译者 | 朱先忠
审校 | 梁策 孙淑娟
K-最近邻(K-Nearest Neighbors,KNN)是一种监督学习机器算法,可用于解决机器学习算法中的回归和分类任务。
KNN可根据当前训练数据点的特征对测试数据集进行预测。在假设相似的事物在很近的距离内存在的情况下,通过计算测试数据和训练数据之间的距离来实现这一点。
该算法将学习过的数据存储起来,使其在预测和分类新数据点时更加有效。当输入新的数据点时,KNN算法能够学习该数据的特征。然后,它会把该新的数据点放在那些更接近共享相同特征的当前训练数据点的位置。
一、KNN中K的含义
通俗来讲,KNN中的“K”是一个参数,表示最近邻的数字。K是一个正整数,通常值很小,建议指定为奇数。K值为数据点创建了一个环境,这样可以更容易地指定哪个数据点属于哪个类别。
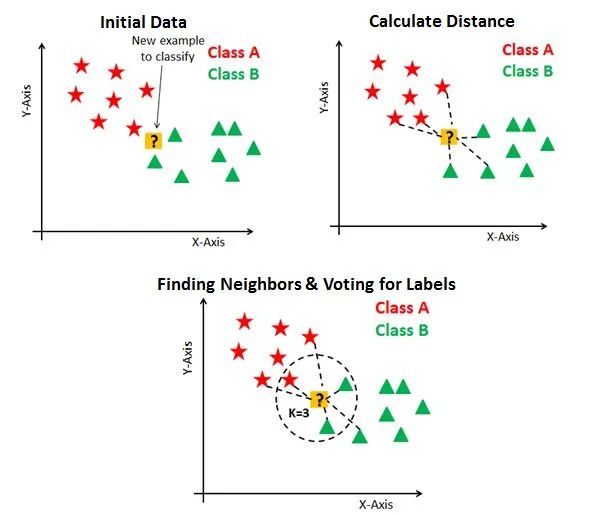
下面的例子显示了3个图表。首先,第一张图负责完成数据的初始化,其中实现了绘制数据点并把它们归属为不同的分类(A与B),并给出了一个待分类的新的样本。第二张图负责完成距离的计算。此图中,计算从新样本数据点到最近训练数据点的距离。然而,这仍然没有完成对新的样本数据点进行分类。因此,使用K值本质上就是创建了一个邻域,我们可以在其中对新的样本数据点进行分类。
于是,我们可以说,当k=3时新数据点将归属B类型。因为与A类型相比,有更多训练过的B类数据点具有与新数据点类似的特征。
图表来源:datacamp.com
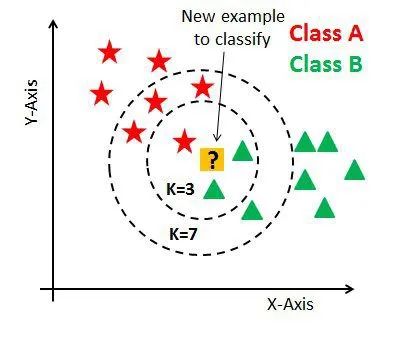
