随着云、本地、边缘间的界限逐渐消失,数据管理的未来可以用四个关键词来描述。
四大关键字
首先是分布式(Distributed),未来的数据管理将是分布式的,因为数据管理须随数据所在的位置而进行。
其次是无服务器(Serverless),此概念较特殊、并不是指未来的数据管理不再需要服务器,而是指未来将没有一个明确的集中式服务器。
再者是协调(Orchestrated),今天的数据会产生在不同的地方和设备上,所以须把它们协调管理。
最后就是元数据(Metadata),无论数据分散在何处,元数据均能把它们协调在一起,因此元数据是未来数据管理中非常重要的一个元素。
三大维度
总体而言,数据管理的未来发展趋势可从三个维度来看——架构的改变、技术的转变以及组织的衍化。
1.架构的改变(Architecture Shifts)
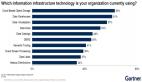
Gartner于2018年针对数据和分析的采用趋势进行了一项调查(多选题)。结果显示企业机构目前使用最普遍的信息基础架构技术为“基于云平台的数据存储”(63%)。
一些传统技术,例如数据仓库(Data Warehouse)和数据库管理系统(DBMS)仍然占着相当大的比重。这些传统技术在未来并不会消失。
举例而言,“数据仓库”是一个非常广泛的案例,未来数据的研究和分析都将需要用到该技术——主要配合在特定案例和场合中使用。
此外,未来还将有诸如“数据目录”(Data Catalogs)这样的技术被广泛使用。
“数据目录”是元数据的重要基础,以往“数据目录”主要用于帮助企业机构了解数据的定义和来源,但现在的趋势是“数据目录”可以帮助企业机构了解数据的特性、使用者以及使用场景。
因此,在数据管理的未来趋势中,“数据目录”将具有举足轻重的地位。
此外,数据湖(Date Lake)已从此前放置在内部数据中心中转变为目前可放在云端上,这是一个非常大的变化,未来诸如此类比较高端的技术均可以移至云平台之上。
