













NLP 正在推动人工智能进入激动人心的新时代。
当前人工智能领域热度最高的方向就是预训练大模型了,很多人相信,这项研究已在通用人工智能领域初显成效。
自然语言处理领域著名学者,斯坦福大学教授克里斯托弗 · 曼宁(Christopher Manning)近期在美国人文与科学学院(AAAS)期刊的 AI & Society 特刊上发表了题为《Human Language Understanding & Reasoning》的文章,探讨了语义、语言理解的本质,展望了大模型的未来。
曼宁认为,随着 NLP 领域的技术突破,我们或许已在通用人工智能(Artificial general intelligence, AGI)方向上迈出了坚定的一步。

摘要
在过去十年中,简单的神经网络计算方式在自然语言处理方面取得了巨大而令人惊讶的突破,人们在超大规模情况下复制了成功,并在大量数据上进行了训练。由此产生的预训练语言模型,如 BERT 和 GPT-3,提供了强大的通用语言理解和生成基础,可以轻松适应许多理解、写作和推理任务。
这些模型展示了一种更为通用的人工智能形式的初步迹象,这可能会在感知体验领域产生强大的基础模型,而不仅仅局限于语言。
NLP 领域的四个时代
当科学家思考人工智能时,大多会首先想到建模或重建单个人脑的能力。不过,现代人类智慧远不止单个大脑的智能。
人类的语言很强大,并且对我们的物种产生了深远影响,因为它为人群整体提供了一种将大脑联网的方式。一个人可能并不比我们的黑猩猩或倭黑猩猩的近亲聪明太多。这些猿类已被证明拥有人类智能的许多标志性技能,例如使用工具和计划。此外,它们的短期记忆力甚至比我们强。
人类发明语言的时间也许永远是个谜,但可以相对肯定的是,在地球生命漫长的进化史中,人类直到最近才发展出语言。原猴、猴子和猿类的共同祖先可以追溯到大约 6500 万年前。人类大约在 600 万年前与黑猩猩分离,而人类语言的历史通常被认为只有几十万年。
人类发展了语言后,交流的力量让智人迅速超越其他生物,尽管我们没有大象那么强壮,也没有猎豹那么快。直到最近,人类才发明了文字(可能仅在五千多年前),让知识可以跨越时空界限进行交流。在短短几千年时间里,这种信息共享机制将我们从青铜时代带到了今天的智能手机。允许人类之间进行理性讨论和信息分发的高保真代码,允许复杂社会的文化演变,催生着现代技术背后的知识。语言的力量是人类社会智能的基础,在人工智能工具增强人类能力的未来世界中,语言将继续发挥重要作用。
由于这些原因,自然语言处理(NLP)领域与人工智能的最早发展同步出现。事实上,机器翻译 NLP 问题的初步工作,包括 1954 年著名的 Georgetown-IBM 实验,实现了史上首例机器翻译,略早于 1956 年人工智能」一词的创造。在本文中,我简要概述了自然语言的历史加工。然后,我描述了 NLP 最近的戏剧性发展,这些发展来自使用在大量数据上训练的大型人工神经网络模型。我追溯了使用这些技术构建有效 NLP 系统所取得的巨大进步,并总结了一些关于这些模型实现了什么,以及下一步将走向何方的想法。
迄今为止,自然语言处理的历史大致可以分为四个时代。
第一个时代从 1950 年到 1969 年。NLP 研究始于机器翻译研究。人们想象,翻译可以迅速建立在计算机在二战期间破译密码巨大成功的基础上。冷战时期的双方研究人员都在寻求开发能够转化其他国家科研成果的系统。然而在这个时代的开始,人们对人类语言、人工智能或机器学习的结构几乎一无所知。回想起来,可用的计算量和数据量小得可怜。尽管最初的系统被大肆宣传,但这些系统仅提供了词级翻译查找和一些简单的,不是很有原则的基于规则的机制来处理词的屈折形式(词形变化)和词序。
