













在前面的文章 Redis:我是如何与客户端进行通信的 中,我们介绍过RESP V2版本协议的规范,RESP的全程是Redis Serialization Protocol,基于这个实现简单且解析性能优秀的通信协议,Redis的服务端与客户端可以通过底层命令的方式进行数据的通信。
随着Redis版本的不断更新以及功能迭代,RESP V2协议开始渐渐无法满足新的需求,为了适配在Redis6.0中出现的一些新功能,在它的基础上发展出了全新的下一代RESP3协议。
下面我们先来回顾一下继承自RESP V2的5种数据返回类型,在了解这些类型的局限性后,再来看看RESP3中新的数据返回类型都在什么地方做出了改进。
1、继承RESP v2的类型
首先,协议中数据的请求格式与RESP V2完全相同,请求的格式如下:
*<参数数量> CRLF
$<参数1的字节长度> CRLF
<参数1的数据> CRLF
$<参数2的字节长度> CRLF
<参数2的数据> CRLF
...
$<参数N的字节长度> CRLF
<参数N的数据> CRLF
每行末尾的CRLF转换成程序语言是\r\n,也就是回车加换行。以set name hydra这条命令为例,转换过程及转换后的结果如下:
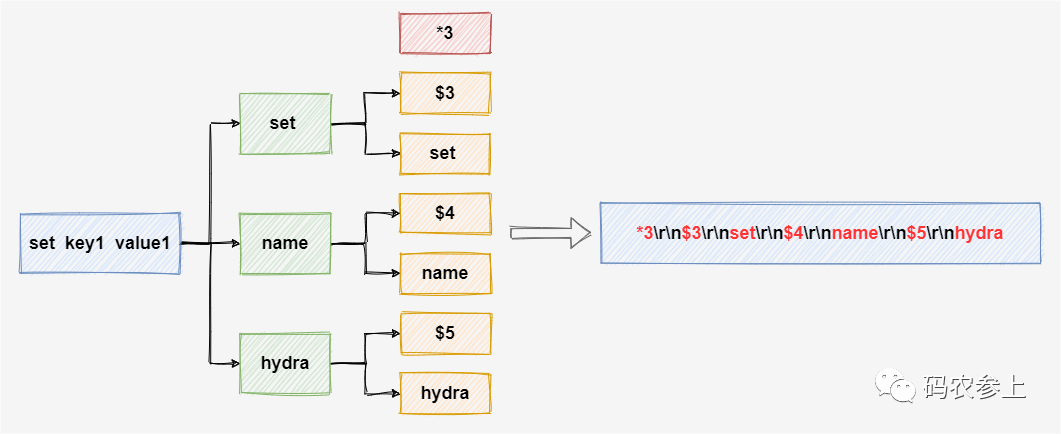
在了解了发送的协议后,下面对不同类型的回复进行测试。这一过程如何进行模拟呢?在前面的文章中,我们是在java代码中通过Socket连接redis服务,发送数据并收到返回结果来模拟这一协议。
不过我们今天采用一种更为简单的方式,直接在命令行下使用telnet进行连接就可以了,以我本机启动的redis为例,直接输入telnet 127.0.0.1 6379就可以连接到redis服务了。之后再将包含换行的指令一次性拷贝到命令行,然后回车,就能够收到来自Redis服务的回复了:
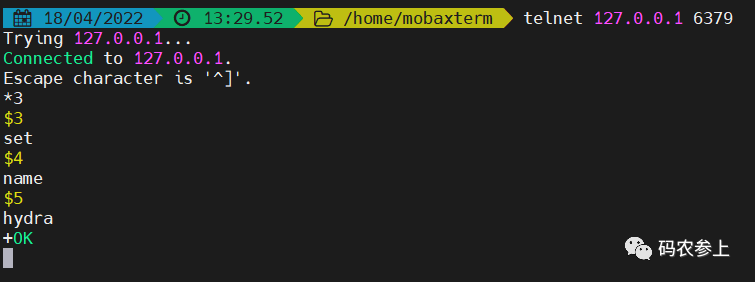
下面先来看看继承自RESP V2的5种返回格式,为了统一命名规范,介绍中均采用RESP3官方文档中的新的名称来替代RESP V2中的旧命名,例如不再使用旧的批量回复、多条批量回复等类型名称。
Simple string
表示简单字符串回复,它只有一行回复,回复的内容以+作为开头,不允许换行,并以\r\n结束。有很多指令在执行成功后只会回复一个OK,使用的就是这种格式,能够有效地将传输、解析的开销降到最低。
还是以上面的set指令为例,发送请求:
*3
$3
set
$4
name
$5
hydra
收到回复:
+OK\r\nSimple error
错误回复,它可以看做简单字符串回复的变种形式,它们之间的格式也非常类似,区别只有第一个字符是以-作为开头,错误回复的内容通常是错误类型及对错误描述的字符串。错误回复出现在一些异常的场景,例如当发送了错误的指令、操作数的数量不对时,都会进行错误回复。
发送一条错误的指令:
*1
$8
Dr.Hydra
收到回复,提示错误信息:
https://mp.weixin.qq.com/s/rLk2EW0TKAIkQvx1WefafA#:~:text=%2DERR%C2%A0unknown%C2%A0command%C2%A0%60Dr.Hydra%60%2C%C2%A0with%C2%A0args%C2%A0beginning%C2%A0with%3A%5Cr%5Cn
Number
整数回复,它的应用也非常广泛,它以:作为开头,以\r\n结束,用于返回一个整数。例如当执行incr后返回自增后的值,执行llen返回数组的长度,或者使用exists命令返回的0或1作为判断一个key是否存在的依据,这些都使用了整数回复。
发送一条查看数组长度的指令:
*2
$4
llen
$7
myarray
收到回复:
:4\r\n
Blob string
多行字符串的回复,也被叫做批量回复,在RESP V2中将它称为Bulk String。以$作为开头,后面是发送的字节长度,然后是\r\n,然后发送实际的数据,最终以\r\n结束。如果要回复的数据不存在,那么回复长度为-1。
发送一条get命令请求:
*2
$3
get
$4
name
收到回复:
$5\r\n
hydra\r\n
Array
可以理解为RESP V2中的多条批量回复,当服务端要返回多个值时,例如返回一些元素的集合时,就会使用Array。它以*作为开头,后面是返回元素的个数,之后再跟随多个上面的Blob String。
*4
$6
lrange
$7
myarray
$1
0
$2
-1
收到回复,包含了集合中的4个元素:
*4
$1
1
$1
2
$1
2
$2
32
这5种继承自RESP V2协议的返回数据类型的简单回顾到此结束,下面我们来开启RESP3协议新特性的探索之旅。
2、RESP3中新的类型
目前在Redis6.0.X版本中,仍然是默认使用的RESP V2协议,并且在兼容RESP V2的基础上,也同时也支持开启RESP3。估计在未来的某个版本,Redis可能会全面切换到RESP3,不过这么做的话对目前的Redis客户端连接工具会有不小的冲击,都需要根据协议内容进行底层通信的改造。
在使用telnet连接到redis服务后,先输入下面的命令来切换到RESP3版本的协议,至于hello命令的具体返回数据以及数据表示的意义,这里暂且略过,后面会具体来看。
hello 3
下面我们就来详细看看在RESP3中,除了保留上面的5种旧回复类型外,新增的13种通信返回数据类型,部分数据类型会配合示例进行演示。为了看起来更加简洁,下面的演示例子发送命令均使用原始命令,不再转化为协议格式,并且省略数据返回结果中每行结束的\r\n!
(1)Null
新协议中使用下划线字符后跟CR和LF字符来表示空值,也就是用_\r\n来替代原先的单个空值的返回$-1。例如在使用get命令查找一个不存在的key时:
get hydra
RESP V2返回:
$-1RESP3返回:
_(2)Double
浮点数返回时以逗号开头,格式为 ,\r\n,使用zset score key member获取分数的命令来进行测试:
zscore fruit apple
RESP V2返回时使用的是Bulk String的格式:
$18
5.6600000000000001
RESP3返回格式:
,5.6600000000000001(3)Boolean
布尔类型的数据返回值,其中true被表示为#t\r\n,而false被表示为#f\r\n。不过Hydra暂时没有找到返回布尔类型结果的例子,即使是用lua脚本直接返回布尔类型也无法实现。
eval "return true" 0
eval "return false" 0
上面的lua脚本在返回true时结果为:1\r\n,返回false时结果为_\r\n,这是因为lua中布尔类型的true会转换为redis中的整数回复1,而false类型会转换成Nil Bulk。至于有哪些指令能够返回布尔类型的数据,有了解的小伙伴可以给我留言补充。
(4)Blob error
与字符串类型比较相似,它的格式为!\r\n\r\n,但是与简单错误类型一样,开头使用!表示返回的是一段错误信息描述。例如错误SYNTAX invalid syntax会按照下面的格式返回:
!21
SYNTAX invalid syntax
(5)Verbatim string
Verbatim string也表示一个字符串格式,与Blob String非常相似,但是使用=开头替换了$,另外之后的三个字节提供了有关字符串格式的信息,例如txt表示纯文本,mkd表示markdown格式,第四个字节则固定为 :。这种格式适用于在没有任何转义或过滤的情况下显示给用户。
使用延时事件统计与分析指令进行测试,发送:
latency doctor
RESP2返回的数据还是Blob String格式:
$196
Dave, no latency spike was observed during the lifetime of this Redis instance, not in the slightest bit. I honestly think you ought to sit down calmly, take a stress pill, and think things over.
