Python 程序允许我们使用 NumPy timedelta64 和 datetime64 来操作和检索时间序列数据。 sklern库中也提供时间序列功能,但 Pandas 为我们提供了更多且好用的函数。

Pandas 库中有四个与时间相关的概念
- 日期时间:日期时间表示特定日期和时间及其各自的时区。 它在 pandas 中的数据类型是 datetime64[ns] 或 datetime64[ns, tz]。
- 时间增量:时间增量表示时间差异,它们可以是不同的单位。 示例:“天、小时、减号”等。换句话说,它们是日期时间的子类。
- 时间跨度:时间跨度被称为固定周期内的相关频率。 时间跨度的数据类型是 period[freq]。
- 日期偏移:日期偏移有助于从当前日期计算选定日期,日期偏移量在 pandas 中没有特定的数据类型。
时间序列分析至关重要,因为它们可以帮助我们了解随着时间的推移影响趋势或系统模式的因素。 在数据可视化的帮助下,分析并做出后续决策。
现在让我们看几个使用这些函数的例子
1、查找特定日期的某一天的名称
import pandas as pd
day = pd.Timestamp(‘2021/1/5’)
day.day_name()- 1.
- 2.
- 3.
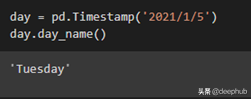
上面的程序是显示特定日期的名称。 第一步是导入 panda 的并使用 Timestamp 和 day_name 函数。 “Timestamp”功能用于输入日期,“day_name”功能用于显示指定日期的名称。
2、执行算术计算
import pandas as pd
day = pd.Timestamp(‘2021/1/5’)
day1 = day + pd.Timedelta(“3 day”)
day1.day_name()
day2 = day1 + pd.offsets.BDay()
day2.day_name()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
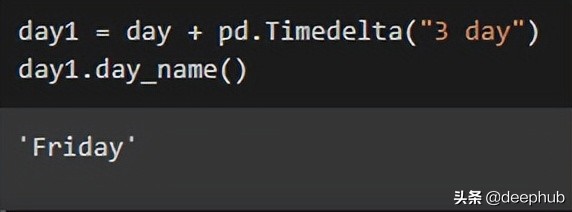
在第一个代码中,显示三天后日期名称。“Timedelta”功能允许输入任何天单位(天、小时、分钟、秒)的时差。
在第二个代码中,使用“offsets.BDay()”函数来显示下一个工作日。 换句话说,这意味着在星期五之后,下一个工作日是星期一。
3、使用时区信息来操作转换日期时间
获取时区的信息
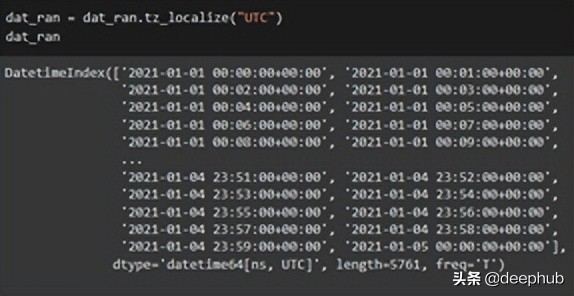
import pandas as pd
import numpy as np
from datetime import datetime
dat_ran = dat_ran.tz_localize(“UTC”)
dat_ran- 1.
- 2.
- 3.
- 4.
- 5.
转换为美国时区
dat_ran.tz_convert(“US/Pacific”)- 1.
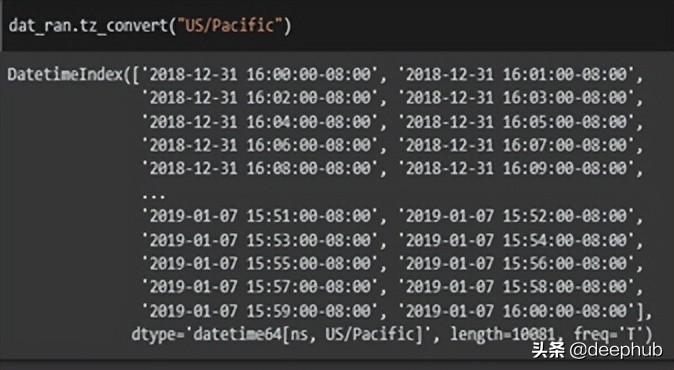
代码的目标是更改日期的时区。 首先需要找到当前时区。 这是“tz_localize()”函数完成的。 我们现在知道当前时区是“UTC”。使用“tz_convert()”函数,转换为美国/太平洋时区。
4、使用日期时间戳
import pandas as pd
import numpy as np
from datetime import datetime
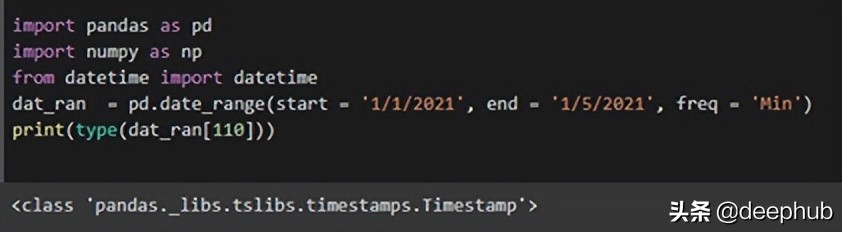
dat_ran = pd.date_range(start = ‘1/1/2021’, end = ‘1/5/2021’, freq = ‘Min’)
print(type(dat_ran[110]))- 1.
