













1. Druid简介
1. 1 概述
Druid是一个快速的列式分布式的支持实时分析的数据存储系统。它在处理PB级数据、毫秒级查询、数据实时处理方面,比传统的OLAP系统有了显著的性能改进。
OLAP分析分为关系型联机分析处理(ROLAP)、多维联机分析处理(MOLAP)两种,MOLAP需要数据预计算好为一个多维数组,典型方式就是Cube,而ROLAP就是数据本身什么样就是什么样,查询时通过MPP提高分布式计算能力。
Druid是ROLAP路线,实时摄取数据,实时出结果,不像Kylin一样,有一个显式的预计算过程。
1.1.2 补充
MPP:俗称大规模并行处理,数据库集群中,每个节点都有独立的磁盘存储系统跟内存系统,业务数据根据数据库模型跟应用特点被划分到各个节点,MPP就是将任务并行分散到多个节点,每个节点计算完毕后将结果汇总下来得到最终结果。
Lambda架构:该 架构的设计是为了在处理大规模数据时,同时发挥流处理和批处理的优势。通过批处理提供全面、准确的数据,通过流处理提供低延迟的数据,从而达到平衡延迟、吞吐量和容错性的目的。为了满足下游的即席查询,批处理和流处理的结果会进行合并。一般有三层。
Batch Layer:批处理层,对离线的历史数据进行预计算。
Speed Layer:加速处理层,处理实时的增量数据。
Serving Layer:合并层,计算历史数据和实时数据都有了。
注意:阿里巴巴也曾创建过一个开源项目叫作Druid(简称阿里Druid),它是一个数据库连接池的项目。阿里Druid和本文讨论的Druid没有任何关系,它们解决完全不同的问题。
1.2 Druid 特点
- 低延迟交互式查询:Druid提供低延迟实时数据摄取(⼊库),典型的lambda架构。并采⽤预聚合、列式存储、位图索引等⼿段使得海量数据分析能够亚秒级响应。
- ⾼可⽤性( High Available ):Druid 使⽤用 HDFS/S3 作为 Deep Storage,Segment 会在多个Historical 节点上进行加载,摄取数据时也可以多副本摄取,保证数据可⽤性和容错性。
- 可伸缩( Horizontal Scalable ):Druid 部署架构都可以⽔平扩展,增加大量服务器来加快数据摄取,以保证亚秒级的查询服务。集群扩展和缩小,只需添加或删除服务器,集群将在后台自动重新平衡,无需任何停机时间。
- 并行处理( Parallel Processing ): Druid 可以在整个集群中进行大规模的并行处理查询(MPP)。
- 丰富的查询能力( Rich Query ):Druid支持时间序列、 TopN、 GroupBy等查询,同时提供了2种查询方式:API 和 SQL(功能较少)。
1.3 Druid 适用 & 不适用场景
⼀句话总结,Druid适合带时间维度、海量数据的实时/准实时分析
- 带时间字段的数据,且时间维度为分析的主要维度。
- 快速交互式查询,且亚秒级快速响应。
- 多维度海量数据,能够预先定义维度。
- 适用于清洗好的记录实时录入,但不需要更新操作。
- 适用于支持宽表,不用Join的方式(换句话说就是一张单表)。
- 适用于可以总结出基础的统计指标,用一个字段表示。
- 适用于对数据质量的敏感度不高的场景(原生版本非精确去重)。
Druid 不适合的场景
- 要求明细查询(破解⽅法是数据冗余)。
- 要求原⽣生Join(提前Join再入Druid)。
