












大家好,我是程序员幽鬼。
随着 Go1.18 发布,泛型已经到来。
一组新的排序函数也已经进入 Go[1]的 golang.org/x/exp/slices[2] 包。这些函数利用 Go 泛型提供更符合人体工程学的排序 API(无需用户实现sort.Interface[3]),并且还提供了不错的性能改进,如上面 CL 所示。
在这篇文章中,我将深入探讨为什么这些泛型函数比 sort 包中的现有函数更快,即使它们使用完全相同的算法和循环结构。希望这能成为一个有趣的一幕,与现有的动态调度机制(接口)相比,Go 泛型是如何实现的。
为了将我们的讨论与 Go 标准库和实验存储库的混乱细节分离,并能够专注于更小、更简单的代码示例,我在更简单的排序算法上重新实现了此比较,其中性能差异也体现在后面。
冒泡排序
首先是冒泡排序。
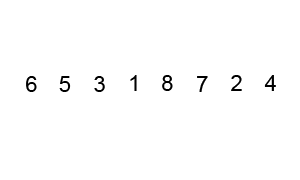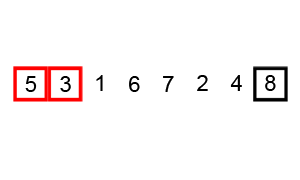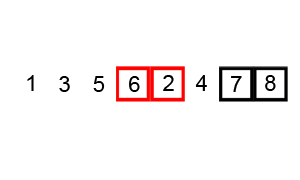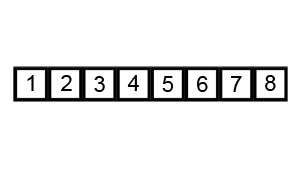
Bubblesort animation from Wikipedia
这篇文章的完整代码,以及测试和基准测试都可以在GitHub上找到[4]。下面是一个简单的气泡排序实现,使用 Go 中的 sort.Interface 接口进行自定义:
func bubbleSortInterface(x sort.Interface) {
n := x.Len()
for {
swapped := false
for i := 1; i < n; i++ {
if x.Less(i, i-1) {
x.Swap(i, i-1)
swapped = true
}
}
if !swapped {
return
}
}
}
sort.Interface[5] 是在 Go 的 sort 包中定义的接口,如下所示:
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
sort 包还提供了有用的类型适配器来填充 sort.Interface 到常见切片类型。例如,sort.StringSlice 使 []string 以升序对元素进行排序的方式实现此接口,我们可以编写如下内容:
var ss []string
// ... code that populates ss
bubbleSortInterface(sort.StringSlice(ss))
泛型版冒泡排序
下面是一个泛型版气泡排序,用于约束 constraints.Ordered 类型的切片。
func bubbleSortGeneric[T constraints.Ordered](x []T "T constraints.Ordered") {
n := len(x)
for {
swapped := false
for i := 1; i < n; i++ {
if x[i] < x[i-1] {
x[i-1], x[i] = x[i], x[i-1]
swapped = true
}
}
if !swapped {
return
}
}
}
代码逻辑相同,除了我们可以使用 len,< 并直接与多个赋值交换,而不是用接口方法。这是可以的,因为该函数知道有关其排序内容的重要事项:它是一个切片,并且它还实现了 Ordered。
性能测试
我通过对随机生成的 1000 个字符串的切片进行排序,对这两个实现进行了基准测试。这是我的机器上的结果:
$ go test -bench=.
goos: linux
goarch: amd64
pkg: example.com
cpu: Intel(R) Core(TM) i7-4771 CPU @ 3.50GHz
BenchmarkSortStringInterface-8 124 9599141 ns/op
BenchmarkSortStringGeneric-8 158 7433097 ns/op
泛型版本的速度提高了 20% 以上。总的来说,这是个好消息。Go 泛型不仅提供了一种方便的方法来编写作用于多种类型的代码,而且还可以提供性能优势!