如果我们将K值增加到7,新数据点将属于A类型。因为与B类型相比,有更多训练过的A类型数据点具有与新数据点类似的特征。
图表来源:datacamp.com
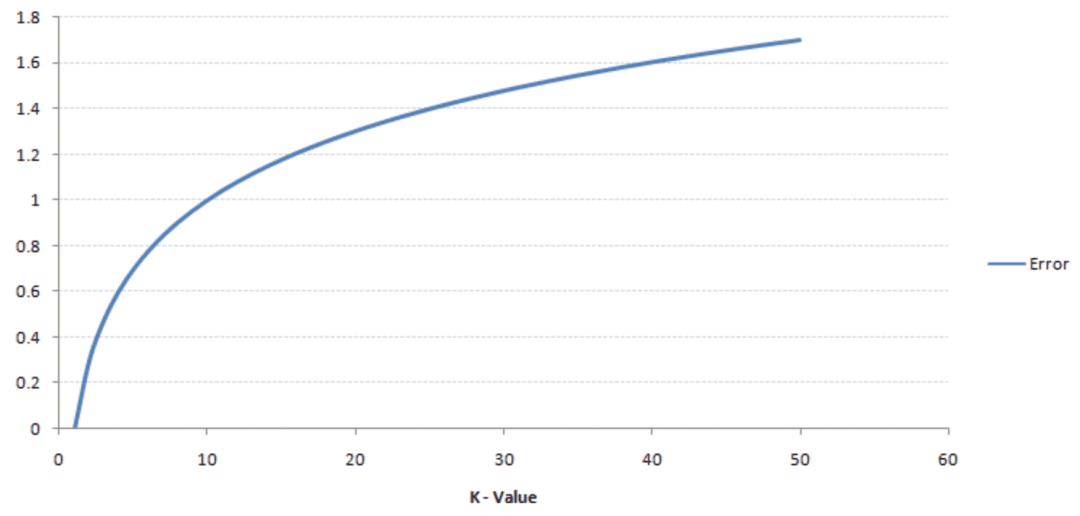
K值通常是一个小数字,因为随着K值的增加,错误率也会上升。下图显示了这一点:
图表来源:analyticsvidhya
然而,如果K值很小,则会导致低偏差但高方差,从而导致模型过度拟合。
此外,我们还建议把K值指定为奇数。因为如果我们试图对一个新数据点分类,而我们只有偶数个类型(例如A类型和B类型)的话,则可能会产生不准确的输出。因此,强烈建议选择带有奇数的K值,以避免出现“平局”情况。
二、计算距离
KNN会计算数据点之间的距离,以便对新数据点进行分类。在KNN中计算该距离最常用的方法是欧几里得法、曼哈顿法和明可夫斯基(Minkowski)法。
欧几里德距离是使用两点之间的直线长度来算出两点间的距离。欧氏距离的公式是新数据点(x)和现有训练数据点(y)之间的平方差之和的平方根。
曼哈顿距离是两点之间的距离,是它们笛卡尔坐标绝对差的总和。曼哈顿距离的公式是使用坐标轴上的线段来计算新数据点(x)和现有训练数据点(y)之间的长度之和。
明可夫斯基距离是赋范向量空间中两点之间的距离,是欧几里德距离和曼哈顿距离的推广。在p=2时的明可夫斯基距离公式中,我们得到了欧几里得距离,也称为L2距离。当p=1时,我们得到曼哈顿距离,也称为L1距离,或者称城市街区距离,又叫作LASSO距离。
下图给出了相应的公式:

下图解释了三者之间的区别:
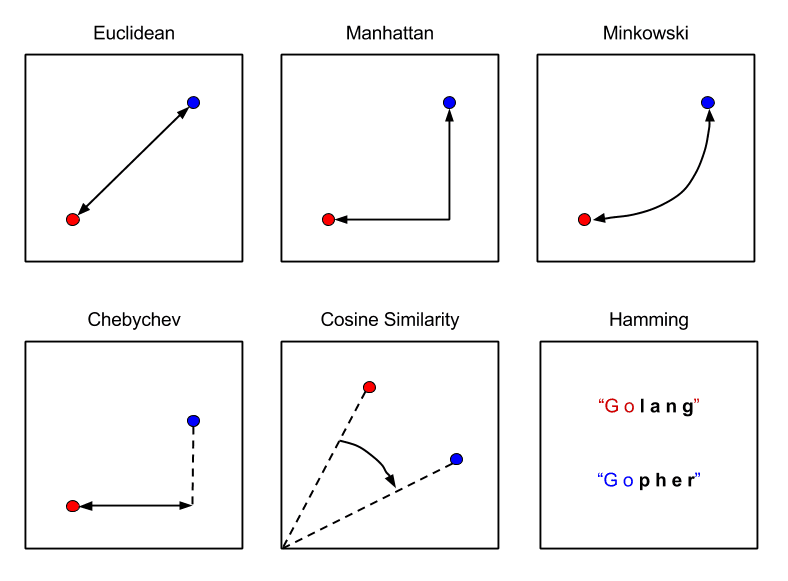
