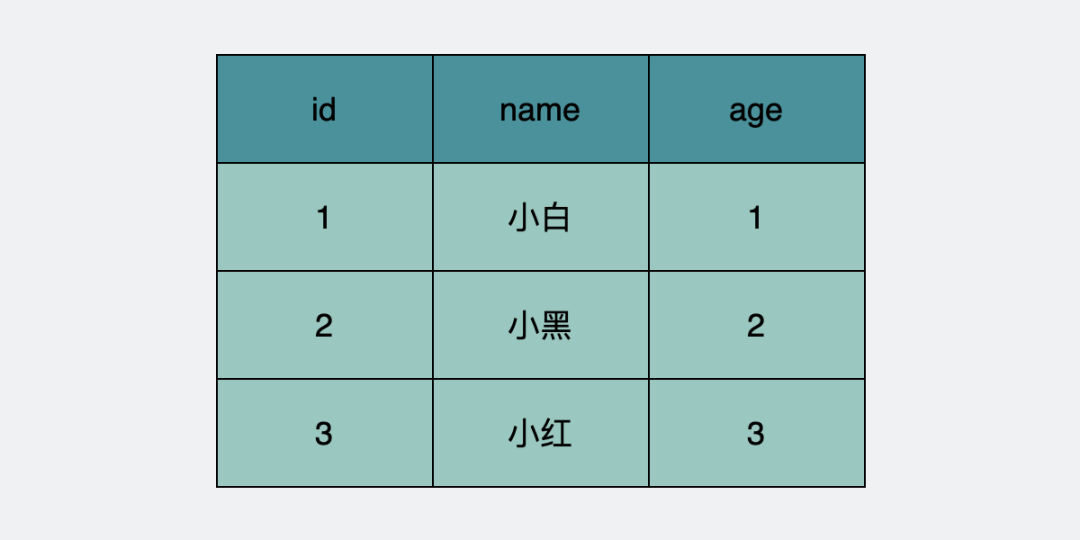
假设当前数据库里有下面这张表。
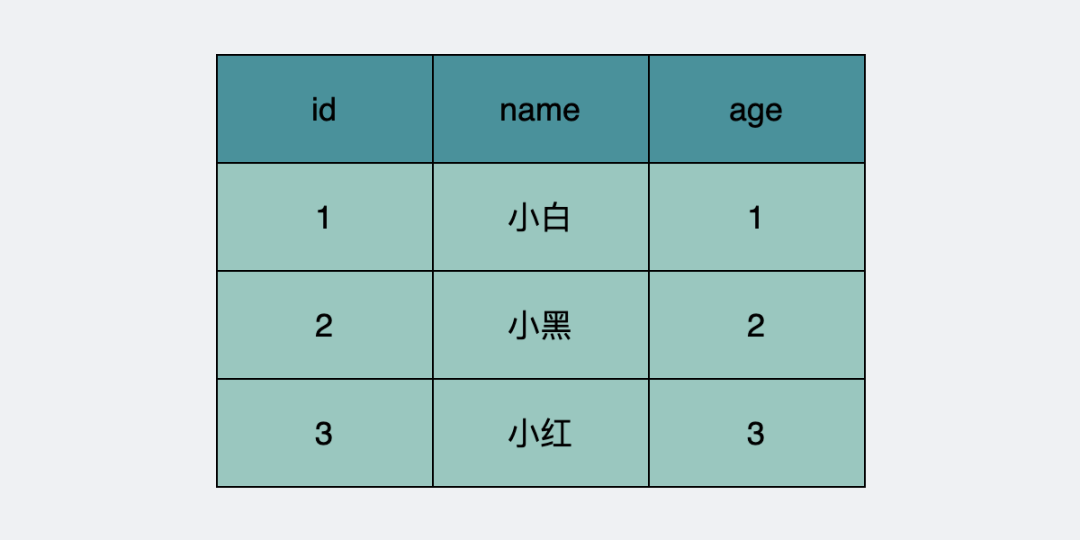
user表数据库原始状态
老规矩,以下内容还是默认发生在innodb引擎的可重复读隔离级别下。
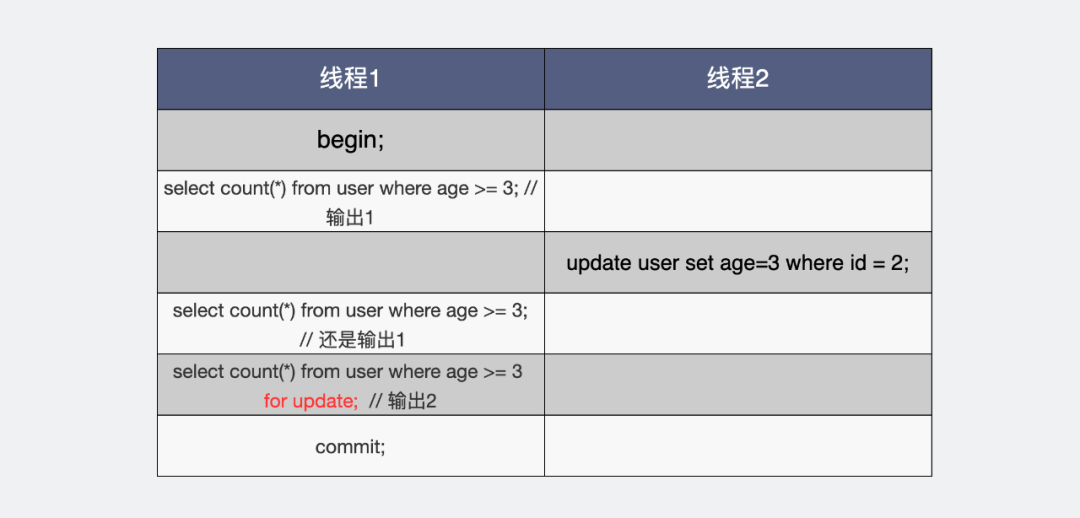
都是select结果却不同
大家可以看到,线程1,同样都是读 age >= 3 的数据。第一次读到1条数据,这个是原始状态。这之后线程2将id=2的age字段也改成了3。
线程1此时再读两次,一次读到的结果还是原来的1条,另一次读的结果却是2条,区别在于加没加for update。
为什么同样条件下,都是读,读出来的数据却不一样呢?
可重复读不是要求每次读出来的内容要一样吗?
要回答这个问题。
我需要从盘古是怎么开天辟地这个话题开始聊起。
不好意思。
失态了。
那就从事务是怎么回滚的开始聊起吧。
事务的回滚是怎么实现的
我们在执行事务的时候,一般都是下面这样的格式
begin;
操作1;
操作2;
操作3;
xxxxx
....
commit;
在提交事务之前,会执行各种操作,里面可以包含各种逻辑。
只要是执行逻辑,那就有可能会报错。
回想下事务的ACID里有个A,原子性,整个事务就是个整体,要么一起成功,要么一起失败。
