我们用 explain 分析包含 group by 的 select 语句时,从输出结果的 Extra 列经常可以看到 Using temporary; Using filesort。看到这个,我们就知道 MySQL 使用了临时表来实现 group by。
使用临时表实现 group by,成本高,执行慢。如果能够利用索引中记录已经排好序的特性,使用索引来实现 group by,那就是鸟枪换炮了。
本文我们一起来探寻 MySQL 使用索引实现 group by 的过程,使用临时表实现 group by 会单独用一篇文章来介绍。
本文内容基于 MySQL 5.7.35 源码。
1、 引言
使用索引实现 group by,最简单的方式,大概就是这样了:
- 存储引擎按顺序一条一条读取记录,返回给 server 层。
- server 层判断记录是否符合 where 条件。
- server 层对符合条件的记录进行聚合函数逻辑处理。
这种实现方式被称为紧凑索引扫描。
紧凑索引扫描会对满足 where 条件的所有记录进行聚合函数处理,而对于 min()、max() 来说,实际需要的只有每个分组中聚合函数字段值最小或最大的那条记录。
如果 server 层能直接从存储引擎读取到每个分组中聚合函数需要的那条记录,而不必读取每个分组中的所有记录进行聚合函数处理,是不是就可以节省很多时间了?
是的,这种只读取分组中部分记录实现 group by 的方式,被称为松散索引扫描。
为了方便描述,本文在需要的时候会以具体 SQL 作为示例说明,示例 SQL 的表结构如下:
CREATE TABLE `t_group_by` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`i1` int(10) unsigned DEFAULT '0',
`c1` char(11) DEFAULT '',
`e1` enum('北京','上海','广州','深圳','天津','杭州','成都','重庆','苏州','南京','洽尔滨','沈阳','长春','厦门','福州','南昌','泉州','德清','长沙','武汉') DEFAULT '北京',
`d1` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_e1_i1` (`e1`,`i1`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;1.2.3.4.5.6.7.8.9.
2、 紧凑索引扫描
group by 字段包含在索引中,并且满足索引最左匹配原则,server 层就可以顺序读取索引中的记录实现 group by,而不需要借助临时表。
紧凑索引扫描中的紧凑,表示 server 层从存储引擎读取记录时,以索引范围扫描或全索引扫描方式,按顺序一条一条读取记录,不会跳过中间的某条记录,示意图如下:
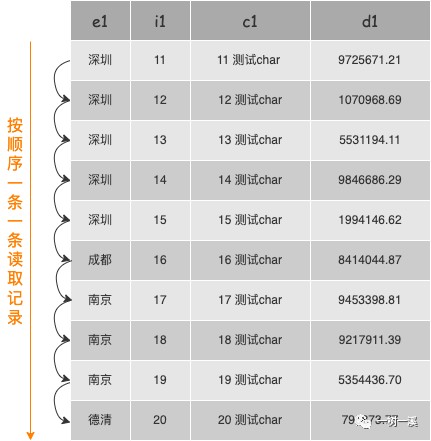
紧凑索引扫描
接下来,我们以 avg() 为例介绍紧凑索引扫描的执行过程,示例 SQL 如下:
select
e1, avg(i1) as t
from t_group_by
where d1 > 5452415
group by e11.2.3.4.5.
词法分析 & 语法分析阶段,avg(i1) 被解析为 Item_sum_avg 类,以下是该类的实例属性的其中 3 个:
- sum,保存分组求和结果。
- count,保存分组计数。
- args,avg() 函数的参数,avg() 只能有一个参数。args[0] 为 i1 字段对应的 Item_field 类实例。

Item_sum_avg
avg() 只有一个参数,为什么参数属性名是 args?