图表来源:Packt订阅
三、KNN算法工作原理
- 以下给出了KNN算法的工作步骤:
- 加载数据集
- 选择一个K值,建议使用奇数以避免平局情形。
- 计算新数据点与相邻现有训练数据点之间的距离。
找到距离新数据点最近的第K个邻近点。
下图概述了这些步骤:
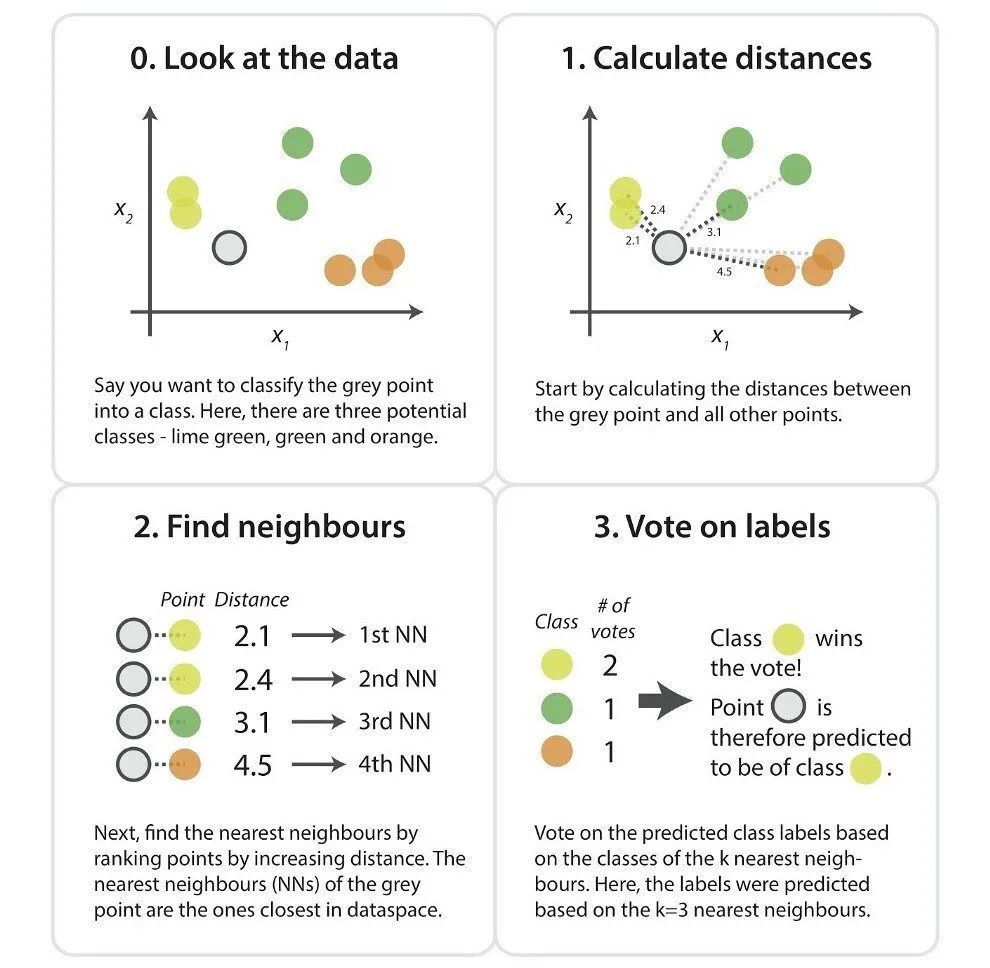
图表来源:kdnuggets.com
四、KNN算法的分类任务应用举例
下文是一个借助Iris数据集在分类任务中使用KNN算法的示例:
1.导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
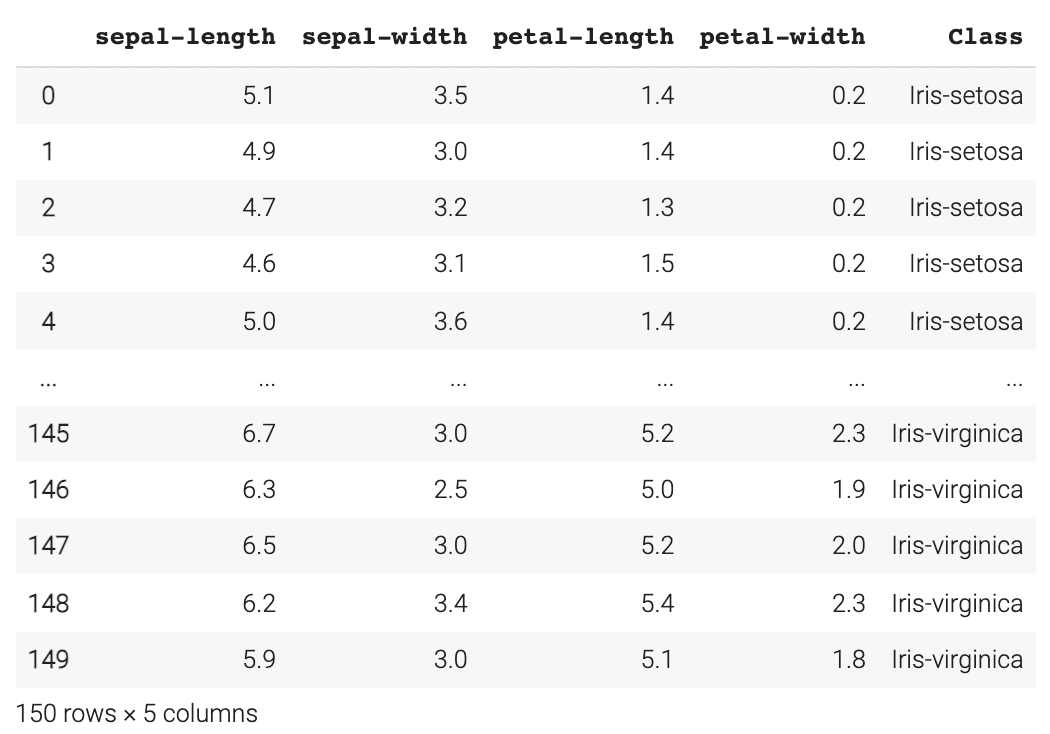
2.加载Iris数据集
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
#指定列名称
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
#读入数据集
dataset = pd.read_csv(url, names=names)
至此的执行结果如下所示:
3.数据预处理
这样做是为了将数据集拆分为属性和标签。X变量将包含数据集的前四列,我们称之为属性,y变量将包含最后一列,我们称之为标签。
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
4.划分为训练集与测试集