1)重“关联”、轻“采集”


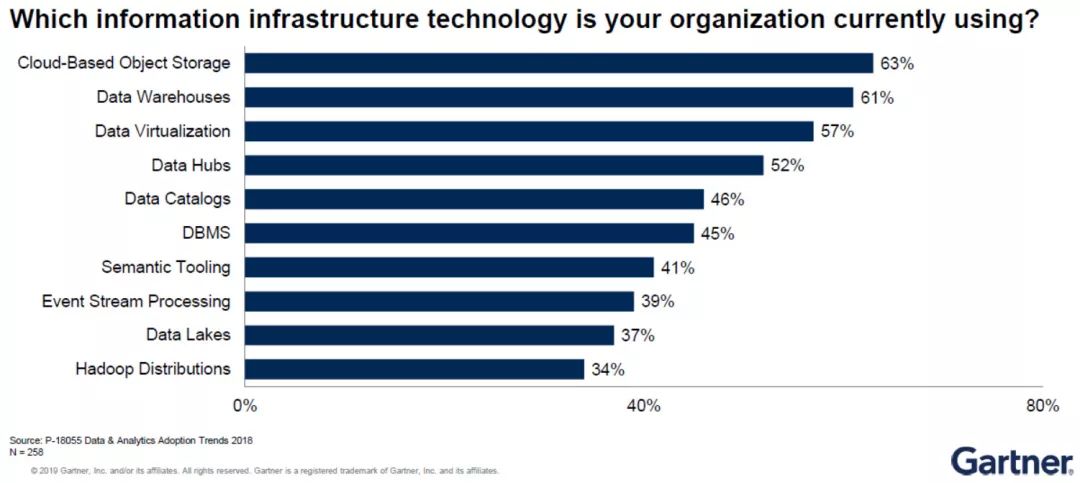
从上述调查背景可以看出,未来的数据管理和集成将会变得更加“关联”(Connect),更少“采集”(Collect)。
当前,在数据管理上,企业机构通常重“采集”、轻“关联”,此情形在中国尤为严重——即企业机构在采集和存储数据后,并不能立即挖掘其中的价值,失去其时效性。
原因在于,从数据被“采集”到应用其价值,这中间有相当长的流程(如上左图所示),包括描述、整理、集成、分享、治理和实施。这一长串流程对企业机构内部IT技术具有相当大的考验。
随着机器学习技术的引入和元数据的应用,目前数据管理和集成已开始呈现出一种新趋势,即更加注重数据的“关联”(如上右图所示),也就是指无论数据是在本地、云端、某个设备感应器上或任何地方,我们都可以在数据保留在原地的情况下,将它们关联起来,而无须采集到特定地方。
在未来增强式的数据管理的环境中,自动发掘数据、透过机器自动意识识别数据中的价值、认定有价值的数据、分析数据、自动采用适合数据的安全措施、分享数据、优化数据,最终实现在最短时间内将精准的数据发送给对的人,对于企业机构至关重要。
2)“移动性数据”成为主要案例
数据管理与集成方面的另一个趋势是“移动性数据”(Data in Motion)。
以往,诸如交易产生后,企业机构便把数据存储进数据库或数据中心内,后续任务即制作报表等工作,这类的数据被称为“静态型”。
“移动性数据”指的是在交易过程中,企业机构就可以看到实时的数据处理——无论数据处在边缘设备还是在数据中心内。数据始终是数据商用平台的核心所在。
3)集中式、分布式、随机式数据治理并存
与数据管理(Data Management)不同,数据治理(Data Governance)注重数据的使用者、使用方式、使用权限的合规性制定。
未来的“数据治理”将会非常动态——可以是集中式、分布式,亦可是随机式。“随机式”是指企业机构可以通过机器学习来增强数据内容以及评估用例。
