自然会产生一个问题:为什么 MobileViT 的量级很轻?作者认为,问题主要在于学习 transformer 的全局表示。对于给定的 patch,之前的研究是(如 Touvron 等人,2021a;Graham 等人,2021)通过学习像素的线性组合将空间信息转换为潜在信息(图 1a)。然后,通过使用 transformer 学习 patch 间的信息,对全局信息进行编码。因此,这些模型失去了 CNN 固有的图像特定归纳偏置。因此,它们需要更强的能力来学习视觉表示。这就导致这些网络模型既深又宽。与这些模型不同,MobileViT 使用卷积和 transformer 的方式是,生成的 MobileViT 既具有类似卷积的属性,又同时允许全局处理。这种建模能力使我们能够设计浅层和窄层的 MobileViT 模型,因此最终的模型很轻。与使用 L=12 和 d=192 的基于 ViT 的模型 DeIT 相比,MobileViT 模型分别在大小为 32×32、16×16 和 8×8 的空间层次上使用 L={2,4,3}和 d={96,120,144},产生的 MobileViT 网络比 DeIT 网络更快(1.85×)、更小(2×)、更好(+1.8%)(表 3 所示)。
计算成本
MobileViT 和 ViTs(图 1a)中多头自注意力的计算成本分别为 O(N^2Pd)和 O(N^2d)。理论上 MobileViT 效率是比 ViTs 低的。然而在实践中,MobileViT 实际比 ViTs 更高效。在 ImageNet-1K 数据集上,与 DeIT 相比,MobileViT 的 FLOPs 减少了一半,并且精确度提高了 1.8%(表 3 所示)。这是因为轻量级设计(前面讨论)的原因。
MobileViT 架构
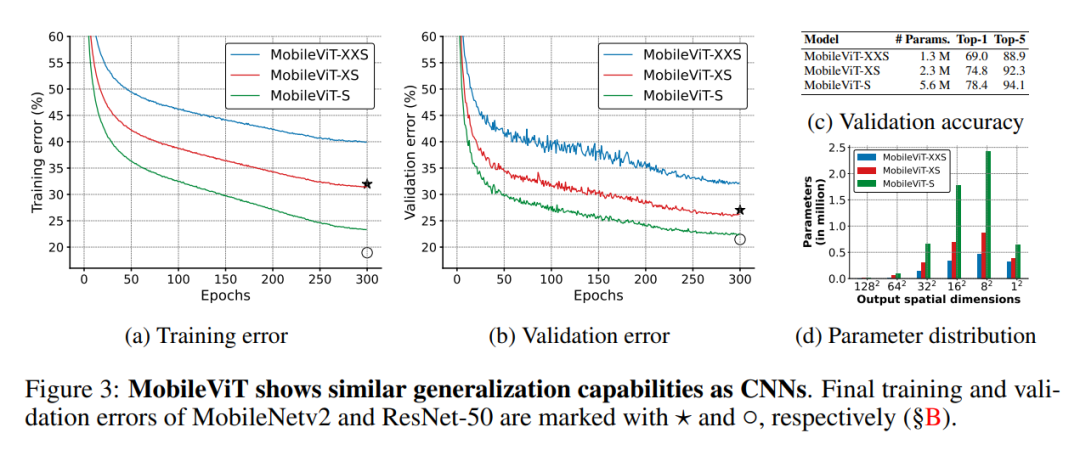
作者设计的网络也是受到轻量级 CNN 理念的启发。以三种不同的网络大小(S:small、XS:extra-small 和 XXS:extra-extra-small)训练 MobileViT 模型,这些网络通常用于移动视觉任务(图 3c)。MobileViT 中的初始层是一个 3×3 的标准卷积,然后是 MobileNetv2(或 MV2)块和 MobileViT 块(图 1b 和 §A)。使用 Swish(Elfwing 等人,2018)作为激活函数。按照 CNN 模型,在 MobileViT 块中使用 n=3。特征映射的空间维度通常是 2 和 h、w 的倍数≤ n。因此在所有空间级别设置 h=w=2。MobileViT 网络中的 MV2 模块主要负责下采样。因此,这些区块在 MobileViT 网络中是浅而窄的。图 3d 中 MobileViT 的空间水平参数分布进一步表明,在不同的网络配置中,MV2 块对网络参数的贡献非常小.