在本文的其余部分,我们将讨论为什么泛型在这里更快。
分析接口版本
在本文附带的代码[6]中,我有一个独立的运行程序,可用于分析。它创建一个大切片,并使用命令行上提供的方法之一对其进行排序。它还支持基于 pprof 的 CPU 分析。让我们看看基于接口的冒泡排序:
$ ./bubble.out -cpuprofile cpui.out -kind strinterface
$ go tool pprof -list bubbleSortInterface ./bubble.out cpui.out
<...>
ROUTINE ======================== main.bubbleSortInterface
350ms 1.10s (flat, cum) 100% of Total
. . 26:
. . 27:func bubbleSortInterface(x sort.Interface) {
. . 28: n := x.Len()
. . 29: for {
. . 30: swapped := false
70ms 70ms 31: for i := 1; i < n; i++ {
160ms 830ms 32: if x.Less(i, i-1) {
20ms 100ms 33: x.Swap(i, i-1)
. . 34: swapped = true
. . 35: }
. . 36: }
100ms 100ms 37: if !swapped {
. . 38: return
. . 39: }
. . 40: }
. . 41:}
. . 42:
如预期的那样,该程序将大部分时间花在内部循环中进行比较和交换,但大多数只是比较。冒泡排序对长度为 N 的序列进行 O(N^2) 次比较。
如果大部分时间都花在比较上,那么研究这实际上意味着什么会很有趣。在此代码中调用 x.Less 时,CPU 执行哪些指令?幸运的是,我最近写了另一篇关于这个主题的博客文章[7]!我建议你至少略读它,但对于我们的目的来说,重要的部分是调用 x.Less 的指令序列:
MOVQ 0x48(SP), DX
MOVQ 0x20(DX), SI
LEAQ -0x1(CX), DI
MOVQ DI, 0x30(SP)
MOVQ 0x50(SP), AX
MOVQ CX, BX
MOVQ DI, CX
NOPL
CALL SI
在我们的代码中,运行 bubbleSortInterface(sort.StringSlice(ss)),所以我们必须转向 sort.StringSlice,用于定义将要调用的实际 Less 方法:
func (x StringSlice) Less(i, j int) bool { return x[i] < x[j] }
汇编代码看起来像这样:
CMPQ 0x10(R14), SP
JBE 0x4664d1
SUBQ $0x28, SP
MOVQ BP, 0x20(SP)
LEAQ 0x20(SP), BP
MOVQ AX, 0x30(SP)
CMPQ DI, BX
JBE 0x4664c5
SHLQ $0x4, DI
MOVQ 0(DI)(AX*1), DX
MOVQ 0x8(DI)(AX*1), R8
CMPQ SI, BX
JBE 0x4664b8
SHLQ $0x4, SI
MOVQ 0(AX)(SI*1), CX
MOVQ 0x8(AX)(SI*1), DI
MOVQ DX, AX
MOVQ R8, BX
CALL runtime.cmpstring(SB)
TESTQ AX, AX
SETL AL
MOVQ 0x20(SP), BP
ADDQ $0x28, SP
RET
如果这看起来比你预期的要长,那是因为 Go 中的切片索引受到保护,防止越界访问,而我们在函数开头看到的比较正是 - 跳转到调用 runtime.panicIndex 的部分代码(为简洁起见,我没有包括)。最后,通过调用 runtime.cmpstring 执行实际的字符串比较。就其本身而言,这是一个非常有趣的函数,它是在通用架构(例如 AMD64[8])的汇编中实现的,但是让我们在这里停止,因为这部分将在我们正在比较的两个实现中共享。
现在,我们应该相当全面地了解了 CPU 在使用接口调度版本运行冒泡排序时花费时间的位置。现在让我们看看泛型版本。
Go 1.18 中泛型如何实现的
Russ Cox 有一篇简短而优秀的博客文章,标题 The Generic Dilemma[9]。它的主要观点是,当一种语言决定是否拥有泛型以及如何实现它们时,它面临着以下决定:
你是否想要缓慢程序员,缓慢编译器和臃肿的二进制文件,或者缓慢的执行时间?
