













推理引擎领域,经过最近几年的打磨优化,阿里推出的MNN(Mobile Neural Network) [1][2][3] 也成为业内领先的推理引擎,当我们想进一步提升性能时,结合深度学习模型设计入手是一个有潜力的方向,结合科学计算、高性能计算领域的知识则是一个更具体的方法,基于这个思考路径, 业内逐渐开始从稀疏计算角度来提升推理引擎性能。稀疏是指数据矩阵中有部分是0元素,一般而言,矩阵稀疏化之后,非0元素数据在内存中不连续,无法直接复用GEMM(general matrix multiply) [9] 算法,同时缓存命中问题或判断开销会降低稀疏计算性能,需要新的方法实现稀疏相对稠密计算的加速。
结合业内已有的稀疏计算方法与MNN的推理框架、内存布局、算子关系,我们在MNN框架中设计支撑多类后端的稀疏整体方案,打磨稀疏计算核心汇编实现达到高性能;重要性能指标数据如下:以AI(Artificial Intelligence)领域经典的分类模型MobileNetV1 [12] MobileNetV2 [13] 为例, 选取相同高通SD 835 CPU(MSM8998),与XNNPack [6] 相比,MobileNetV1 90%稀疏度时XNNPack 加速比为2.35x,MNN加速比为 2.57x - 3.96x。MobileNetV2 85% 稀疏度时, XNNPack MobileNetV2(只有 block=2),加速比为1.62x,MNN加速比为 3.71x(block=4),block含义与其他模型信息见1.1、 3.1节解读,其他信息在后续展开。
1. 稀疏布局与加速原理
1.1 可调分块稀疏权重
深度神经网络模型的稀疏计算包括输入稀疏 [11] 、输出稀疏、权重稀疏,0元素占全部元素的比例就是稀疏度,通常而言输入和输出稀疏对具备特定属性模型会有效果,例如激活函数为ReLU,计算出负数值会被归零,所以可以不精确计算出这些结果,只计算符号实现加速。而在CPU对通用DNN模型具备加速效果的是权重稀疏,在MNN中我们聚焦权重稀疏这个通用场景,另一个重要特点是面向深度学习的权重稀疏比例一般在30%-90%,有别于科学计算中极度稀疏到99%的场景。即以下三点:
MNN稀疏计算的基本选型:
- 左右矩阵方面:选择通用权重稀疏;
- 稀疏度方面: 在30%-90%左右需产生加速效果,非科学计算的极度稀疏场景;
- 结构方面:不采用裁剪权重矩阵通道维度的完全结构化剪枝方法,而是随机稀疏+分块稀疏。