RESP V3返回的数据采用了新的格式:
=200
txt:Dave, no latency spike was observed during the lifetime of this Redis instance, not in the slightest bit. I honestly think you ought to sit down calmly, take a stress pill, and think things over.
(6)Big number
Big number类型用于返回非常大的整数数字,可以表示在有符号64位数字范围内的整数,包括正数或负数,但是需要注意不能含有小数部分。数据格式为(\r\n,以左括号开头,示例如下:
(3492890328409238509324850943850943825024385注意,当Big number不可用时,客户端会返回一个字符串格式的数据。
(7)Aggregate data types
与前面我们介绍的给定数据类型的单个值不同,Aggregate data types可以理解为聚合数据类型。这也是RESP3的一个核心思想,要能够从协议和类型的角度,来描述不同语义的聚合数据类型。
聚合数据类型的格式如下,通常由聚合类型、元素个数以及具体的单一元素构成:
<aggregate-type-char><numelements><CR><LF>
... numelements other types ...
例如一个包含三个数字的数组[1,2,3]可以表示为:
*3
:1
:2
:3
当然聚合数据类型中的元素可以是其他聚合数据类型,例如在数组中也可以嵌套包含其他数组(下面的内容包含了缩进方便理解):
*2
*3
:1
$5
hello
:2
#f
上面的聚合数据类型所表示的数据为[[1,"hello",2],false]。
(8)Map
Map数据类型与数组比较类似,但是以%作为起始,后面是Map中键值对的数量,而不再是单个数据项的数量。它的数据内容是一个有序的键值对的数组,之后分行显示键值对的key和value,因此后面的数据行一定是偶数行。先看一下官方文档给出的例子,以下面的Json字符串为例:
{
"first":1,
"second":2
}转换为Map类型后格式为下面的形式:
%2
+first
:1
+second
:2
但是通过实验,Hydra发现了点有意思的东西,当我们发送一条hgetall的命令来请求哈希类型的数据时:
hgetall user
RESP V2返回的数据仍然使用老的Array格式,符合我们的预期:
*4
$4
name
$5
Hydra
$3
age
$2
18
但是下面RESP3的数据返回却出乎我们的意料,可以看到虽然前面的%2表示使用了Map格式,但是后面并没有遵循官方文档给出的规范,除了开头的%2以外,其余部分与Array完全相同()。
%2
$4
name
$5
Hydra
$3
age
$2
18
关于实际传输数据与文档中给出示例的出入,Hydra有一点自己的猜测,放在最后总结部分。
(9)Set
Set与Array类型非常相似,但是它的第一个字节使用~替代了*,它是一个无序的数据集合。还是先看一下官方文档中给出的示例,下面是一个包含了5个元素的集合类型数据,并且其中具体的数据类型可以不同:
~5<CR><LF>
+orange<CR><LF>
+apple<CR><LF>
#t<CR><LF>
:100<CR><LF>
:999<CR><LF>
下面使用SMEMBERS命令获取集合中的所有元素进行测试:
SMEMBERS myset
RESP V2返回时仍然使用Array格式:
*3
$1
a
$1
c
$1
b
RESP3的数据返回情况和Map比较类似,使用~开头,但是没有完全遵从协议中的格式:
~3
$1
a
$1
c
$1
b
(10)Attribute
Attribute类型与Map类型非常相似,但是头一个字节使用|来代替了%,Attribute描述的数据内容比较像Map中的字典映射。客户端不应该将这个字典内容看做数据回复的一部分,而是当做增强回复内容的辅助数据。
在文档中提到,在未来某个版本的Redis中可能会出现这样一个功能,每次执行指令时都会打印访问的key的请求频率,这个值可能使用一个浮点数表示,那么在执行MGET a b时就可能会收到回复:
|1
+key-popularity
%2
$1
a
,0.1923
$1
b
,0.0012
*2
:2039123
:9543892
在上面的数据回复中,实际中回复的数据应该是[2039123,9543892],但是在前面附加了它们请求的属性,当读到这个Attribute类型数据后,应当继续读取后面的实际数据。
(11)Push
Push数据类型是一种服务器向客户端发送的异步数据,它的格式与Array类型比较类似,但是以>开头,接下来的数组中的第一个数据为字符串类型,表示服务器发送给客户端的推送数据是何种类型。数组中其他的数据也都包含自己的类型,需要按照协议中类型规范进行解析。
简单看一下文档中给出的示例,在执行get key命令后,可能会得到两个有效回复:
>4
+pubsub
+message
+somechannel
+this is the message
$9
Get-Reply
在上面的这段回复中需要注意,收到的两个回复中第一个是推送数据的类型,第二个才是真正回复的数据内容。
注意!这里在文档中有一句提示:虽然下面的演示使用的是Simple string格式,但是在实际数据传输中使用的是Blob string格式。所以盲猜一波,上面的Map和Set也是同样的情况?
