1. 任务切换
现在有一块CPU,但是有两个程序都想来执行,我们需要开发一个任务调度程序。

只有两个程序,so easy啦!让它们交替执行就行了。
为了实现切换,我们提供一个API,这两个程序执行一会儿就主动调用一下这个API,然后在这个API内部实现任务的切换。
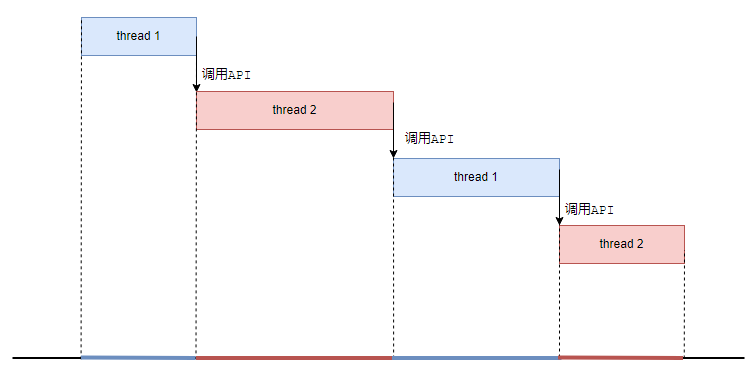
所谓的切换,其实就是把当前进程的上下文(也就是CPU一堆的寄存器值)保存到进程的TCB(进程控制块,每个进程对应的内存数据结构)里。然后把另一个进程TCB里的上下文寄存器的值装载起来,开始运行。
这是一种主动配合式的调度。
2. 抢占
然而,理想很美好,现实很骨感。
这些个程序可能不是那么听话,可能很久都不调用我们的API交出CPU,甚至可能搞了个死循环,另一个程序永远也没机会执行。
看来:不能依赖程序主动交出执行权,调度程序需要有抢占CPU的能力!
怎么抢占呢?
我们可以利用时钟中断!
因为一旦有中断事件到来,CPU就得去执行中断处理程序。只要在时钟中断的处理函数里面加入调度入口,就能抢到CPU的执行权。
为了公平起见,我们决定让每个进程都执行一小段时间,我们把这个叫做时间片,比如100ms,然后轮流执行它们就可以了,差不多是这个样子:
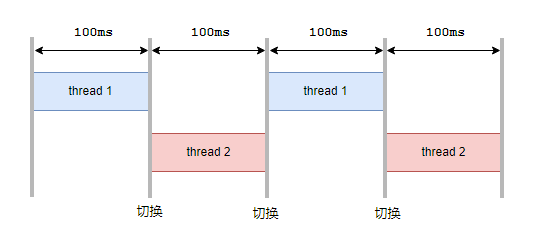
我们给CPU编程,让它每1ms发送一次时钟中断。在每个时钟中断到来时,检查当前的线程运行时间是否足够100ms,如果没有就将当前线程运行的时间+1ms,然后中断处理结束,让它继续运行。
如果检查发现时间已经到了100ms,就切换另一个进程来运行。
100ms对于人类几乎感知不到,所以还以为两个线程是在同时运行。
一个最最最简单的任务调度程序就完成了。
3. 阻塞
渐渐地,进程多了起来,3个、4个、5个···
我们用一个队列把它们存起来,先进先出,就叫做就绪队列吧,意思是准备要排队执行的队列。
所有就绪的进程,依次排队被我们的调度程序翻牌子执行。
没过多久,我们发现有些进程经常占着茅坑不xx,在sleep或者等待锁的时候,白白霸占着CPU空转,搞得队列里其他进程怨声载道。
那咱们对调度程序再做一个优化吧:当有进程等待锁、I/O等待或者sleep的时候,调度程序也需要介入,即使分配给它的时间片还没用完,也要让它主动交出CPU,并把它放到另一个等待队列里去,等到等待的条件满足的时候,再把它请回到就绪队列排队。
现在,我们的调度程序不再允许有占着CPU却摸鱼的现象发生。
4. 优先级
后来,进程进一步多了起来,6个、7个、···、100个。
每一个进程都执行100ms,转一圈下来就是10000ms=10s。
一个打字程序,按了键盘10s钟之后才反应过来,这系统卡的一匹,简直没法用。
我们可以把每个进程执行的时间缩短为10ms,转一圈下来变成了1000ms=1s,情况好了很多,但还是有点卡。