ACID
如果失败了的话,那就要让执行到一半的事务有能力回到没执行事务前的状态,这就是回滚。
执行事务的代码就类似写成下面这样。
begin;
try:
操作1;
操作2;
操作3;
xxxxx
....
commit;
except Exception:
rollback;
如果执行rollback能回到事务执行前的状态的话,那说明mysql需要知道某些行,执行事务前的数据长什么样子。
那数据库是怎么做到的呢?
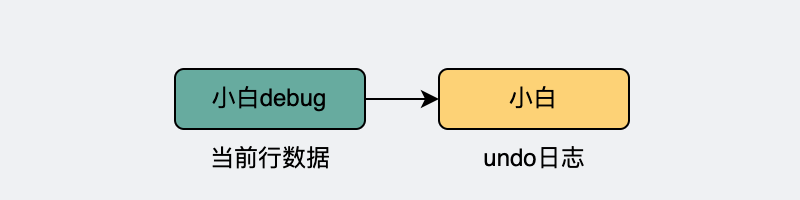
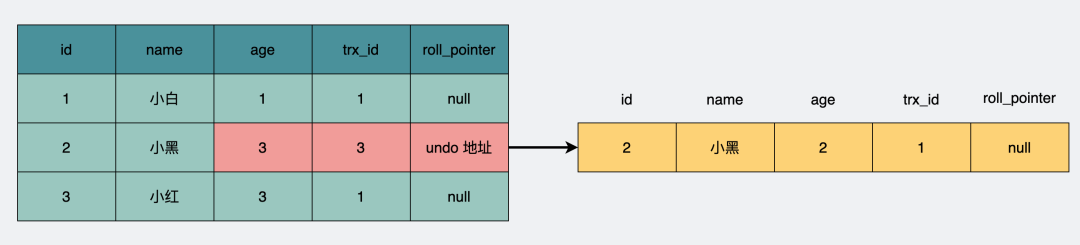
这就要提到undo日志了,它记录了某一行数据,在执行事务前是怎么样的。
比如id=1那行数据,name字段从"小白"更新成了"小白debug",那就会新增一个undo日志,用于记录之前的数据。
 un
un
do日志会记录之前的数据
由于同时并发执行的事务可以有很多,于是可能会有很多undo日志,日志里加入事务的id(trx_id)字段,用于标明这是哪个事务下产生的undo日志。
同时将它们用链表的形式组织起来,在undo日志里加入一个指针(roll_pointer),指向上一个undo日志,于是就形成了一条版本链。
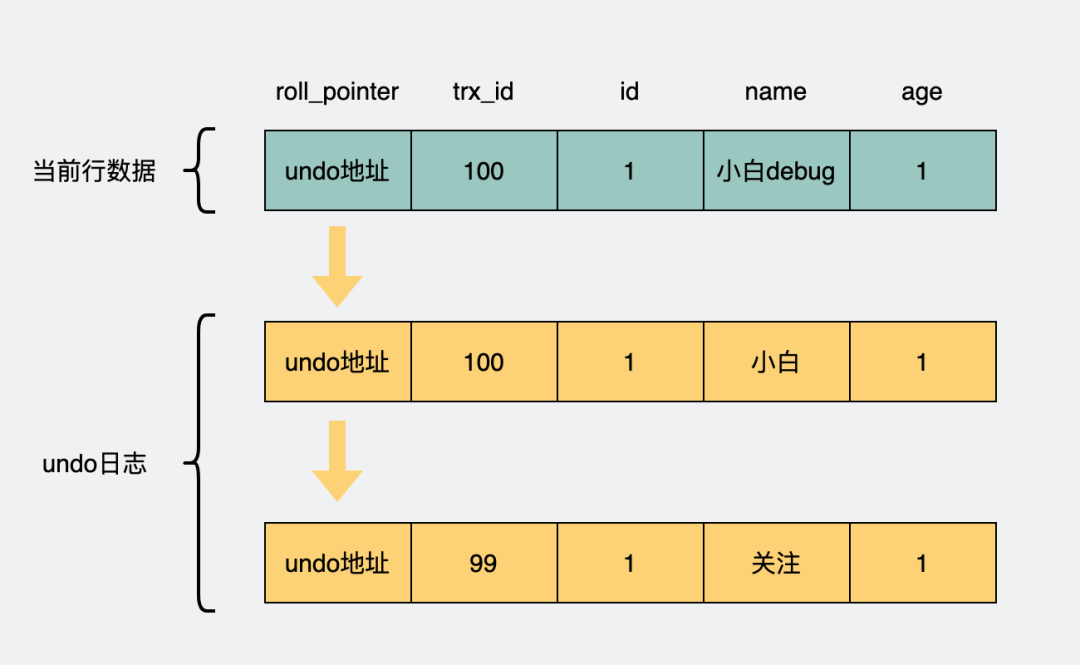