Item_sum_avg 类的实例属性 args 是从父类 Item_sum 继承得到的。
Item_sum_count 类(count() 对应的类)的实例属性 args 也是从父类 Item_sum 继承的,count() 可以有多个参数,所以,用 args 来表示聚合函数的参数。
查询准备阶段(prepare 阶段),i1 字段对应的 Item_field 类实例会关联到表 t_group_by 的 i1 字段。

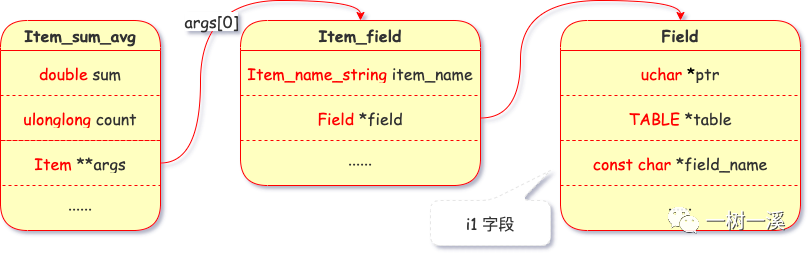
Item_sum_avg
执行阶段,server 层从存储引擎读取到一条记录之后,判断记录是否符合 where 条件(d1 > 5452415)。
记录不符合 where 条件,继续读取下一条记录。
记录符合 where 条件,进行聚合函数逻辑处理。
如果当前记录的分组前缀(示例 SQL 中 group by 的 e1 字段值)和上一条记录的分组前缀不一样,说明需要结束上一个分组,并开启新分组。
- 结束上一个分组:通过 sum / count 计算得到分组平均值(即 avg(i1) 的结果),把分组前缀及分组平均值发送给客户端。
- 开启新分组:Item_sum_avg 类的实例属性 sum、count 清零,当前记录的 e1 字段值作为新分组前缀,然后,新分组进行分组求和(sum 加上 i1 字段值)、分组计数(count 加 1)。
如果当前记录的分组前缀和上一条记录的分组前缀一样,说明还是同一个分组,只需要进行分组求和、分组计数,不需要计算平均值。
分组求和、分组计数代码如下:
bool Item_sum_avg::add()
{
// 分组求和
if (Item_sum_sum::add())
return TRUE;
// 分组计数(字段值不为 NULL 才进行计数)
if (!aggr->arg_is_null(true))
count++;
return FALSE;
}1.2.3.4.5.6.7.8.9.10.
只有字段值不为 NULL,分组计数(count)才会加 1。
了解 avg() 之后,count()、sum() 也就明白了。count()、sum() 和 avg() 的执行过程基本一样,不同之处在于:
- count() 对应的类 Item_sum_count 只有 count 属性,只需要进行分组计数,不需要分组求和、计算平均值。
- sum() 对应的类 Item_sum_sum 只有 sum 属性,只需要进行分组求和,不需要分组计数、计算平均值。
3、 松散索引扫描
松散索引扫描,从存储引擎读取分组记录时,会跳着读,读取分组前缀之后,直接通过分组前缀(group by 字段的值)定位到分组中符合 where 条件的第一条或最后一条记录,而不需要读取分组的所有记录,然后就接着读取下一个分组的分组前缀,这样可以减少 select 语句执行过程中需要读取的记录数,从而比紧凑索引扫描更快(有例外情况,后面会介绍)。
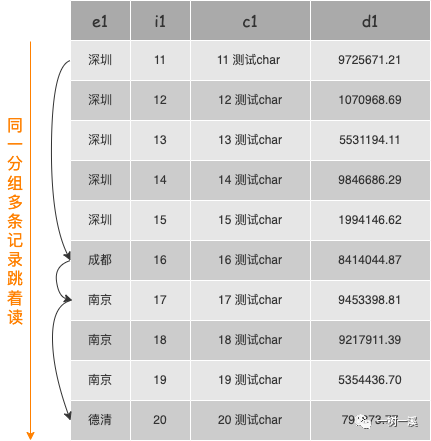
松散索引扫描
如果 select 语句执行过程中使用了松散索引扫描实现 group by,explain 输出结果的 Extra 列会显示 Using index for group-by。
松散索引扫描用于 min()、max(),可以减少需要读取的记录数;用于 count(distinct)、sum(distinct)、avg(distinct) ,可以对记录去重,避免使用临时表去重。
我们以 min() 为例介绍松散索引扫描的执行过程,示例 SQL 如下:
select
e1, min(i1)
from t_group_by
group by e11.2.3.4.