在这一步中,我们将把数据集分成训练和测试两部分,从而了解算法对训练数据的学习程度,以及它在测试数据上的表现。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
5.特征缩放
特征缩放是在预测之前对数据预处理的一个重要步骤。下面的方法用于规范化数据的特征范围。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
6.用KNN做出预测
首先,我们需要从sklearn.neighbors库导入KNeighborsClassifier类,然后选择K值。在这个例子中我选择了7(记住,强烈建议选择一个奇数值以避免平局情况)。
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=7)
classifier.fit(X_train, y_train)
然后,我们继续对测试数据集进行预测。
y_pred = classifier.predict(X_test)
7.算法准确性评估
借助sklearn.metrics库,我们可以通过分类报告来评估算法的准确性,查看精确度、召回率和F1分数。
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
下面给出该代码的执行结果:
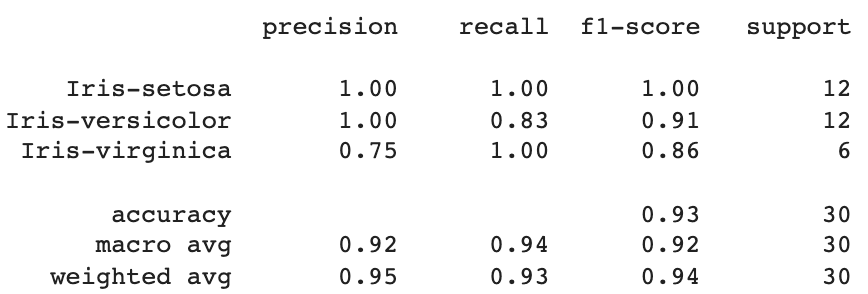
由此我们可以看出,KNN算法对30个数据点进行了分类,平均总准确率为95%,召回率为93%,F1分数为94%。
8.找到正确的K值
