传统的版权保护行业费时、费力、成本高,海量内容难以全量保护,内容分发难以掌控传播的安全问题。区块链技术具有不可篡改、追根溯源、分布式共识等特点,和数字版权保护具有天然契合之处,将区块链技术与 AI 多媒体侵权检测技术相结合,极大降低了版权维权成本,提升版权保护效率,同时也为网络版权的存证、交易、维权提供了新的途径。因此,蚂蚁集团 - 数字科技线推出了一站式数字内容原创保护平台 「鹊凿」,图片视频等内容一键上链,快速完成版权存证,在司法机关和公证机构的共同见证下,成为“盗版维权” 的铁证。
相关的产品介绍可见于官网:https://www.mydcs.com/pages/index
在版权保护中,视频侵权检测能力是极为重要的一部分。现如今,盗版视频的猖獗不仅让视频网站损失惨重,同时给内容创作者带来经济和精神上的损失更是不可估量。2021 年 4 月,中宣部版权局提出,加大对视频侵权行为的打击力度。近些年,包括二次创作、视频剪辑在内的侵权手段层出不穷,盗版视频的侵权样例也不仅局限在简单的盗摄或者加水印等容易被识别的方式。因此面向版权保护的视频侵权检测方法就变得尤为重要,针对这一系列问题,基于 AI 的多媒体比对算法技术,能够显著地节省人工审核的成本,提高侵权取证的效率,实现在大范围检索情况下做出精确的识别,是解决视频侵权问题的有效方案。
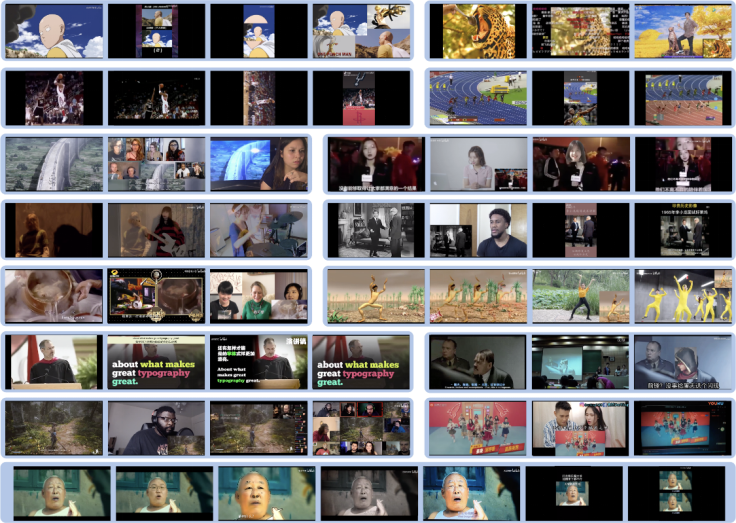
图 1. 蚂蚁构建大规模视频侵权数据集(VCSL)中的典型侵权样例
但是目前针对版权侵权检测,尤其是视频侵权这一领域在学术界和产业界都存在着一些瓶颈问题,主要体现在下面三点:
- 数据集,目前学术界已经开源的数据集大部分都是只有视频级别的标注(Trecvid[1], SVD[2], FIVR[3]),即视频对之间只标注了是否侵权,而并未标注两个视频之间实际侵权的时间片段(即侵权起始时间位置和结束时间位置)。目前开源的拥有片段级别标注的数据集仅有 2014 年 ECCV 上开源的 VCDB 数据集[4],但这个数据集规模比较小,仅有 6k 对实际侵权的视频对,这也会在后面的章节进行介绍。
- 算法评价指标,在学术界中,视频级别的拷贝检测评价指标比较成熟,但是片段粒度的拷贝检测准确度的评价指标仍然存在着比较多的问题。之前 VCDB 论文中提出的评价指标在实际的实验测试中出现了一系列指标上的偏差以及应用上的问题。