词法分析 & 语法分析阶段,min(i1) 被解析为 Item_sum_min 类,以下是该类的实例属性的其中 2 个:
- value,该属性类型为 Item_cache,Item_cache 子类的实例属性 value 保存分组最小值(分组记录中 i1 字段的最小值)。
- args,min() 函数的参数,args[0] 为 i1 字段对应的 Item_field 类实例。
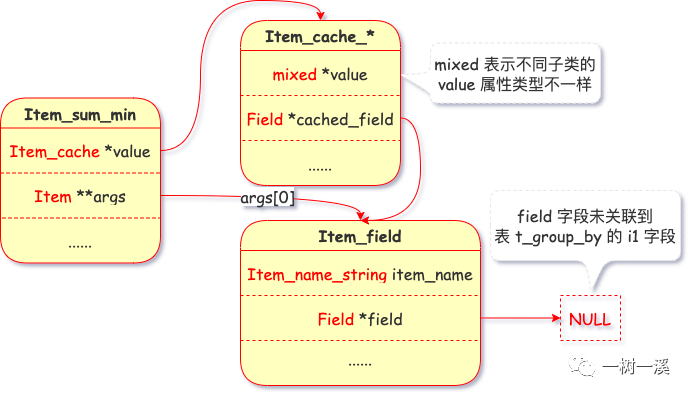
 Item_sum_min
Item_sum_min
查询准备阶段,i1 字段对应的 Item_field 类实例会关联到表 t_group_by 的 i1 字段。
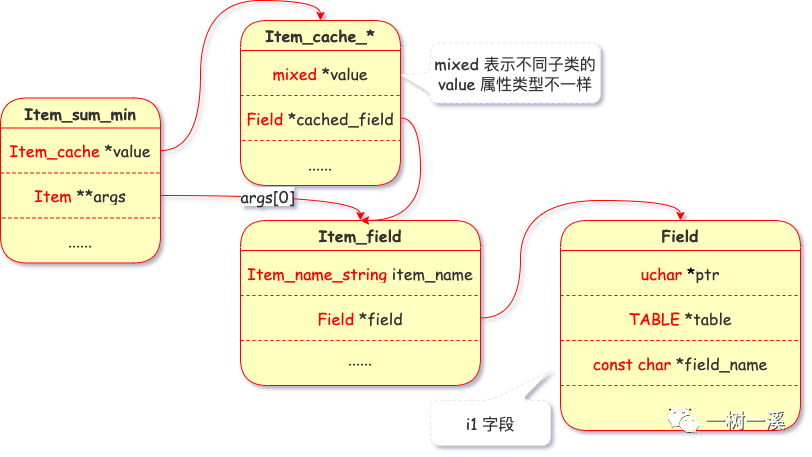
 Item_sum_min
Item_sum_min
执行阶段,读取分组最小值的过程分为两步:
- 读取分组前缀(示例 SQL 中 group by 的 e1 字段值),从存储引擎读取分组的第一条记录,得到分组前缀。
- 根据分组前缀读取分组最小值(分组记录中 i1 字段的最小值),用前面得到的分组前缀限定索引扫描范围,从存储引擎读取分组中 i1 字段的最小值,保存到 value 属性中。
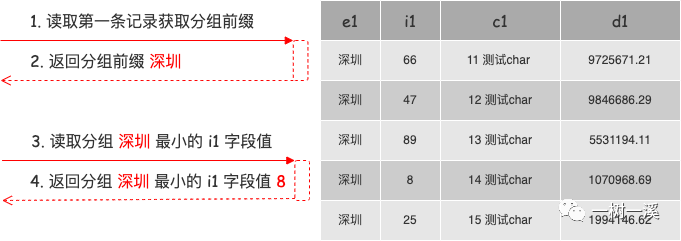
读取分组最小值
4、 两种索引扫描怎么选?
松散索引扫描虽然具备提升 select 语句执行效率的能力,但只有在适用的场景下才能发挥它的威力,因此,它的使用需要满足以下条件:
条件 1,select 语句只能是单表查询,不能是连接查询。
条件 2,group by 字段必须满足索引的最左匹配原则。例如:表中有一个索引包含 c1, c2, c3 三个字段,group by c1, c2 满足最左匹配原则。
条件 3,如果 select 字段列表中包含聚合函数,聚合函数必须满足这些条件:
- 所有聚合函数的参数都必须是同一个字段。
- 聚合函数字段必须是索引中的字段,并且 group by 字段 + 聚合函数字段也必须满足索引最左匹配原则。
- 聚合函数要么是 min()、max() 中的 1 ~ 2 个;要么是 count(distinct)、sum(distinct)、avg(distinct) 中的 1 ~ 3个。
松散索引扫描中,两类聚合函数不能同时存在,因为它们对于分组前缀处理逻辑不一样。在读取数据时,min()、max() 用 group by 字段值作为分组前缀;count(distinct)、sum(distinct)、avg(distinct) 用 group by 字段值 + 聚合函数中的字段值作为分组前缀。
条件 4,索引中所有字段必须是全字段索引,不能是前缀索引。
例如:有个字段 c1 varchar(20),索引中该字段为 index(c1(10)),这样的索引就不能用于松散索引扫描。
满足以上条件,还只是站在了使用松散索引扫描的门外,想要登堂入室,还必须进行成本评估。
如果松散索引扫描的成本比紧凑索引扫描的成本低,自然就要用松散索引扫描来提升 select 语句的执行效率了。
(1) 松散索引扫描成本更高怎么办?
松散索引扫描成本比紧凑索引扫描成本更高时,如果 select 语句中的聚合函数是 min()、max() 中的 1 ~ 2 个,就会使用紧凑索引扫描。
松散索引扫描自带去重功能,不需要借助临时表,和包含 distinct 关键字的聚合函数天生更匹配。紧凑索引扫描则需要借助临时表对记录进行去重。
如果聚合函数是 count(distinct)、sum(distinct)、avg(distinct) 中的 1 ~ 3 个,虽然紧凑索引扫描读取记录成本更低,但必须使用临时表对记录去重,这样一来,紧凑索引扫描读取数据 + 临时表去重的成本就比松散索引扫描成本更高了。
这就很尴尬了,两种方式各有优缺点,两难之下,MySQL 要怎么办?