而且这一招架不住进程越来越多,200个,300个,甚至更多,转一圈的时间还是在变长。
但又不好继续压缩时间,否则就花太多时间在切换上了,真正执行的时间变少。
归根结底,问题在于进程多了以后,再按照顺序轮转不合时宜了。
得让一些进程拥有VIP特权,能够优先执行。
要不这样吧,给每个进程设定一个优先级,从1到40,总共40个优先级,数字越大,优先级越高。

调度的时候,把队列遍历一圈,找出里面优先级最高的进程来执行。
现在,我们只需要给打字程序这样的交互式进程设定一个高优先级,再次按下键盘后,很快就能得到响应了。
5. O(1)复杂度
每次调度的时候都得去遍历所有的进程,这复杂度是O(N)。
进程少倒还不打紧,多了以后就有些恼火了,这效率太低了。
让所有进程一起排在一个大的队列里,不是一个明智的做法。
要不我们按照优先级拆分成不同的队列吧!每个优先级单独弄一个就绪队列,就是40个队列,分开排队,找起来效率更高。
调度的时候,按照优先级顺序,依次来看每一个队列是否有可以执行的进程,找到后就从队列里取出来执行,相同优先级队列里面的进程,轮流执行。

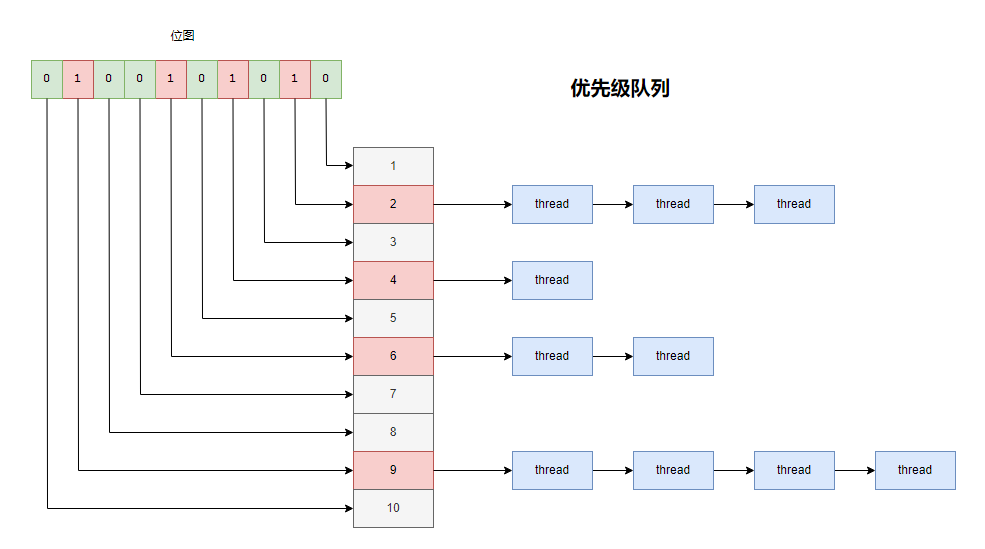
为了快速知道每一个优先级队列里面有没有进程,咱们再弄一个位图,40个bit,每一位表示一个优先级队列,如果是1就知道这个优先级的队列里有进程需要执行,为0就没有。
关于这个优先级队列,差不多可以这样定义:
struct priority_queue {
int nr_active; // 所有队列的进程总数
unsigned long bitmap[BITMAP_SIZE]; // 位图
struct list_head queue[MAX_PRIO]; // 队列数组
};
现在找起来可方便了,进程再多也没事,都可以在O(1)的时间复杂度里找到要调度的进程。
6. 饿死问题
系统运行了一段时间,发现了一个重要的问题:由于高优先级进程的存在,低优先级的程序很难得到执行机会,容易被“饿死”。
除非高优先级的进程执行结束,或者在睡眠等待,否则只要它一直待在就绪队列里,其他进程就没有机会。
这可不行呀,虽然你优先级高,但总得给别人分口吃的吧。
看来进程执行完成之后,不能马上把它再放回原来的队列里去,得这一轮大家都执行过后才行。
不放回原队列,那放哪里去呢?
干脆再弄一个优先级队列,把它叫做expired队列,并把原来的优先级队列叫做active队列。
调度的时候,从active队列里提取进程。完成一次调度后就把它放到expired队列,等原来的队列里的进程都挨个执行完一圈,active队列就空了,它们都来到了这个expired队列,然后交换两个队列,从头再来。
嗯,为了避免内存拷贝。把active和expired定义成指针,到时候直接交换两个指针,更省事儿!