第二个时代,从 1970 年到 1992 年,我们见证了一系列 NLP 演示系统的发展,这些演示系统在处理人类语言中的句法和引用等现象方面表现出复杂性和深度。这些系统包括 Terry Winograd 的 SHRDLU、Bill Woods 的 LUNAR、Roger Schank 的系统,如 SAM、Gary Hendrix 的 LIFER 和 Danny Bobrow 的 GUS。这些都是人们手工构建的基于规则的系统,但他们开始建模和使用人类语言理解的一些复杂性。一些系统甚至被部署用于数据库查询等任务。语言学和基于知识的人工智能正在迅速发展,在这个时代的第二个十年里出现了新一代的手工构建系统,它与声明性和语言知识及其程序处理区分开来,并受益于一系列更现代的语言理论的发展。
然而我们的工作方向在 1993 年到 2012 年间的第三个时代发生了显著变化。在此期间,数字文本变得丰富,最适用的方向是开发能够在大量自然语言内容上实现某种程度语言理解的算法,并利用文本的存在来帮助获得这种能力。这导致该领域围绕 NLP 的经验机器学习模型在根本上被重新定位,这一方向至今仍占主导地位。
在这个时期初期,我们主要的方法是掌握合理数量的在线文本——当时的文本集合一般在几千万字以下——并从中提取某种模型数据,主要是通过计算特定事实。例如,你可能发现人识别的事物类型在人的位置(如城市、城镇或堡垒)和隐喻概念(如想象力、注意力或本质)之间相当均衡。但是对单词的计数仅能提供语言理解设备,早期从文本集合中学习语言结构的经验尝试相当不成功。这导致该领域的大部分人专注于构建带注释的语言资源,例如标记单词、文本中的人名或公司名称的实例,或树库中句子的语法结构,然后使用监督机器学习技术构建模型,该模型可以在运行时在新文本片段上生成类似的标签。
自 2013 年至今,我们扩展了第三个时代的经验方向,但由于引入了深度学习 / 人工神经网络方法,工作已经发生了巨大的变化。
在新方法中,单词和句子由(数十或千维)实值向量空间中的位置表示,含义或句法的相似性由该空间中的接近度表示。从 2013 年到 2018 年,深度学习为构建高性能模型提供了一种更强大的方法,其更容易对更远距离的上下文进行建模,并且模型可以更好地泛化到具有相似含义的单词或短语上,因为它们可以利用向量空间中的邻近性,而不是依赖于符号的同一性(例如词形或词性)。然而,该方法在构建监督机器学习模型以执行特定分析任务方面没有改变。
在 2018 年,一切都发生了变化,超大规模自监督(self-supervised)神经网络学习的第一个重大成功就在 NLP 上。在这种方法中,系统可以通过接触大量文本(现在通常是数十亿字)来学习大量的语言和世界知识。实现这一点的自监督方法是让 AI 系统从文本中自行创建预测挑战,例如在给定先前单词的情况下连续识别文本中的每个「下一单词」,或填充文本中遮掩的单词或短语。通过数十亿次重复这样的预测任务并从错误中学习,模型在下一次给定类似的文本上下文时会做得更好,积累了对语言和世界的一般知识,然后可以将这些知识部署到更多人们感兴趣的任务中,例如问答或文本分类。
为什么大模型是突破
事后看来,大规模自监督学习方法的发展很可能被视为一次革命,第三个时代可能会延长到 2017 年。预训练自监督方法的影响是一个突破:现在我们可以在大量未标记的人类语言材料上训练,生成一个大型预训练模型,其可以很容易地通过微调或提示进行调整,在各种自然语言理解和生成任务上提供强大的结果。现在,人们对 NLP 的进步和关注爆发了。出现了一种乐观的感觉,我们开始看到具有一定程度通用智能的知识灌输系统的出现。
我无法在此完整描述目前占主导地位的人类语言神经网络模型。大体上,这些模型通过实数向量表示一切,并且能够在接触到许多数据后通过从某些预测任务到单词表示的错误(归结为进行微积分)的反向传播来学习很好地表示一段文字。
自 2018 年以来,NLP 应用的主要神经网络模型一直是 Transformer 架构神经网络。Transformer 是一个比几十年前人类探索的用于单词序列的简单神经网络更复杂的模型,主要思想之一是注意力机制——通过它,一个位置的表示被计算为来自其他位置的表示的加权组合。Transformer 模型中一个常见的自监督目标是屏蔽文本中的偶尔出现的单词,该模型要计算空位上曾经存在的单词。它通过从每个单词位置(包括掩码位置)计算表示该位置的查询、键和值的向量来做到这一点。将某个位置的查询与每个位置的值进行比较,算法计算出每个位置的注意力。基于此,计算所有位置的值的加权平均值。