 undo日志版本链
undo日志版本链
有了这个版本链,当某个事务执行到一半发现失败时,就直接回滚,这时候就可以顺着这个版本链,回到执行事务前的状态。
当前读和快照读是什么
有了上面的undo日志版本链之后,我们可以看到最新的数据在表头,在这之后的都是一个个旧的数据版本。不管是最新的,还是旧的数据版本,我们都叫它数据快照。
当前读,读的就是版本链的表头,也就是最新的数据。
快照读,读的就是版本链里的其中一个快照,当然如果这个快照正好就是表头,那此时快照读和当前读的结果一样。

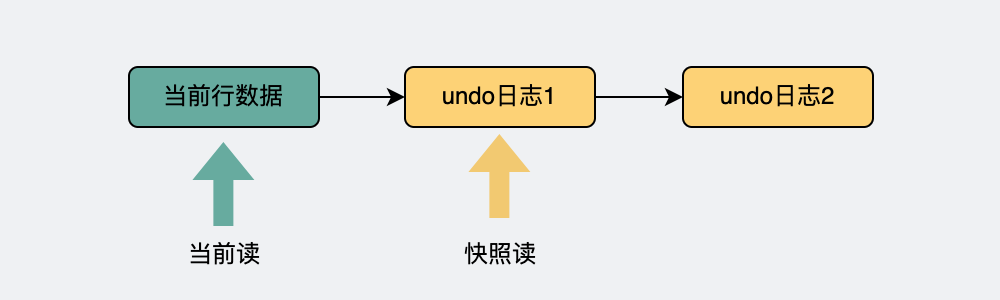
当前读和快照读
我们平时执行的普通select语句,比如下面这种,就是快照读。
select * from user where phone_no=2;
而特殊的select语句,比如在select后面加上lock in share mode或for update,都属于当前读。
除此之外insert,update,delete操作都属于写操作,既然写,那必然是写最新的数据,所以都会引发当前读。
那么问题来了。
当前读,读的是版本链的表头,那么执行当前读的时候,有没有可能恰好有其他事务,生成更加新的快照,替代当前表头,成为新的表头呢,那这时候岂不是读的不是最新数据了?
