不久之前,机器之心AI科技年会在线上召开。杜克大学电子计算机工程系教授陈怡然发表了主题演讲《高效人工智能系统的软硬件协同设计》。
演讲视频回顾:
https://www.bilibili.com/video/BV1yP4y1T7hq?spm_id_from=333.999.0.0
以下为陈怡然在机器之心 AI 科技年会上的演讲内容,机器之心做了不改变原意的编辑。
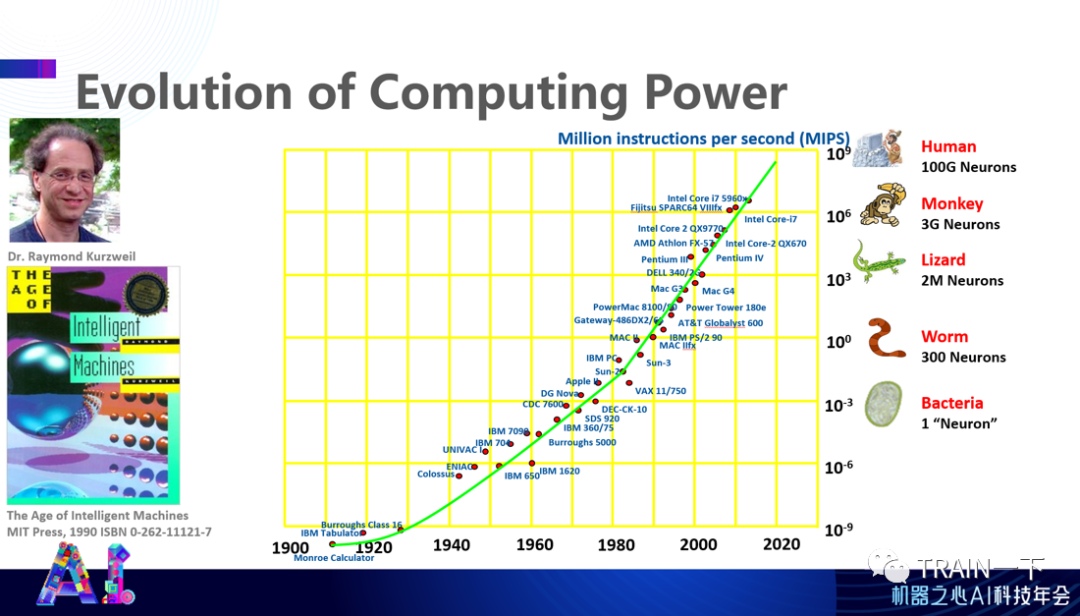
我经常用这张图,来源于大概 32 年前的一本书《The Age OF Intelligent Machines》,作者是 Kurzweil 博士 ,他当时就预言了未来人工智能所需要的算力发展。我们对这张图做了些延伸,单个器件上大概能够集成多少计算能力。过去 100 年,计算能力几乎呈指数增长趋势,到现在,比如今天英伟达发布会最新 GPU 的计算,包括上周苹果发布的 GPU 芯片,基本上可以带来超过一个人脑级别的计算能力,为我们带来了非常大的可能。
人工智能计算平台分很多种,从大家比较熟悉的 GPU、FPGA、ASIC 到新型架构,实际都遵循了一个原则:要么更高效,要么更专业需要更长时间,要么更灵活,不可能在多个维度达到统一,永远存在一个设计上的矛盾。
