1.前言
为了尽量减少自然和人为灾难(如停电、灾难性软件故障和网络中断)对业务的影响,以及随着我行基于Kafka的实时业务不断增长,Kafka的重要性日益增长,在我行逐步优化跨IDC的Kafka连续性建设已经成为我们目前亟待解决的问题。
本文就目前已有的灾备方案在元数据同步、数据复制、消费位移同步、灾备模式等方面进行调研对比。
2.现有灾备方案
方案 | 描述 | 使用方 |
MirrorMaker1(简称MM1) | 原理是启动消费者从源集群进行消费,然后发送到目标集群,功能较简单 | |
MirrorMaker2(简称MM2)或 基于MM2的改进 | 基于Kafka Connect框架实现,由LinkedIn工程师贡献,修复MM1的局限性,Topic和分区可自动感知,acl和配置可自动同步,支持双活,提供offset转换功能 | 360 |
Confluent Replicator | Confluent收费版,与MM2相比,双活模式更优雅,可支持单条消息的修改 | Confluent |
基于Follower的同步机制 | 利用Kafka的副本同步机制创建Fetcher线程同步数据,需要在原生Kafka上进行二次开发 | 字节、滴滴 |
uReplicator | 改进MM1,利用分布式的任务管理框架Apache Helix控制Partition的分配,不需要全部rebalance | Uber |
brooklin | 改进MM1,实现思路和MM2类似,与uReplicator一样,为了减少rebalance,采用Sticky Assignment控制Partition的分配,除了支持Kafka集群间的复制,还能作为Azure Event Hubs,AWS Kinesis流式服务之间的通道,另外还能作为CDC连接器 |
3.各方案的主要设计点对比分析
3.1 元数据同步
元数据同步主要是指Topic、Partition、Configuration、ACL的同步,我们需要评估各方案在新增Topic,分区扩容后、修改Configuration和ACL后能否自动感知,以及评估方案中选择复制的Topic是否灵活(比如是否支持白名单、黑名单机制,是否支持正则),目标集群中Topic名称是否发生改变(决定是否支持双向复制,是否会发生循环复制)。
MM1方案中,选择复制的Topic只支持白名单机制(--whitelist或者--include参数指定),且白名单支持正则写法,但是当源集群新增Topic后,目标集群的auto.create.topics.enable设置为true时,才能自动在目标集群创建相同名称的Topic(可以扩展messagehandler改名),否则必须重启MirrorMaker才能发现新增的Topic,关于目标集群上的Topic的分区数,MM1是按默认值num.partitions进行配置(其他方案均无该问题),无法和源集群上保持一致,ACL也无法同步。
相比MM1,MM2弥补了上述不足,主要是依赖MirrorSourceConnector里的多个定时任务实现该功能,更新Topic/Partition、Configuration、ACL的间隔时长分别由三个参数指定,非常灵活。在MM2中,目前截至3.0.0的版本,支持两种复制策略,默认的DefaultReplicationPolicy中目标集群中复制后Topic名称发生变化,前面会加一个源集群的前缀,为了兼容MM1,3.0.0中新增的IdentityReplicationPolicy中目标集群中复制后Topic名称不会发生变化。
Confluent Replicator,根据官网描述,也同样具备上述功能,原理和MM2类似,只是检测更新只由一个参数确定。Replicator可以定义复制后Topic的名称,由参数topic.rename.format指定,默认值是保持Topic名称不变。
基于Follower的同步机制的方案,由于网上资料不足,具体实现无法得知,但是原理估计和MM2类似,复制后在目标集群中Topic名称保持不变。
uReplicator的实现略有不同,复制哪些Topic,由参数enableAutoWhitelist和patternToExcludeTopics一起决定,当enableAutoWhitelist设置为true时,若源集群和目标集群中存在相同Topic,那么不需要其他设置即可实现数据复制,若设置为false,需要将复制的Topic名称等信息提交给uReplicator Controller,由该Controller来控制分区的分配,另外黑名单参数patternToExcludeTopics控制哪些Topic不用复制;分区扩容是否自动感知,是由参数enableAutoTopicExpansion控制的;关于Configuration和ACL无法实现同步。