- 侵权定位算法,侵权定位算法,在这里侵权定位(Temporal Alignment)算法指的是在提取出两段视频的时序特征后,需要输出两段视频侵权的时间片段。大部分侵权定位的算法都是不开源的,因此学术界也无法形成一个完善的 benchmark,视频拷贝检测和侵权定位这个领域也相对较为停滞。
针对以上三个主要问题,该研究做了大量的视频拷贝检测和侵权定位相关的研究工作,包括了:
- 提出了目前最大规模(超过现有其他数据集 2 个数量级规模)的视频侵权定位数据集,包括了超过 16 万对侵权视频对,28 万对侵权片段,并且涵盖了大量的视频领域和视频时长。
- 提出了全新的视频片段拷贝检测的评价指标,该评价指标充分考虑到了视频拷贝检测这个任务的特殊性,并且在实际场景下体现出了更好的适应性。
- 提出了关键帧和侵权定位端到端的模型 SSAN 并达到了现阶段最高指标,并且将现阶段学术界的常见侵权定位算法进行复现并且开源,形成了完善全面的视频侵权定位 benchmark。
上面的成果已经分别被计算机视觉顶会 CVPR 和多媒体顶会 ACM MM 成功录用和发表。

- CVPR 2022 VCSL 论文:https://arxiv.org/abs/2203.02654
- VCSL 数据集和评测以及算法代码:https://github.com/alipay/VCSL
大规模视频片段拷贝检测数据集 VCSL针对上一节提出的现有数据集问题,该研究希望提出一个全面的数据集,满足下面的要求:
- 视频拷贝的类型必须要尽可能的全面,但是要避免过度变换使得侵权的视频基本不具备观赏性。
- 视频类型必须覆盖常见的视频种类,比如电影、电视剧、动画、体育等不同场景。
- 视频时长分布尽可能广泛,不要局限于只是短视频或者只是长视频。
基于以上三个要求,该研究打标完成了 VCSL(Video Copy Segment Localization)数据集。研究者从 Youtube 和 Bilibili 上选取了 122 个种子视频,每个种子视频也与关键词相关联。在打标过程中,研究者模拟了真实情况,让打标同学进行搜索找到可能侵权的视频然后再进行打标比对,滤除不相干的视频并标注出实际侵权的时间片段。
