












有研究称,他们使用一种技术在一周内清理了 PASCAL VOC 2012 数据集中的 17120 张图像,并发现 PASCAL 中 6.5% 的图像有不同的错误(缺失标签、类标签错误等)。他们在创纪录的时间内修复了这些错误,并将模型的性能提高了 13% 的 mAP。
通常情况下,模型性能较差可能是由于训练数据质量不高引起的。即使在 2022 年,由于数据是公司最重要的资产之一,开发人员也经常因数据质量低劣而感到工作棘手。本文中,总部位于德国柏林的面向视觉 AI 从业者的下一代注释工具提供商 Hasty,希望通过更快、更高效地清理数据来简化和降低视觉 AI 解决方案开发的风险。
他们开发了 AI Consensus Scoring (AI CS) 功能,它是 Hasty 生态系统的一部分(Hasty 是该公司开发的一个端到端的 AI 平台,可让 ML 工程师和领域专家更快地交付计算机视觉模型,从而缩短变革性产品和服务的上市时间),该功能使得手动共识评分(consensus scoring)成为过去,其将 AI 集成到质量控制流程中,使其更快、更便宜,并且随着用户添加的数据越多,性能扩展越好。
本文中,研究者将利用 AI CS 功能来改进、更新和升级最流行的目标检测基准数据集 PASCAL VOC 2012 。
我们先来简单介绍一下 PASCAL,它是一个著名的学术数据集,可用于目标检测和语义分割等视觉 AI 任务的基准模型。PASCAL 已有十多年的历史,现在还一直被广泛使用,近 4 年就有 160 篇论文使用它。