- 没有时列或者不以时间作为主要分析维度。
- 不支持多时间维度,所有维度均为string类型。
- 想通过单纯SQL语法查询。
1.4 横向对比

产品对比
- Druid:是一个实时处理时序数据的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。提起预聚合了模型,不适合即席查询分享,不支持JOIN,SQL支持鸡肋,不适合明细查询。
- Kylin:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。不适合即席查询(提前定于模型预聚合,预技术量大),不支持明细查询,外部依赖较多,不支持多事实表Join。
- Presto:它没有使用MapReduce,大部分场景下比Hive快一个数量级,其中的关键是所有的处理都在内存中完成。不支持预聚合,自己没存储。
- Impala:基于内存运算,速度快,支持的数据源没有Presto多。不支持预聚合,自己没存储。
- Spark SQL:基于Spark平台上的一个OLAP框架,基本思路是增加机器来并行计算,从而提高查询速度。
- ElasticSearch:最大的特点是使用了倒排索引解决索引问题。根据研究,ES在数据获取和聚集用的资源比在Druid高。不支持预聚合,不适合超大规模数据处理,组合查询性能欠佳。
- ClickHouse:C++编写的高性能OLAP工具,不支持高并发,数据量超大会出现瓶颈(尽量选择预聚合出结果表),贼吃CPU资源(新版支持MVCC)。
- 框架选型:从超大数据的查询效率来看 Druid > Kylin > Presto > Spark SQL,从支持的数据源种类来讲 Presto > Spark SQL > Kylin > Druid。
2. Druid 架构
Druid为了实现海量数据实时分析采⽤了⼀些特殊的⼿段和⽐较复杂的架构,大致分两节分别介绍。
2.1 Druid 核心概念
Druid能实现海量数据实时分析,主要采取了如下特殊手段。
- 预聚合。
- 列式存储。
- 多级分区 + 位图索引(Datasource、Segments)。
2.1.1 roll up 预聚合
分析查询逃不开聚合操作,Druid在数据⼊库时就提前进行了聚合,这就是所谓的预聚合(roll-up)。Druid把数据按照选定维度的相同的值进行分组聚合,可以⼤大降低存储⼤小。数据查询的时候只需要预聚合的数据基础上进行轻量的⼆次过滤和聚合即可快速拿到分析结果,当然预聚合是以牺牲明细数据分析查询为代价。
要做预聚合,Druid要求数据能够分为三个部分:
- Timestamp列:Druid所有分析查询均涉及时间(思考:时间实际上是⼀个特殊的维度,它可以衍⽣出一堆维度,Druid把它单列列出来了)
- Dimension列(维度):Dimension列指⽤于分析数据⻆度的列,例如从地域、产品、用户的角度来分析订单数据,一般⽤用于过滤、分组等等。
- Metric列(度量):Metric列指的是⽤于做聚合和其他计算的列。⼀般来说是数字。
{"timestamp":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":20,"bytes":9024}
{"timestamp":"2018-01-01T01:01:51Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":255,"bytes":21133}