常规结构化剪枝中 [4][5] ,直接删减权重矩阵的IC或OC维度的整个维度切片,裁剪后模型仍然是稠密的,直接缩减矩阵乘法规模,由于对宏观结构改变较大,导致模型精度损失显著。
MNN中的稀疏计算选择对权重在OC维度做动态分块稀疏,下图1为随机稀疏分块下矩阵乘法的左右矩阵数据布局,涂色方格表示数据非0, 白色方格表示稀疏化处理后为0,即可不存储,又可不计算。
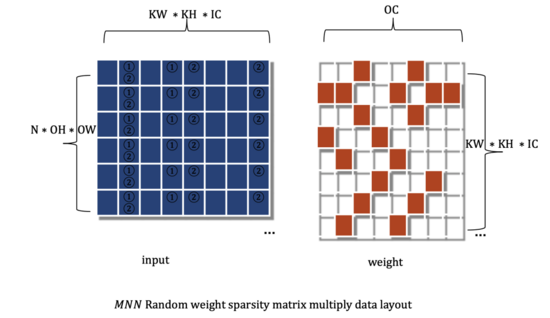
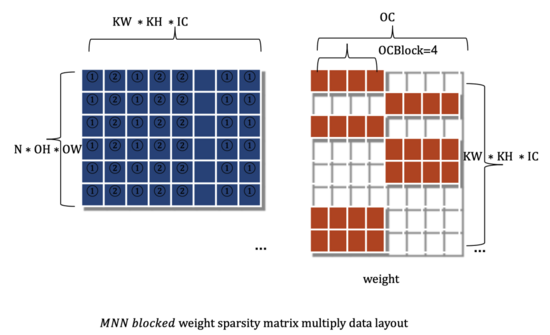
下图2为分块稀疏的矩阵乘法的左右矩阵数据布局,左矩阵与随机稀疏情形相同, 右矩阵为权重矩阵,以每OCBlock为单位,连续为0或非0分布于内存中。为了灵活性考虑,我们设计支持OCBlock为可调数值。
1.2 权重矩阵数据压缩格式
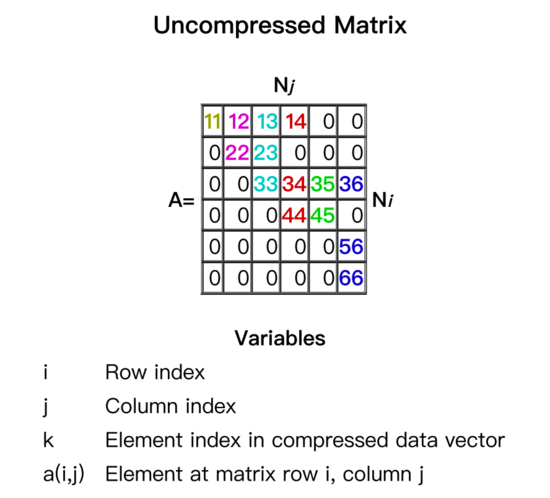
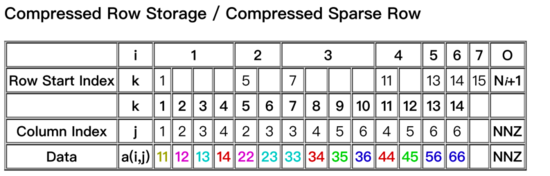
经过对比选型,在MNN中权重矩阵采用了多种布局形式,原始权重如图3所示,为了保障性能的同时压缩内存占用。性能随机稀疏时,选用图4所示的布局样式;分块稀疏时,选用图5布局。原始矩阵压缩为非0数据与索引部分。下图4、5中,权重矩阵A的0元素被压缩后不再存储,data为非0数据,Row start Index 与Column Index为行索引与列索引。图5的布局时,可以节省更多索引空间,压缩内存占用。
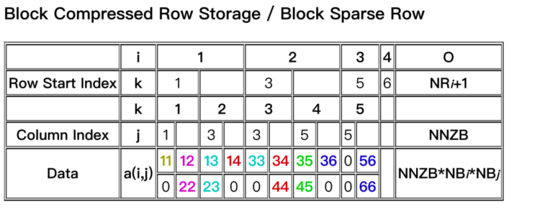
2. MNN稀疏计算方案设计
2.1 推理框架层设计
在MNN已有架构基础上的设计稀疏计算,则设计与实现需要考虑较多现状的约束,结合基础软件的定位,设计目标主要包括以下5个方面。
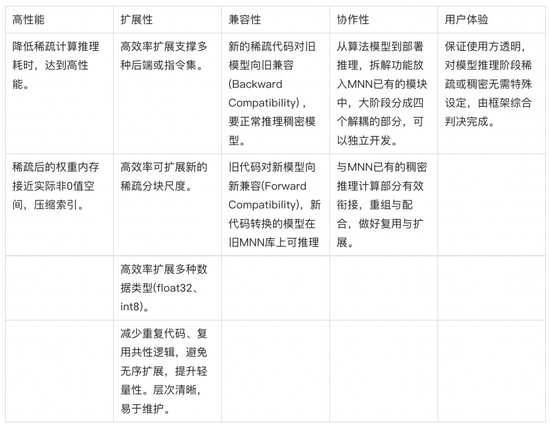
说明:由于汉语时序的”前后“和英语”forward/backward”语义相反,故用了向旧兼容代替通常说的有歧义的"向前兼容"。
2.2 MNN稀疏计算架构解析
经过不断设计与完善,MNN稀疏计算目前整体上包含稀疏训练、转换参数、算子框架、后端kernel 四个阶段,设计四部分松耦合;方便层内扩展,以及模块化集成与被集成,如下图package UML所示。为了便于理解,参考C4Model建模方法分层,图6为container层架构、图7为具体一层的Component层架构。
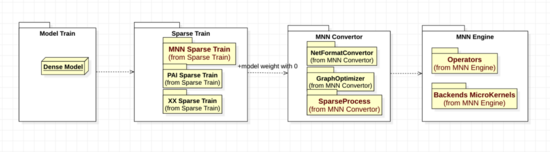
