












引言
无论何时何地,我们都可以了解到服务器的性能,这归功于作为运维之眼的监控系统。G行监控系统使用的监控工具有多种,Nagios作为老牌监控工具,凭借其灵活的配置功能和强大的管理中心在G行发挥着重要作用。本文从功能、系统监控原理和在G行的应用等方面介绍Nagios监控工具。
一、Nagios功能
1.主机或服务状态监控
Nagios可以监控的服务器操作系统主要包含Linux、Unix和Windows等,可监控的网络设备有路由器、交换机等,支持对http、tcp、pop3、smtp等各种应用协议进行外部可用性探测。
2.监控告警通知
Nagios对发现的问题会及时产生告警信息,并通过事先定义好的方式,如:邮件、短信、微信等方式通知相关人员。同时,Nagios还支持利用客户化程序和调用API来进行告警通知,以便用户更好的发现问题,并进行自动化处理。
3.监控信息可视化
Nagios结合web服务器,可以将其监控的所有信息以web页面的形式展现出来,还可以进一步结合外部软件实现监控数据可视化分析,以图表的形式展示在web页面中,下图为Nagios web页面展示。
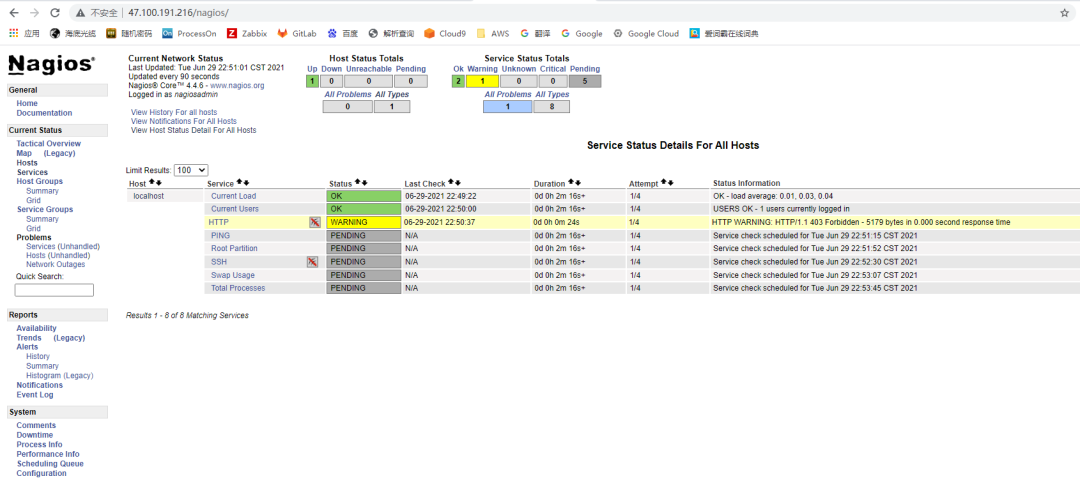
图1 Nagios web页面展示
4.监控数据存储
Nagios监控采集到的数据会存储下来,可以通过NDOUtis组件存储到数据库中实现历史监控信息的查询。
二、Nagios系统监控原理
Nagios是一种C/S方式的监控工具,系统中的角色可以分为:
(1)Nagios服务器:安装核心模块,负责监控的处理、任务调度、下发指令和web展示。
(2)被监控主机:安装代理模块,执行具体的监控指令、返回监控的结果。
Nagios服务器向代理模块发送请求,代理模块调用各个插件获取具体资源的状态信息,然后返回给Nagios服务器,最后对收集到的信息进行分析,并通过web应用进行展示。
Nagios系统主要包含Nagios daemon、Nagios plugin、nrpe三个组件,它还包含NSCA、NSClinet++、NDOUtils组件,组成逻辑图如下所示:
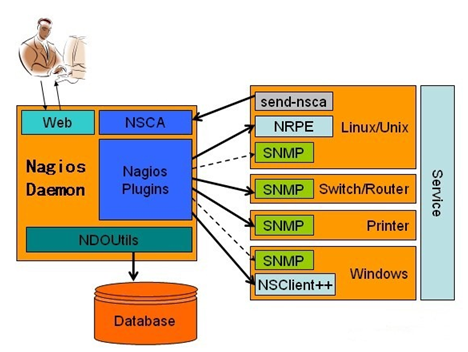
图2 Nagios逻辑结构图
Nagios daemon:Nagios系统的核心组件,它负责组织与管理各组件,将它们协调起来共同完成监控任务,并完成监控信息的组织与展示。
Nagios plugin:Nagios核心组件自带以及用户自开发的一些插件,它们是实现各项监控的具体小程序,由它们采集到相应的数据以后,回送给Nagios服务器。
NRPE:Nagios系统要想取得被监控主机的存活状态以及http、ftp、ssh等公开服务可用,可以通过程序探测得出。如果要想取得被监控主机上如磁盘容量、CPU负载等本地信息时,就需要代理程序,Linux系统是nrpe,Windows是NSClient++,通过代理程序来获取监控数据,再发送到Nagios服务器。
三、插件介绍及应用