“缓慢编译器和臃肿的二进制文件”是指通过完全单态化[10]实现模板的 C++ 方法 —— 每个模板调用都被视为宏扩展,其完整代码复制粘贴正确的类型。
“缓慢的执行时间”是指 Java 的装箱方法,或动态语言,其中代码由于每次调用时的透明动态调度而变得微不足道。
请注意,这些描述都不是贬义的。这些都是语言设计师面临的真正权衡,包括 Go。
具体来说,Go 已经认真考虑了单态化(在 Go 世界中称为“stempciling”)和动态调度(在 Go 世界中称为“字典”):
- 泛型实现 - 模板设计文档[11]
- 泛型实现 - 字典设计文档[12]
由于上述原因,这两种方法本身都不是完美的。因此,提出了另一种设计:
- 泛型实现 - GC Shape Stenciling[13]
“GC shape” 方法是模板和字典两个极端之间的折衷。根据实例化的类型,我们要么单态化,要么使用动态调度。有一个更新的文档[14]详细介绍了 Go 1.18 如何执行此操作。
具体来说,不同的底层类型(如 int 和 string)将获得自己的 GC Shape,这意味着将为每个类型生成不同的函数,这些类型是硬编码的(因此这是单态化)。另一方面,所有指针类型都将分组为相同的 GC Shape,并将使用动态调度。
请注意,这是 Go 1.18 中的状态,它可能会,而且很可能在未来会改变,因为 Go 团队正在与社区协同,以了解最适合现实生活中工作负载的方法。
分析泛型版本
如果我们使用 pprof 来分析泛型版本,我们将看到它也花费了大部分时间进行比较,但总体上比接口版本花费的时间少。
如上一节所述,string类型将获得自己的 GC shape,因此其自己的函数将针对 string 类型进行硬编码。让我们看看汇编是怎样的。
首先,翻阅二进制文件的调试信息,我们将找到符号 bubbleSortGeneric[go.shape.string_0],它表示 bubbleSortGeneric 的模板版本,用于 string 当前唯一的成员的 GC shape。但是,我们不会将其作为要调用的独立函数,因为它已内联到其调用站点中。此内联不会以任何方式影响性能,因此我们只关注内部循环的说明,为了提醒你,这些指令会执行以下操作:
for i := 1; i < n; i++ {
if x[i] < x[i-1] {
x[i-1], x[i] = x[i], x[i-1]
swapped = true
}
}
它转换为此如下汇编:
MOVQ 0x80(SP), R8
INCQ R8
MOVQ 0x70(SP), CX
MOVQ 0x78(SP), BX
MOVQ R8, DX
MOVL AX, SI
MOVQ 0xb0(SP), AX
CMPQ DX, BX
JLE 0x4aef20
MOVQ DX, 0x80(SP)
MOVB SI, 0x3d(SP)
MOVQ DX, SI
SHLQ $0x4, DX
MOVQ DX, 0x90(SP)
MOVQ 0(DX)(AX*1), R8
MOVQ 0x8(DX)(AX*1), BX
LEAQ -0x1(SI), R9
SHLQ $0x4, R9
MOVQ R9, 0x88(SP)
MOVQ 0(R9)(AX*1), CX
MOVQ 0x8(R9)(AX*1), DI
MOVQ R8, AX
CALL runtime.cmpstring(SB)
MOVQ 0xb0(SP), DX
MOVQ 0x90(SP), SI
LEAQ 0(SI)(DX*1), DI
MOVQ 0x88(SP), R8
LEAQ 0(R8)(DX*1), R9
TESTQ AX, AX
JGE 0x4af01a
首先要注意的是,没有向 Less 方法发送动态调度。每次循环迭代都直接调用 cmpstring。其次,汇编的后半部分类似于前面显示的 Less 代码,但有一个关键区别 ——没有边界检查!Go 包括一个边界检查消除 (BCE) 通行证[15],它可以摆脱边界检查进行比较:
// ... earlier we had n := len(x)
for i := 1; i < n; i++ {
if x[i] < x[i-1] {
编译器知道 i 始终介于 1 和 len(x) 之间(通过查看循环描述和 i 以其他方式修改的事实),因此 x[i] 和 x[i-1] 都可以安全地访问切片内边界。
在接口版本中,编译器不会从 Less 中删除边界检查。该函数的定义如下:
func (x StringSlice) Less(i, j int) bool { return x[i] < x[j] }
谁知道会传递哪些指数!此外,由于动态调度,此函数未内联其调用方,编译器可以更深入地了解正在发生的事情。Go 编译器具有一些去冗长化功能,但它们在这里不起作用。这是编译器改进的另一个有趣的领域。
具有自定义比较函数的泛型排序
为了验证前面描述的一些观察结果,我实现了泛型冒泡排序的另一个版本。这一次,不依赖于 constraints.Ordered ,但改用比较函数:
func bubbleSortFunc[T any](x []T, less func(a, b T "T any") bool) {
n := len(x)
for {
swapped := false
for i := 1; i < n; i++ {
if less(x[i], x[i-1]) {
x[i-1], x[i] = x[i], x[i-1]
swapped = true
}
}
if !swapped {
return
}
}
}
我们可以使用此函数对字符串进行排序,如下所示:
bubbleSortFunc(ss, func(a, b string) bool { return a < b })
在阅读以下内容之前,你能否猜出与使用 < 的泛型排序以及基于接口的排序相比,这种方法在基准测试中的表现如何?