- 第一,属于算法模型阶段, 算法工程师结合数据搭建模型,根据自身偏好在各类框架下训练得到AI模型;
- 第二,稀疏化训练阶段,参考图6,从float稠密权重模型开始,导入MNN Python压缩工具包(mnncompress),设定mnncompress需要的参数,运行将原模型中权重部分数值稀疏化为0。我们建议用户使用MNNCompress工具里的训练插件,最大化发挥加速性能;
- 第三,转换模型阶段,MNN convertor 主要包含三类模块,MNN内部buffer格式转换、图优化、后处理,选择算子,将权重矩阵统计处理,满足稀疏阈值的,给添加稀疏后端识别和运行需要的参数,最终写文件得到稀疏MNN模型;
- 第四,MNN engine推理计算阶段,部署新模型到MNN运行环境中,和普通模型运行一样,MNN 运行时会自行处理算子映射、后端microkernel选择、执行推理。参考一般模型部署运行文档。(https://www.yuque.com/mnn/cn/create_session)
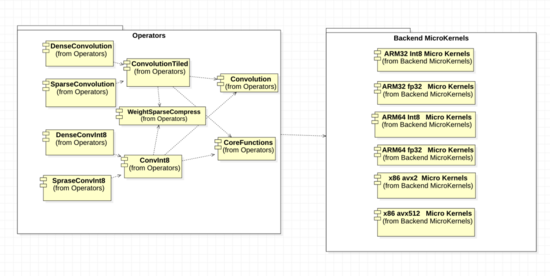
在 MNN Engine中,参考图7, 算子operators和后端backend做如下结构设计与考量。
- 外部看来,算子注册并未新增一种“稀疏卷积”算子,仍然是普通的卷积算子,这样可以减小用户使用的选择成本,减少算子膨胀,在MNN内部更灵活地选择稀疏计算加速,或原始稠密卷积。
- 算子层面,将原始的稠密卷积重组成两层,合理分配可复用与需要扩展的部分,实现稀疏计算压缩各类操作。
- 量化稀疏算子则基于量化卷积算子ConvInt8Tiled扩充实现,基本方法与2相近。
- 算子中平台有关的核心函数,我们分别实现了ARM32 fp32,ARM32 int8, ARM64 fp32, ARM64 int8, x86 avx2 fp32, x86 avx512 fp32共6种后端的汇编代码。
- 测试类方面,稀疏的用例完全包含稠密卷积的用例,并增加稀疏分块维度,遍历不同分块、不同稀疏度、不同后端的正确性。
3. 稀疏计算性能评估
3.1 典型模型稀疏加速评估
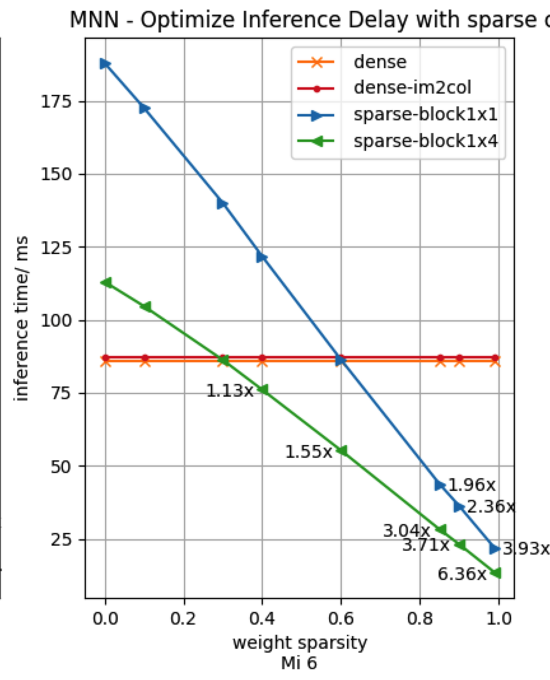
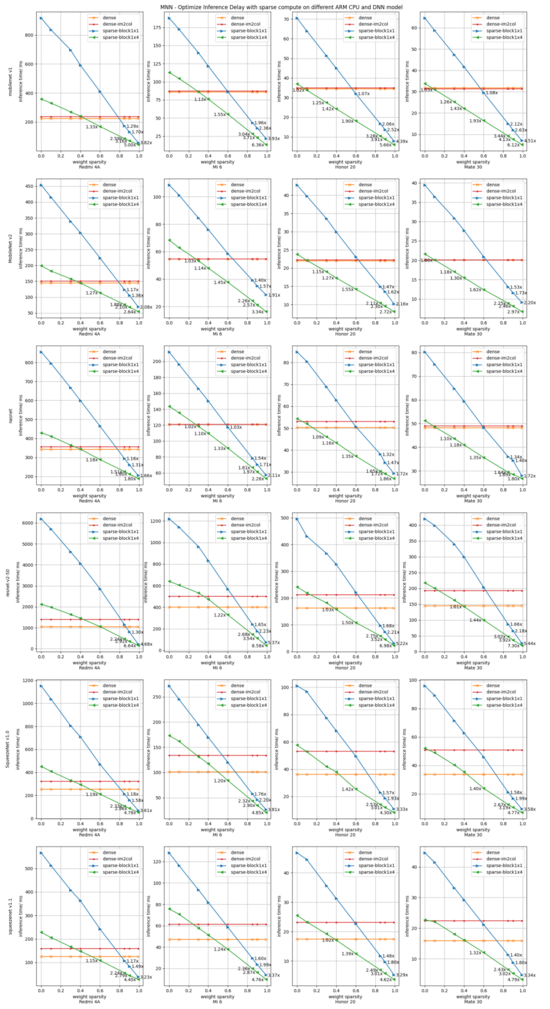
为全面评估fp32稀疏加速效果,我们从"稀疏度、分块大小、cpu型号、模型类型"四个维度进行评测,汇集在图8展示结果, 单张曲线图表示固定一个设备、一个模型时,推理耗时随稀疏度的变化曲线。