{"timestamp":"2018-01-01T01:01:59Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":11,"bytes":5780}
{"timestamp":"2018-01-01T01:02:14Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":38,"bytes":6289}
{"timestamp":"2018-01-01T01:02:29Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":377,"bytes":359971}
{"timestamp":"2018-01-01T01:03:29Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":49,"bytes":10204}
{"timestamp":"2018-01-02T21:33:14Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":38,"bytes":6289}
{"timestamp":"2018-01-02T21:33:45Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":123,"bytes":93999}
{"timestamp":"2018-01-02T21:35:45Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":12,"bytes":2818}
比如上面这样一份明细数据,timestamp当然是Timestamp列,srcIP和dstIP是Dimension列(维度),packets和bytes是Metric列。该数据⼊库到Druid时如果我们打开预聚合功能(可以不打开聚合,数据量⼤大就不⾏了),要求对packets和bytes进⾏行行累加(sum),并且要求按条计数(count *),聚合之后的数据是这样的:
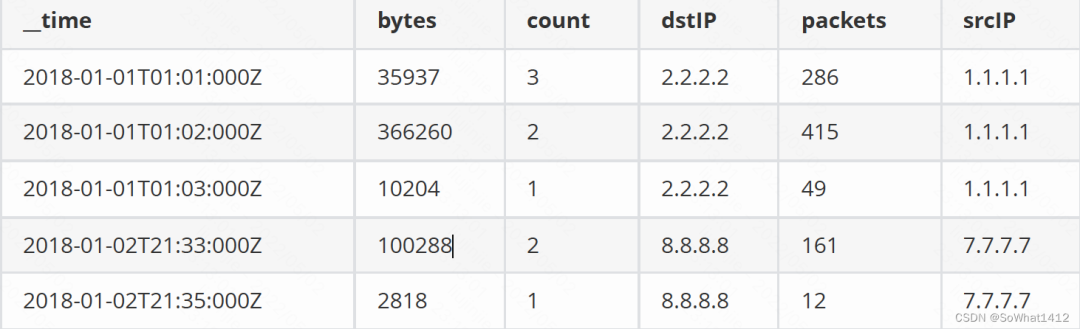
聚合后数据
2.1.2 列式存储
行式:
行式存储查询
列式:

列式存储查询
在大数据领域列式存储是个常见的优化手段,一般在OLTP数据库会用行式存储,OLAP数据库会使用列式存储。列式存储一般有如下优点:
对于分析查询,⼀般只需要⽤到少量的列,在列式存储中,只需要读取所需的数据列即可。例例如,如果您需要100列列中的5列,则I / O减少20倍。
按列分开存储,按数据包读取时因此更易于压缩。列中的数据具有相同特征也更易于压缩, 这样可以进⼀步减少I / O量。
由于减少了I / O,因此更更多数据可以容纳在系统缓存中,进⼀步提⾼分析性能。
2.1.3 DataSource & Segments
Druid的数据在存储层面是按照Datasource和Segments实现多级分区存储的,并建⽴了位图索引。
- Datasource相当于关系型数据库中的表,
- Datasource会按照时间来分片(类似于HBase⾥里里的Region和Kudu⾥的tablet),每⼀个时间分⽚被称为chunk,
- chunk并不是直接存储单元,在chunk内部数据还会被切分为⼀个或者多个segment。所有的segment独⽴立存储,通常包含数百万⾏行行,segment与chunk的关系如下图:
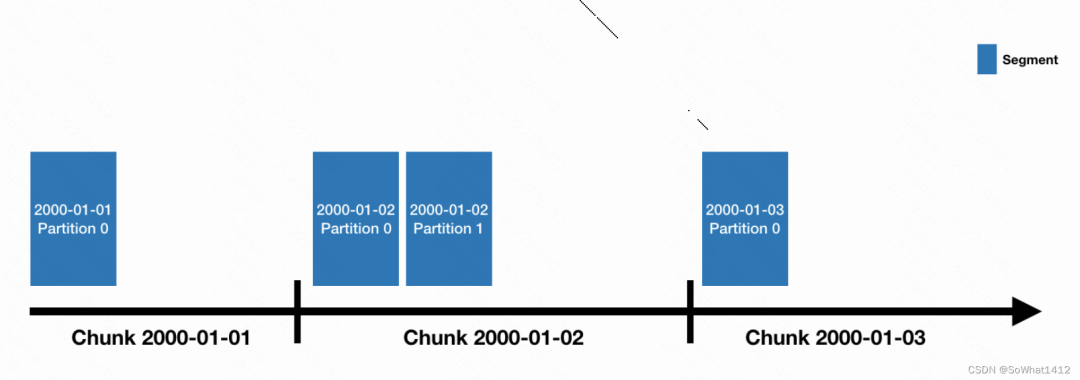
Segment跟Chunk
Segment是Druid数据存储的最小单元,内部采用列式存储,建立了位图索引,对数据进行了编码跟压缩。
Druid数据存储的摄取方式、聚合方式、每列数据存储的字节起始位都有存储。
2.1.4 位图索引
假设现有这样一份数据:
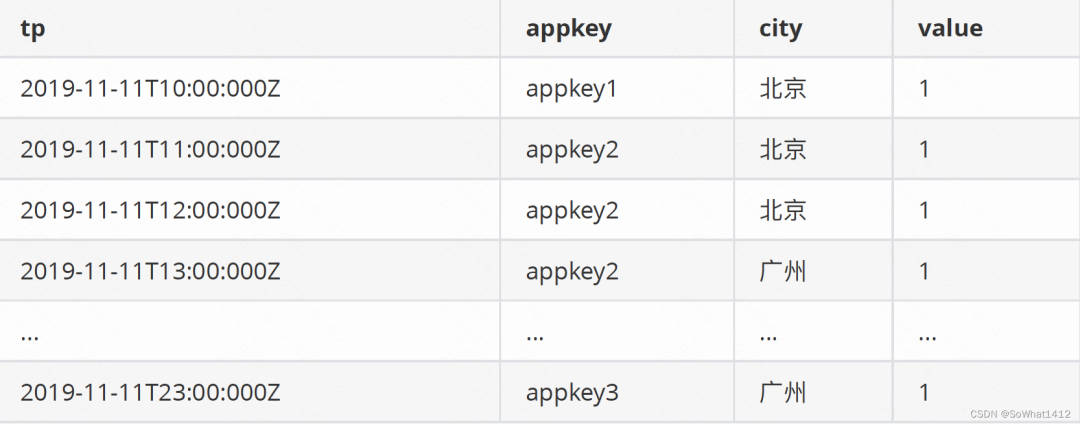
原始数据
以tp为时间列,appkey和city为维度,以value为度量值,导⼊Druid后按天聚合,最终结果是:
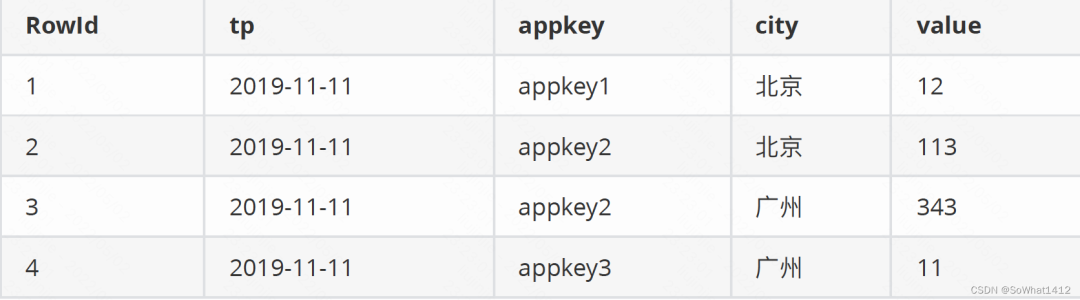
聚合后
数据经过聚合之后查询本身就很快了,为了进⼀步加速对聚合之后数据的查询,Druid会建立位图索引:
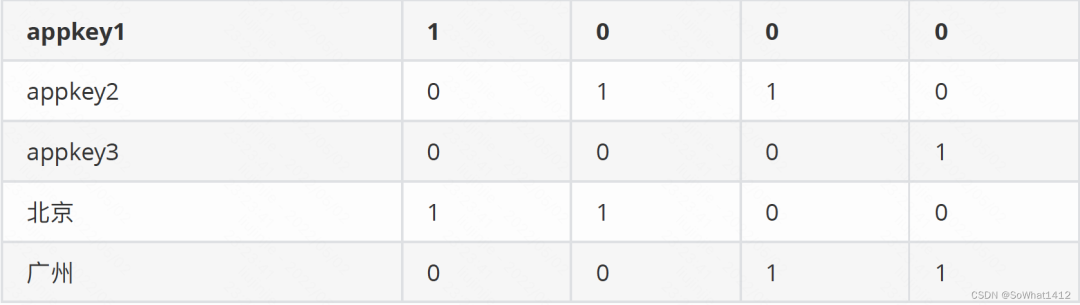
位图索引
上⾯的位图索引不是针对列⽽是针对列的值,记录了列的值在数据的哪⼀行出现过,第一列是具体列的值,后续列标识该列的值在某⼀⾏是否出现过,依次是第1列到第n列。例如appkey1在第⼀⾏出现过,在其他⾏没出现,那就是1000(例子中只有四个列)。
Select sum(value) from xxx where time=’2019-11-11’and appkey in
(‘appkey1’,’appkey2’) and area=’北京’
当我们有如上查询时,⾸先根据时间段定位到segment,然后根据appkey in (‘appkey1’,’appkey2’) and area=’北京’ 查到各⾃的bitmap:(appkey1(1000) or appkey2(0110)) and 北京(1100) = (1100) 也就是说,符合条件的列是第⼀行和第⼆行,这两⾏的metric的和为125.
2.2 Druid 架构
2.2.1 核心架构
Druid在架构上主要参考了Google的Dremel,PowerDrill。
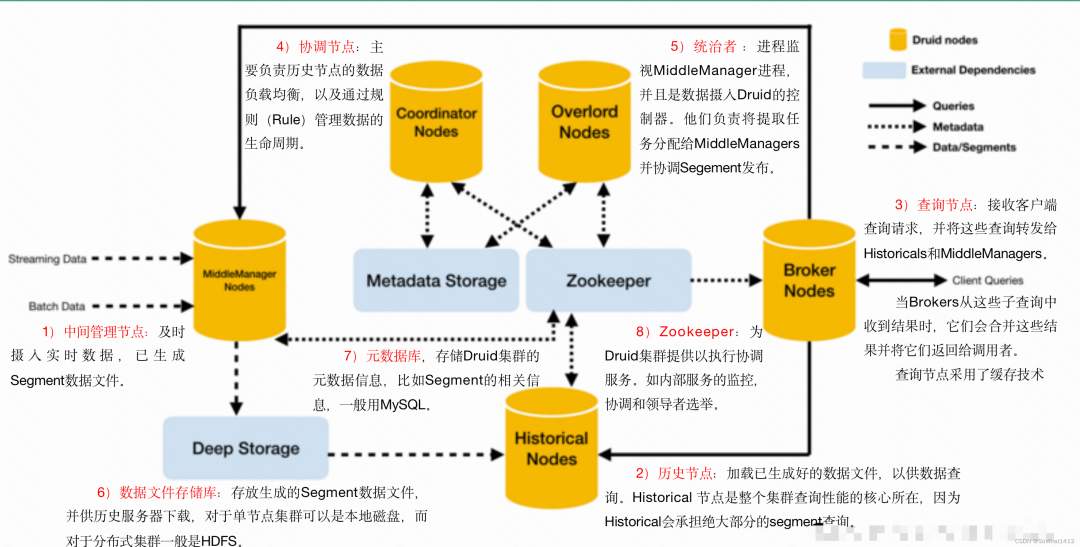
Druid官方架构图
Druid核⼼架构中包括如下节点(Druid 的所有功能都在同⼀个包,通过不同的命令启动):
- Coordinator: 负责集群 Segment 的管理和发布,并确保 Segment 在 Historical 集群中的负载均衡。
- Broker : 负责从客户端接收查询请求,并将查询请求转发给 Historical 节点和MiddleManager 节点。Broker 节点需要感知 Segment 信息在集群上的分布。
- Historical :负责按照规则加载Segment并提供历史数据的查询。
- Router(可选) :可选节点,在 Broker 集群之上的API⽹网关,有了 Router 节点 Broker 不不在是单点服务了,提⾼高了并发查询的能力,提供类似Nginx的功能。
- Indexing Service : Indexing Service顾名思义就是指索引服务,在索引服务⽣成segment的过程中,由OverlordNode接收加载任务,然后⽣成索引任务(Index Service)并将任务分发给多个MiddleManager节点,MiddleManager节点根据索引协议⽣生成多个Peon,Peon将完成数据的索引任务并⽣成segment,并将segment提交到分布式存储⾥面(⼀般是HDFS),然后Coordinator节点感知到segment⽣成,给Historical节点分发下载任务,Historical节点从分布式存储⾥面下载segment到本地(⽀持量和流式摄取)。