比如,在 GPU 上算力最高,功耗也最高。FPGA 上会实现一些非常容易可重构的计算,但能效比可能不是那么好。ASIC 能效比非常好,但需要更长的开发周期 ,基本上是对特定应用做设计,当出货量比较小的时候,不是特别有效。

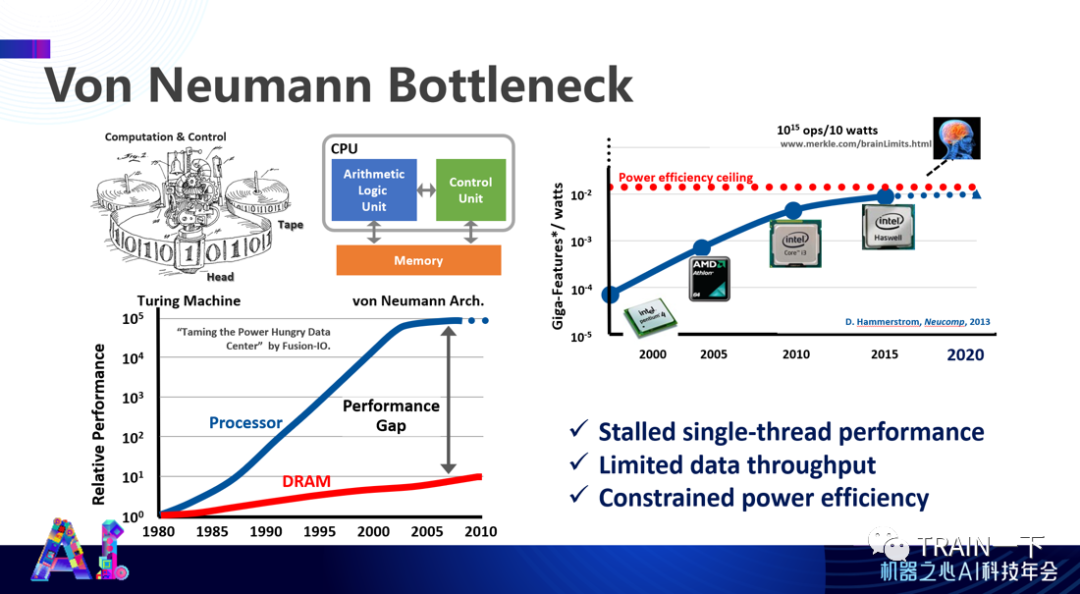
大家比较熟悉冯 · 诺伊曼瓶颈,实际上是说计算能力可以通过不断增加计算单元来实现,但最后瓶颈在于能不能把数据及时给到计算单元。过去四五十年,片上计算能力和片外数据通过存储带宽提供给片上的能力差距越来越大,也带来了 “内存墙” 的概念。当然,实际具体设计中,比如不能及时挪走产生的热量、不能无限制增大使用频率等,(这些)都迫使我们寻找新的计算设计。
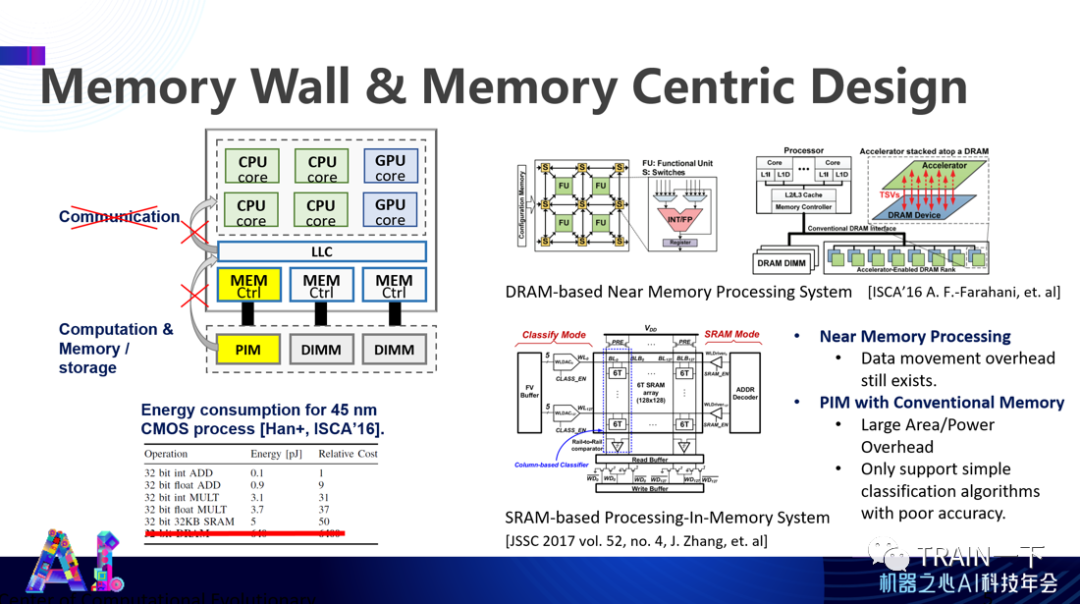
现在比较热门的是近存或存内计算设计,想法也非常简单,既然瓶颈来源于数据间流动,尤其是存储空间到计算空间的流动,能不能想一些办法让计算跟存储发生在同一个地方?这实际上正好和冯诺依曼体系相对,后者是将两者分开,这个要合在一起。