将大图的第1行第2列取出单列置于上方,便于解读数据。单张曲线图包含四条曲线,"dense"为MNN当前基准, "dense-im2col"为将推理算法固定为分块im2col做加速的数据,不使用winograd之类加速算法, "sparse-block1x1"表示对权重矩阵的稀疏为1x1分块,也就是完全随机稀疏。 "sparse-block1x4"是半结构化稀疏,表示对权重矩阵的稀疏分块为1x4分块,沿着ic维度分块为1, 沿着oc维度分块为4。
从小图可见在mobilenet V1、Mi6 机型、1x4分块时,对应绿色左三角◁曲线,稀疏加速比在0.9稀疏度是达到3.71x。
参考对比XNNPack模型推理性能:
XNNPack [6] 数据评测采用高通SD 835 CPU(MSM8998),mobilenetV1 为90%稀疏度,对mobilenetV2 为85% 稀疏度,
对应SD 835 CPU,我们以小米6为例,下图第1行第2列,为例对比数据:
XNNPack mobilenetV1(sparsity=0.9, block=1),加速比为2.35x,MNN加速比为 2.57x , 分块为1x4时加速比3.96x.
XNNPack mobilenetV2(sparsity=0.85, block=2),加速比为1.62x,MNN加速比为 3.71x(block=4).
对于卷积kernel不是1x1的层,我们仍可以实现稀疏加速,在XNNPack的论文中表明他们并未能实现稀疏加速。
通过数据大图8,我们可得到几点分析和结论:
- 参照设备小米6上, 在稀疏分块1x4时,稀疏加速临界值优化到0.3, 低端机型临界值有升高,其他中高端机型, 分块1x4时, 稀疏度0.1的时候就达到加速临界值了, 0.9稀疏度时加速比可达4.13x。
- MNN推理耗时随稀疏度增加,基本线性下降,跨模型、cpu 一致性比较好。
- 内存占用:经过推导, 稀疏相对稠密节省的内存比例如下,
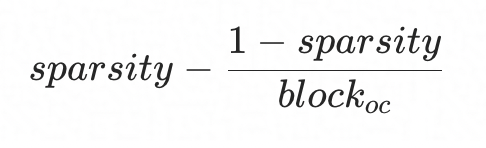
另一方面,我们评估了典型模型的分类精度,MobileNet V2在0.5稀疏度、1x4稀疏分块配置下,精度损失0.6%,对应上图加速比为1.3x。

4. 业务模型实践
4.1 某图片超分业务
在某业务移动端链路上,时间延迟与流量是其痛点,业务方对接端智能 MNN与工作台,开发超分辨率任务模型,同时使用MNN稀疏计算加速方案,主要做了四个步骤,
- 第一步为超分模型算法训练;
