今年上半年,中美互联网、科技公司都迎来了不同程度的裁员和缩招。但与此同时,也有不少人选择了在这个时期跳槽,而且是从令人羡慕的「大厂」跳到他们感兴趣的创业公司。下图是 Mila 研究者 Ethan Caballero 整理的一份「最近离开谷歌的 AI 研究者」 的名单:
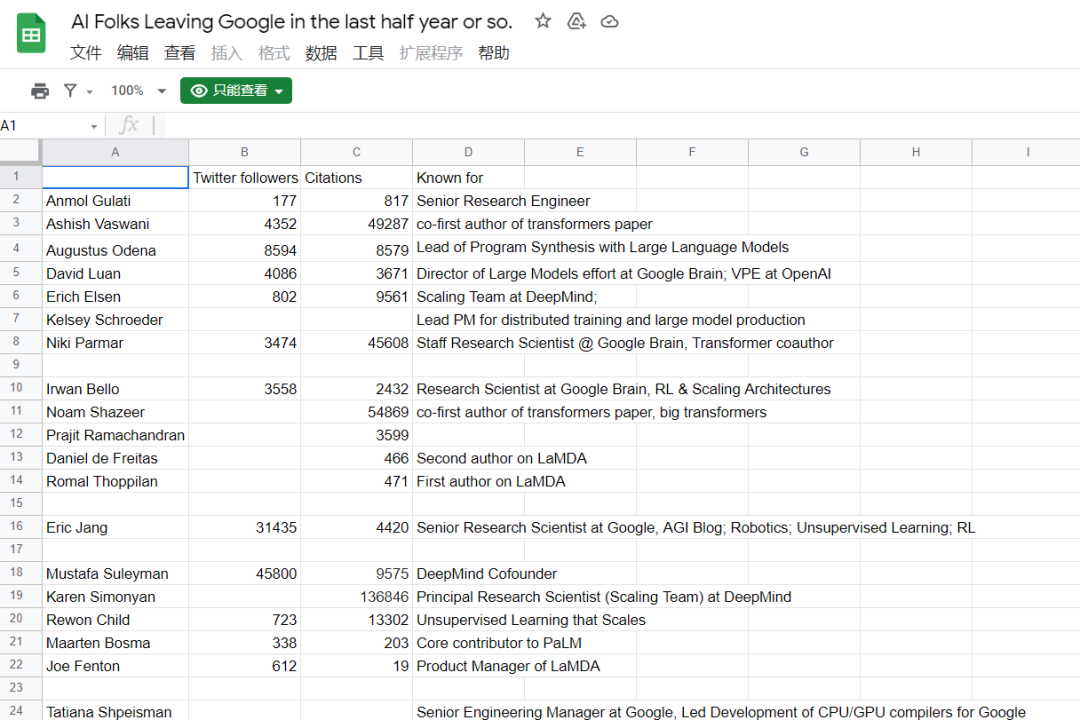
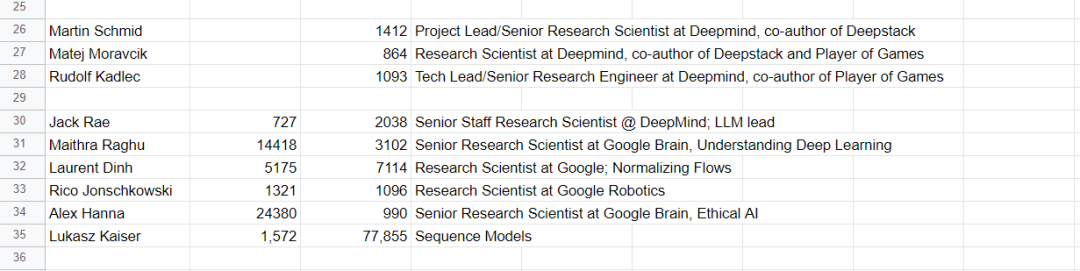
名单地址:https://docs.google.com/spreadsheets/d/14M-K2JHTOqWVsV4x95psAb94CblRIrhBimk8HVgwmRY/edit#gid=0
这份名单包含很多我们熟悉的研究者,比如 Transformer 重要作者 Ashish Vaswani 和 Niki Parmar,他们和同样在名单中的 Anmol Gulati、Augustus Odena 等人一起创立了一家名为 Adept 的新公司,致力于让人和计算机以创造性的方式一起工作,从而实现通用智能。
当然,并不是所有人都会在离开谷歌之后创立自己的公司,比如谷歌机器人高级研究科学家 Eric Jang。他在今年三月末从谷歌离职(待了 6 年),4 月 25 日宣布加入挪威机器人公司「Halodi Robotics」,担任 AI 副总裁一职。
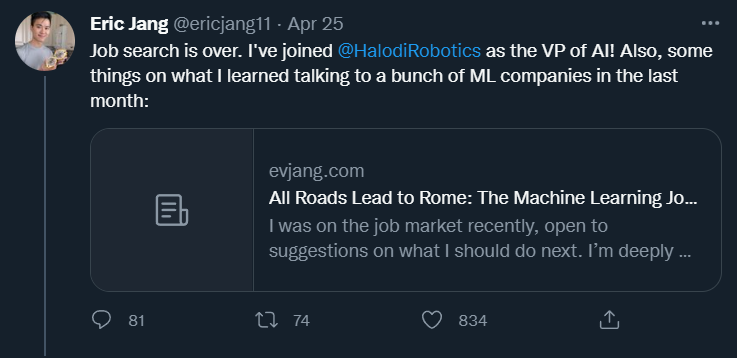
对于这一选择,不少人可能会问,为什么要选择这样一家公司?这些大厂研究人员在跳槽时都考虑哪些因素?在前段时间发布的一份博客(All Roads Lead to Rome: The Machine Learning Job Market in 2022)中,Eric Jang 详细介绍了他的决策过程以及他对美国当前机器学习就业市场的了解和对 AGI(通用人工智能)实现路线的看法。
以下是博客原文:
选择下家公司时考虑的因素
就我本人来说,下一份工作的唯一限制因素是我想继续运用自己的机器学习技能。下表列出了我考虑过的各个选项。我和这些公司的董事和创始人都谈过,但大多都没走到接受 HR 正式面试的程度。注意,这些选项的利弊只是我基于 2022 年 4 月的观察所列出的主观观点。在充满炒作的硅谷,一家公司可能在几年内就经历过山车一样的大起大落,所以这张表可能很快就会过时。