为什么可以这么做?因为新型计算,比如神经网络或图计算,经常有一方不变,另外一方不断变化的情况。比如 A 乘上 B,A 不断变化而 B 不变,这种情况下,可以在存储 B 的地方进行计算,不需要把数据挪来挪去。
大家进行了非常多尝试,比如用 DRAM 来做计存。最近,阿里好像也写了一篇文章讲了存内计算,把存储器设计成可以有计算单元,直接在里面进行相应计算,这都是一些有益的尝试。与在从外面拿到数据过来进行计算相比,这个计算能效强几千倍,是非常有希望的未来发展方向。
我们今天讲的一些内容与这些相关,包括存内计算深度学习加速器、模型方面的优化,分布式训练系统以及一些涉及神经网络架构设计自动化方面的操作。
当你看到存内计算时,第一个想法是把神经网络参数存到一个地方,数据进到这个地方后直接进行计算,避免数据搬运。一个比较常见的场景是,把这些参数存在一个特殊纳米芯片上,(纳米芯片里的)一些器件上的阻值可以通过电流或电压变化(而变化,进而可以被用)来进行编程,表现一个参数。
当涉及一个比较大的矩阵形式,所有输入跟所有输出可以在某些交叉节点上进行连接,非常像一个矩阵在神经网络里面的状态,所有输入相当于一个向量,向量乘以矩阵可以看做所有电压进行输入,电压经过电流产生一个合并的电流就是他们所有统计的和。这就以一个非常高效的方式实现了向量跟矩阵的相乘。