这种操作在 Transformer 神经网络的每一层重复多次,结果值通过一个全连接的神经网络层进一步操作,并通过使用归一化层和残差连接为每个单词生成一个新的向量。整个过程重复多次,为 Transformer 神经网络提供了额外的深度层。最后,掩码位置上方的表示应捕获原始文本中的单词:例如,如图 1 所示的 committee。
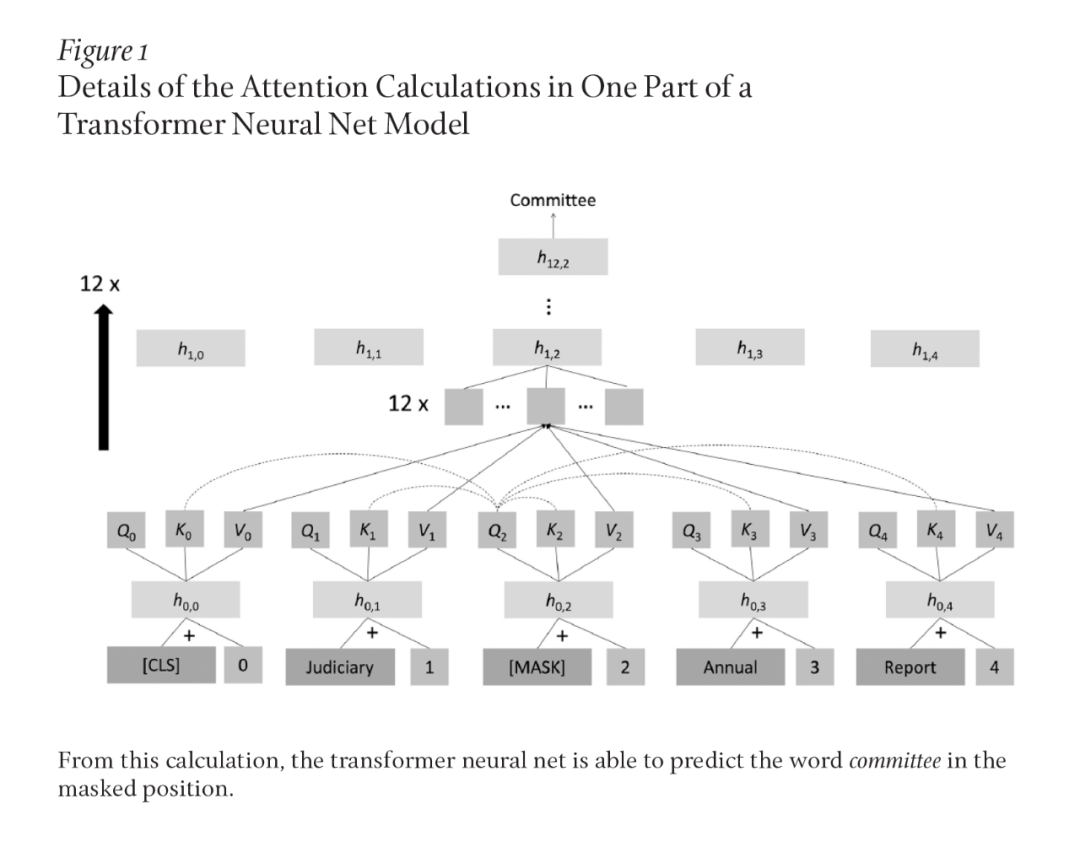
通过 Transformer 神经网络的简单计算可以实现或学习什么并不明显,起初它更像是某种复杂的统计关联学习器。然而,利用像 Transformer 这样非常强大、灵活的超参数模型和大量数据来练习预测,模型发现并表征了人类语言的大部分结构。研究表明这些模型学习和表征句子的句法结构,并学习记忆许多事实,这些有助于模型成功预测自然语言中被掩码的词。
此外,虽然预测一个被掩码的词最初似乎是一项相当简单和低级的任务,但这个任务的结果却有着强大和普遍的作用。这些模型汇集了它们所接触的语言和广泛的现实知识。
只需要再给出进一步的指令,这样的大型预训练模型 (LPLM) 就可以部署于许多特定的 NLP 任务。从 2018 年到 2020 年,领域内的标准方法是通过少量额外的监督学习来微调模型,在感兴趣的确切任务上对其进行训练。但最近,研究人员惊讶地发现,这些模型中最大的模型,例如 GPT-3(生成式预训练 Transformer),只需提示(prompt)即可很好地执行新任务。给模型一个人类语言描述或几个例子,说明人们希望模型做什么,模型就可以执行许多它们从未接受过训练的任务。
大模型带来的 NLP 新范式
传统的自然语言处理模型通常由几个独立开发的组件组合而成,通常构建成一个 pipeline,其中首先尝试捕获文本的句子结构和低级实体,然后是高级含义的词汇,这也是馈入一些特定领域的执行组件。在过去的几年里,业内已经用 LPLM 取代了这种传统的 NLP 解决方案,通常经过微调来执行特定的任务。我们可以期待一下 LPLM 在 2020 年代能够完成哪些目标。
早期的机器翻译系统涵盖了有限领域中的有限语言结构。从广泛的翻译文本的平行语料库(parallel corpora)构建大型统计模型,这种方法是可以覆盖机器翻译的,这也成就了 2006 年首次推出的 Google 翻译。
十年后,即 2016 年底,当人们转向使用神经机器翻译时,Google 的机器翻译性能获得了显著提高。但新型系统的更新换代越来越快,2020 年基于 Transformer 的神经翻译系统用不同的神经架构和方法进行了改进。
新系统不是在两种语言之间进行翻译的大型系统,而是利用一个巨大的神经网络,同时在谷歌翻译涵盖的所有语言上进行训练,仅用一个简单的 token 标记不同的语言。虽然这个系统仍会出错,但机器翻译不断在发展,今天的自动翻译的质量已经非常出色。
例如,将法语翻译成英语:
Il avait été surnommé, au milieu des années 1930, le « Fou chantant », alors qu’il faisait ses débuts d’artiste soliste après avoir créé, en 1933, un duo à succès avec le pianiste Johnny Hess.
Pour son dynamisme sur scène, silhouette agile, ses yeux écarquillés et rieurs, ses cheveux en bataille, surtout pour le rythme qu’il donnait aux mots dans ses interprétations et l’écriture de ses textes.