答案是不会,不管是select … for update这些(特殊的)读操作,还是insert、update这些写操作,都会对这行数据加锁。而生成undo日志快照,也是在写操作的情况下生成的,执行写操作前也需要获得锁。所以写操作需要阻塞等待当前读完成后,获得锁后才能更新版本链。
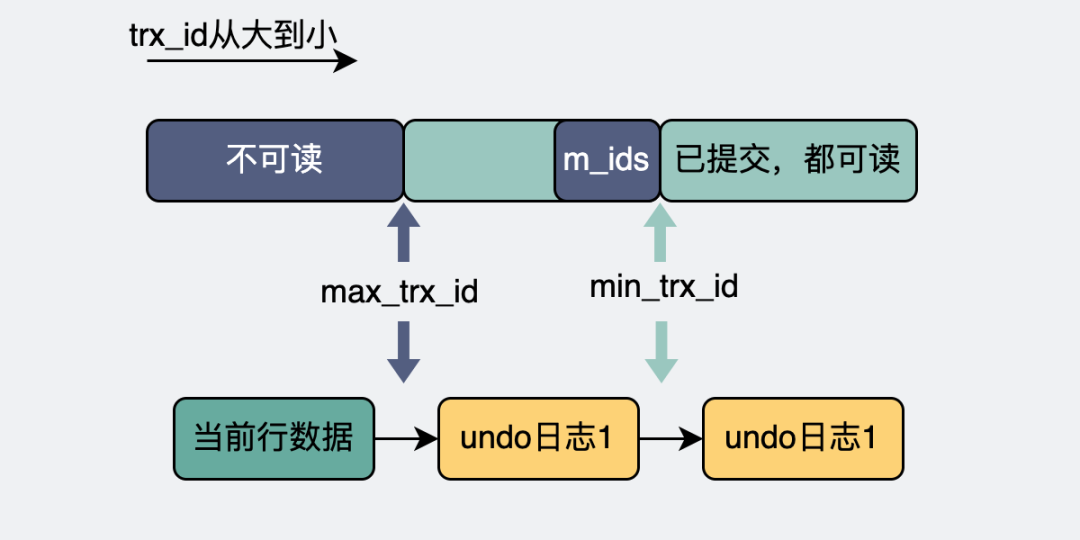
read view
数据库里可以同时并发执行非常多的事务, 每个事务都会被分配一个事务ID, 这个 ID 是递增的,越新的事务,ID 越大。
而数据表里某行数据的undo日志版本链,每个undo日志上面也有一个事务id (trx_id),它是创建这个undo日志的事务id。
并不是所有事务都会生成undo日志,也就是说某行数据的undo日志版本链上只有部分事务的id。但是,所有事务都有可能会访问这行数据对应的版本链。而且版本链上虽然有很多undo日志快照,但也不是所有undo日志都能被读,毕竟有些undo日志,创建它们的事务还没提交呢,人家随时可能失败并回滚。
现在的问题就成了,现在有一个事务,通过快照读的方式去读undo日志版本链,那它能读哪些快照?并且它应该读哪个快照?
这里就要引入一个read view的概念。它就像是一个有上下边界的滑动窗口。
整个数据库里有那么多事务,这些事务分为已经提交(commit)的,和没提交的。没提交的,意味着这些事务还在进行中,也就是所谓的活跃事务。所有的活跃事务的id,组成m_ids。而这其中最小的事务id就是read view的下边界,叫min_trx_id。
产生read view的那一刻,所有事务里最大的事务id,加个1,就是这个read view的上边界,叫max_trx_id。
概念太多,有点乱?没事的,继续往下看,后面会有例子的。
事务能读哪些快照
有了这些基础信息之后,我们先看下事务在read view下,他能读哪些快照呢?