- Overlord : Overlord Node负责segment生成的任务,并提供任务的状态信息,当然原理跟上⾯类似,也在Zookeeper中对应的⽬录下,由实际执行任务的最⼩单位在Zookeeper中同步更新任务信息,类似于回调函数的执⾏过程。跟Coordinator Node⼀样,它在集群里⾯⼀般只存在一个,如果存在多个Overlord Node,Zookeeper会根据选举算法(⼀一致性算法避免脑裂)产⽣生⼀一个Leader,其余的当Follower,当Leader遇到问题宕机时,Zookeeper会在Follower中再次选取⼀一个Leader,从⽽维持集群⽣成segment服务的正常运行。Overlord Node会将任务分发给MiddleManager Node,由MiddleManager Node负责具体的segment⽣成任务。
- MiddleManager : Overlord Node会将任务分发给MiddleManager Node,所以MiddleManager Node会在Zookeeper中感知到新的索引任务。⼀但感知到新的索引任务,会创建Peon(segment具体执⾏者,也是索引过程的最⼩单位)来具体执行索引任务,一个 MiddleManager Node会运行很多个Peon的实例。
简单来说:
- coordinator : 管理集群的数据视图,segment的load与dropr。
- historical : 历史节点,负责历史窗⼝口内数据的查询r。
- broker : 查询节点,查询拆分,结果汇聚r。
- indexing service : ⼀套实时/批量数据导⼊任务的调度服务r。
- overlord : 负责接收任务,管理理任务状态,类似Hadoop中ResourceManager。
- middleManager : 接受任务启动任务,类似Hadoop中NodeManager。
- peon : 实际的任务进程,类似Hadoop中的container。
总结下大致查询链路,查询打到Router, Router选择对应的broker,broker会根据查询时间,查询属性等因素来进行segment筛选。broker会查找到对应的Historical跟MiddleManager节点,这俩节点会重写为子查询,然后最终把结果汇总到broker,需要注意middleManager可以查询没有发布到历史节点的数据,这样Druid可以进行近实时查询。
Druid通过下面三种优化方法提高查询性能:
- Segment 裁剪。
- 对于每个Segment,通过索引过滤指定行。
- 制度去结果所需的行列。
2.2.2 外部依赖
- Zookeeper :主要用于内部服务发现,协调跟leader选举。
- 深度存储(Deep Storage) : 深度存储服务是能够被每个Druid服务能访问到的共享文件系统,一般类似S3、HDFS或网络文件系统。
- 元数据存储(Metadata Store) : 元数据存储服务主要用来存储Druid中一些元数据,比如segment相关信息,跟Hadoop一样,一般把数存储到MySQL中。