实验结果
IMAGENET-1K 数据集上的图像分类结果
与 CNN 对比
图 6a 显示,在不同的网络规模(MobileNet v1(Howard et al.,2017)、MobileNet v2(Sandler et al.,2018)、ShuffleNet v2(Ma et al.,2018)、ESPNetv2(Mehta et al.,2019)和 MobileNet v3(Howard et al.,2019))中,MobileNet 在性能上优于轻量级 CNN。对于大约 250 万个参数的模型(图 6b),在 ImageNet1k 验证集上,MobileViT 的性能比 MobileNetv2 好 5%,比 ShuffleNetv2 好 5.4%,比 MobileNetv3 好 7.4%。图 6c 进一步表明,MobileViT 的性能优于重量级 CNN(ResNet(He 等人,2016 年)、DenseNet(Huang 等人,2017 年)、ResNet SE(Hu 等人,2018 年)和 EfficientNet(Tan&Le,2019a))。对于类似数量的参数,MobileViT 比 EfficientNet 的准确度高 2.1%。
与 ViTs 进行比较
图 7 将 MobileViT 与在 ImageNet-1k 未蒸馏数据集上从头开始训练的 ViT 变体进行了比较(DeIT(Touvron et al.,2021a)、T2T(Yuan et al.,2021b)、PVT(Wang et al.,2021)、CAIT(Touvron et al.,2021b)、DeepViT(Zhou et al.,2021)、CeiT(Yuan et al.,2021a)、CrossViT(Chen et al.,2021a)、LocalViT(Li et al.,2021)、PiT(Heo et al.,2021),ConViT(d’Ascoli 等人,2021 年)、ViL(Zhang 等人,2021 年)、BoTNet(Srinivas 等人,2021 年)和 Mobile-former(Chen 等人,2021b 年)。不像 ViT 变体显著受益于深层数据增强(例如,PiT w / 基础与高级:72.4(R4)与 78.1(R17);图 7b),MobileViT 通过更少的参数和基本的增强实现了更好的性能。例如,MobileViT 只有 DeIT 的 1/2.5 大小,但性能比 DeIT 好 2.6%(图 7b 中的 R3 和 R8)。

MOBILEVIT 作为通用主干网络的表现
移动目标检测
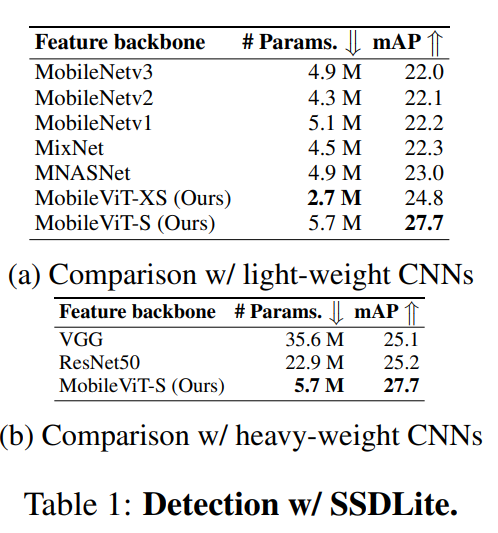
表 1a 显示,对于相同的输入分辨率 320×320,使用 MobileViT 的 SSDLite 优于使用其他轻量级 CNN 模型(MobileNetv1/v2/v3、MNASNet 和 MixNet)的 SSDLite。此外,使用 MobileViT 的 SSDLite 性能优于使用重型主干网络的标准 SSD-300,同时学习的参数也明显减少(表 1b)。
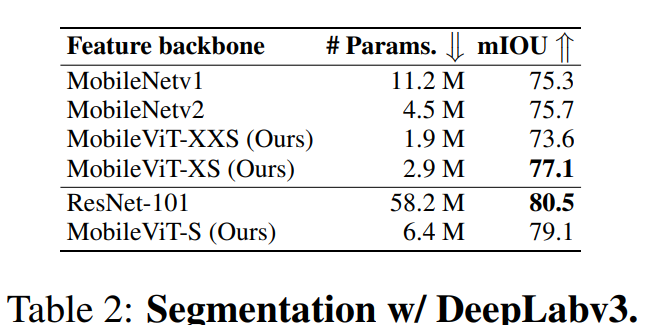
移动语义分割:从表 2 可见,使用 MobileViT 的特征主干网络比 DeepLabv3 更小、更好。
移动设备上的性能测试
轻量级和低延迟的网络对于实现移动视觉应用非常重要。为了证明 MobileViT 对此类应用的有效性,使用公开的 CoreMLTools(2021 年)将预先训练的全精度 MobileViT 模型转换为 CoreML。然后在移动设备 (iPhone12) 上测试它们的推理时间(平均超 100 次迭代)。
图 8 显示了 MobileViT 网络在三个不同任务上的推断时间,其中两个 patch 大小设置(Config-A: 2, 2, 2 和 Config-B: 8, 4, 2)。