Nodejs是一个高效的异步服务平台,因此非常适合于开发高并发的后台服务。要满足高并发,后台服务需要做到的是能够及时响应客户端发送过来的请求。这里要注意的是”响应“而不是”完成“,客户端可能要求后台从数据库查询特定数据,后台接收请求后会告诉客户端”你的要求我收到而且正在处理,当我处理完成了再通知你”。由此NodeJS能完成高并发的原因在于,它会将那些耗时长的处理提交给线程池处理,它的主线程则一直响应客户端的请求,等到线程池把耗时久的任务完成,主线程拿到结果后再发送给对应的客户。
因此NodeJS的基本模式是,由一个主线程不断接收客户端请求,如果请求需要一定时间才完成,主线程会将任务丢给线程池,然后继续回头处理其他客户的请求。在主线程的循环中,它会不断轮询特定队列,看看是否有数据可以处理,如果有那么它就从队列中取下来,然后将数据进行处理后发送给需要的客户端。由于主线程不用长时间阻塞,因此它能够在给定时间内对大量的客户端请求进行响应,这是它能实现高并发的原因。
主线程不断轮询特定队列是否有数据的过程也叫event loop。其基本流程如下:
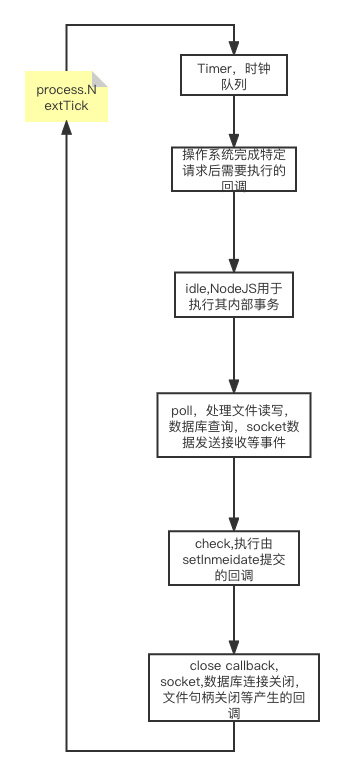
NodeJS代码的特点在于,任何我们自己写的代码,它在执行时一定在主线程中,而且你不用担心因多线程导致的重入等问题。在NodeJS代码中,一旦有异步调用产生,执行流就会将这个调用提交给它的线程池,然后直接指向异步调用后面的代码,例如:
console.log(1)
setTimer(()=>{console.log(2), 0)
console.log(3)
上面代码运行时输出结果是1,3,2,这是因为setTimer是异步函数,在主线程里不会得到执行,主线程会把这个时钟任务交给线程池,等到时钟结束后,里面的回调就会放置在上图中的时钟队列,因此主线程会越过setTimer直接指向它后面的语句,等到主线程下次循环到上图中的时钟队列位置时才会把setTimer设置的回调函数拿出来执行。
由此对于NodeJS的event loop来说它包含若干个阶段,每个阶段对应上图的一个方块。在每个阶段,主线程会从对应队列中获取数据返回给客户端,或者是将存储在队列中的回调函数进行执行,当队列清空,或者访问的队列元素超过给定值后就会进入下一个阶段。
从上图可以看出,所有时钟相关的回调都在Timer阶段执行,例如代码使用setTimer, setInterval等接口时,NodeJS会把时钟请求提交给操作系统,一旦时钟结束后,操作系统会通知NodeJS,后者就会把时钟对应的回调挂入Timer阶段对应的队列。第二个阶段是操作系统在某项情况下需要通知特定事件给NodeJS,例如TCP连接请求被拒绝,数据库连接失败等;idle阶段属于nodejs内部使用,主线程会执行一些nodejs内部特定回调函数执行一些内部事务,这部分通常与我们开发无关;poll阶段应该是nodejs主线程的主要工作所在,当文件打开成功,数据从文件中读入,或者数据写入文件等相应IO事件发生时,对应的回调函数都会存储在这个阶段的队列,典型的fs.writeFile(p, (err, data)=>{})调用,它对应的回调函数就在这个阶段才能执行。check阶段执行由setImmediate提交的回调函数,setImmediate和setTimeout(callback, 0)其实性质一样,只不过这两个异步函数对应的回调在不同的阶段执行,如果我们再代码中同时执行setImmediate和setTimeout(callback, 0),那么哪个回调先执行就取决于主线程当前处于哪个阶段,我们可以做个实验,在本地创建一个文件例如hello.txt,然后创建index.js,在里面添加代码如下:
setTimeout(function() {
console.log('setTimeout')
}, 0)
setImmediate(function() {
console.log('setImmediate')
})
在多次运行index.js情况下,有时候setTimeout先打印,有时候setImmediate先打印,这取决于主线程处于哪个阶段,如果它执行时主线程已经越过check阶段,那么setTimeout将先打印,反之亦然。如果我们在IO回调中执行上面代码,例如:
fs.readFile('./hello.txt', ()=> {
setTimeout(function() {
console.log('setTimeout in read file')
}, 0)
setImmediate(function() {
