













有人曾统计了某家互联网公司的季度财报。结果显示,该公司员工平均月薪是其他同行的3~4倍。消息一出,立即引起人们热议。虽然后来这家公司出来辟谣,表明公开的酬金成本包括员工培训、福利开支、缴纳税金、商业保险、年终奖,但这并没能让大众信服。人们关心的问题是:统计平均工资的方法是否合理?
如果把一个普通员工和世界首富的工资放在一块取平均值,那么可以想象,普通人的工资几乎可以忽略不计。在一个企业中,20%的人占据了80%的工资总额。高收入的人比例偏少,但对平均工资的影响很大。
平均工资仅仅是经济领域的一个例子。生活中,我们会接触到各式各样的数据,它们以不同的形态展现。在处理一组数据时,平均值可以很好地代表这组数据的平均水平,但由于削峰填谷,它也势必会损失一部分信息,只能反映总体特征的一个方面。
想要掌握数据的全貌,就要了解数据的属性和性质。对于一组数据,我们首先要知道大部分数值落在哪里?也就是说,我们通常选择数据的“中间位置”,即反映数据集中趋势的统计量,来表示数据的中心。这里的度量方法有平均数、中位数、众数等。
01 平均数
平均数也叫平均值、均值,是统计学中最基本、最常用的一种定义一组数据特征的指标,用来描述数据的平均水平。计算平均数可以把所有数据相加再除以数据个数,比如{1,2,3,4,5}的平均数就是3。
尽管平均数是描述数据集最有用的一个统计量,但是它并非总是度量数据中心的最佳方法。最主要问题是平均数对极端值(比如离群点)很敏感,会被少数很低或很高的数值明显影响。为了抵消这种影响,可以使用截尾均值,即丢弃一部分高低极端值后计算均值。比如跳水比赛,就采用去掉最高分和最低分的截尾均值计分法。
02 中位数
中位数是将数据按大小顺序排列后处在中间位置的数,描述数据的中等水平。如果有奇数个数,则中位数是中间值;如果是偶数个数,则中位数一般取两个最中间值的平均值。它适用于对倾斜(非对称)数据的度量。
03 众数
众数是集合中出现频率最高的数值,描述数据的一般水平。众数的个数不一定是唯一的。一组数据中,可能会存在多个众数,也可能不存在众数。众数不仅适用于数值型的数据,对于非数值型的数据也同样适用。例如,{苹果,苹果,苹果,香蕉,梨,梨}这组数据中,没有均值和中位数,但是存在众数—苹果。
04 众数、中位数、均值的关系
如果一组数据的平均值、中位数、众数是同一个数,则说明它的数据分布是对称的。但这种情况不常见,更多情况下,数据是正倾斜或负倾斜,如图2-1所示。
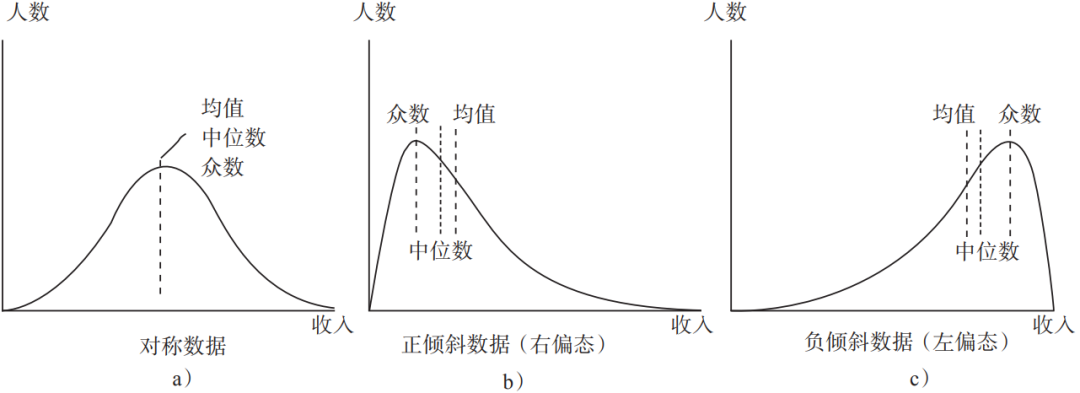 ▲图2-1 众数、中位数、均值的关系
▲图2-1 众数、中位数、均值的关系
收入数据就是典型的偏斜数据,大多数人是工薪阶层或退休老人,只有少数几个亿万富翁。收入数据如图2-1中的正倾斜数据,大多数人的收入集中在左侧,右侧有一条长长的尾巴,表示少数人的收入。这种分布不适合用平均数来描述。因为平均数对极端数据非常敏感,一两个亿万富翁,会拉高整个人群的收入水平线,使得收入均值比人们认知中的平均收入高出很多。
平均工资消除了大量低收入人群和少数巨额收入人群之间的差异。但如果换成众数也不合适,因为低收入人群占了工资比例的大多数区间。统计工资时的合理选择是统计中位数,它揭示了一半人和另一半人收入的分界线。
当然,并不是说中位数就是一个比平均数更好的统计量,只是它更适合工资统计。
引入统计量的意义就在于简化。比如老师告诉你说,孩子考试的排名处于班级里面的后10%,你就应该意识到他的学习成绩不太好,学习上要加把劲。在这个过程中,你不需要知道任何关于考试本身的内容,或孩子在考试中到底答对了多少题。一个排名数字,就能让你了解孩子的学习水平。
不过也正是由于统计量的简化,它不可避免地会丢失一些信息,其优点也是缺点。许多现象是无法只用一个数字来解释的。如果单凭一个统计量描述对象具有局限性,我们就应该尝试获得更多的数据,以及更多的细节。
关于作者:徐晟,某商业银行IT技术主管,毕业于上海交通大学,从事IT技术领域工作十余年,对科技发展、人工智能有自己独到的见解,专注于智能运维(AIOps)、数据可视化、容量管理等方面工作。
本文摘编自《大话机器智能:一书看透AI的底层运行逻辑》,经出版方授权发布。(ISBN:9787111696193)


