- 第二步,参考稀疏训练文档,设定压缩工具mnncompress需要的稀疏参数,得到权重部分数稀疏为0的模型;
- 第三步,使用MNN convertor转换模型;
- 运用MNN工作台(https://www.mnn.zone/m/0.3/) ,部署模型到mnn运行环境中。整套流程集成再MNN工作台,大大提升了AI的开发流程效率,感兴趣的同学可以试用和联系工作台负责人”明弈“。
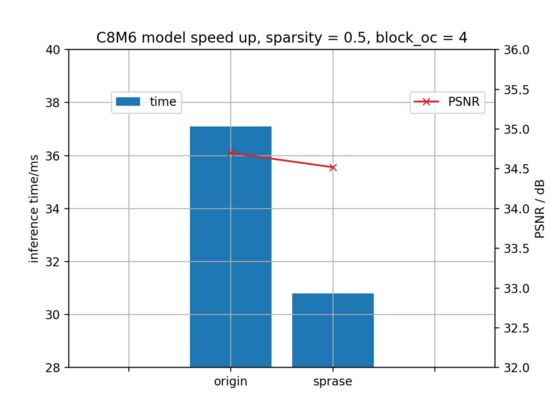
下图所示,在稀疏度0.45情况下,稀疏自身方案对推理的加速比约1.2x, 业务指标为图像信噪比,从 34.728dB少量下降到34.502dB。对业务精度影响在接受范围内。
4.2 某语音模型
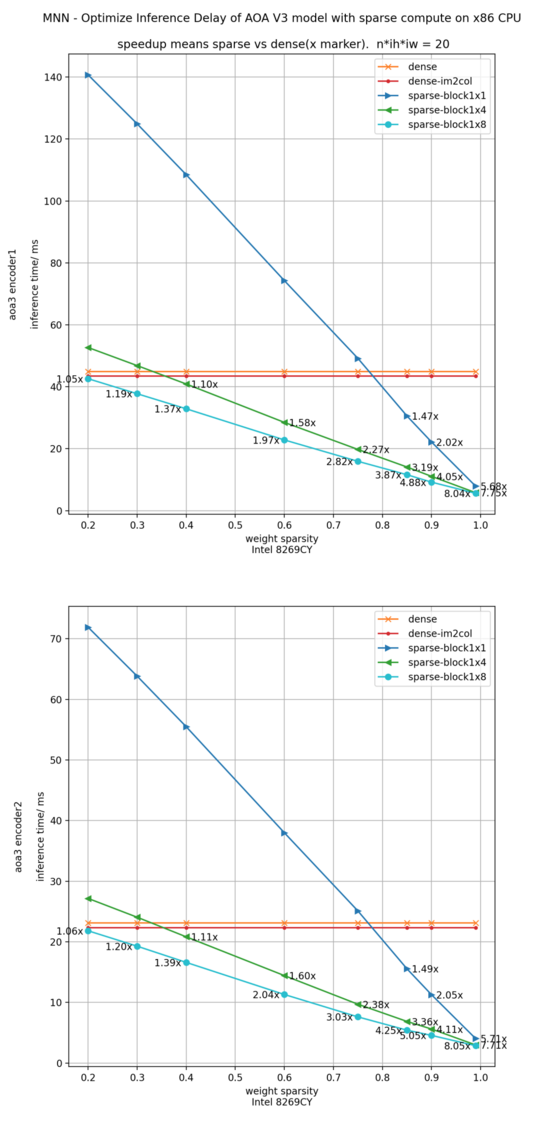
另一个业务方模型为某语音模型,下图为构造稀疏后在avx512下实测加速比,不同稀疏方法对加速会有影响,0.75稀疏度时,输入序列20时(典型场景1),下图所示,稀疏与稠密模型相比,encoder1加速比 2.82x, encoder2加速比3.02x。对于此方案达到预期的加速比。
5. 总结与展望
我们在MNN现有框架中,设计了通用稀疏卷积计算方案,使其数据布局、算子结构配合既有MNN结构、发挥出较高性能,而XNNPack的稀疏矩阵乘法只针对网络pointwise类卷积有加速。
第一点,我们设计实现了推理性能优于XNNPack的MNN稀疏加速方案;0.9稀疏度时,CV模型在ARM端获得3.16x-4.13x加速比,跨机型、跨模型加速效果都比较显著。
第二点,在实际业务模型中验证了业务精度指标,损失有限、可接受。
第三点,推理耗时随稀疏度增加线性下降,跨模型、cpu 一致;在小米6上,稀疏分块1x4加速临界值优化到0.3,中高端机型甚至稀疏度0.1的时候可达临界值。
第四点,降低内存占用随稀疏度成正比,具体数值见性能分析部分。
在引擎实现、稀疏计算内核、汇编代码开发中,经常会从不及预想值开始,在一次次调试中不断加深对MNN既有逻辑的理解,优化稀疏算子代码、SIMD代码,优化数据布局,最终将综合指标提升到高水准。
稀疏计算研发工作得以完成,非常感谢团队的同学通力协作!移动端或服务端,量化加速在不同领域都相对常见,指令集支持由来已久。而深度模型在CPU上的稀疏计算加速不断发展,分别使用时,二者各有相对优势。稀疏计算加速可以理解为一种 "可伸缩"等效位宽的技术,这个角度可以探索更多独特的应用场景。



