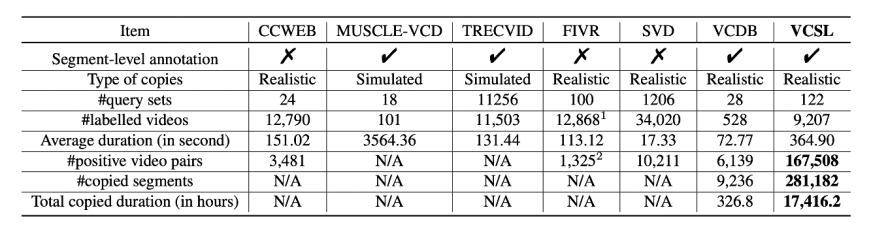
表 1. VCSL 与其他学术界现有数据集的比较
VCSL 数据集与学术界其他数据集的对比由表 1 所示,可以看到 VCSL 在侵权视频对数量和侵权片段数量上都比现有学术界数据集高出两个数量级。并且在视频时长、侵权片段时长、视频种类的分布上更加广泛。
视频片段拷贝检测的新评价指标
学术界范围内,之前在 Muscle-VCD[5]和 VCDB[4]中提出过片段级别拷贝检测的评价指标,这几年比较常见的学术界工作主要用了 VCDB[4]中定义的片段的准确率和召回率:

准确率和召回率的分子均为正确被检测到的片段,其中正确检测到的片段定义为只要与实际的侵权片段有一帧的重合即定义为正确检测。准确率的分母为所有被检测到的片段数量,召回率的分母为实际打标真实拷贝的片段数量。另外,VCDB 论文中还定义了帧的准确率和召回率:

与片段粒度类似,只不过统计维度是在帧粒度。
上述提到的片段准确率 / 召回率和帧准确率 / 召回率都有其局限性。最重要的一点是,该评价指标只适合于片段和视频的拷贝检测,即需要打标好的被侵权片段与可能侵权的视频作为输入,而不是两段完整的视频作为输入,这种评价方式在实际场景下是不现实的。同时,对于片段准确率 / 召回率,检测到的片段只要和实际的打标片段有一帧重叠就认为是正确的计算方式,会导致评价指标对侵权定位的准确度的感知比较差。另外,这些指标没有考虑到视频拷贝的一些重要特性,即下面提到的切分等效性。
之前的评价指标需要将标注好的片段和视频比较,这个并不适合于实际的应用。在该研究提出的评价指标中,他们用两个完整的视频作为输入来检测这两个视频中可能存在的拷贝片段。另外,该研究在观察视频拷贝的标注数据中发现了视频拷贝一个特性,即片段切分等效特性。这种特性是由于在某些情况下,很难确定拷贝片段的边界,如下图所示,视频部分的中间帧被修改以及短暂插入其他视频帧,如下图 2(a)所示,另外图 2(b)这种混剪的情况也类似,该研究认为在这些情况下,将拷贝视频片段标注为一整段和多段连续的片段都是合理的。因此该研究在设计新的评价指标时,需要将这种片段切分等效特性考虑进去,使得评价指标对这种切分是鲁棒的。