Nagios核心模块只支持少量的监控功能,大部分监控功能都是通过各种插件来完成的。监控插件获取监控数据的方式可以分为两种:主动监控和被动监控。二者的区别在于,主动检测是由Nagios执行查询命令,而被动监控是由外部程序(代理)将检测结果推送给Nagios服务器。
主动监控:Nagios监控服务器定期主动到被监控端获取数据。主动监控又分为需要在被监控端安装agent和不需要安装agent两种。
- 需要安装agent:windows平台下是NSClient++,linux下是nrpe。
- 不需要安装agent:开启被监控端的snmp,或者通过其他网络协议进行监控。
被动监控:被监控端是将自身监控数据发往Nagios的方式,又可以分为以下两种:
- 被监控端通过安装nsca,定期检查本机监控项目,并将告警数据发往Nagios服务器。
- 被监控端配置snmp trap,将相应的trap信息发往Nagios服务器。
目前Nagios在G行主要承担外部探测功能,从Service端主动发动监控检查。
Nagios大部分的监控功能都是通过插件来实现的,以下简单介绍一些我们现在使用的Nagios插件。
(1)Nagios plugins,是个软件包,里面包含众多的插件,我们现在使用的包括:check_nt 用于监控Windows系统的负载、内存使用、磁盘使用、系统运行时间、某进程运行情况。在Nagios服务器上使用此插件,需要在被监控的Windows系统上安装agent——NSClient++ 。
监控系统负载
check_nt -H $HOSTNAME$ -p 12489-v CPULOAD –l 5,80,90
监控系统内存使用
check_nt -H $HOSTNAME$ -p 12489-v MEMUSE –w 80 –c 90
监控系统磁盘使用
check_nt -H $HOSTNAME$ -p 12489-v USEDDISKSPACE -l d -c 80
监控系统运行时间
check_nt -H $HOSTNAME$ -p 12489-v UPTIME
监控系统进程
check_nt -H $HOSTNAME$ -p 12489-v PROCSTATE -d SHOWALL -l explorer.exe
-H :指定被监控IP -p:是NSClient++默认开启端口 -v:要监控的项目
-w: wanring阈值 -c:critical阈值 -l:附加参数
(2)check_nrpe,nrpe软件包包含了check_nrpe命令,使用这个命令来获取被监控数据,它的工作方式是:通过被监控端上的nrpe配置文件来定义监控命令(这些命令可以是Nagios plugins中的,也可以是自己开发的监控脚本),然后从Nagios服务器上通过check_nrpe调用这些已定义的监控命令,返回监控数据。
监控系统负载
在被监控的linux端,安装nrpe和Nagios plugin,通过更改nrpe.conf文件,我们定义命令:
command[check_load]=/usr/local/Nagios/libexec/check_load-w 15,10,5 -c 30,25,20