记住一个大前提:事务只能读到自己产生的undo日志数据(事务提不提交都行),或者是其他事务已经提交完成的数据。
现在事务(假设就叫事务A吧)有了read view之后,不管看哪个undo日志版本链,我们都可以把read view往版本链上一放。版本链就被分成了好几部分。

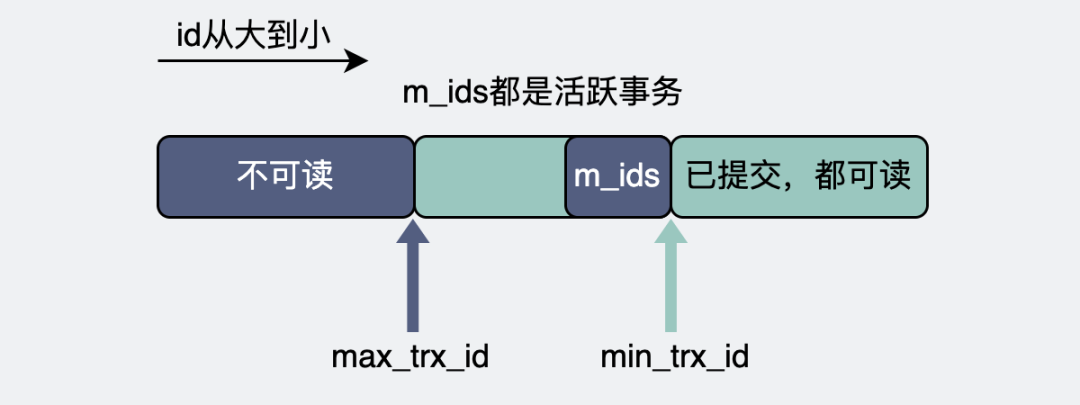
readview
- 版本链快照的trx_id < read view的min_trx_id。
从上面的描述中,我们可以知道read view的m_ids来源于数据库所有活跃事务的id,而最小的min_trx_id就是read view的下边界,因为事务id是根据时间递增的,所以如果版本链快照的trx_id比 min_trx_id 还要小,那这些肯定都是非活跃(已经提交)的事务id,这些快照都能被事务A读到。
- 版本链快照的trx_id >= read view的max_trx_id。
max_trx_id是在事务A创建read view的那一刻产生的,它比那时候所有数据库已知的事务id都还要大。所以如果undo日志版本链上的某个快照上含有比 max_trx_id 还要大的 trx_id,那说明这个快照已经超出事务A的"理解范围了",它不该被读到。
- read view的min_trx_id <= 版本链快照的trx_id < read view的max_trx_id。
- 如果版本链快照的trx_id正好就是事务A的id,那正好是它自己生成的undo日志快照,那不管有没有提交,都能读。
- 如果版本链快照的trx_id正好在活跃事务m_ids中, 那这些事务数据都还没提交,所以事务A不能读到它们。
- 除了上面两种情况外,剩下的都是已经提交的事务数据,可以放心读。
事务会读哪个快照
上面提到,事务在read view的可见范围里,有机会能读到N多快照。但那么多快照版本,事务具体会读哪个快照呢?
