












虽然DeepFake能令人置信地换脸,但没法同样换好头发。现在浙大与瑞典研究者都扩宽思路,用GAN或CNN来另外生成逼真的虚拟发丝。
DeepFake技术面世的2010年间末叶,正好赶上了川普时代。
无数搓手打算用DeepFake来好好恶搞大总统一下的玩梗人,在实操中遇到了一个不大不小的障碍:
各家DeepFake类软件,可以给图像换上金毛闯王的橙脸,但那头不羁的金发实在让AI都生成不出令人置信的替代品。
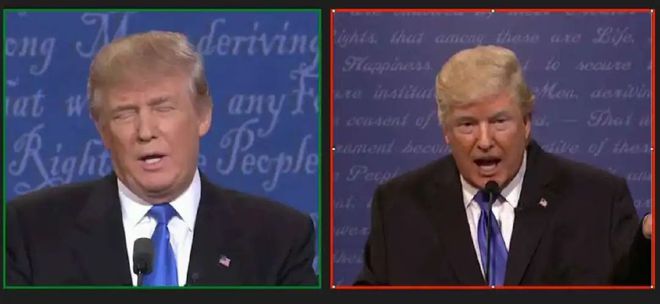
看,是不是那头毛就让DeepFake产品露馅了。
DeepFake搞得定换脸,也搞不定换头发
其实这是老问题遇到了新挑战。如何栩栩如生地复现人像模特的头发,这是一个自希腊-罗马时代的雕像师开始就很觉棘手的难题。
人脑袋平均有大概100000根头发丝,并且因为颜色和折射率的不同,在超过一定的长度后,即使在计算机时代也只能用复杂物理模型进行模拟,来进行图像移动和重组。
目前,只有自20世纪末以来的传统CGI技术可以做到这一点。
当下的DeepFake技术还是不太能解决这个问题。数年来,DeepFaceLab也只发布一个仅仅能捕捉短发的「头部全体毛发」模型,发部还是僵硬的。这还是一款在业内领先的软件包。
最近,DFL的合作伙伴FaceSwap做出了BiseNet语义分割模型,能使用户在deepfake输出图像中包括到耳部和头发的图形细节呈现。
这两套软件包都来自2017年Deepfakes的源代码,在当时颇受争议。
就算现在DeepFake模型要呈现的头发图像非常短,输出结果的质量往往也很差,头像好像是叠加上去的一样,不像是浑然一体的图像一部分。
用GAN来生成毛发
目前,业界用来模拟人像使用最多的两种办法,一个是神经辐射场技术(Neural Radiance Fields)。NeRF可以从多个视角捕捉画面,之后可以将这些视角的3D成像封装在可探索的神经网络AI里。
另一种办法则是生成对抗网络(GAN),GAN在人类图像合成方面比NeRF更加先进,即使是NeRF在2020年才出现。
NeRF对3D几何图形的推测性理解,将使其能够以较高的保真度和一致性,对图案场景进行复制。哪怕当前没有施加物理模型的空间、或者准确来说和摄像头视角无关的变化,所收集的数据导致的变形都是一样的。
不过就目前来看,NeRF模拟人类发丝运动模拟的能力并不出色。
与NeRF不同,GAN天然就有个几乎致命的劣势。GAN的潜在空间并不会自然包含对3D信息的理解。
因此,3D可感知的GAN所生成的人脸合成图像,在近几年成了图像生成研究的热点问题。而2019年的InterFaceGAN是最主要的突破之一。
然而,即使是在InterFaceGAN展示上的精心挑选的图像结果,也都表明:在时间的一致性的表现上,神经网络AI生成发丝图像达到令人满意的一致性依然是一项艰巨的挑战,应用在VFX图像工作流程中仍然性能不可靠。
越来越明显的是,通过操控神经网络AI潜在空间进行的连贯视图生成,可能是一种类似炼金术的技术。
越来越多的论文中不得不另辟蹊径,将基于CGI的3D信息作为稳定的和规范化的约束,纳入GAN的工作流程。
CGI元素可以由3D形式的中间图形元表示,比方说「蒙皮多人线性模型」(SMPL,Skinned Multi-Person Linear Model)。
又或是应用和NeRF模式相近的3D推断技术得出,在这种技术中,图像的几何元素是从源图像和源视频中评估出来的。
就在本周,悉尼科技大学的ReLER实验室、AAII研究所、阿里达摩院以及浙江大学的研究者合作发布了一项论文,描述了用于3D可感知图像合成的「多视角连贯性生成性对抗网络」(MVCGAN)。