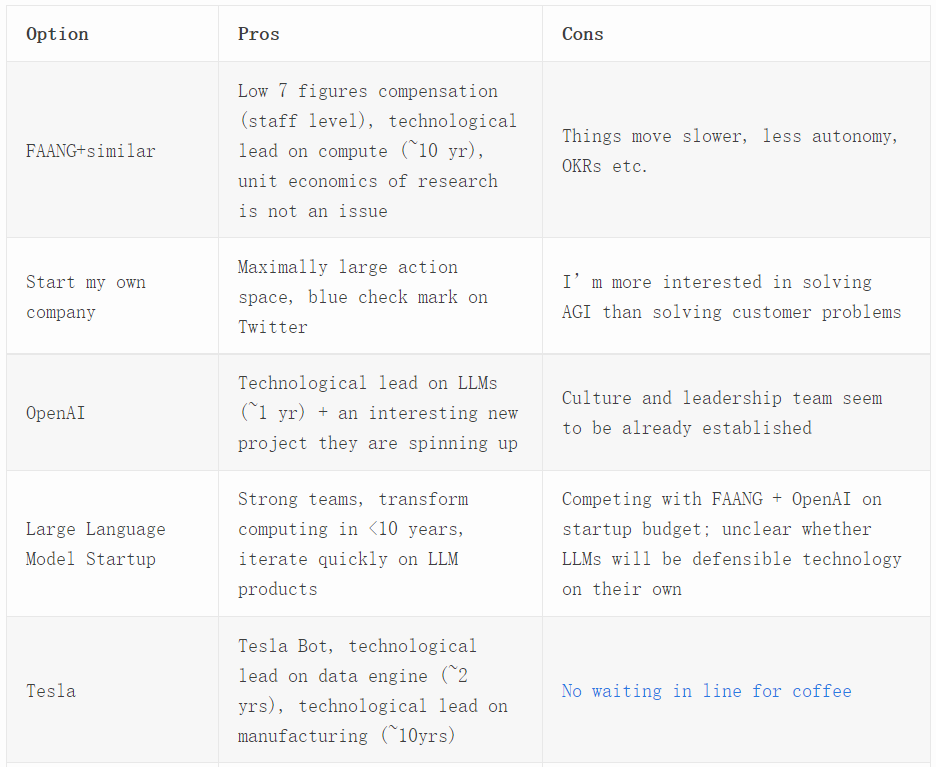

注:图中特斯拉一栏中的「No waiting in line for coffee」指的是马斯克曾威胁要解雇所有在 SpaceX 公司排着长队等咖啡的实习生,并安装了摄像头,以确保此类事件不会再次发生。(来源:https://twitter.com/rabois/status/1514601392178040836)
技术领先时间
对我来说,在选择下一家公司时,最重要的决定因素是该公司是否拥有领先竞争对手数年的技术优势。谷歌日志团队的一位朋友告诉我,他对小公司不感兴趣,因为他们在技术上远远落后于谷歌的行星级基础设施,他们甚至还没有开始理解谷歌现在正在解决的问题,更不用说解决谷歌十年前就已经开始着手解决的问题了。
在上表中,我列出了我认为具有独特技术优势的公司。例如,OpenAI 现在在招聘方面绝对是压倒性的,因为他们在大型语言模型算法方面处于领先地位,能凭借模型 surgery 和超参数调优这类商业机密玩转 scaling law。尽管 FAANG 在算力方面拥有优势,但 OpenAI 显然在创造技术领先时间方面做得很好。
与此同时,如果拿一个 FAANG 的普通机器学习研究者和一个博士生相比,前者在 raw compute 方面要领先 15 年。谷歌和 DeepMind 的语言模型在大多数指标上可能比 GPT-3 更强。但在有些情况下,计算方面的技术领先是不够的。于是,一些研究人员离开了谷歌,因为在对外推出基于大型语言模型的产品时,他们不得不经历很多繁琐的程序,这令他们非常不满。
我认真考虑过将我的职业规划转向生成模型(generative models),因为:1. 机器人学非常难;2. 在 ML 泛化方面,最令人印象深刻的案例似乎总是在生成式建模中。然而,纯生成的建模空间感觉竞争有点激烈,每个人都在为拥有同样的产品和研究想法而奋斗。不管有没有我,这个领域都可能以同样的方式发展。