brooklin选择复制的Topic只支持白名单机制,可支持正则,新增Topic和分区扩容后可自动感知,检测更新由参数partitionFetchIntervalMs确定,复制后Topic名称前可加前缀,由参数DESTINATION_TOPIC_PFEFIX确定。
总结如下:
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步机制 | uReplicator | brooklin |
复制后Topic名称变化 | 不变,也可自定义 | 可保持不变,也可以增加固定前缀 | 可保持不变,也可以自定义 | 不变 | 不变 | 可保持不变,也可定义前缀 |
自动检测和复制新Topic | 部分支持(取决于目标集群的自动创建topic是否开启) | 支持 | 支持 | 取决于二次开发的功能 | 不支持 | 支持 |
自动检测和复制新分区 | 不支持 | 支持 | 支持 | 取决于二次开发的功能 | 支持 | 支持 |
源集群和目标集群总Topic配置一致 | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
配置和ACL更新是否同步 | 不支持 | 支持 | 支持 | 取决于二次开发的功能 | 不支持 | 不支持 |
选择复制Topic的灵活度:是否具有白名单、黑名单和正则表达式的主题 | 部分支持 | 支持 | 支持 | 取决于二次开发的功能 | 部分支持 | 部分支持 |
3.2 数据复制
数据复制是灾备方案的最核心点之一,我们需要评估各方案中复制后消息offset能否对齐,复制期间数据的一致性能否保证即是否会丢失数据或者会出现重复数据。首先说明一下,由于复制会有延迟,因此所有这些灾备方案里RPO都不等于0。
基于Follower的同步机制的方案可以保持offset对齐,由于副本同步存在延迟,当主机房异常时,备机房上仍有丢失部分数据的可能性,offset可保持一致,不会出现重复数据的可能性。其他方案均不能保证offset对齐(除非是复制时源Topic的offset从0开始),关于每个方案中消费者从源集群消费,再写入到目标集群的逻辑,我们一一详细解释下:
先从MM1开始,这是他的设计架构:
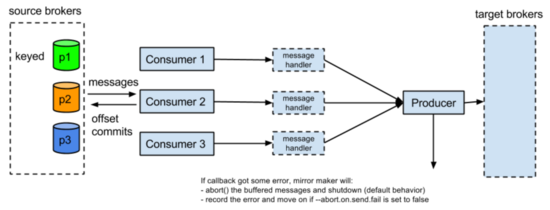
在KIP-3 MirrorMaker Enhancement里,设计了上述架构,从以下几处保证不丢数:
1.关掉消费者的自动提交位移,提交位移之前会调用producer.flush()刷出缓存里数据
2.在producer端,通过设置这几个参数max.in.flight.requests.per.connection=1(多个consumer共享一个producer,这个producer每次只给broker发一个request),retries=Int.MaxValue(返回是可重试异常,无限次重试直到缓冲区满),ack=-1(发给所有副本)
3.设置abortOnSendFail,当producer端收到不可重试异常后(比如消息过大之类的异常),停止MirrorMaker进程,否则会丢失发送失败的部分数据
另外为了避免在consumer发生rebalance的是时候出现重复数据(rebalance时候有些数据位移没提交),定义了一个新的consumerRebalance监听器,在发生partitionRevoke的时候,先刷出producer缓存里数据,再提交位移。
从上面设计来看,MM1是不丢数,但是还是存在数据重复的可能性,这是Kafka的非幂等Producer决定的,另外MM1的设计还有很多缺陷,比如只有一个Producer,发送效率低,另外这个Producer是轮询发送,消息发送到目的Topic上的分区和源Topic的分区不一定一致,由于是轮询,这个Producer和集群里每个broker会建立连接。对比uReplicator,同样也是在flush之后再提交位移去避免丢数,在MM1的缺陷都得到了改进,每个WorkerInstance里有多个FetcherThread和多个ProducerThread,从源集群fetch数据后会放到一个队列里,ProducerThread从队列里取走数据并发到目标集群的Topic,每条消息发送到目的Topic上分区和源分区保持一致,可以保持语义上一致。
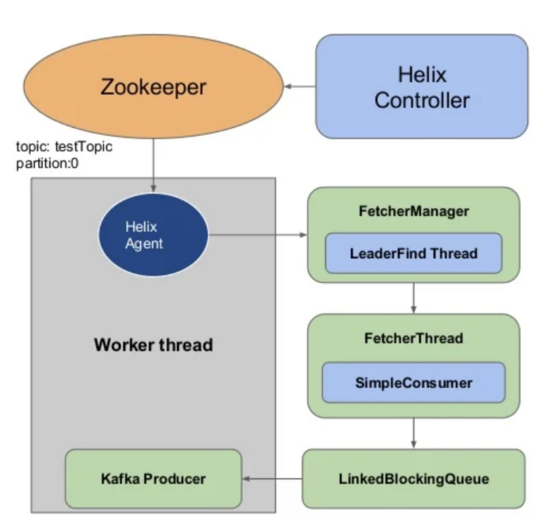