MVCGAN生成的头像
MVCGAN包含了一个「生成辐射场网络」(GRAF)AI,它可以在GAN中提供几何限制。理论上来讲,这个组合可以说实现了任何基于GAN的方法的最逼真虚拟头发输出结果。

MVCGAN生成的带发丝头像与其他模型生成头像的对比
从上图可以看出,在极端发丝参数下,除MVCGAN外,其他模型的图像结果都产生不可置信的扭曲
不过,在CGI工作流程中,以时间为基础的虚拟发丝重建依然是一项挑战。
因此业界尚无理由相信,传统的、基于几何图形的办法,能够在可预见将来能把具有时间一致性的发丝图形合成带入AI的潜在空间中。
用CNN生成稳定的虚拟头发数据
不过,瑞典查尔默斯理工学院三位研究人员即将发表的论文,或许还可以为「用神经网络生成人发图像」的研究提供新进展。
这篇题为《用卷积神经网络实时进行毛发滤镜》的论文即将在2022年5月份的重要学术会议「交互式3D图形和游戏盛会」上发表。
该系统由一个基于自动编码器的神经网络AI作为基础,该神经网络AI能够实时评估生成的虚拟发丝图案分辨率,包括发丝在虚拟空间中自动产生的阴影和头发厚度呈现。此自动编码器的随机数种子来自于由OpenGL几何体生成的有限随机数样本。
由这种方法途径,就可以只渲染有限数量的、具有随机透明度的样本,然后训练U-net来重建原始图像。
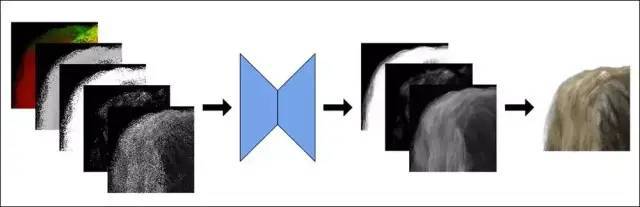
该神经网络在PyTorch上进行训练,可以在6-12小时内完成训练达到收敛,具体市场取决于神经网络体量和输入特征值的数量。然后将训练的参数(权重)用于图像系统的实时实现。
训练数据集,则是通过以随机距离、姿势以及不同的照明条件,来渲染数百张直发和波浪发型的实际图片而生成的。
样本中的发丝半透明度数值,是从在超采样分辨率条件下、以随机透明度渲染的图像平均求得的。
原始的高分辨率数据,先被降采样,以适应网络和硬件限制;然后在典型的自动编码器工作流程中进行上采样,以提高清晰度。

利用从训练模型派生的算法的「实时」软件,作为此AI模型的实时推理应用程序,采用了NVIDIA CUDA、cuDNN和OpenGL的混合。
初始输入特征值被转储到OpenGL的多重采样颜色缓冲区中,其处理结果在CNN中继续处理前会分流到cuDNN张量,然后这些张量将会被复制回「实时」OpenGL纹理中,以施加到最终图像中。
这个AI的实时运行硬件是一张NVIDIA RTX 2080显卡,产生的图像分辨率是1024x1024像素。
由于头发颜色的数据值与神经网络AI处理的最终值是完全分离的,因此改变头发颜色是一项容易的任务,尽管虚拟发丝的渐变和条纹等效果仍然将在未来构成挑战。

结论
探索自动编码器或GAN的潜在空间,仍然更类似于靠直觉的驾帆船,而非精确驾驶。只有在最近的时段,业界才开始看到在NeRF、GAN和非deepfake(2017)自动编码器框架等方法中生成「更简单」的几何形状(如人脸)的可靠结果。
人类头发显著的结构复杂性,加上需要结合当前物理模型和图像合成方法无法提供的其他特征,表明头发合成不太可能仍然只是一般面部合成模型中的一个集成组件。此任务需要复杂的、专用的和独立的神经网络AI来完成,即使这些神经网络最终可能会被纳入更广泛、更复杂的面部合成框架中。




