拥有未来技术对于招聘工程师来说非常重要,因为他们中的许多人并不想浪费自己的生命去建立别人已经拥有的能力。举个例子,这就像一个神经科学实验室试图招募博士生用膜片钳实验研究猴子的大脑,而隔壁的实验室正在使用光遗传技术和 Neurallink 机器人。如果你有天赋,你可以自己重新发明这些,但这真值得你花费宝贵的时间吗?
当然,公司和研究实验室不是一回事。从长远来看,产品与市场的契合度,以及团队构建未来技术优势的能力将更加重要。现有公司可能会变得臃肿、偏离轨道,而新贵公司可能会利用不同的优势,或将设计引向独特的方向。很多独角兽公司都不是先行者。
为什么不选择自己开公司呢?
作为一个湾区人,我原本打算围绕 MLOps 开办自己的公司。我想建立一个领先的数据管理和标注系统,用于 AGI + 主动学习。但有三件事改变了我的想法:
首先,我和一些客户谈了谈,以了解他们的 ML 和数据管理需求,看看有没有哪个产品市场比较适合我。他们的很多问题并不需要前沿技术来解决,但我对前沿技术之外的很多问题又不感兴趣,比如为营销活动构建模拟器、为工厂中的机械臂拾放做出更好的姿势评估器或对用户提要内容进行排名等。绝大多数企业都在解决无聊但重要的问题。但我希望我一生的工作是为人类实现更大的技术飞跃。
其次,我认为,在公司估值突破 1 亿美元后,CEO 们很少能做出任何令人印象深刻的技术贡献。要想把工作做得很好,他们就要花大部分时间去处理协调、产品和公司层面的问题。他们积累了令人难以置信的社交渠道和影响力,甚至可能不时提交一些代码,但他们每天的日程安排充满了 bullshit,他们再也不会卓有成效地修补这些代码了。类似情况也发生在高级研究人员身上。这让我非常害怕。
著名计算机科学家、图灵奖得主理查德 · 汉明在他的演讲《You and Your Research》中说道,「如果你有了一些出色的成果,你就会被拉进各种委员会,然后没办法再出新的成果。」
有传闻说,Ken Thompson 在妻子出去度假一个月的时间里写出了 UNIX 操作系统,因为这个月他有时间专注于更深层次的工作。《The Murder of Wilbur Wright》中写道,如果这是真的,那该有多可怕?有没有可能 Thompson 一生都背负着沉重的责任,然后在一个短暂的自由时刻做了一些任何人都没有做过的最重要的工作?