注:check_load包含在Nagiosplugins中,只能运行在linux上。-w是warning阈值,-c是critical阈值,三个值分别对应这系统1分钟、5分钟、15分钟的负载阈值。
(3)check_ping,用于检查主机存活,可以简单的理解为ping。
监控系统网络情况
check_ping –H $HOSTNAME$ -w100.0,20% -c 500.0,60%
-w:warning阈值,100代表延迟时间,20%代表丢包率
-c:critical阈值,500代表延迟时间,60%代表丢包率。
当ping的情况无论是达到延迟时间的阈值还是丢包率的阈值,都会报警。
(4)check_tcp,检查tcp连接相应时间。
check_tcp –H $HOSTNAME$ -p 7001-w 0.05 -c 0.1
-p:指定tcp服务端口 -w:相应时间warning阈值 -c:相应时间critical阈值
(5)SNMP– Linux:通过snmp的方式监控,不需要被监控端安装agent,只需要被监控操作系统或者被监控应用系统开启并配置snmp服务即可。Nagios服务器通过snmpwalk命令连接并获取远端的系统信息。
监控linux磁盘
snmp_linux_disk_check.sh -H HOST-C community -w warning -c critical [-d disk]
-H指定被监控主机IP。-C团体字。-w磁盘使用率告警阈值-c磁盘使用率criticla告警阈值-d是可选项,指定磁盘挂载点,如省略则检测主机上所有挂载点。
监控linux CPU
snmp_linux_cpu_check.sh -H HOST-C community -w warning -c critical
-H,-C参数意义同上-w是cpu使用率告警阈值-c是cpu使用率critical告警阈值
监控linux内存
snmp_linux_mem_check_v1.sh -HHOST -C community -w warning -c critical
-H,-C意义同上-w是内存使用率告警阈值 -c是内存使用率critical告警阈值
四、在G行的应用
Nagios在G行主要承担外部探测功能,从Service端主动发动监控检查。目前监控对象包括操作系统、数据库、应用(端口、页面、日志等)、专用设备等。
Nagios监控架构如下:
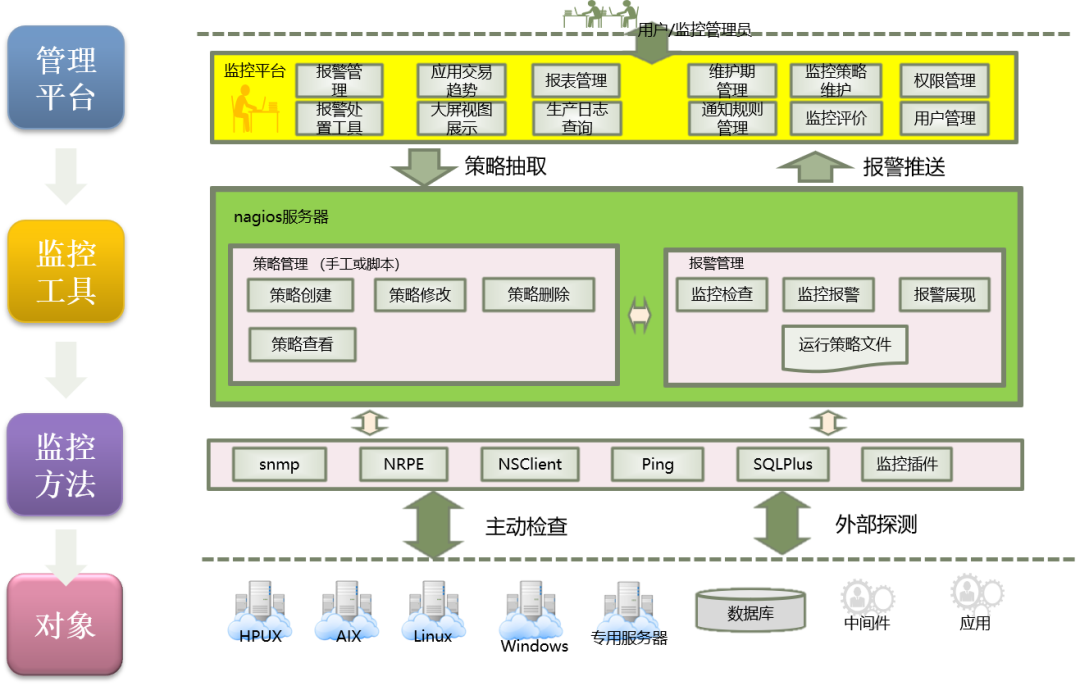
图3 Nagios在G行的监控架构
五、总结与展望
Nagios是一款轻量级的开源监控软件,它可以有效的监控Linux、Windows类等的主机和网络设备,可以自定义监控脚本,同时具有部署简单、告警方式灵活、可监控多种协议等优点。目前行业中常用监控软件还有Zabbix、Prometheus等,它们分别有支持分布式监控和容器监控等优点,这两种监控工具也在G行有应用,共同支撑着G行的监控系统,并在监控自服务和监控标准等方面继续优化。