3. 数据摄取
3.1 摄取分类
目前Druid数据摄取主要有批量跟流式两大类。
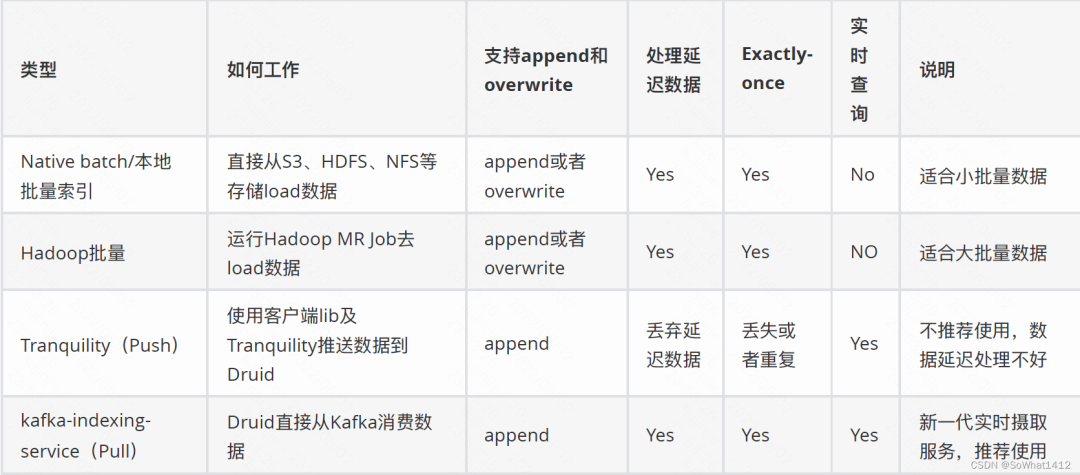
数据摄取
Druid的indexing-service即⽀持批量也支持流式,上表中的Native batch/本地批量索引和kafkaindexing-service(Pull)均使⽤用了了indexing-service,只不过通过摄取任务类型来区分。
3.2 Index Service
Index Service是运行索引相关任务的⾼可⽤性分布式服务,它的架构中包括了了Overlord、MiddleManager、Peon。简单理解:
- Indexing Service : ⼀套实时/批量数据导⼊任务的调度服务。
- Overlord-调度服务的master节点,负责接收任务,管理理任务状态。
- MiddleManager-worker节点,接收任务启动任务。
- Peon-实际的任务进程(Hadoop批量索引方式下,Pero就是YARN client)。
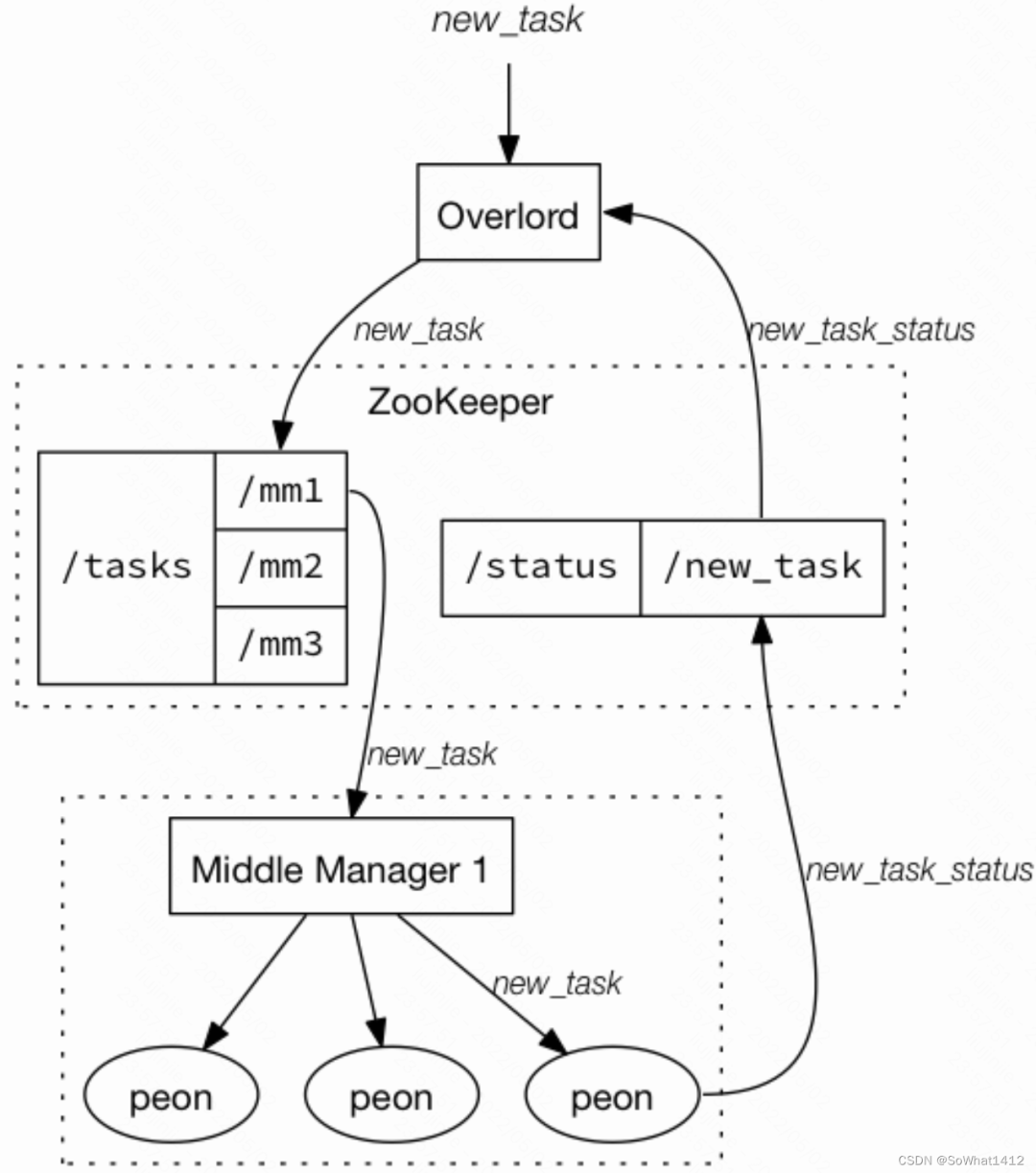
index Service工作流程
在上图中,通过index-service的方式批量摄取数据,我们需要向Overlord提交⼀个索引任务,Overlord接受任务,通过Zookeeper将任务信息分配给MiddleManger,Middlemanager领取任务后创建Peon进程,Peon通过Zookeeper向Overlord定期汇报任务状态。
3.3 摄取规则
Druid⽀持批量数据摄⼊和实时流数据摄入两种数据摄⼊方式,⽆论是哪种⽅式都得指定⼀个摄取规则⽂文件(Ingestion Spec)定义摄取的详细规则(类似于Flume采集数据都得指定⼀个配置文件⼀样)。
数据摄取时type可指定为index、index_hadoop、kafka这三种,然后可以尝试通过本地、HDFS、Kafka准备数据源,准备好数据摄取规则文件。
4. 查询
Druid⼀直提供REST API进行数据查询,在0.10之前第三方提供SQL⽀持,但不是很成熟,从0.10开始原生提供实验性SQL查询功能,截⽌Druid0.12.3还是处于实验性阶段。

查询方式
4.1 REST API 查询
用户可通过REST API的方式将请求包装为JSON格式进行查询,返回的结果也是JSON格式,接下来主要说明下请求JSON的格式。
4.2 Filter
Filter就是过滤器,⽤用对维度进行行筛选和过滤,满⾜Filter的行将会被返回,类似sql中的where⼦句。
- Selector Filte : 类似于SQL中的where colname=value。
- Regex Filter : 使用Java支持的正则表达式进行维度过滤筛选。
- In Filter : 类似于SQL中的in语句。
- Bound Filter : 比较过滤器,包含⼤于,等于,⼩于三种,它默认支持的就是字符串串⽐比较,如果使用数字进行比较,需要在查询中设定alpaNumeric的值为true,需要注意的是Bound Filter默认的⼤小⽐较为>=或者<=,因此如果使用<或>,需要指定lowerStrict值为true,或者upperStrict值为true。