最后,我选择的 Halodi 已经建立了非常棒的技术,他们给了我一个难得的机会去体验未来生活,这些都建立在领先时代 5 + 年的东西之上。我对 Bernt(公司 CEO)对人体解剖学的尊重印象深刻:从使我们即使没有精确规划依然可以抓握的过阻尼系统的内在被动智能,到让我们在几乎不消耗能量的情况下穿过可变地形的足部弹簧系统。我们都相信,当你想围绕人类而不是机器来设计世界时,类人机器人在完成大多数任务时并非「矫枉过正」,而是唯一可行的形式。
条条道路通罗马
几个月前,我问 Ilya Sutskever(OpenAI 首席科学家),到底是创办一个纯粹的 AGI 研究实验室(如 OpenAI、DeepMind),还是一个可以盈利的技术公司更有意义,后者可以产生构建 AGI 所需的数据护城河。
Ilya 说:「条条大路通罗马,每一家成功的科技公司都将会成为 AGI 公司。」
这听起来有点令人诧异,但你应该记得,重复改进一个产品涉及到指数级难度增长的更深度的技术。
- 在半导体制造中,从 32nm 工艺节点缩小到 14nm 是相当困难的,但从 14nm 到 7nm 是更加困难的,你需要解决超纯水之类的中间问题;
- 在 1980 年代,为渐冻症患者创建一个简单的文本转语音系统已经成为可能,但改进边缘情况的发音和自然地处理语调变化还要得益于深度学习的突破;
- 在单台计算机上你就可以训练一个不错的字符级语言模型,但从条件字符建模中去除一些熵需要依靠数据中心;
- 高速公路的自动驾驶并不太难,但在住宅区道路上实现 L5 级别的自动驾驶才被认为是完备的 AGI。
为了在未来几十年继续为客户增加边际价值,企业们必须习惯于解决一些非常困难的问题。也许最终每个人都会聚在一起解决同样的难题,即 AGI,这样他们就可以制作具有竞争力的短视频应用程序、待办事项列表或语法检查器。我们可以对「AGI」的含义以及所有公司实现这一点需要多长时间持怀疑态度,但我觉得基础模型很快就会成为许多软件产品的下注之地。
我还想知道几年后,无损压缩大量互联网级数据的专业知识是否将不再成为技术领先者 (FAANG) 之间的防御护城河。因此,寻找辅助数据和业务护城河以叠加到大规模 ML 专业知识上是有意义的。通往 AGI 的道路有很多条,我在下面为一些大型玩家勾勒出了这些道路:
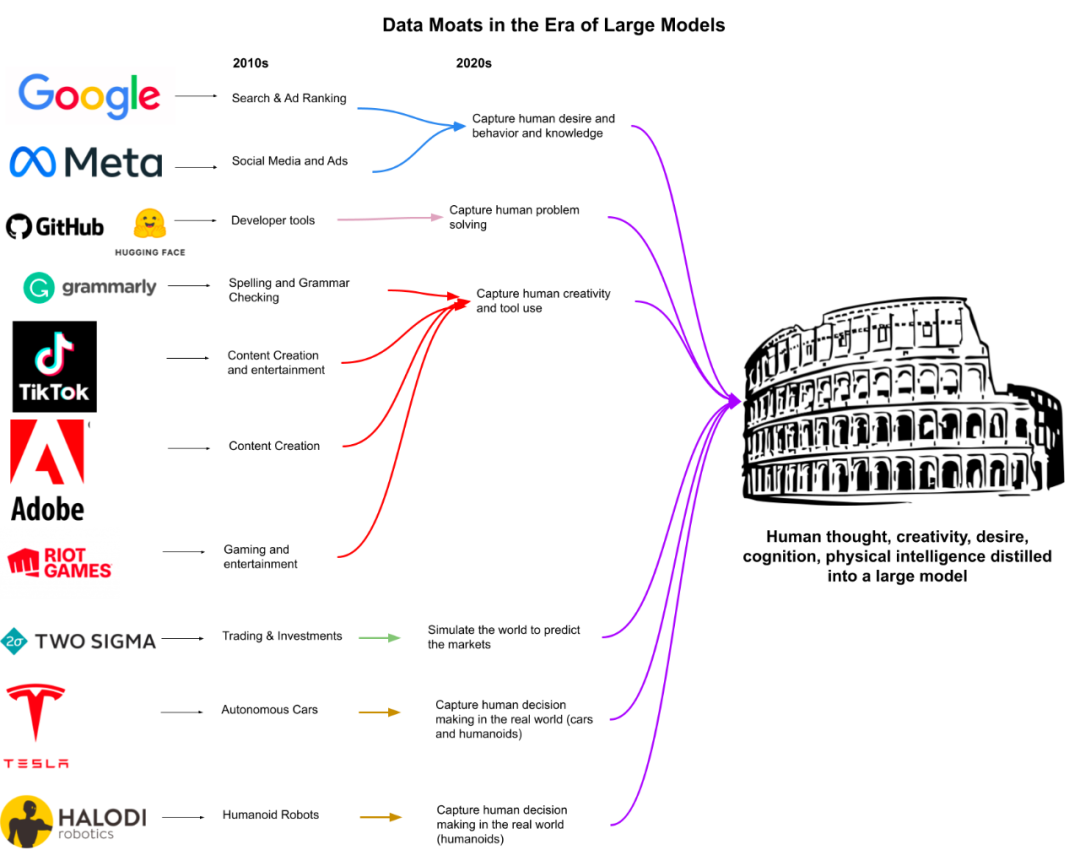
例如,Alphabet 拥有很多有价值的搜索引擎数据,可以捕捉到人类的想法和好奇心。Meta 记录了大量的社会智能数据和性格特征。如果他们愿意,他们可以收集 Oculus 控制器的交互来创建人类行为的轨迹,然后将这些知识用于以后的机器人技术。TikTok 的推荐算法可能比我们更了解自己的潜意识。即使是像 Grammarly、Slack 和 Riot Games 这样的公司,也拥有用于人类智能的独特数据护城河。