举例而言,某件物品在首次被海关征收关税时,海关可能不知如何“治理”它。但“机器学习”引擎可以自动分辨该物品的属性,进而据此自动帮助海关生成此件物品应该遵循的“治理”规则。
4)元数据是未来数据管理的关键
企业机构的数据来源不仅多种多样(包括ERP、CRM、SCM和HCM),且用途极为广泛(可用于外部供应商、客户与合作伙伴,呈现方式包括图表、报表和指示板)。
将这些来源与用途连接起来——即连通无服务器进程(Serverless Processes)和物理合并(Physical Consolidation)的关键桥梁就是元数据。
2.技术的转变(Technology Changes)
Gartner预计,在2021年之前,能够采用数据中心、数据湖或者数据仓库这种统一战略的企业机构,将比竞争对手多出30%的使用案例。
此外,在2023年之前,75%的数据库将迁移至云平台上,此举意味着减少数据库管理系统供应商的规模并且增加数据治理和集成的复杂性。
1)人工智能让数据管理软件的运行更加流畅


现在,人工智能可以帮助企业机构增强数据管理。事实上,数据管理技术的未来就是人工智能和机器学习的应用。
具体而言,有以下四方面:
第一是数据质量(Data Quality)。目前市场上有很多供应商都是在用机器学习的方式帮助企业机构扩展和增强数据的分析、清理、连接、识别、语义协调和重组。企业机构在不同数据源中管理主数据质量以往需要人为操作、费时费力,而机器学习可以使这一整串流程变得完全自动化,且准确率明显提高。
第二是主数据管理(Master Data Management)。机器学习可以帮助企业机构配置和优化主数据,尤其在记录匹配和算法融合方面,机器学习可以让企业机构对主数据的管理更加便利。
第三是数据集成(Data Integration)。人工智能可以通过升级多个相同模式并根据语义分析,向企业机构告知数据源的相关性,推荐企业机构将相同的数据源进行连接,最终使得数据集成的流程更加简化。
