Nosql数据库
NoSQL这个词,意思是 "不仅仅是SQL",最早出现在20世纪90年代末,指的是为了解决网络和云数据管理的要求,克服传统SQL技术的限制而建立的新系统(见我们的 blog post on SQL vs. NoSQL vs NewSQL不同方法之间的比较)。这些限制是缺乏横向可扩展性,数据摄取效率低,模式僵化,以及难以支持复杂的数据,如文档和图表。

图1:传统的SQL数据库
作为支持标准关系模型的传统SQL数据库的替代品,NoSQL系统支持标准SQL以外的数据模型和查询语言。它们通常强调可扩展性(以牺牲一致性为代价)、灵活的模式和实用的API,用于编程复杂的数据密集型应用。为了提供可扩展性,NoSQL系统通常在一个无共享的集群中使用扩展的方法(见 blog post on shared-nothing),并进行复制以保证可用性。
大数据软件栈中的nosql
根据底层数据模型,NoSQL系统有四大类(Özsu & Valduriez, 2020),例如,键值数据存储、宽列存储、文档存储和图形数据库。在每个类别中,我们可以找到数据模型的不同变化(与标准化的关系数据模型不同)和不同的查询语言或API。然而,对于文档存储,JSON正在成为事实上的标准。还有一些多模型数据存储,在一个系统中结合了多种数据模型,通常是文档和图形。
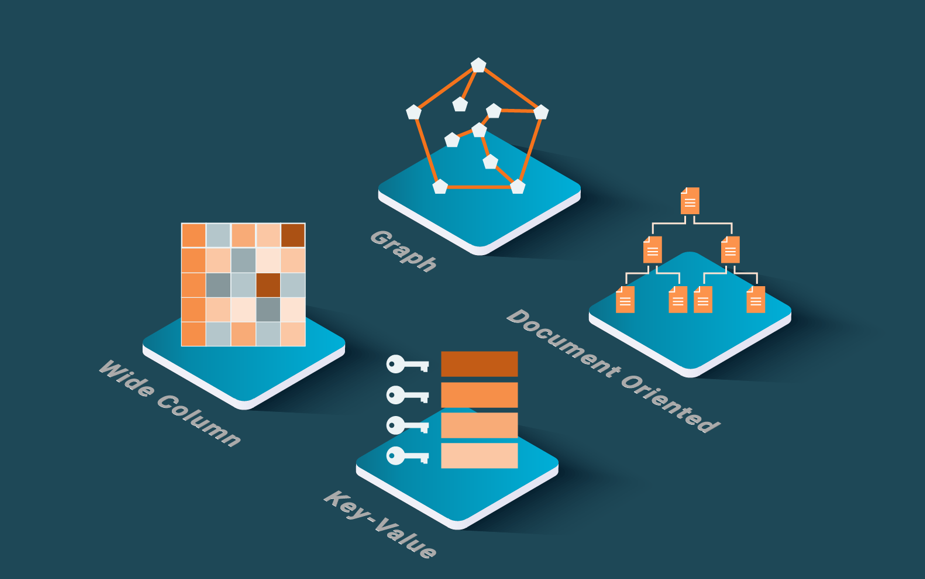
图2:NoSQL类别
键值数据存储和宽列存储
键值数据存储和宽列存储有时被归为同一类,因为它们都是无模式的,并且共享许多特征。在键值数据模型中,所有的数据都被表示为键值对,其中键是唯一的标识值。键值系统是无模式的,这产生了巨大的灵活性和可扩展性。它们通常提供一个简单的接口,如put(key,value),value=get(key),and delete(key)。宽列存储可以将行存储为属性-值对的列表。第一个属性被称为主键或主键,例如,社会安全号码,它在一个行的集合中唯一地识别一个行,例如,人。键通常是排序的,这使得范围查询和键的有序处理成为可能。这是宽列存储的一种能力,键值存储通常不支持。