PASCAL 在过去十年中没有改变,世界各地的团队在科研中都保持该数据集的「原样」进行科研。但是,该数据集是很久以前注释的,当时算法还没有今天准确,注释要求也没有那么严格,会出现很多错误。例如下图所示:尽管马是在前景并且可见,但没有马的标签,这些质量问题在 PASCAL 中很常见。

如果让人工来处理 PASCAL 数据集,成本高昂且非常耗时,该研究使用 AI 进行质量控制并提高 PASCAL 的质量,他们的目的是如果数据质量足够好,模型性能会不会随之提高,为了执行这个测试,他们设置了一个包含以下步骤的实验:
- 在 Hasty 平台上使用 AI Consensus Scoring 功能清洗 PASCAL VOC 2012;
- 使用 Faster R-CNN 架构在原始的 PASCAL 训练集上训练自定义模型;
- 使用相同的 Faster R-CNN 架构和参数,在清理后的 PASCAL 训练集上准备一个自定义模型;
- 实验之后,得出结论。
下面为实验过程,以第一人称进行编译整理, 看看他们是如何做到的以及结果如何?
清洗 PASCAL VOC 2012
我们的首要任务是改进数据集。我们从 Kaggle 获得数据集,将其上传到 Hasty 平台,导入注释,并安排两次 AI CS 运行。对于那些不熟悉我们 AI CS 功能的人,该功能支持类、目标检测和实例分割审查,因此它会检查注释的类标签、边界框、多边形和掩码。在进行审查时,AI CS 会寻找额外或缺失的标签、伪影、错误类别的注释,以及形状不精确的边界框或实例。