这里先简单铺垫一下Push回复类型在redis6中非常重要的一个使用场景客户端缓存client-side caching,它允许将数据存储在本地应用中,当访问时不再需要访问redis服务端,但是其他客户端修改数据时需要通知当前客户端作废掉本地应用的客户端缓存,这时候就会用到Push类型的消息。
我们先在客户端A中执行下面的命令:
client tracking on
get key1
在客户端B中执行:
set key1 newValue
这时就会在客户端A中收到Push类型的消息,通知客户端缓存失效。在下面收到的消息中就包含了两部分,第一部分表示收到的消息类型为invalidate,第二部分则是需要作废的缓存key1:
>2
$10
invalidate
*1
$4
key1
(12)Stream
在前面介绍的类型中,返回的数据字符串一般都具有指定的长度,例如下面这样:
$1234<CR><LF>
.... 1234 bytes of data here ...<CR><LF>
但是有时候需要将一段不知道长度的字符串数据从客户端传给服务器(或者反向传输)时,很明显这种格式无法使用,因此需要一种新的格式用来传送不确定长度的数据。
文档中提到,过去在服务端有一个私有扩展的数据格式,规范如下:
$EOF:<40 bytes marker><CR><LF>
... any number of bytes of data here not containing the marker ...
<40 bytes marker>
它以$EOF:作为起始字节,然后是40字节的marker标识符,在\r\n后跟随的是真正的数据,结束后也是40字节的标识符。标识符以伪随机的方式生成,基本上不会与正常的数据发生冲突。
但是这种格式存在一定的局限性,主要问题就在于生成标识符以及解析标识符上,由于一些原因使得上面这种格式在实际使用中非常脆弱。因此最终在规范中提出了一种分块编码格式,举一个简单的例子,当需要发送事先不知道长度的字符串Hello world时:
$?
;4
Hell
;5
o wor
;2
ld
;0
这种格式以$?开头,表示是一个不知道长度的分块编码格式,后面传输的数据数量没有限制,在最后以零长度的;0作为结束传输的标识。文档中提到,目前还没有命令会以这个格式来进行数据回复,但是会在后面的功能模块中实装这个协议。
(13)HELLO
在介绍RESP3的最开始,我们就在telnet中通过hello 3的命令来切换协议到V3版本。这个特殊的命令完成了两件事:
- 它允许服务器与RESP V2版本向后兼容,也方便以后更加轻松的切换到RESP3。
- hello命令可以返回有关服务器和协议的信息,以供客户端使用。
hello命令的格式如下,可以看到除了协议版本号外,还可以指定用户名和密码:
HELLO <protocol-version> [AUTH <username> <password>]
hello命令的返回结果是前面介绍过的Map类型,仅仅在客户端和服务器建立连接的时候发送。
%7
$6
server
$5
redis
$7
version
$6
6.0.16
$5
proto
:3
$2
id
:18
$4
mode
$10
standalone
$4
role
$6
master
$7
modules
*0
转换为我们可读的Map格式后,可以看到它返回的Redis服务端的一些信息:
{
"server":"redis",
"version":"6.0.16",
"proto":3,
"id":18,
"mode":"standalone",
"role":"master",
"modules":[]
}3、总结
在RESP V2中,通信协议还是比较简单,通信内容大多也都还是通过数组形式进行编码和发送,这种情况带来了很多不便,有很多情况需要根据操作命令的类型来判断返回的数据具体是什么类型,这无疑增加了客户端解析数据的难度与复杂度。
而在RESP3中,通过引入新的多种数据类型,通过起始字节的字符进行类型的区分编码,使客户端可以直接判断返回数据的类型,在相当大的程度上,减轻了解析的复杂度,提升了效率。
本文中对于新的返回数据类型,一部分给出了通信数据的示例,但还是有一些类型暂时没有找到合适的命令进行测试,有了解的小伙伴们可以给我补充。
另外对于Map和Set,实际传输的数据与官方文档给出的仍有一定出入,个人认为情况和Push相同,可能是官方文档中更多只偏向于演示,使用Simple string来代替了Blob string。
最后再啰嗦一句,说说协议的命名,新一代的协议名称就叫RESP3,而没有继承第二代的命名规范叫RESP V3,也不是RESP version3什么乱七八糟的,所以就不要纠结文中为啥一会是RESP V2,一会是RESP3这种不对称的命名了。


