- 2.
- 3.
- 4.
- 5.
5、创建日期系列
import pandas as pd
import numpy as np
from datetime import datetime
dat_ran = pd.date_range(start = ‘1/1/2021’, end = ‘1/5/2021’, freq = ‘Min’)
print(dat_ran)- 1.
- 2.
- 3.
- 4.
- 5.
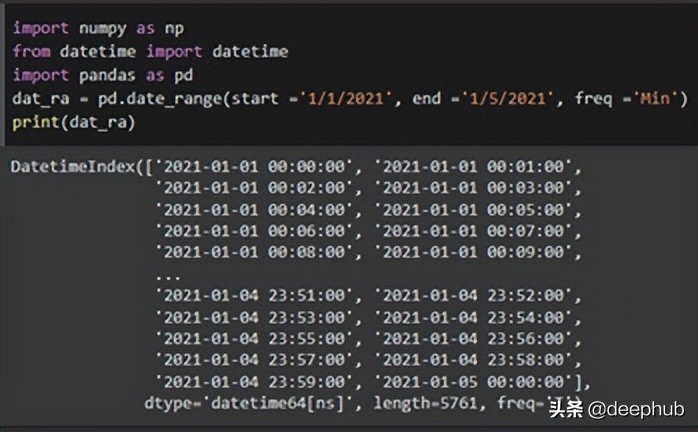
上面的代码生成了一个日期系列的范围。使用“date_range”函数,输入开始和结束日期,可以获得该范围内的日期。
6、操作日期序列
import pandas as pd
from datetime import datetime
import numpy as np
dat_ran = pd.date_range(start =’1/1/2019', end =’1/08/2019',freq =’Min’)
df = pd.DataFrame(dat_ran, columns =[‘date’])
df[‘data’] = np.random.randint(0, 100, size =(len(dat_ran)))
print(df.head(5))- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
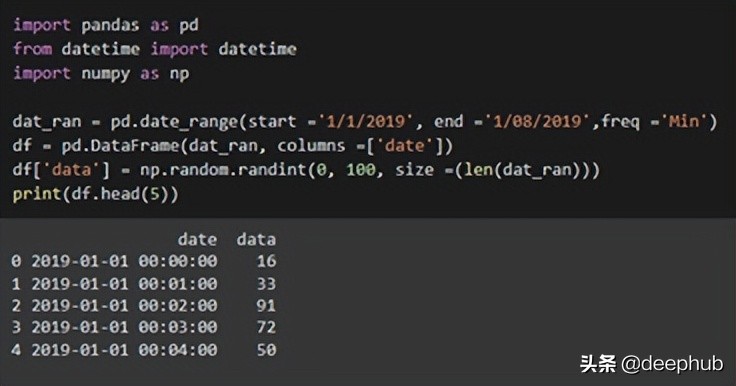
在上面的代码中,使用“DataFrame”函数将字符串类型转换为dataframe。 最后“np.random.randint()”函数是随机生成一些假定的数据。
7、使用时间戳数据对数据进行切片
import pandas as pd
from datetime import datetime
import numpy as np
dat_ran = pd.date_range(start =’1/1/2019', end =’1/08/2019', freq =’Min’)
df = pd.DataFrame(dat_ran, columns =[‘date’])
df[‘data’] = np.random.randint(0, 100, size =(len(dat_ran)))
string_data = [str(x) for x in dat_ran]
print(string_data[1:5])- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
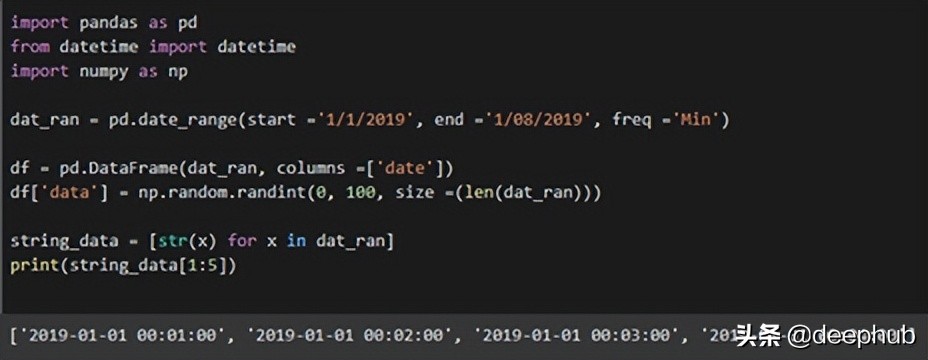
上面代码是是第6条的的延续。 在创建dataframe并将其映射到随机数后,对列表进行切片。
最后总结,本文通过示例演示了时间序列和日期函数的所有基础知识。 建议参考本文中的内容并尝试pandas中的其他日期函数进行更深入的学习,因为这些函数在我们实际工作中非常的重要。