He was nicknamed the Singing Madman in the mid-1930s when he was making his debut as a solo artist after creating a successful duet with pianist Johnny Hess in 1933.
For his dynamism on stage, his agile figure, his wide, laughing eyes, his messy hair, especially for the rhythm he gave to the words in his interpretations and the writing of his texts.
在问答系统中,系统在一组文本中查找相关信息,然后提供特定问题的答案(而不是像早期的 Web 搜索那样仅返回建议相关信息的页面)。问答系统有许多直接的商业应用,包括售前和售后客户咨询。现代神经网络问答系统在提取文本中存在的答案方面具有很高的准确性,甚至可以很好地找出不存在的答案。
例如,从以下英文文本中找到问题的答案:
Samsung saved its best features for the Galaxy Note 20 Ultra, including a more refined design than the Galaxy S20 Ultra–a phone I don’t recommend. You’ll find an exceptional 6.9-inch screen, sharp 5x optical zoom camera and a swifter stylus for annotating screenshots and taking notes.
The Note 20 Ultra also makes small but significant enhancements over the Note 10 Plus, especially in the camera realm. Do these features justify the Note 20 Ultra’s price? It begins at $1,300 for the 128GB version.
The retail price is a steep ask, especially when you combine a climate of deep global recession and mounting unemployment.
三星 Galaxy Note 20 Ultra 的价格是多少?
- 128GB 版本 1300 美元
Galaxy Note 20 Ultra 有 20 倍光学变焦吗?
- 没有
Galaxy Note 20 Ultra 的光学变焦是多少?
- 5x
Galaxy Note 20 Ultra 的屏幕有多大?
- 6.9 英寸
对于常见的传统 NLP 任务,例如在一段文本中标记人或组织名称或对文本进行情感倾向分类(正面或负面),当前最好的系统还是基于 LPLM 的,对于特定任务通过提供一组以所需方式标记的样本进行微调。尽管这些任务在大型语言模型出现之前就可以很好地完成,但大型模型中语言和世界知识的广度进一步提高了在这些任务上的性能。
最后,LPLM 引发了在生成流畅和连续文本的能力方面的一场革命。除了许多创造性用途之外,此类系统还具有工具性质的用途,例如编写公式化的新闻文章、自动生成摘要。此外,这样的系统可以根据放射科医生的发现提出(或总结)要点来帮助放射科医生诊断病情。
这些 NLP 系统在许多任务上都表现得非常好。事实上,给出一个特定的任务,它们通常可以被训练成像人类一样执行这些任务。尽管如此,仍有理由怀疑这些系统是否真的理解它们在做什么,或者它们是否只是单纯地重复一些操作,没有意义。
以较复杂的编程语言理解为例,编程语言中描述单词意义主要借助指称语义学:单词、短语或句子的含义是对象或情况的集合,用这种方法描述世界或其数学抽象。这与 NLP 中现代实验研究的简单分布语义(或使用意义理论)形成鲜明对比,单词的含义不再只是对上下文的描述。
大模型真的理解人类语言吗?