在brooklin中,每个Brooklin Instance中可以起多个Consumer和Producer,也可保持语义上一致,比uReplicator更有优势的一处就是提供了flushless的生产者(也可提供flush的Producer),哪些消息发送成功,才会提交这些位移,因为调用Producer.flush()可以将缓冲区的数据强制发送,但是代价较高,在清空缓冲前会堵塞发送线程。
consumer.poll()->producer.send(records)->producer.flush()->consumer.commit()
优化为:
consumer.poll()->producer.send(records)->consumer.commit(offsets)
在MirrorMaker2中,采用Kafka Connect框架进行复制数据,从源端消费数据后,存到一个类型为IdentityHashMap的内存结构outstandingMessages中,Producer发送到目的端成功后,会从该内存结构中删除该消息,另外会定时将从源端消费的进度保存到Kafka Topic中。这种实现机制不会丢失数据,但是Producer发送成功后,未将进度持久化前进程异常挂掉,那么会产生重复消息。目前在KIP-656: MirrorMaker2 Exactly-once Semantics提出了一种可实现Exactly Only Once的方案,思路是将提交消费位移和发送消息放在一个事务里,但是相关Patch KAFKA-10339仍然没被合进主分支,最后更新停留在20年8月份。
根据Confluent Replicator官网描述,复制不会丢数,但是可能会重复,因此和上述MM2、uReplicator、brooklin一样,提供的都是At least Once Delivery消息传递语义。
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步机制 | uReplicator | brooklin |
复制前后分区语义一致 | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
offset对齐 | 不能 | 不支持 | 不支持 | 支持 | 不支持 | 不支持 |
消息传递语义 | 不丢数,可能重复 At least Once | 不丢数,可能重复 At least Once, 未来会提供EOS语义 | 不丢数,可能重复 At least Once | 取决于二次开发的功能, 从Kafka副本同步的原理看, 在参数设置合理的情况下,在副本之间同步过程中数据可保持一致 | 不丢数,可能重复 At least Once | 不丢数,可能重复 At least Once |
3.3 消费位移同步
灾备方案中除数据复制,消费位移的同步也非常关键,灾备切换后消费者是否能在新的集群中恢复消费,取决于consumer offset是否能同步。
在MM1设计中,若要同步消费位移,只能将__consumer_offsets作为一个普通的Topic进行同步,但是由于源集群和目标集群的offset可能存在不对齐的情况,因此无法进行offset转换。
在MM2设计中,解决了上述MM1问题,设计思路是会定期在目标集群的checkpoint Topic中记录消费位移,包括源端和目标端的已提交位移,消息包括如下字段:
- consumer group id (String) 消费组
- topic (String) – includes source cluster prefix topic名称
- partition (int) 分区名称
- upstream offset (int): latest committed offset in source cluster 源集群的消费位移
- downstream offset (int): latest committed offset translated to target cluster 目标集群的消费位移
- metadata (String) partition元数据
- timestamp
另外,还设计了一个offset sync Topic用于记录源端和目的端offset的映射。
同时,MM2还提供了MirrorClient接口做位移转换:
// Find the local offsets corresponding to the latest checkpoint from a specific upstream consumer group.