PASCAL VOC 2012 包含 17.120 张图像和 20 个不同类别的约 37.700 个标签。我们已经针对 28.900 (OD) 和 1.320 (Class) 潜在错误任务运行了目标检测和类别审查。
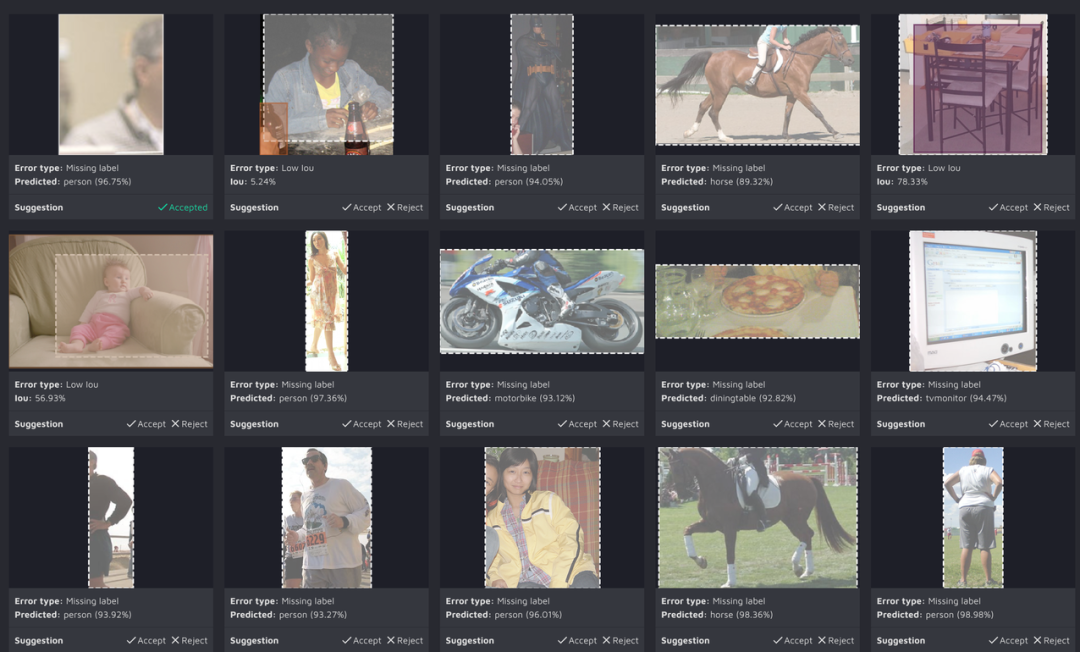
AI CS 可以让你发现潜在问题。然后,你可以专注于修复错误,而无需花几天或几周的时间来查错。
我们要检查这些潜在错误并解决它们,最重要的是,我们希望修改后的注释比原始注释器更准确。具体包括:
- 当 AI CS 检测到潜在错误时,我们尝试修复每张图像上所有可能出现的这些错误;
- 我们没有打算注释每个可能的目标,如果注释遗漏了一个目标,并且在前景中或在没有缩放的情况下肉眼可见,我们就注释它;
- 我们试图让边界框像像素一样完美;
- 我们还对部分(数据集类目标未注释部分)进行了注释,因为原始数据集具有它们的特性。
有了上述目标,我们首先检查了现有注释类标签的类审查运行,试图找出潜在的错误。超过 60% 的 AI CS 建议非常有用,因为它们有助于识别原始数据集不明显的问题。例如,注释器将沙发和椅子混淆。我们通过重新标记整个数据集的 500 多个标签来解决这个问题。

原始注释示例。图中有两张沙发和两把扶手椅。两把扶手椅中的一张标注为沙发,而另一把则标注为椅子。

修改后的标注,扶手椅是椅子,沙发是沙发。
在分析 OD 和 Class 审查时,我们发现 PASCAL 最突出的问题不是错误分类注释、奇怪的边界框或额外的标签。它最大的问题是缺少许多潜在的注释。我们很难估计确切的数字,但我们觉得有数千个未标记的目标应该被标记。