第四是数据库管理系统(DataBase Management System)。人工智能技术的引入将使数据库从存储、索引、分区到调整、优化、修补——这一系列繁琐的人工流程变得更加自动化。
2)动态元数据创造“自我驱动型”数据管理
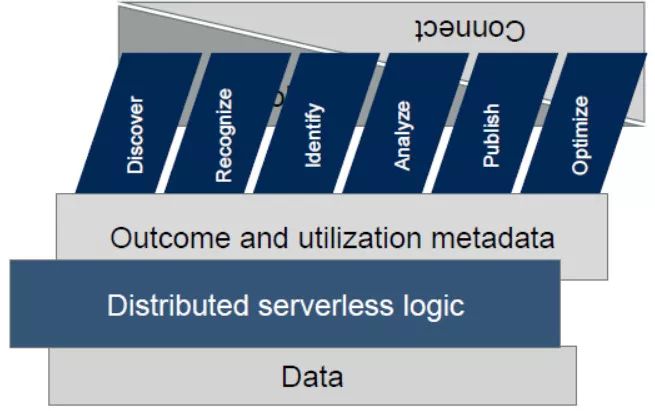
机器学习和人工智能是一个后端底层技术,诸如性能分析等更多数据管理工作的完成还需动态元数据的支持。元数据专门用于描述数据的特质,帮助企业机构将不同的数据进行关联并做推荐。
以数据分析为例,企业机构在定义数据的相关性时,动态元数据就会起到中间凝合力的作用。
3)开源软件收益与风险的平衡
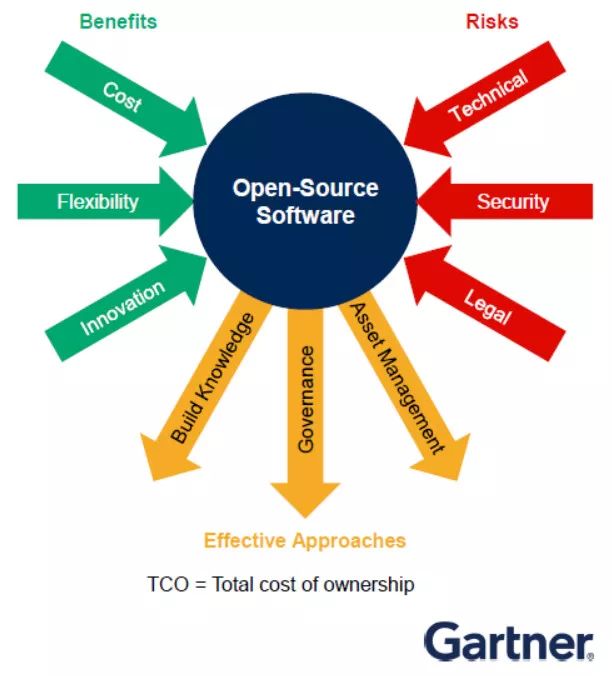
提及开源,一般想到的是总拥有成本(TCO)很低、企业机构的回本速度很快。
虽然企业机构有时无法通过开源软件(OSS)得到所需支持,但目前市场上已有很多商业软件包可给予帮助。
其次,若企业机构需要研发创新并保持灵活性,那么开源软件应是首要选择。
再者,据Gartner调查,全球90%的企业机构已把开源软件用在任务关键型的IT流程中。
最后,企业机构应把服务水平协议与商业供应商的平衡性放入自身的数据管理策略考量中。
3.组织的衍化(Organization Evolves)
Gartner预测,到2022年之前,使用动态元数据去连接、优化、自动化数据集成流程的企业机构将减少30%的数据交付的时间。
此外,到2023年之前,在数据管理中使用人工智能技术能够帮助企业机构进行更多的自动化工作,因此这些企业机构对于IT专业人士的需求将减少20%。
1)自动化数据与分析工作即将来临
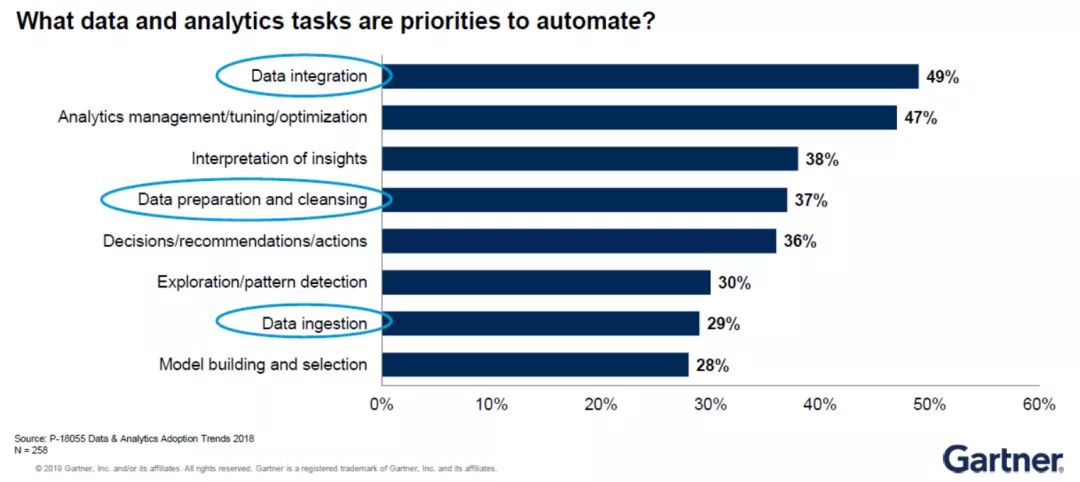
Gartner就数据分析工作的自动化优先级进行过一项调研。调研结果显示,数据集成(Data Integration)排名第一,因为其最费时间也最易出错。