console.log('setImmediate in read file')
})
})
那么setImmediate in read file一定会先打印,因为readFile的回调在poll阶段执行,而check阶段紧跟着poll,因此读取文件的回调执行后主线程进入check阶段,于是setImmediate设置的回调一定先执行。
上图中还有一个process.nextTick,它也是一个异步函数,但它不属于event loop的任何阶段,当当前event loop阶段走完重新回到timer阶段时,主线程会先查看是否有nextTick提供的回调,如果有,那么先执行给定回调然后再进入timer阶段。它本质上跟setImmediate没有什么区别,只不过后者属于event loop的特定阶段而前者不属于event loop,因此它最大的作用是让代码在主线程进入下一轮循环前做一些操作,例如释放掉一些没用的资源。
由于nodejs的异步模式,有些错误可能很难处理,这类问题称之为Zalgo问题,他们的特点是把同步逻辑和异步逻辑组合在一起从而导致难以复现和难以调试的Bug,一个例子如下:
import {readFile} from 'fs'
const cache = new Map()
function problemRead(filename, cb) {
if (cache.has(filename)) {
cb(cache.get(filename))
} else {
readFile(filename, 'utf8', (err, data)= {
cache.set(filename, data)
cb(data)
})
}
}
在上面代码中,problemRead有两种模式,一种是如果缓存没有存在,那么使用readFile进行异步读取,如果缓存已经存在,那么cb对应的回调函数将直接执行,因此cb有可能在执行时存在不同上下文环境,这种情况很容易导致代码出现问题,例如创建文件zalgo.mjs,实现代码如下:
function createFileReader(filename) {
const listeners = []
problemRead(filename, value=>{
listeners.forEach(listener => listener(value))
})
return {
onDataReady: listener => listeners.push(listener)
}
}
const reader1 = createFileReader('./hello.txt')
reader1.onDataReady(data => {
console.log("calling from reader1: ", data)
const reader2 = createFileReader('./hello.txt')
reader2.onDataReady(data => {
//这里的回调不会被调用
console.log('calling from reader2: ', data)
})
})
上面代码执行时只会输出:
calling from reader1: hello world!
也就是read2对应的回调没有调用。它的原因是这样,第一次调用createFileReader时,由于数据没有缓存,因此代码调用异步接口readFile,前面我们说过任何异步调用都会提交内线程池,它绝不会在主线程中运行,因此readFile接下来的代码会直接运行,于是我们就有机会把reader1对应的回调加入到listeners队列,等到回调完成后,reader1的回调函数已经存储在listeners中,于是在回调中遍历listeners队列,取出其中的回调函数执行,这样reader1指定的回调就能得以执行。
在reader2对应的createFileReader函数执行后,对应的数据已经存储在缓存中,于是代码直接将listener2队列中的回调元素拿出来执行,注意这个时候reader2.onDataReady对应代码还没有执行,因此reader2对应的回调函数还没有来得及放入到listeners队列,于是它就得不到执行的机会。这种问题很难调试,首先它不好重现,如果createReader后面继续存在被调用,那么reader2对应的回调就可以被执行,同时上面代码reader2的回调没有执行,同时代码也不产生任何异常或错误,这使得问题的定位会非常困难,nodejs社区把这种问题叫做upleasing zalgo,这是一个特定的典故。这给我们的教训是,在代码中要不全部使用异步模式,要不就同步模式,决不能两种交叉混合使用。