OD 审查通过数据集,寻找额外或缺失的标签和错误形状的边界框。并非所有缺失的注释都被 AI CS 突出显示,但我们已尽最大努力改进 AI CS 预测的至少有一个缺失标签的所有图片。结果,OD 审查帮助我们在 1.140 张图像中找到了 6.600 个缺失注释。
我们花了大约 80 个小时来审查所有建议并清理数据集,这是一个了不起的结果。
在原始 PASCAL 上训练自定义模型
如上所述,我们决定设置两组实验,训练两个模型,一个在初始的 PASCAL 上,另一个在经过清理的 PASCAL 版本上。为了进行神经网络训练,我们使用了 Hasty 另一个功能:Model Playground,这是一个无需编码的解决方案,允许你在简化的 UI 中构建 AI 模型,同时保持对架构和每个关键神经网络参数的控制。
在整个工作过程中,我们对模型进行了多次迭代,试图为任务找到最佳超参数。最后,我们选择了:
- 以 ResNet101 FPN 为骨干的更快的 R-CNN 架构;
- 采用 R101-FPN COCO 权值进行模型初始化;
- 模糊,水平翻转,随机剪切,旋转和颜色抖动作为增强;
- AdamW 为求解器,ReduceLROnPlateau 为调度器;
- 就像在其他 OD 任务中一样,使用了损失组合(RPN Bounding Box 损失、RPN 分类损失、最终 Bounding Box 回归损失和最终分类损失);
- 作为指标,我们有 COCO mAP,幸运的是,它直接在 Model Playground 中实现。
大约一天半的时间来训练。假设架构的深度、网络正在处理的图像数量、计划的训练迭代次数(10.000)以及 COCO mAP 在 5.000 张图片中每 50 次迭代计算的事实,它并没有花费太长时间。以下是模型取得的结果:
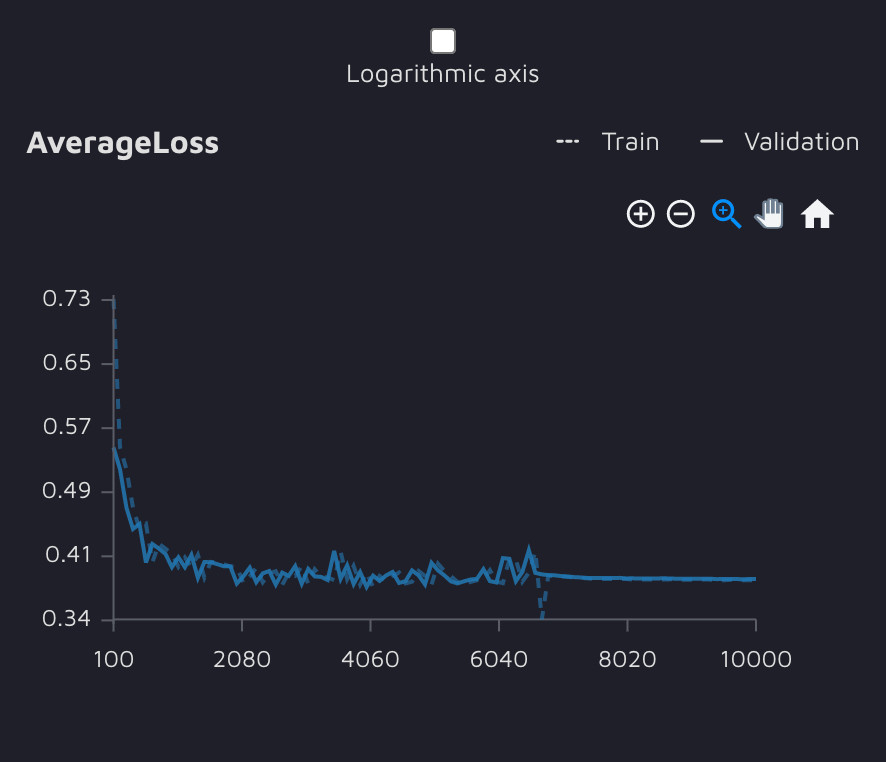
原始模型训练迭代的平均损失。
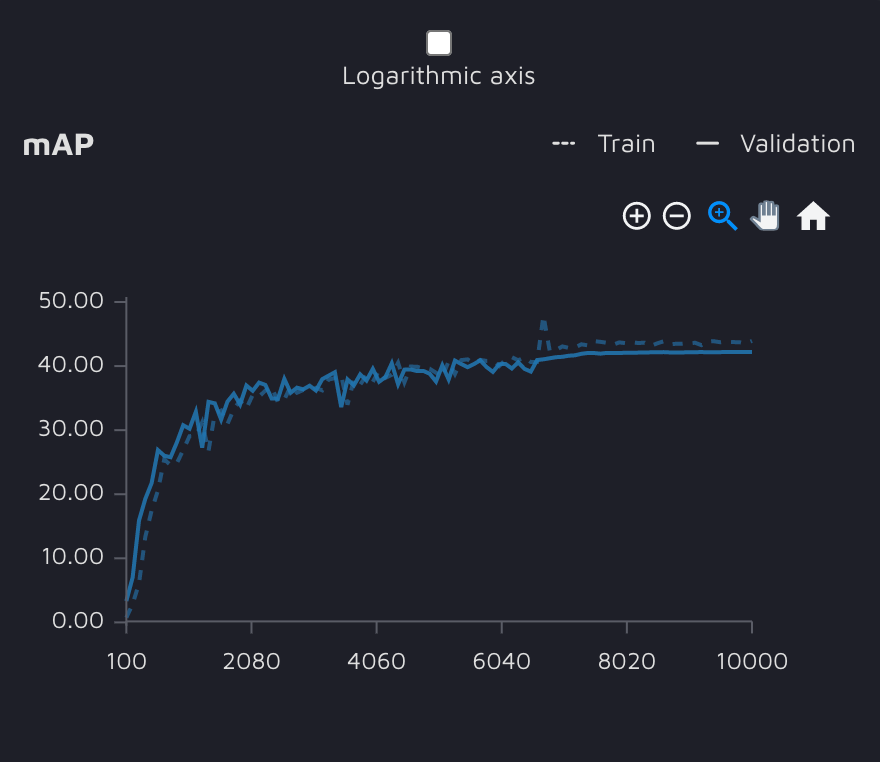
跨原始模型验证迭代的 COCO mAP 图。
使用这种架构实现的最终 COCO mAP 结果是验证时的 0.42 mAP。在原始 PASCAL 上训练的模型的性能不如最先进的架构。尽管如此,考虑到我们在构建模型上花费的时间和精力很少(经历了 3 次迭代,每次花费 1 小时),这仍然是一个不错的结果。无论如何,这样的结果会让我们的实验更有趣。让我们看看是否可以在不调整模型参数的情况下,通过改进数据来获得所需的指标值。
在更新的 PASCAL 上训练的自定义模型
在这里,我们采用相同的图像进行训练和验证,以训练以下模型作为基线。唯一的区别是拆分中的数据更好(添加了更多标签并修复了一些标签)。
不幸的是,原始数据集并没有在其训练 / 测试集拆分中包含 17120 个图像中的每一个,有些图片被遗漏了。因此尽管在原始数据集中添加了 6600 个标签,但在训练 / 测试拆分中,我们只得到了大约 3000 个新标签和大约 190 个修复标签。
尽管如此,我们继续使用 PASCAL VOC 2012 改进后的训练 / 测试拆分来训练和验证模型,看看效果如何。
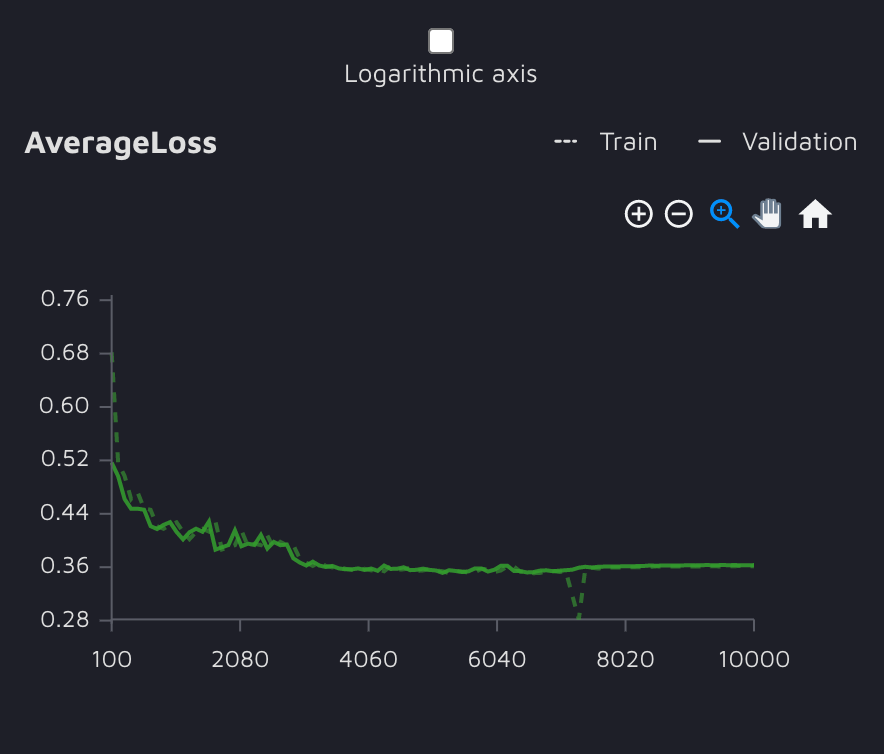
更新模型的训练迭代中的 AverageLoss 图。