此外,机器学习相关技术的研发需要进行大量前期的数据准备(Data Preparation)。Gartner预计数据科学家大约需要花费70%到80%的时间进行数据准备。
因此,若数据准备无法进行自动化,那么项目交付的时间就会极其漫长。
2)人机联盟:少花钱、多做事
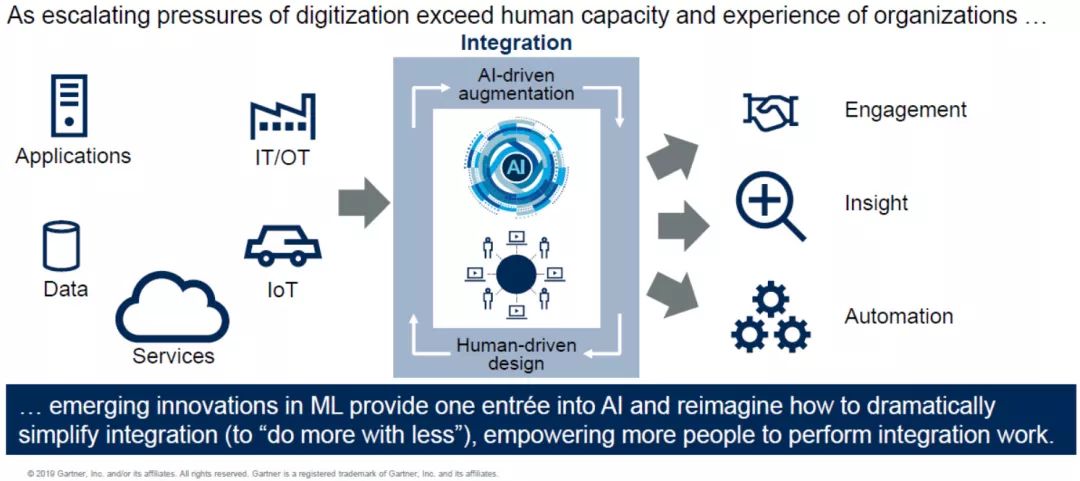
未来,数据集成工作需要人与机器共同完成。数据存在不同的端口且数量庞大,因此单独的人力难以进行处理、需有工具进行支持。未来,这种工具将引入人工智能与机器学习技术,让人力做不到或短期内无法实现的工作变成现实。
与此同时,此前从事这类工作的IT工程师将可腾出时间去做更多、更重要的事情。
3)元数据与数据管理架构紧密贴合
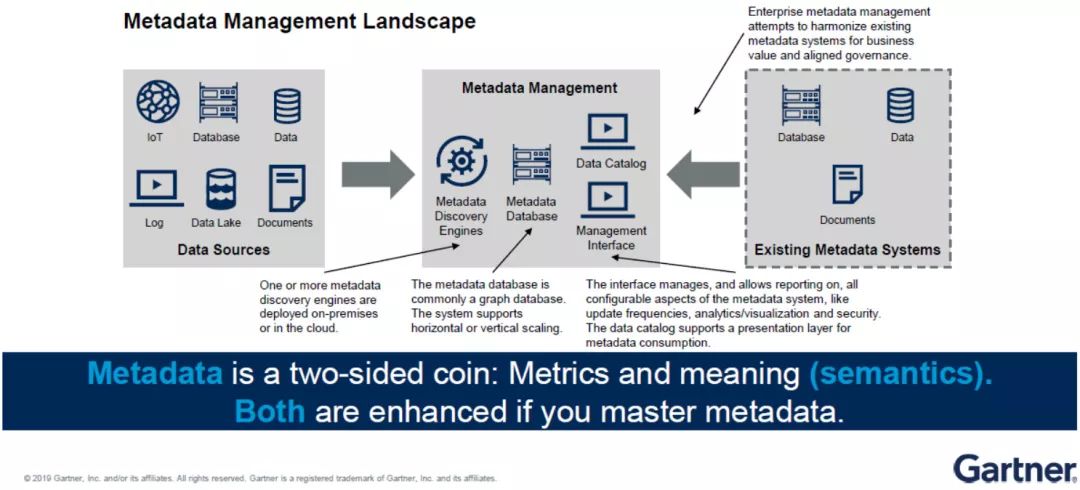
元数据的管理平台上有很多引擎,有些可以根据数据目录,即目前所存储的数据信息,自动地发现企业机构目前架构中有哪些数据源还未掌控,然后进行处理。
元数据有两种维度——度量(Metrics)与语义(Meaning)。
以往,企业机构做得更多的是语义,但在未来元数据的管理上,两者具有同等重要性,甚至“度量”的地位更高,因为它可以根据此前类似数据的集成方式自动进行数据挖掘和规划。
4)数据管理新角色不断涌现
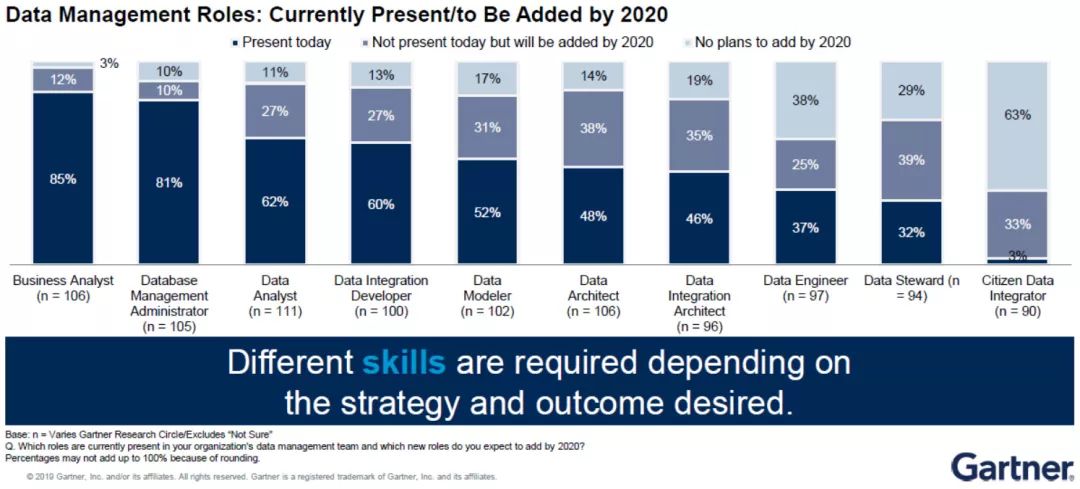
Gartner针对“企业机构目前及2020前的数据管理职位”进行过调研,结果如上图所示。其中,需重点强调的是数据管家(Data Steward)。“数据管家”在未来的数据管理工作中占有极其重要的地位。
当前,企业机构已经意识到自己的数据源变得更多、数据使用案例变得更为复杂,在此情况下,它们需要新的岗位去应对挑战。
但需强调的是,每个企业机构都有自己不同的战略,它们需要根据预测的业务结果来应用不同的技能、设置不同的数据管理岗位。