图 2. 视频侵权案例,(a),(b)图左侧为按时间排布的视频画面帧,右侧为视频帧序列相似图,横轴和纵轴分别代表着两个视频的时间轴,黑框内表示实际标注的侵权事件片段,详细解释图也可见于后文图 6 右侧。
这个评价指标的表示可以通过视频帧相似图进行表示,如下图所示。拷贝片段对在相似图上表现为一个检测框,而这个拷贝片段,可以表现为在相似图上的一条直线,这表示了帧的顺序对应。而橘黄色框表示实际打标的 GT 拷贝片段,蓝色框表示算法输出的预测拷贝片段。
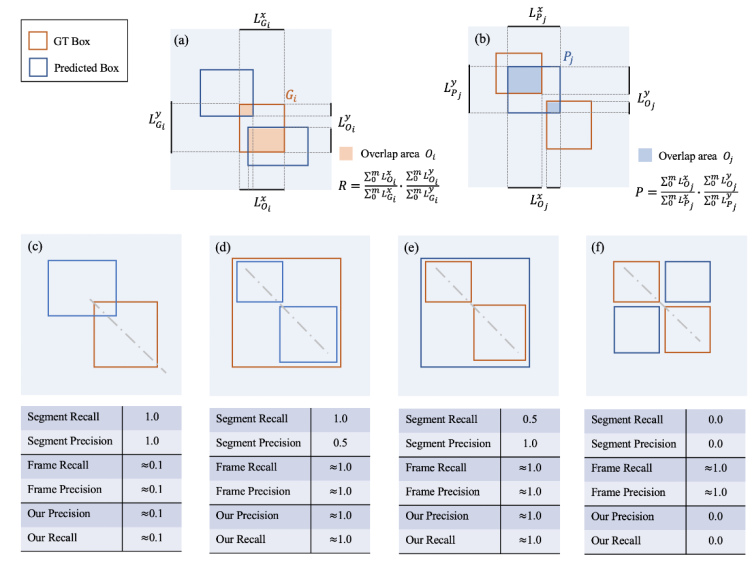
图 3. (a-b)描述了该研究提出的算法计算过程,(c-f)描述了四种对比该研究提出的评价指标和之前指标对比的简化情况。虚线表示侵权帧在时域上的位置,同时也会有其他更复杂的侵权情况表现为更复杂的 pattern。
具体来说,首先该研究找到每个 GT 框与所有的预测框的交际区域,如上图 (a) 所示,接下来计算这个交叠区域在 x 轴和 y 轴上的并集长度。同时计算出每个 GT 框的长度和宽度,最后分子为交叠区域的并集长度相加,分母为 GT 框的长度相加,即可得到 recall,如上图 (a) 所示。类似的,首先该研究找到每个预测框与所有 GT 框的交际区域,如上图 (b) 所示,接下来计算这个交叠区域在 x 轴和 y 轴上的并集长度。同时计算出每个预测框的长度和宽度,最后分子为交叠区域的并集长度相加,分母为预测框的长度相加,即可得到 precision,如上图 (b) 所示。
值得注意的是,该研究并没有用学术界常用的面积,而是采用了 x y 轴的投影进行计算,这是为了评价指标对片段切分更加鲁棒。最后,将 recall 和 precision 结合,得到 F-score,作为评价参数。

视频片段拷贝检测算法 benchmark
首先将视频拷贝检测算法的处理流程分为三个部分:视频预处理,视频特征提取和视频侵权定位,如下图所示。
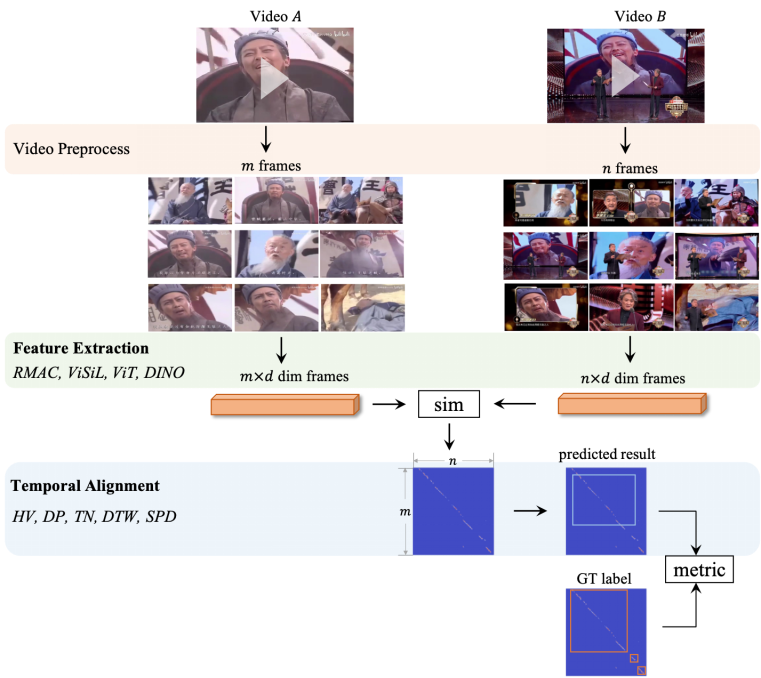
图 4. 视频拷贝检测算法处理流程。