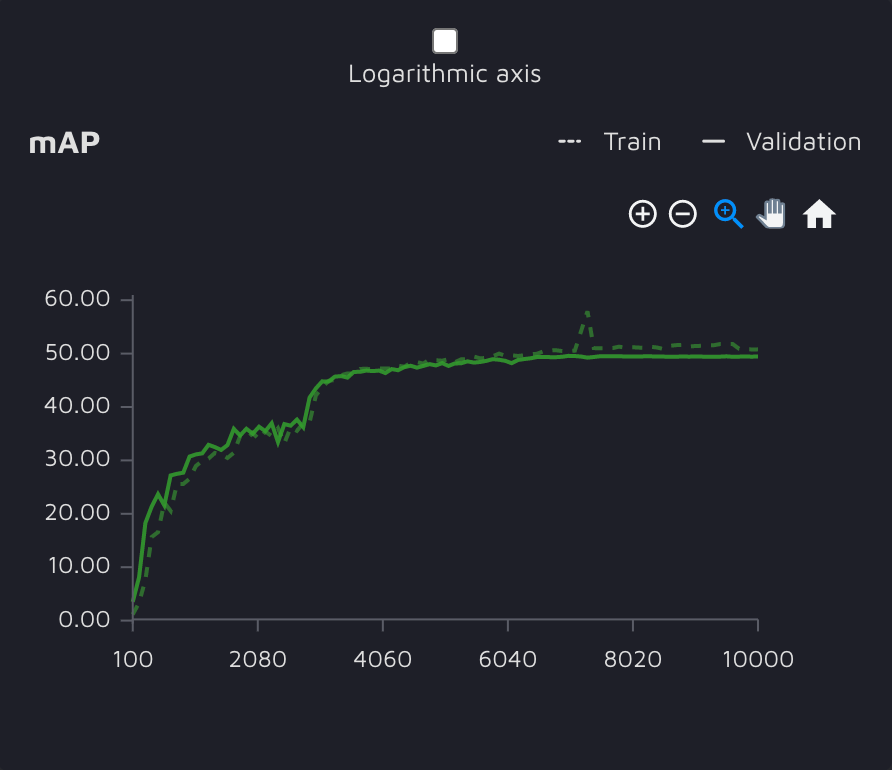
更新模型的验证迭代中的 COCO mAP 图。
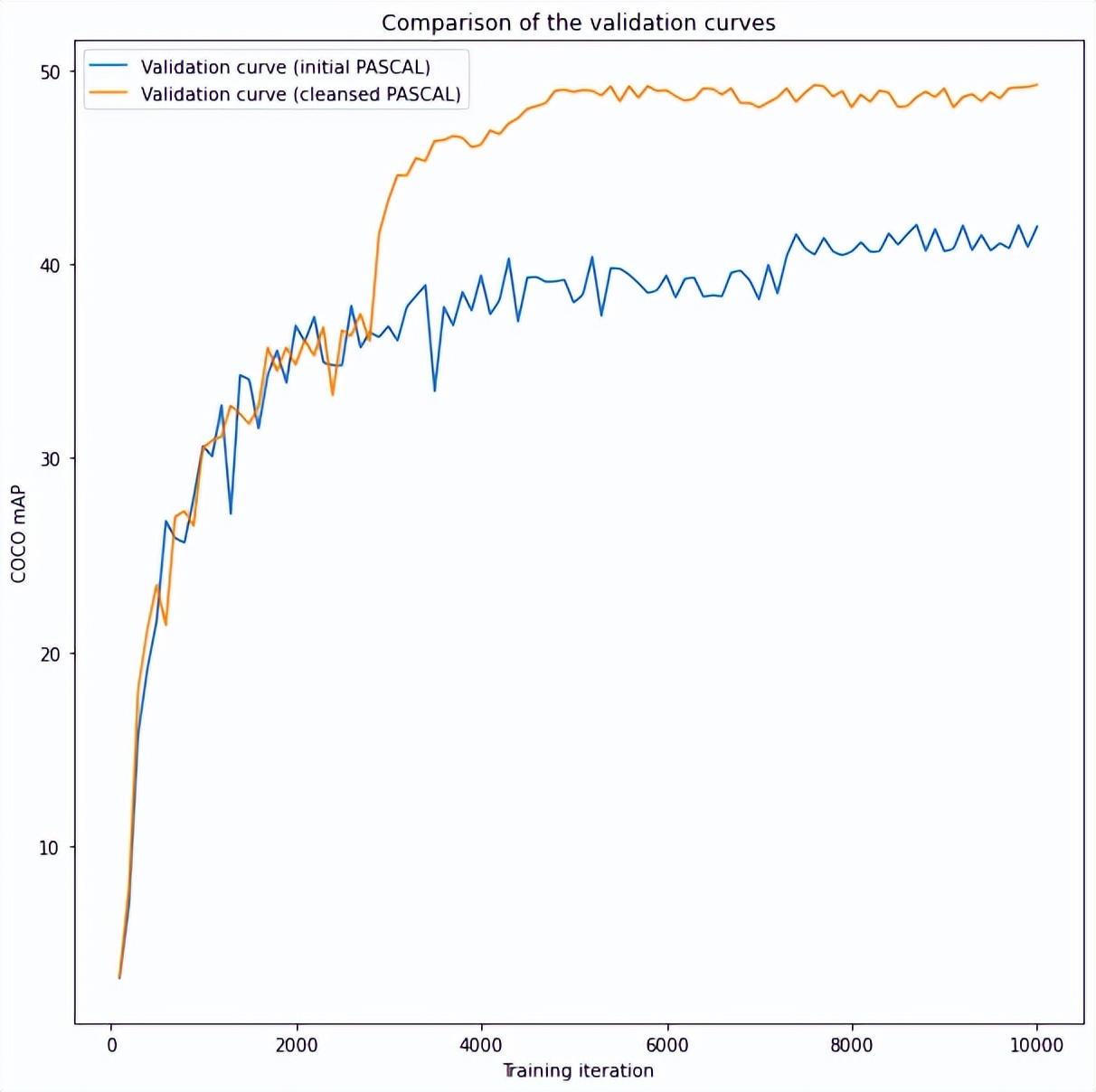
直接比较
正如我们所见,新模型的性能优于原始模型。与之前模型的 0.42 值相比,它在验证时达到了 0.49 COCO mAP。这样看很明显实验是成功的。
结果在 45-55 COCO mAP 之内,这意味着更新后的模型比原始模型效果更好,并提供了所需的度量值。是时候得出一些结论并讨论我们刚刚目睹的情况了。
结论
本文展示了以数据为中心的 AI 开发概念。我们的思路是通过提升数据以获得更好的模型,进而也获得了想要的结果。如今,当模型开始接近性能的上限时,通过调整模型将关键指标的结果提高 1-2% 以上可能是具有挑战性且成本高昂的事。但是,你不应该忽略构建机器学习并不仅仅是模型和参数,还有两个关键组成部分——算法和数据。
在该研究中,我们并没有试图击败任何 SOTA 或获得比此前研究更好的结果。我们希望通过实验结果展示:花费时间改进数据有利于模型性能。希望通过添加 3000 个缺失标签使 COCO mAP 增加 13% 的案例足够令人信服。
通过清理数据和向图像添加更多标签可以获得的结果很难预测。效果很大程度上取决于你的任务、NN 参数和许多其他因素。即使在本文的例子中,我们也不能确定多 3000 个标签会是能带来额外 13% mAP 的。尽管如此,结果不言自明。虽然有时很难确定通过获得更好的数据来改进模型指标的上限,这是值得尝试的方向。


