这些公司中的每一个都可以利用他们的业务数据作为创造通用智能的楔子,通过行为克隆人类的思想和欲望本身。
我个人(通过加入 Halodi)押注的护城河是「比其他任何公司都领先 5 年的人形机器人」。Halodi 已经有了,而特斯拉正在开发他们的同类产品。我在 Halodi 的主要工作最初是训练模型以解决移动操作中的特定客户问题,同时也为 AGI 制定路线图:如何从人形形式压缩大量具身的第一人称数据,从而产生通用智能、心智理论和自我意识。
近年来,具身 AI 和机器人研究已经失去了一些光彩,因为大型语言模型现在可以解释笑话,而机器人仍然在以不可接受的成功率进行拾取和放置。但或许,这值得一次反向押注,即仅在比特世界对模型进行训练是不够的,莫拉维克悖论根本不是悖论,而是我们没有解决「大部分智能」的后果。
莫拉维克悖论是由人工智能和机器人学者所发现的一个和常识相左的现象。和传统假设不同,人类所独有的高阶智慧能力只需要非常少的计算能力,例如推理,但是无意识的技能和直觉却需要极大的运算能力。如莫拉维克所写,「要让电脑如成人般地下棋是相对容易的,但是要让电脑有如一岁小孩般的感知和行动能力却是相当困难甚至是不可能的」。
选择之后的担忧
我对 Halodi(以及一般的 AGI 初创公司)有一些真正的担忧。历史告诉我们,机器人公司的死亡率很高,我不知道有哪家通用机器人公司曾经成功过。
机器人公司倾向于从通用机器人的使命开始,然后迅速转向专注于一些无聊的事情。波士顿动力、Kindred、Teleexistence——名单不胜枚举。就像在商业和生活中一样,资本和进化的力量共同支持着硬件的专业化,而不是智能的普遍化。我祈祷这不会发生在我们身上。
我想起了 Gwern 关于「时机」的文章:过早推出意味着失败,但保守和过晚推出同样糟糕,因为无论预测如何,一个好主意都会像火一样吸引过度乐观的飞蛾一样的研究人员或企业家: 所有人都被献祭了,只有一个运气好、在完美瞬间亲吻火焰的人,最后赢得了一切,此时每个人都可以看到最佳时机已经过去。
但我也提醒自己理查德 · 海明对克劳德 · 香农的评价:
「他想创造一种编码方法,但他不知道该怎么做,所以他创造了一种随机代码,接着就被卡住了。然后他问了一个不可能的问题:这些平均随机代码能做什么?然后他证明了这些平均代码是随机良好的,也就是说至少有一个代码是良好的。除了有无畏勇气的人,谁敢这么想?」
人生苦短,做任何事都需要无限的勇气。