- Logincal Expression Filter : 包含and,not,or三种过滤器器,⽀持嵌套,可以构建丰富的逻辑表达式,与sql 中的and、not、or类似。
4.3 granularity
granularity 配置项指定查询时的时间聚合粒度,查询时的时间聚合粒度要 >= 创建索引时设置的索引粒度,druid提供了了三种类型的聚合粒度分别是:Simple、Duration、Period。
Simple :druid提供的固定时间粒度,⽤字符串串表示,默认就是Simple,定义查询规则的时候不需要显示设置type配置项,druid提供的常⽤用Simple粒度:
all:会将起始和结束时间内所有数据聚合到⼀一起返回⼀一个结果集,
none:按照创建索引时的最⼩粒度做聚合计算,最⼩粒度是毫秒为单位,不推荐使⽤,性能较差
minute:以分钟作为聚合的最⼩小粒度
fifteen_minute:15分钟聚合
thirty_minute:30分钟聚合
hour:⼀小时聚合
day:天聚合
month:按年年聚合
quarter:按季度聚合
Duration : 对Simple的补充,duration聚合粒度提供了了更更加灵活的粒度,不不只局限于Simple聚合粒度提供的固定聚合粒度,⽽是以毫秒为单位⾃定义聚合粒度。
⽐如两小时做⼀次聚合可以设置duration配置项为7200000毫秒,
所以Simple聚合粒度不能够满⾜足的聚合粒度可以选择使⽤用Duration聚合粒度。
注意:使⽤用Duration聚合粒度需要设置配置项type值为duration。
Period : 聚合粒度采⽤了⽇期格式,常⽤的⼏种时间跨度表示⽅法。
一小时:PT1H
一周:P1W
⼀天:P1D
⼀月:P1M
注意: 使⽤Period聚合粒度需要设置配置项type值为period
4.4 Aggregator
聚合器在数据摄⼊和查询是均可以使用,在数据摄⼊]入阶段使⽤]用聚合器能够在数据被查询之前按照维度进行聚合计算,提⾼查询阶段聚合计算性能,在查询过程中,使⽤聚合器能够实现各种不同指标的组合计算。
公共属性:
- type : 声明使⽤用的聚合器器类型
- name : 定义返回值的字段名称,相当于sql语法中的字段别名
- fieldName : 数据源中已定义的指标名称,该值不可以⾃自定义,必须与数据源中的指标名⼀致
4.4.1 常见聚合器
- count
计数聚合器,等同于sql语法中的count函数,⽤于计算druid roll-up合并之后的数据条数,并不是原始数据条数。
在定义数据模式指标规则中必须添加⼀个count类型的计数指标count;
{"type":"count","name":out_name}
如果想要查询原始数据摄⼊入多少条,在查询时使⽤用longSum,JSON示例例如下:
{"type":"longSum","name":out_name,"fieldName":"count"}
- sum
求和聚合器,等同于sql语法中的sum函数,druid提供两种类型的聚合器,分别是long类型和double类型的聚合器。
longSum
doubleSum
floatSum
- Min/Max
类似SQL语法中的Min/Max
longMin
longMax
doubleMin
doubleMax
floatMin
floatMax
4.4.2 去重
原生 Druid 去重功能支持情况
- 维度列
仅支持单维度,构建时需要基于该维度做 hash partition。