事务会从表头开始遍历这个undo日志版本链,它会拿每个undo日志里的trx_id去跟自己的read view的上下边界去做判断。第一个出现的小于max_trx_id的快照。
- 如果快照是自己产生,那提不提交都行,就决定是读它了。
- 如果快照是别人产生的,且已经提交完成了,那也行,决定读它了。
比如下图,undo日志1正好小于max_trx_id,且事务已经提交,那么就读它了。
readview与undo版本链
MVCC是什么
像上面这种,维护一个多快照的undo日志版本链,事务根据自己的read view去决定具体读那个undo日志快照,最理想的情况下是每个事务都读自己的一份快照,然后在这个快照上做自己的逻辑,只有在写数据的时候,才去操作最新的行数据,这样读和写就被分开了,比起单行数据没有快照的方式,它能更好的解决读写冲突,所以数据库并发性能也更好。其实这就是面试里常问的MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。

MVCC
四个隔离级别是怎么实现的
之前的写的一篇文章最后留了个问题,四个隔离级别是怎么实现的。
知道了undo日志版本链和MVCC之后,我们再回过头来看下这个问题。
 四层隔离级别
四层隔离级别
读未提交,每次读到的都是最新的数据,也不管数据行所在的事务是否提交。实现也很简单,只需要每次都读undo日志版本链的链表头(最新的快照)就行了。
与读未提交不同,读提交和可重复读隔离级别都是基于MVCC的read view实现的,反过来说, MVCC也只会出现在这两个隔离级别里。
读已提交隔离级别,每次执行普通select,都会重新生成一个新的read view,然后拿着这个最新的read view到某行数据的版本链上挨个遍历,找到第一个合适的数据。这样就能做到每次都读到其他事务最新已提交的数据。
可重复读隔离级别下的事务只会在第一次执行普通select时生成read view,后续不管执行几次普通select,都会复用这个 read view。这样就能保持每次读的时候都是在同一标准下进行读取,那读到的数据也会是一样的。
串行化目的就是让并发事务看起来就像单线程执行一样,那实现也很简单,和读未提交隔离级别一样,串行化隔离界别下事务只读undo日志链的链表头,也就是最新版本的快照,并且就算是普通select,也会在版本链的最新快照上加入读锁。这样其他事务想写,也得等这个读锁释放掉才行。所有对这行数据进行操作的事务,都老老实实地阻塞等待加锁,一个接一个进行处理,从效果上看就跟单线程处理一样。
再看文章开头的例子
我们用上面提到的概念,重新回到文章开头的例子,梳理一遍。
user表数据库原始状态
我们假设数据库一开始的三条数据,都是由trx_id=1的事务insert生成的。