把原来的队列封装一下:
struct runqueue {
struct priority_queue* active;
struct priority_queue* expired;
struct priority_queue array[2];
};
就这样,所有进程在两个队列中兜兜转转,现在低优先级的进程也有机会被执行到了,不会被饿死了。
7. 优先级与时间片
到目前为止,虽然进程有优先级之分,但这只影响它们的调度顺序,而不影响它们执行的时间,所有的进程时间片依然是100ms。
现在,优先级高的程序提出了抗议:我执行的任务很重要,需要给我更长的CPU时间片!
于是,一个新的需求来了:不同优先级进程,运行的时间片需要有区别。
优先级高的,时间片得长一点;优先级低的,时间片得短一些。
这个需求倒也好办,我们以中间优先级20为基础,设定优先级为20的进程时间片是100ms,优先级每增加1级,时间片+5ms,每减少一级,时间片-5ms。
优先级 ---- 时间片
1 5ms
2 10ms
3 15ms
··· ···
18 90ms
19 95ms
20 100ms # base
21 105ms
··· ···
39 195ms
40 200ms
现在,高优先级的进程不仅能够优先被执行,给它分配的运行时间也更多了。
上面的时间片分配算法还不算是完美,它有一个问题:
如果现在只有两个优先级为20和21的进程在运行,时间片分别是100ms和105ms,那么两个进程分别能获取到的CPU时间占比是100/(100+105)=48.7%和105/(100+105)=51.2%。
优先级增加1,CPU时间占比多了2.5%,看起来没什么问题。
现在如果换成只有两个优先级为1和2的进程在运行,时间片分别是5ms和10ms,那么两个进程分别能获取到的CPU时间占比是5/(5+10)=33.3%和10/(5+10)=66.7%。
优先级2只比优先级1的进程高了一级,获取的CPU时间占比就翻了一倍!
同样是优先级加1,这差距咋就这么大呢?
说好的公平呢?
8. 公平调度:时间分配
现在,我们换个思路,不用绝对时间片,而用相对时间片。
比如设定我们的调度周期为100ms,这100ms让所有可以运行的进程来瓜分,100ms之后所有就绪的进程都被执行了一圈儿。
那么问题来了,如何让进程们来瓜分这100ms呢?
当然是按照优先级来分。
我们给不同优先级的进程设置不同的权重,优先级高的,权重值高,就多分一点儿,优先级越低的,权重值低,就少分一点儿。


那这个权重值设定为多少好呢?
别急,有人已经帮我们想好了,就是下面这个数组。
想知道为什么是这些数字而不是别的,是有讲究的,不过先不用管。
const int sched_prio_to_weight[40] = {
88761, 71755, 56483, 46273, 36291,
29154, 23254, 18705, 14949, 11916,
9548, 7620, 6100, 4904, 3906,
3121, 2501, 1991, 1586, 1277,
1024, 820, 655, 526, 423,
335, 272, 215, 172, 137,
110, 87, 70, 56, 45,
36, 29, 23, 18, 15,
};
现在,各个进程按照自己优先级对应的权重,来从这100ms的调度周期里来分配时间。
不知道你发现没有,如果进程特别多,那可能分下来的时间就会很少。咱们还得设定一个最小值,不然一天天的净跑去调度切换了,真正执行的时间少了。
这个最小值,就是进程至少得运行这么久才能切换。
9. 公平调度:进程选择
时间分配的问题解决了,还有一个问题:调度的时候,如何挑选下一个需要执行的进程呢?
前面我们按照权重来给大家分配了时间,但肯定有一些进程,因为I/O、锁、睡眠等原因没有把分配的时间用完,这一些进程应该得到补偿,一旦它们符合执行条件后,应该优先被执行。
主动放弃了CPU的进程,它们运行的时间肯定比分配的短。要不,按照进程运行的时间来排个序,挑选时间最短的进程来运行?
但是,不同进程优先级不一样,分配到的时间本来就有长短啊。
要是能够消除因为权重造成的时间分配长短不一问题就好了,就能用运行时间来排序了。
要不咱们再弄一个虚拟运行时间,把权重带来的影响再给修复回去?
比如优先级高的进程,分配的时间多,统计它的运行时间的时候,就让它流逝的慢一些。
而优先级低的进程,分配的时间少,统计它的运行时间的时候,就让它流逝的快一些。
这样所有进程在没有任何睡眠、等待、I/O的情况下,大家都是用完了自己的时间,消除权重后的虚拟时间都应该是一样一样的,都是整个调度周期的1/N!