不能跨 interval 进行计算。
cardinality agg,非精确,基于 hll 。查询时 hash 函数较耗费 CPU。
嵌套 group by,精确,耗费资源。
社区 DistinctCount 插件,精确,但是局限很大。
- 指标列
HyperUniques/Sketch,非精确,基于 hll,摄入时做计算,相比 cardinality agg 性能更高。
结论:Druid 缺乏一种支持预聚合、资源占用低、通用性强的精确去重支持。用户可自己基于bitmap、unique做二次开发精确去重。
4.4.3 Post Aggregator
Post-Aggregator可以对结果进⾏行⼆次加工并输出,最终的输出既包含Aggregation的结果,也包含Post-Aggregator的结果,Post-Aggregator包含的类型:
- Arithmetic Post-Aggregator ⽀持对Aggregator的结果进行加减乘除的计算。
- Field Accessor Post-Aggregator 返回指定的Aggregator的值,在Post-Aggregator中大部分情况下使⽤用fieldAccess来访问Aggregator,在fieldName中指定Aggregator里定义的name。
4.5 查询类型
druid的查询分为三大类,分别是聚合查询,元数据查询以及普通查询。
普通的查询:
Select
Scan
Search
聚合查询:
Timeseries
TopN
GroupBy
元数据查询:
Time Bounding
Segment Metadata
DataSource Metadata
普通的查询没什么好讲的,只有一个需要注意的点,那就是select在查询大量的数据的时候,很消耗内存,如果没有分页的需求,可以用scan替代。
元数据的查询,主要不是基于业务的查询,而是对当前表的属性,或者是定义列的类型这一类属性的查询,比如xxx表中"country"是什么类型的数据,xxx表收集数据起止时间,或者当前分段的版本是什么之类的信息。
主要需要理解的是三种内置的聚合查询,本质上做的操作是这样的。
- timeseries: 时序查询,实际上即是对数据基于时间点(timestamp)的一次上卷。适合用来看某几个度量在一个时间段内的趋势。排序可按时间降序或升序。
- topN: 在时间点的基础上,又增加了一个维度(OLAP的概念算两个维度),进而对源数据进行切片,切片之后分别上卷,最后返回一个聚合集,你可以指定某个指标作为排序的依据。官方文档称这对比单个druid dimension 的groupBy 更高效。适合看某个维度下的时间趋势,(比如美国和中国十年内GDP的增长趋势比对,在这里除了时间外国家就是另外一个维度)。
- GroupBy: 适用于两个维度以上的查询,druid会根据维度切块,并且分别上卷,最后返回聚合集。相对于topN而言,这是一个向下钻取的操作,每多一个维度意味着保留更多的细节。(比如增加一个行业的维度,就可以知道美国和中国十年内,每一年不同行业贡献GDP的占比)。
一般在查询时需要指定若干参数的。
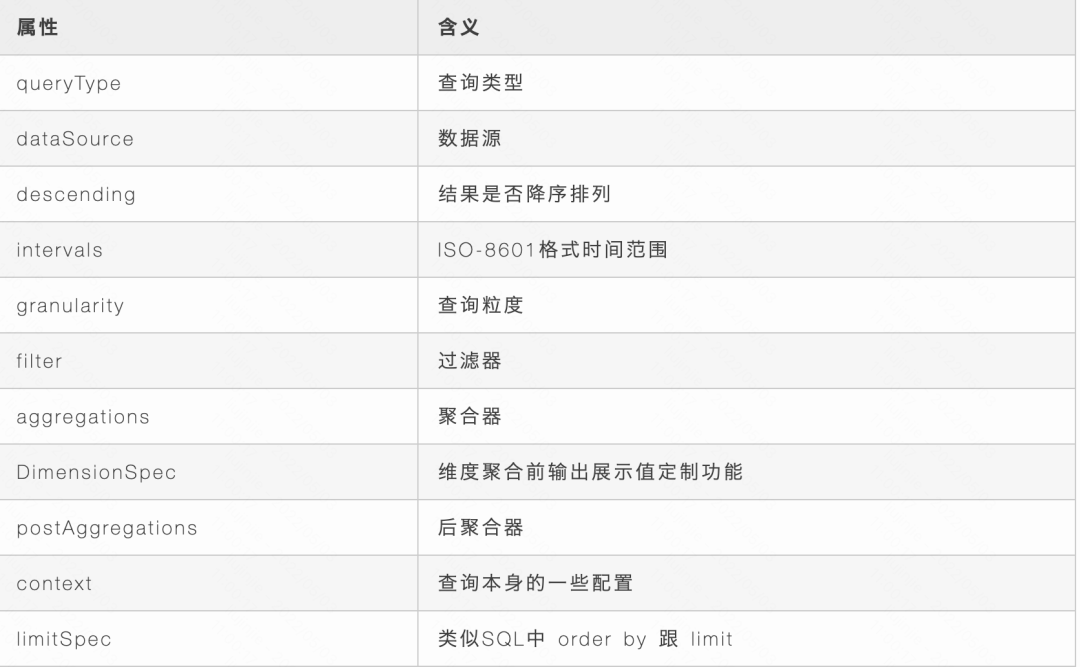
参考
Druid官网:https://druid.apache.org
快手Druid实战:https://toutiao.io/posts/9pgmav/preview
