两难之下,最好的选择就是找到第三个选项。为此,MySQL 祭出了一个大招,既要和紧凑索引扫描一样顺序读取数据,又要用松散索引扫描自带的去重能力。如果用了这个大招,在 explain 输出结果的 Extra 列可以看到 Using index for group-by (scanning)。
MySQL 把紧凑索引扫描中使用的顺序读取记录嵌入到松散索引扫描的逻辑里,当评估紧凑索引扫描成本比松散索引扫描低时,对于包含 distinct 关键字的聚合函数,就会用顺序读取记录代替跳着读取记录,并且在顺序读取记录的过程中完成记录去重。
对于松散索引扫描的这个变种,到写完本文为止,我还没有在哪里看到官方有正式的命名,为了方便记忆,估且把它命名为顺序松散索引扫描吧。
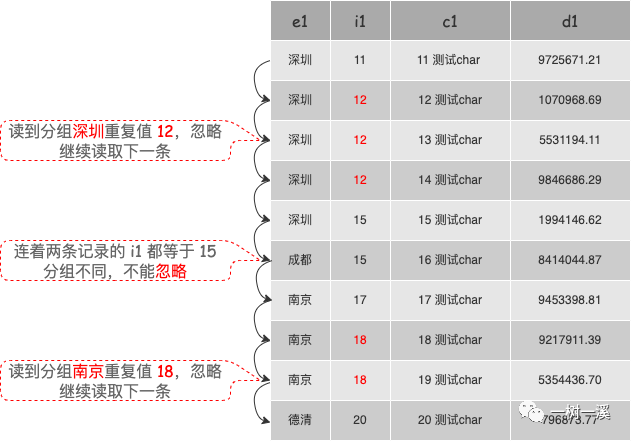
顺序松散索引扫描
(2) 为什么松散索引扫描会比紧凑索引扫描成本高?
紧凑索引扫描,存储引擎按顺序一条一条读取记录,返回给 server 层,server 层判断记录是否符合 where 条件,然后对符合条件的记录进行聚合函数逻辑处理。
松散索引扫描,对于每个分组,都会从存储引擎读取两次数据,第一次是读取分组的第一条记录,得到分组前缀;第二次是根据分组前缀读取分组中索引扫描范围的第一条或最后一条记录。
如果分组中的记录数量多,第二次读取记录时,能跳过的记录就多,节省的成本就多,松散索引扫描就会比紧凑索引扫描更快。
如果分组中的记录数量少,第二次读取记录时,能跳过的记录就少,每个分组读取两次记录增加的成本超过了跳过记录节省的成本,松散索引扫描就会比紧凑索引扫描更慢。
5、 总结
引言小节,介绍了 MySQL 实现 group by 的两种索引扫描方式:紧凑索引扫描、松散索引扫描。
紧凑索引扫描小节,以 avg() 为例介绍了紧凑索引扫描的执行过程,avg() 在词法分析 & 语法分析阶段会被解析为 Item_sum_avg 类。该类的实例属性 sum、count、args 分别用于保存分组求和结果、分组计数、avg() 函数的参数。
在执行阶段,通过把 avg() 字段值累加到 sum 属性进行分组求和;对 count 属性进行自增实现分组计数;通过 sum / count 计算得到分组平均值。
Item_sum_count、Item_sum_sum、Item_sum_avg、Item_sum_min、Item_sum_max 类的实例属性 args 都继承自父类 Item_sum,用于保存聚合函数参数,count() 支持多个参数,所以,参数的属性名为 args 而不是 arg。
松散索引扫描小节,以 min() 为例介绍了松散索引扫描的执行过程,执行阶段,分为两步读取分组最小值:读取分组前缀,根据分组前缀读取分组最小值。
两种索引扫描怎么选? 小节,介绍了使用松散索引扫描必须满足的一系列条件。
当松散索引扫描比紧凑索引扫描成本高时,min()、max() 会选择用紧凑索引扫描,MySQL 为 count(distinct)、sum(distinct)、avg(distinct) 引入松散索引扫描的变种,顺序读取索引记录(和紧凑索引扫描一样)+ 松散索引扫描自带的记录去重功能,避免了使用临时表对记录去重。
还介绍了松散索引扫描比紧凑索引扫描的成本高,是因为分组中记录数量少时,两次读取存储引擎数据增加的成本超过了跳着读取索引记录节省的成本。
本文转载自微信公众号「一树一溪」,可以通过以下二维码关注。转载本文请联系一树一溪公众号。