这才叫公平嘛!

现在只需要把所有进程按照虚拟时间来排个序,排在前面的虚拟时间短,调度的时候就选择它来运行。
好主意,那用什么样的数据结构来组织管理进程呢?
数组?插入不方便。
链表?寻找插入位置的时候时间复杂度是O(N)。
用二叉搜索树貌似是个不错的方案。左节点虚拟时间比父节点和右节点的虚拟时间小,只要找到最左边的节点就是要调用的进程,时间复杂度是O(LogN)。
但二叉搜索树有个毛病,一个不小心就容易变成一棵“跛脚”的树,这时间复杂度就又上去了。
红黑树没有这个问题,它自带平衡性,要不就它吧!
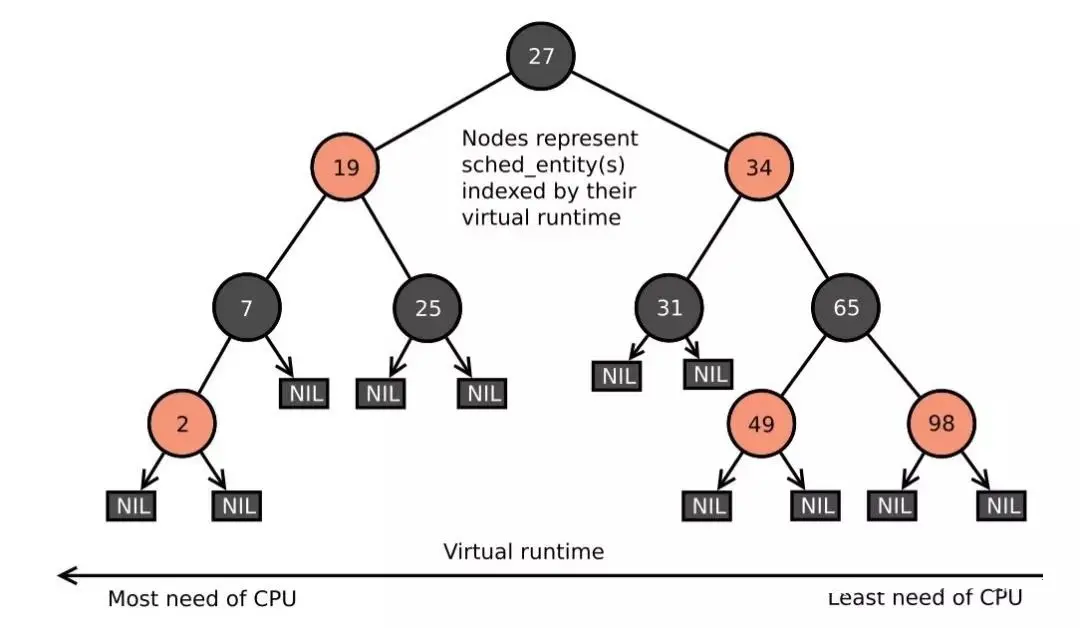
根据虚拟时间来把所有待运行的进程组织成一棵红黑树,只要找到整棵树最左边的节点,就是要运行的进程。
不过为了更高效,树调整更新导致最左边节点发生变化的时候,把它给缓存起来,这样调度的时候就直接拿到这个缓存节点就好了。
完美!
总结
上面讲述的进程调度模型其实就是Linux中O(1)调度算法和CFS(完全公平调度算法)调度算法的雏形,为了便于理解,文中进行了一定程度的简化。包括但不限于:
- 在实际的Linux中,进程优先级有140个,分为实时进程和非实时进程。
- 在实际的Linux中,进程通过一个叫nice值(对其他进程的友好度,nice越大,越友好,越谦让,优先级越低)的东西映射到优先级,优先级数字越大,优先级反而越低。
- 在实际的Linux中,进程的优先级分为静态和动态,是会随着运行而变化的,不是固定不变。
- 在多核模式下,为了防止加锁带来的性能损失,每一个CPU核都有自己的调度队列。
- 在实际的Linux中,参与调度的是线程,而不是进程。但在早期的Linux中,没有线程的概念,调度就是基于进程来进行,引入线程后,线程又称为轻量级进程。现在我们平时所说的进程和线程在语义上有所不同,这一点要注意区别。
看完了这篇文章,再去看Linux的调度算法,应该会轻松不少。