于是数据表一开始长下面这样。每行数据只有一个快照。注意快照里,trx_id填的是创建它们的事务id,也就是刚刚提到的事务1。roll_pointer原本应该指向insert产生的undo日志,为了简化,这里写为null(insert undo日志在事务提交后可以被清理掉)。
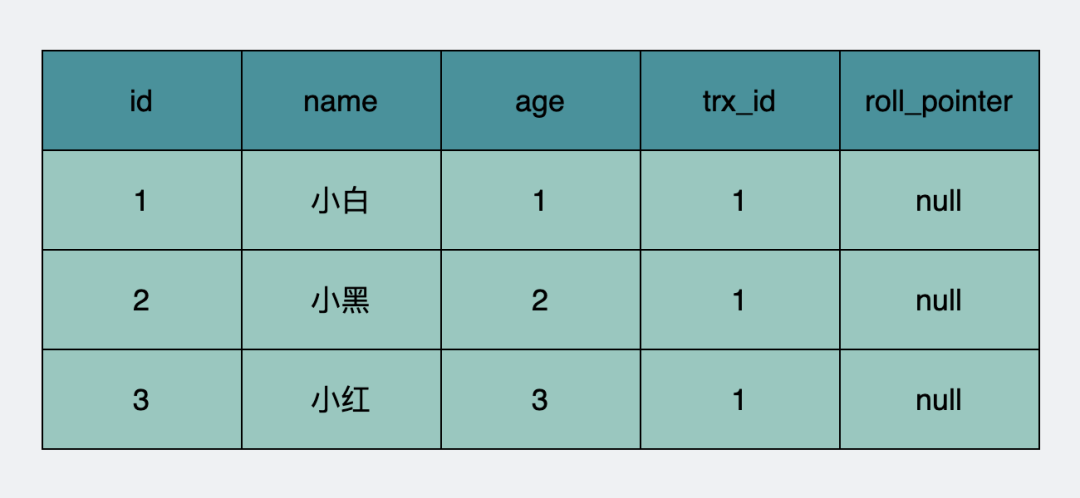
user表数据库原始trx信息
下面这个图,还是文章开头的图,这里放出来是为了方便大家,不用划回去看了。
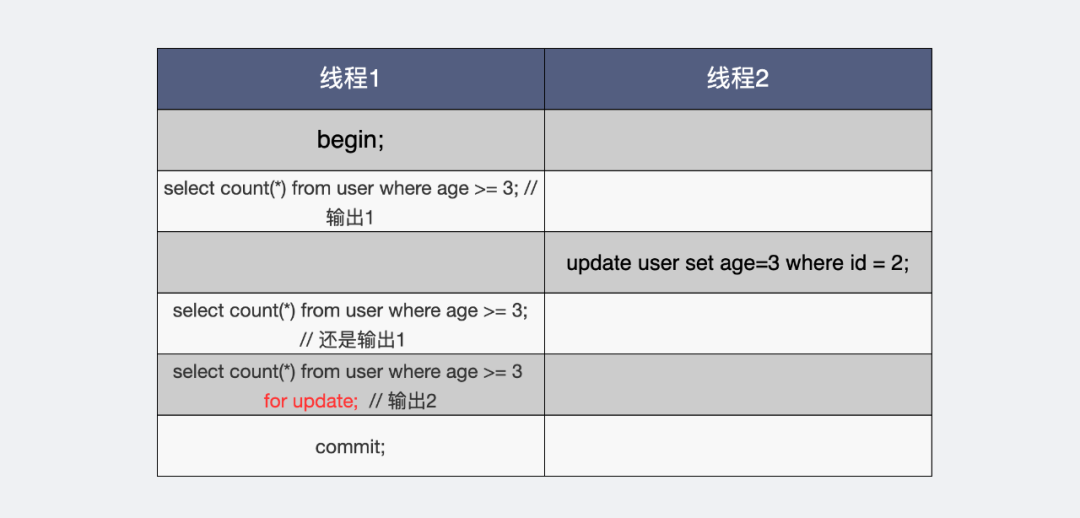
都是select结果却不同
在线程1启动事务,我们假设它的事务trx_id=2,第一次执行普通select,是快照读,在可重复读隔离级别,会生成一个read view。当前这个数据库,活跃事务只有它一个,那m_ids =[2]。m_ids里最小的id,也就是min_trx_id=2。max_trx_id是当前最大数据库事务id(只有它自己,所以也是2),加个1,也就是max_trx_id=3。
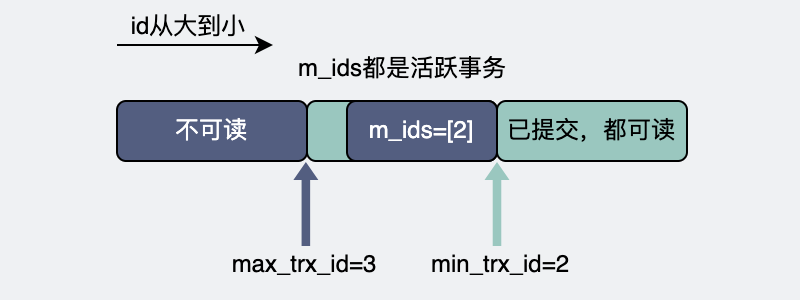
 事务1的readview
事务1的readview
此时线程1的事务,拿着这个read view去读数据库表。
因为这三条数据的trx_id=1都小于min_trx_id=2,都属于可见范围,因此能读到这三条数据的所有快照,最后返回符合条件(age>=3)的数据,有1条。
这时候事务2,假设它的事务trx_id=3,执行更新操作,生成新的undo日志快照。
 user表数据库加入undo日志
user表数据库加入undo日志
此时线程1第二次执行普通select,还是快照读,由于是可重复读,会复用之前的read view,再执行一次读操作,这里重点关注id=2的那行数据,从版本链表头开始遍历,第一个快照trx_id=3 >= read view的max_trx_id=3,因此不可读,遍历下一个快照trx_id=1 < min_trx_id=2,可读。于是id=2的那行数据,还是拿到age=2,而不是更新后的age=3,因此快照读结果还是只有1条数据符合age>=3。
但是线程1第三次读,执行select for update,就成了当前读了,直接读undo日志版本链里最新的那行快照,于是能读到id=2,age=3,所以最终结果返回符合age>=3的数据有2条。
总的来说就是,由于快照读和当前读,读数据的规则不同,我们看到了不一样的结果。
看到这里,大家应该理解了,所谓的可重复读每次读都要读到一样的数据,这里头的"读",指的是快照读。
如果下次面试官问你,可重复读隔离级别下每次读到的数据都是一样的吗?
你该知道怎么回答了吧?
总结
- 事务通过undo日志实现回滚的功能,从而实现事务的原子性(Atomicity)。
- 多个事务生成的undo日志构成一条版本链。快照读时事务根据read view来决定具体读哪个快照。当前读时事务直接读最新的快照版本。
- mysql的innodb引擎通过MVCC提升了读写并发。