基于 VCSL 数据集和新的评价指标,该研究首先复现了目前常见的侵权定位算法,包括霍夫投票(Hough Voting)、时域网络(Temporal Network)、动态规划(Dynamic Programming)、动态时间扭曲(Dynamic Time Warping),并结合常见的开源帧特征算法,得到如下图所示的 benchmark。
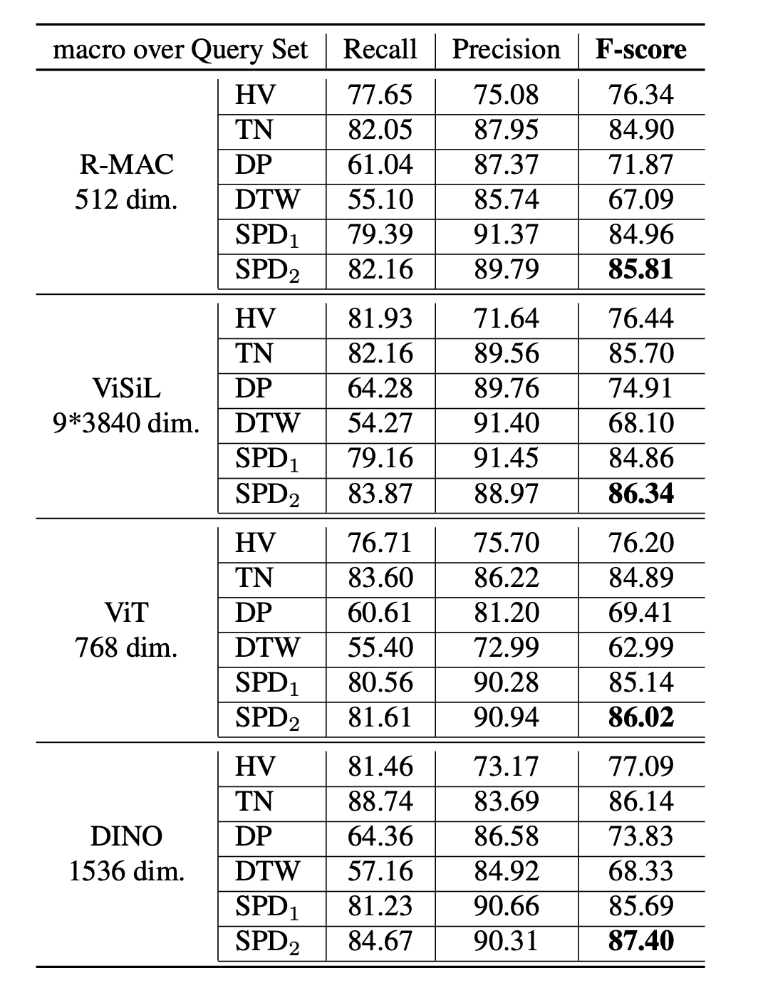
其中 SPD 是该研究团队在去年 ACM MM21 中提出的侵权定位算法,也是当前视频侵权定位效果最好的算法。其中 SPD 下划线 1 表示在之前开源数据集 VCDB 上训练的效果,下划线 2 表示在 VCSL 数据集上训练的效果。可以看到后者效果好于前者,这也说明了大规模数据集的重要性。
这里也简单介绍下该研究在 ACM MM21 上发表的论文《Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval》,他们提出了一种视频片段相似度和定位网络(Segment Similarity and Alignment Network,SSAN),主要由两个部分组成:自监督关键帧检测 (Self-supervised Keyframe Extraction,SKE) 和相似图侵权定位检测(Similarity Pattern Detection,SPD)。关键帧检测(SKE)主要用于提取鲁棒且有代表性的关键帧,去除相似冗余帧;相似图侵权定位检测(SPD)主要用于视频相似片段定位。整个 SSAN 可以端到端进行训练,得到现阶段最好的片段级别侵权定位效果。
论文地址:https://dl.acm.org/doi/abs/10.1145/3474085.3475301
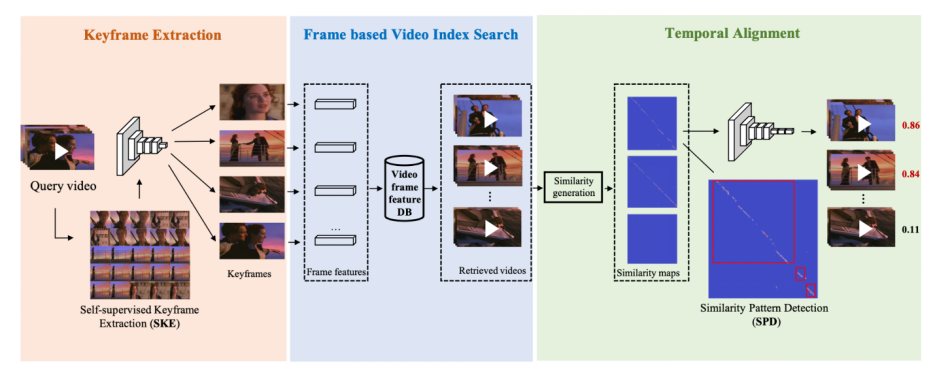
图 5. SSAN 算法结构,包括了关键帧抽取模块,基于帧的视频检索和时域侵权定位模块
在相似图侵权定位检测(SPD)这个模块中,该研究巧妙地将侵权定位问题转变成一个目标检测问题,如下图所示,这样就只需要极少的运算量就可以得到侵权定位的结果,并且具有多段侵权检测能力。
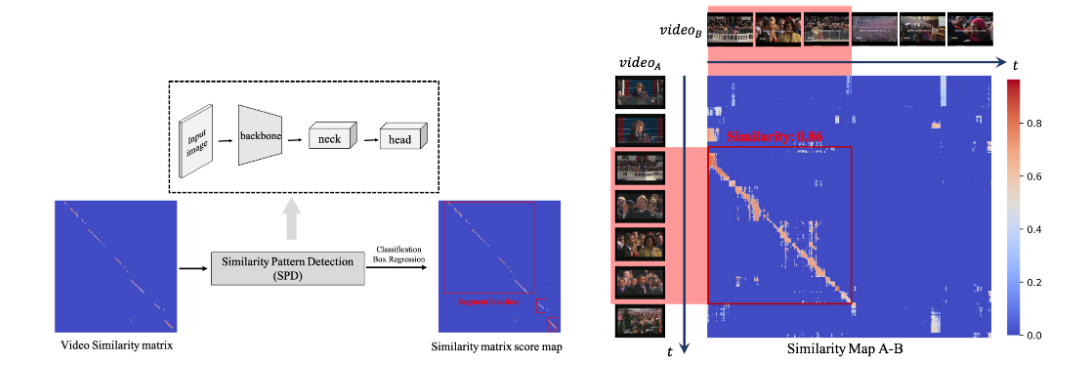
图 6. 左图,时域侵权定位 SPD 算法示意图,右图,相似图生成与原视频对示意图