键值数据存储有一个分布式的架构,在一个无共享的集群中可以线性扩展。一个键值集合的行通常是水平分区的,使用散列或键值范围,并存储在一些集群节点上。键值数据存储也善于使用SSTables有效地摄取数据(他们声称使用LSM树,但实际上使用SSTables,见我们的 blog post on B+ Trees, LSM trees and SSTables),这是一种数据结构和摄取算法,通过使用单个I/O来插入许多行,在摄取数据方面非常高效。键值数据存储解决了僵化的模式问题,仅仅是通过无模式,每一行都可以有不同的结构,即任意的列集。
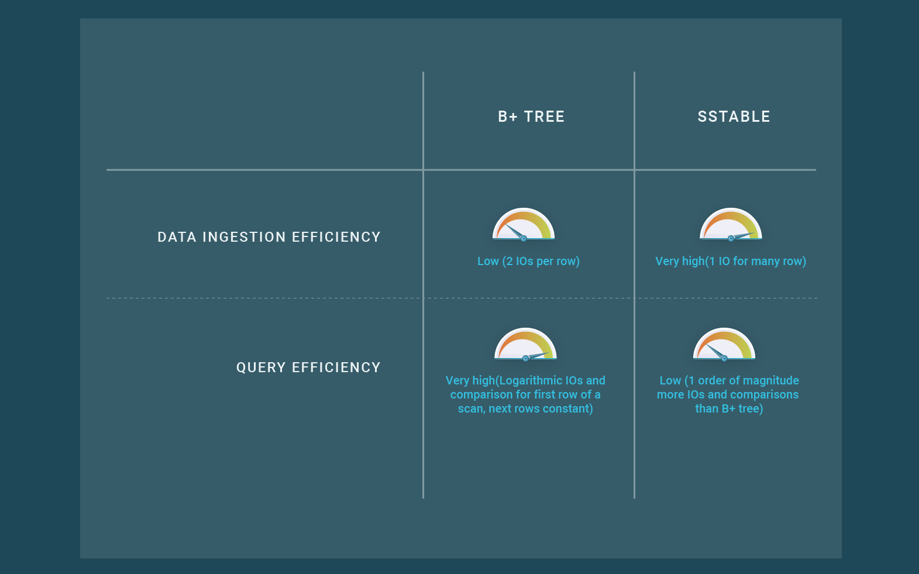
图3:B+树和SST表的比较
键值数据存储的这些新特性影响了性能。首先,SST表格在查询数据方面的效率很低,所以在键值数据存储中读取数据的成本要比使用B+树的SQL数据库高很多。其次,模式的灵活性意味着数据表示在空间方面变得更加昂贵,因为列名必须被编码并存储在行内。更重要的是,一般用于打包相同大小的列的技术不能被应用,所以数据表示的效率更低。由于其固定的模式,SQL数据库可以在行中组织列,在空间和访问时间方面非常有效。
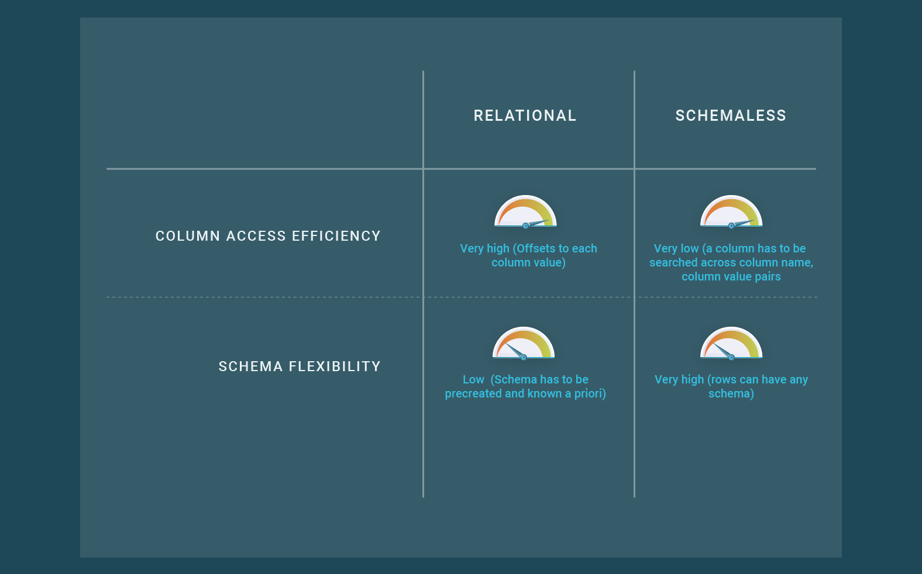
图4:关系型和无模式型方法的比较
最后,键值存储以强大的数据一致性换取可扩展性和可用性,依赖于不同的控制一致性的方式,如副本的最终一致性,有条件的写入,以及最终一致性和强一致性的读取。

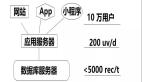
图5:键值数据存储的属性
宽列存储结合了SQL数据库的一些有益特性(例如,以表的形式表示数据)和键值存储的灵活性(例如,列内无模式数据)和可扩展性。宽列表中的每一行都由一个键唯一标识,并有一些命名的列。然而,与关系表不同的是,列只能包含原子值(即二进制字符串),一个列可以很宽,包含多个键值对。宽列存储用更多的声明性结构扩展了键值存储接口,允许对列族进行扫描、精确匹配和范围查询。它们通常为这些结构提供一个API,以便在编程语言中使用。

图6:键值和宽列存储的比较