$ go test -bench=.
goos: linux
goarch: amd64
pkg: example.com
cpu: Intel(R) Core(TM) i7-4771 CPU @ 3.50GHz
BenchmarkSortStringInterface-8 124 9599141 ns/op
BenchmarkSortStringGeneric-8 158 7433097 ns/op
BenchmarkSortStringFunc-8 138 8584866 ns/op
它大约在中间!比其他泛型函数慢 14%,但比基于接口的版本快 10%。
在查看其汇编代码时,很容易看出原因。虽然基于函数的版本不会避免每次比较的函数调用(它必须调用作为参数提供的函数),但它确实避免了边界检查,因为对 x[i] 和 x[i-1] 的访问发生在函数的主体内(而不是在它调用的函数中)。所以我们获得了部分胜利。
这种比较具有有趣的现实意义,因为 SortFunc 也是添加到 golang.org/exp/slices 的变体,以提供更通用的排序功能(对于不受约束的类型)。此版本还提供了针对 sort.Sort 排序的加速。
另一个含义是用于对指针类型进行排序。如前所述,1.18 中的 Go 编译器会将所有指针类型分组到一个 GC Shape 中,这意味着它需要传递字典才能进行动态调度。这可能会使代码变慢,尽管 BCE 仍然应该启动 —— 所以不会慢很多。我在代码库[16]中有一个基准测试来演示这一点。
最后,作为一个简单的练习 - 采用此处显示的冒泡排序函数,并使用泛型函数与基于接口的函数对大片整数进行基准排序。你可能会看到相比字符串,泛型有大规模加速。你能弄清楚为什么吗?
总结由 Planetscale 工程师撰写的这篇文章[17]描述了一些场景,在这些场景中,将单态代码转换为泛型会使其明显变慢。这是一篇非常好的文章,值得一读(我喜欢反汇编小部件)。
值得一提的是,Go 中的泛型是非常新的。我们现在使用的是最近发布的初始实现!第一个版本专注于使泛型完全正常工作,并花费了大量精力来校正许多棘手的角落情况。性能[18]也是有计划的,但现在还不是最高优先级。
也就是说,实施工作在不断变化,并且一直在改进。例如,这个 Go 更改[19] 将进入 Go 1.19,已经修复了 Planetscale 文章中讨论的一些问题。另一方面,由于 The Generic Dilemma 中讨论的原因,Go 的泛型在所有可能的情况下都不太可能是“零成本”的。Go 非常重视快速的编译时间和紧凑的二进制大小,因此它必须对任何设计进行一定的权衡。
原文链接:https://eli.thegreenplace.net/2022/faster-sorting-with-go-generics/
参考资料
[1]也已经进入 Go: https://go-review.googlesource.com/c/exp/+/378134
[2]golang.org/x/exp/slices: https://pkg.go.dev/golang.org/x/exp/slices
[3]sort.Interface: https://pkg.go.dev/sort#Interface
[4]都可以在GitHub上找到: https://github.com/eliben/code-for-blog/tree/master/2022/genericsort
[5]sort.Interface: https://pkg.go.dev/sort#Interface
[6]本文附带的代码: https://github.com/eliben/code-for-blog/tree/master/2022/genericsort
[7]另一篇关于这个主题的博客文章: https://eli.thegreenplace.net/2022/interface-method-calls-with-the-go-register-abi/
[8]例如 AMD64: https://cs.opensource.google/go/go/+/master:src/internal/bytealg/compare_amd64.s;l=19?q=cmpstring&ss=go%2Fgo&start=11
[9]The Generic Dilemma: https://research.swtch.com/generic
[10]完全单态化: https://en.wikipedia.org/wiki/Monomorphization
[11]泛型实现 - 模板设计文档: https://go.googlesource.com/proposal/+/refs/heads/master/design/generics-implementation-stenciling.md
[12]泛型实现 - 字典设计文档: https://go.googlesource.com/proposal/+/refs/heads/master/design/generics-implementation-dictionaries.md
[13]泛型实现 - GC Shape Stenciling: https://github.com/golang/proposal/blob/master/design/generics-implementation-gcshape.md
[14]个更新的文档: https://github.com/golang/proposal/blob/master/design/generics-implementation-dictionaries-go1.18.md
[15]边界检查消除 (BCE) 通行证: https://go101.org/article/bounds-check-elimination.html
[16]代码库: https://github.com/eliben/code-for-blog/tree/master/2022/genericsort
[17]由 Planetscale 工程师撰写的这篇文章: https://planetscale.com/blog/generics-can-make-your-go-code-slower
[18]性能: https://wiki.c2.com/?MakeItWorkMakeItRightMakeItFast
[19]这个 Go 更改: https://go-review.googlesource.com/c/go/+/385274



