Map<TopicPartition, OffsetAndMetadata> remoteConsumerOffsets(String consumerGroupId,
``String remoteClusterAlias, Duration timeout)
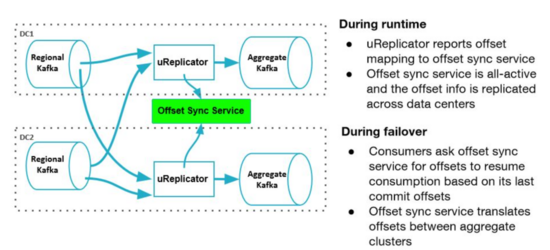
在uReplicator中,另外设计了一个offset Sync的服务,跟MM2类似(可能是MM2参考了uReplicator的设计),这个服务可以实时收集不同集群offset 的映射关系,计算出从一个DC切换到另一个DC后需要从哪个 offset 进行读取。
在brooklin中,没有类似uReplicator里的offset Sync服务,需要自己实现。
在Confluent Replicator中,用另外一种思路解决该问题,不同DC的时间是一致的,在Kafka的消息里包含时间戳,5.0 版引入了一项新功能,该功能使用时间戳自动转换偏移量,以便消费者可以故障转移到不同的数据中心并开始在目标集群中消费他们在源集群中中断的数据。要使用此功能,需要在Consumer中设置Consumer Timestamps Interceptor 的拦截器,该拦截器保留消费消息的元数据,包括:
• Consumer group ID
• Topic name
• Partition
• Committed offset
• Timestamp
此消费者时间戳信息保存在位于源集群中名为 __consumer_timestamps 的 Kafka Topic中。然后Replicator通过以下步骤进行offset转换:
- 从源集群中的 consumer_timestamps 主题中读取消费者偏移量和时间戳信息,以获取消费者组的进度
- 将源数据中心中的已提交偏移量转换为目标数据中心中的相应偏移量
- 将转换后的偏移量写入目标集群中的 __consumer_offsets 主题
那么消费者切换到目标中心的集群后,可继续进行消费。
基于Follower的同步机制方案,Topic完全一致,只要将__consumer_offsets也同步,那么消费者故障转移后仍可继续消费。
在消费位移同步方面,各方案总结如下:
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步机制 | uReplicator | brooklin |
复制消费位移 | 部分支持 | 支持 | 支持 | 支持 | 部分支持 | 部分支持 |
offset转换 | 不支持 | 支持 | 支持 | 不需要 | 支持 | 不支持 |
客户端切换 | 客户端自定义 seek offset | 通过接口获取目标集群 的offset,再seek | 不需要做额外转换, 启动即可 | 不需要做额外转换, 启动即可 | 通过sync topic服务 查看目标集群的offset,再seek | 客户端自定义 seek offset |
3.4 是否支持双活
为了提升资源利用率,灾备模式的选取也是一个重要考量点。
MM1是不支持双活模式的,两个集群无法配置为相互复制(“Active/Active”),主要是因为如果在两个集群中若存在相同名称的Topic,无法解决Topic循环复制的问题。
MM1这个可能循环复制的问题在MM2中解决,解决思路是复制后的Topic与原Topic名称不一致,会加上源集群的名称作为前缀,例如如下示例中,A集群中的topic1在复制到B集群后,名称变更为A.topic1。
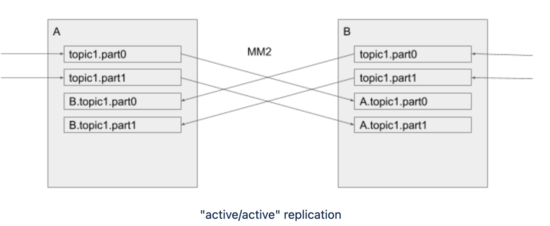
但是MM2默认的DefaultReplicationPolicy是复制后Topic名称改变,对客户端来说会增加切换代价,可以考虑改成IdentityReplicationPolicy,这种复制策略只能支持单向复制,主集群提供业务服务,即Active/Standy模式。
在Confluent Replicator 5.0.1中,为了避免循环复制,利用了KIP-82 Add Record Headers的特性,在消息的header里加入了消息来源,如果目标集群的集群 ID 与header里的源集群 ID 匹配,并且目标Topic名称与header的Topic名称匹配,则 Replicator 不会将消息复制到目标集群。如下图所示:
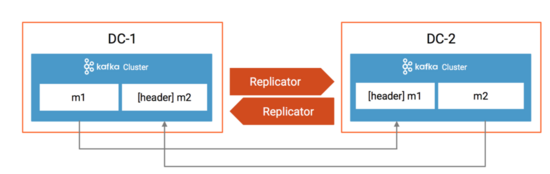
DC-1的m1复制后DC-2,消息的header里加入了标记,这条消息是从DC-1复制过来的,那么Replicator不会把DC-2的m1再复制到DC-1,同理,DC-1的m2也不会复制到DC-2。因此Confluent Replicator是可以支持Active/Active模式的。
在uReplicator中,通过数据的冗余提供Region级别的故障转移,在这种设计中,每个区域除部署一套本地Kafka集群,还会部署一套聚合集群,这套聚合集群里存储了所有区域的数据。
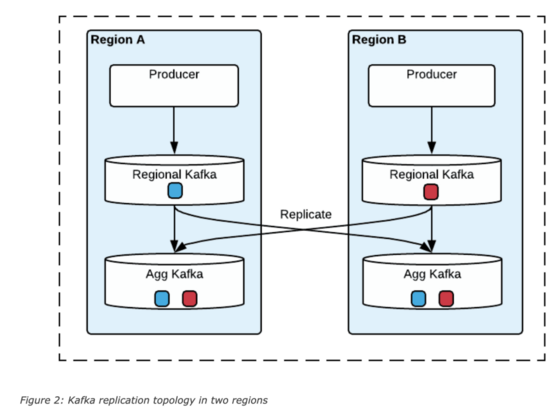
当区域集群A和B中存在相同Topic,那么汇聚后,在区域A和B中的消息offset可能不一致,uReplicator设计了一个offset管理服务,会记录这个对应关系,示例如下:
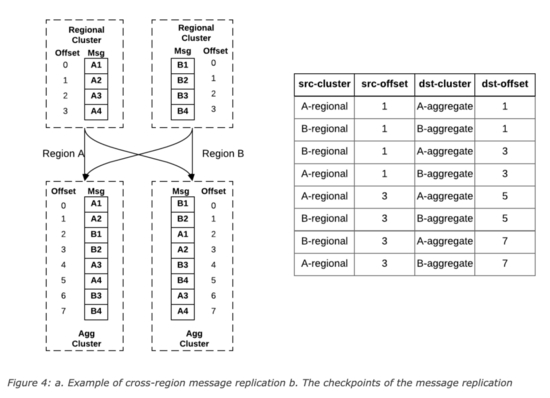
这种设计中,可以支持消费者的Active/Active和Active/Standy模式,前者是每个区域起一个消费者消费聚合集群的的数据,只有一个区域是主区域,只有主区域的数据可以更新数据到后端数据库中,当主区域故障后,指定新的主区域,新的主区域继续消费计算,在Active/Standy模式中,所有区域中只有一个消费者,该区域故障后,在其他区域启动一个消费者,根据offset管理服务里记录的offset对应关系,从每个区域的区域集群中找到所有最新的checkpoints,然后根据该checkpoints在Standy区域的聚合集群查找最小offset,从Standy区域的该offset开始消费。
在brooklin中,也可以通过类似uReplicator的设计利用数据的冗余实现Active/Active灾备模式。
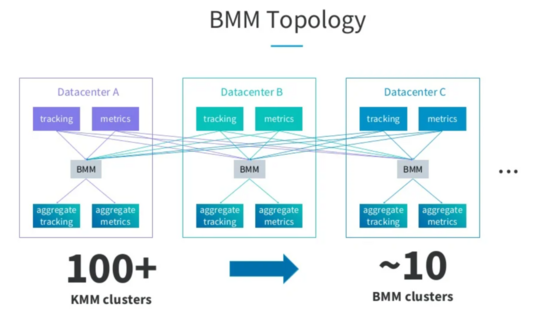
在字节介绍的灾备方案中,Producer只能往主集群写(主备集群中的信息是存储在配置中心里的,客户端需要先从配置中心查询),Producer可以在双中心部署,但是通过配置中心路由到主集群,Consumer也可在双中心部署,若采用Active/Standy模式,各自消费本地机房的数据,但是只有主集群里消费者的消费位移可以生效,在采用Active/Active模式下,消费者只能从主集群进行消费,这两种模式下,都是将双中心所有消费者的消费位移采用一个存储统一存储。
在灾备模式方面,各方案总结如下:
方案 | MM1 | MM2 | Confluent Replicator | 基于Follower的同步机制 | uReplicator | brooklin |
双集群是否可互相复制 | 不支持 | 支持 | 支持 | 不支持 | 支持,依靠聚合集群 | 支持,依靠聚合集群 |
Producer Active/Active | 不支持 | 支持 | 支持 | 支持,但是其实只写入主集群 | 支持 | 支持 |
Consumer Active/Standy | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
Consumer Active/Active | 不支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
4.各方案的主要设计点总结
总结来说,这些方案里归结为三类:
1.Kafka社区的设计路线方案,从源集群消费,再写入到目标集群,包含MM1,MM2,uReplicator,brooklin这几种方案,MM2是参考了uReplicator的设计,实现方案和brooklin类似,那么在这四种方案中,MM2可以作为优先考虑方案。
2.Confluent Replicator的商业收费方案,也是利用Kafka Connect框架进行消费写入,在避免Topic循环复制和消费位移转换方面做得非常出色,客户端切换的代价很低。
3.以字节、滴滴为代表的基于Follower同步机制的方案,这种方案里复制后的Topic是源Topic的镜像,客户端不需要做offset转换,需要改造Kafka代码,考虑到后续和原生Kafka代码的版本融合,技术要求较高。
目前来说,没有一个完美的解决方案,各公司可根据自身实际需求制定。