在本例中,我选择了K值为7。如果我们想检查最佳K值是什么,我们可以生成一个图表以显示不同的K值及其产生的错误率。我将研究1到30之间的K值情况。为此,我们需要在1到30之间执行一个循环,在每次循环期间计算平均误差并将其添加到误差列表中。相关代码如下:
error = []
#计算1到30之间的K值的错误率
for i in range(1, 30):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
绘制K值错误率图:
plt.figure(figsize=(12, 5))
plt.plot(range(1, 30), error, color='red', marker='o',
markerfacecolor='yellow', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
输出图形如下:
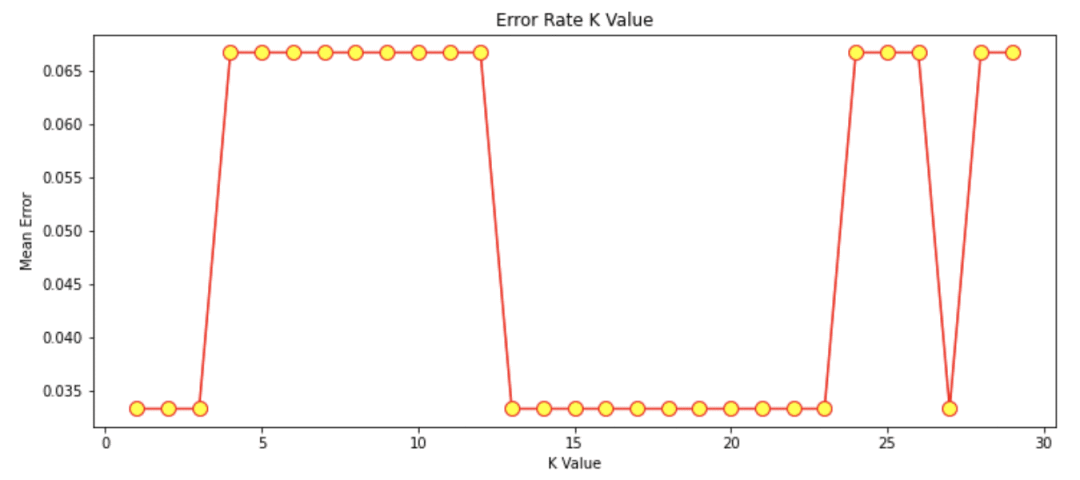
图形来源:本文作者例程输出结果
从上图可以看出,平均误差为0的K值主要在k值13-23之间。
五、总结
KNN是一种易于实现的简单的机器学习算法,可用于执行机器学习过程中的回归和分类任务。其中,K值是一个参数,表示最近邻的数值。实际应用中,建议把K值指定为奇数。另外,在KNN算法中你可以选择不同的距离度量算法(最常见的是使用欧几里得距离、曼哈顿距离和明可夫斯基距离)。
原文链接:https://www.kdnuggets.com/2022/04/nearest-neighbors-classification.html
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。