我认为语言的意义源于理解语言形式与其他事物之间的关联网络。如果我们拥有一个密集的关联网络,那么我们就可以很好地理解语言形式的含义。例如,如果我已知「shehnai」是个印度语词汇,那么我对这个词的含义就能够有一个合理的概念,它是印度唢呐;如果我能听到这种乐器演奏的声音,那么我对 shehnai 这个词会有更丰富的含义理解。
反过来,如果我从未见过或听过 shehnai 的声音,但有人告诉我它就像传统的印度双簧管,那么这个词对我来说也有一些意义:它与印度有关,与管乐器有关,并用来演奏音乐。
如果有人补充说 shehnai 有孔,有多个簧片和像双簧管一样的喇叭形末端,那么我就有更多连接到 shehnai 这个对象的属性网络。相反,我可能没有这些信息,只有几段使用该词的上下文,例如:
- 从一周前开始,有人坐在房子入口处的竹林里吹奏着 shehnai;Bikash Babu 不喜欢 shehnai 的哀号,但决心满足新郎家人的所有传统期望。
尽管在某些方面,我对 shehnai 这个词的含义理解会较少,但我仍然知道它是一种管状乐器,这也基于我知道一些额外的文化关联。
因此,理解语言的含义包括理解语言形式的关联网络,预训练语言模型能够学习语言的含义。除了词汇本身的含义,预训练语言模型也掌握了很多实际的知识。很多模型都经过了在百科全书上的训练,它们知道亚伯拉罕 · 林肯于 1809 年出生于肯塔基州;知道《Destiny’s Child》的主唱是碧昂丝。
就像人类一样,机器也可以从人类知识存储库中受益匪浅。然而,模型对词义和世界知识的理解往往非常不完整,需要用其他感官数据(sensory data)和知识来增强。大量文本数据首先为探索和构建这些模型提供了一种非常容易访问的方法,但扩展到其他类型的数据也是非常有必要的。
LPLM 在语言理解任务上的成功,以及将大规模自监督学习扩展到其他数据模式(如视觉、机器人技术、知识图谱、生物信息学和多模态数据)令人兴奋的前景表明了更通用方向的希望。我们提出了通用类模型的术语基础模型,通过自监督在大量数据上训练了数百万个参数,然后可以轻松地适应执行广泛的下游任务。例如 BERT(来自 Transformers 的双向编码器表示) 和 GPT-3 是这种基础模型的早期示例,但现在正在进行更广泛的工作。
一个方向是将语言模型与更加结构化的知识存储连接起来,这些知识存储表示为知识图神经网络或运行时要查阅的大量文本。不过最令人兴奋和有希望的方向是建立基础模型(foundation model),使其还可以吸收来自世界的其他感官数据,以实现集成的多模态学习。
这方面的一个例子是最近的 DALL-E 模型,在对成对的图像和文本的语料库进行自监督学习后,该算法可以通过生成相应的图片来表达新文本的含义。

我们现在还处于基础模型时代的早期,但在这里,让我勾勒出一个可能的未来:大多数信息处理和分析任务,甚至可能像机器人控制这样的事情,都将由少数几个基础模型之一的特化版接手。这些模型训练起来既昂贵又耗时,但让它们适应不同的任务将非常容易。事实上,人们也许可以简单地使用自然语言指令来做到这一点。
这种在少数模型上的收敛带来了几个风险:能够构建这些模型的机构可能拥有过多的权力和影响力,许多最终用户可能会受到这些模型中存在偏见的影响,且很难判断模型是否正确。另外,在特定环境中使用的安全性也存疑,因为模型及其训练数据非常大。
不论如何,这些模型把大量训练数据中获得的知识部署到许多不同任务的能力,将使其变得非常强大,它们还将成为首批在执行许多特定任务时,只需要人类下指示,告诉它如何做就能做到的人工智能。虽然这些模型最终可能只是模糊地了解一些知识,它们的可能性或许仍然有限,缺乏人类水平的精细逻辑或因果推理能力。但基础模型的通用有效性意味着它们将得到非常广泛的部署,它们将在未来十年让人们第一次看到更普遍的人工智能形式。






