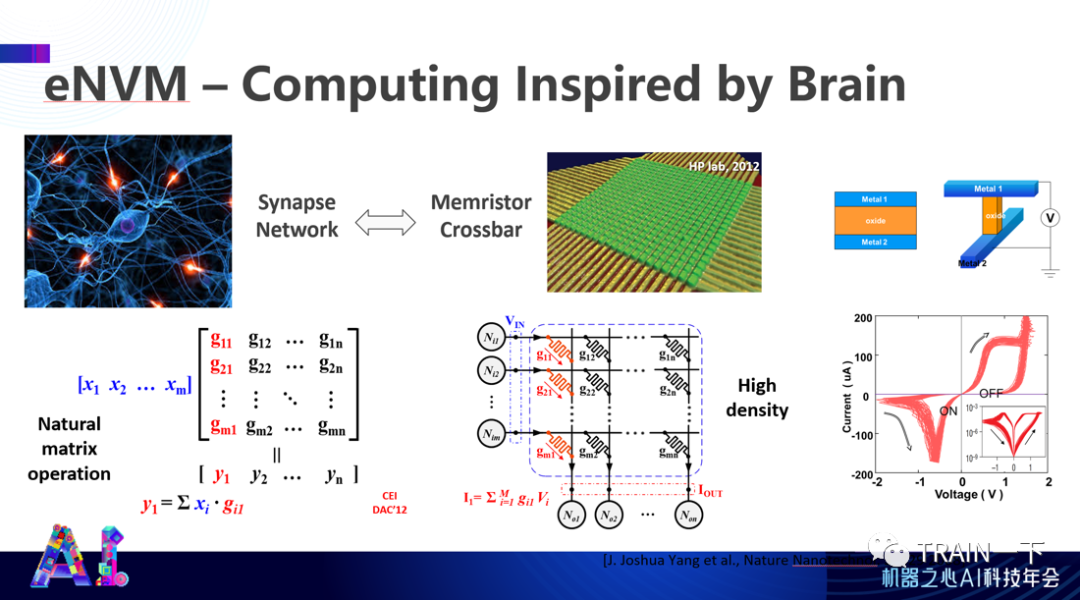
过去十几年,我们在杜克做了大量相关尝试,并设计了一些芯片。

2019 年我们在 VLSI 发了一篇文章,可以用新型存储器和传统 CMOS 进行连接,集成之后可以将比如卷积神经网络整个映射到这样一个矩阵状态里,同时可以选择精度,进行精度和能效之间的权衡(tradoff)。相比传统 CMOS 设计,性能最后可以得到几十倍的提高。
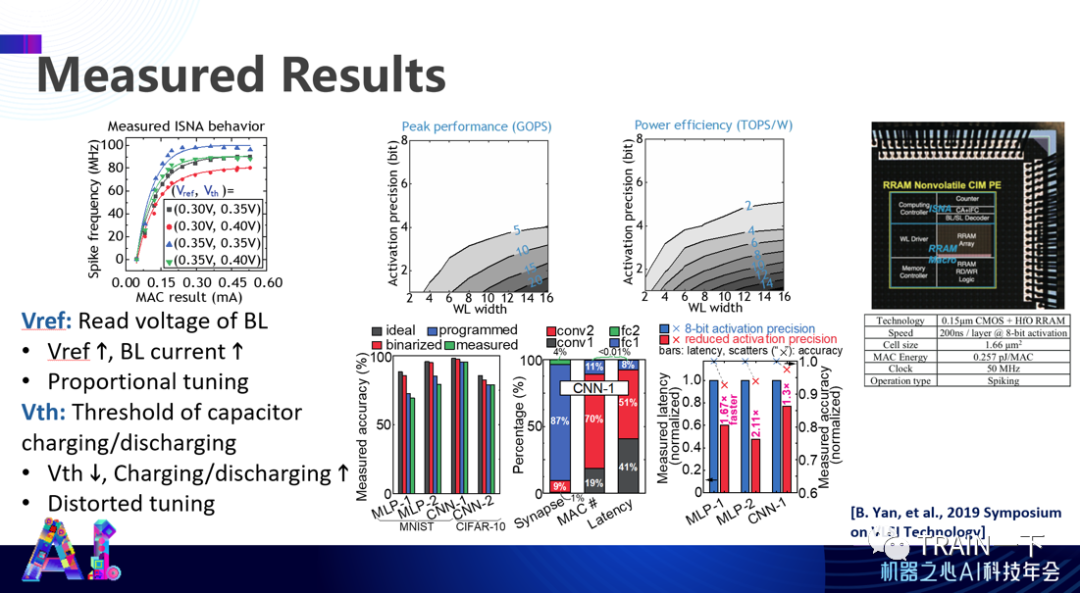
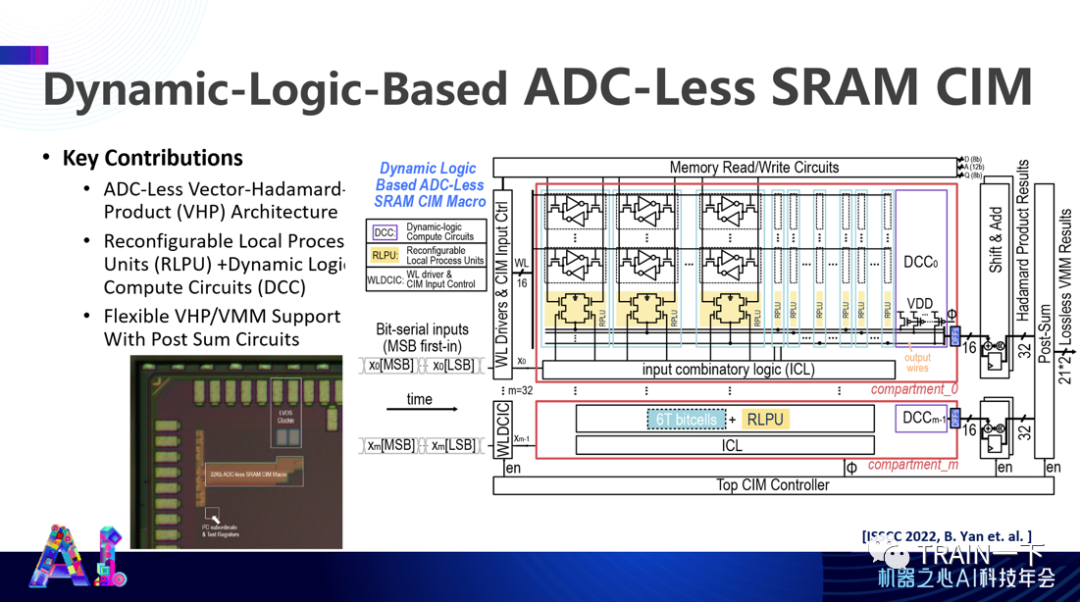
今年在 ISSCC 上我们也有另外一个工作,主要是我们毕业的学生燕博南在北大的一个课题小组工作,这个设计思想还可以放到传统 SRAM 。这个设计的一个特别之处在于,传统设计通过电阻进行参数表达,实际上是一种模拟计算方式。换句话说,组织上连续态表达一个参数,这就需要模拟到数字的转换,数模转换非常昂贵。而我们在 ISSCC 上的工作:ADC-Less SRAM 实际上是一个二值的整数表达,比如零和一,这就有可能去掉数模转换,直接实现数字状态下的计算。这是当时实现的一个技术突破。
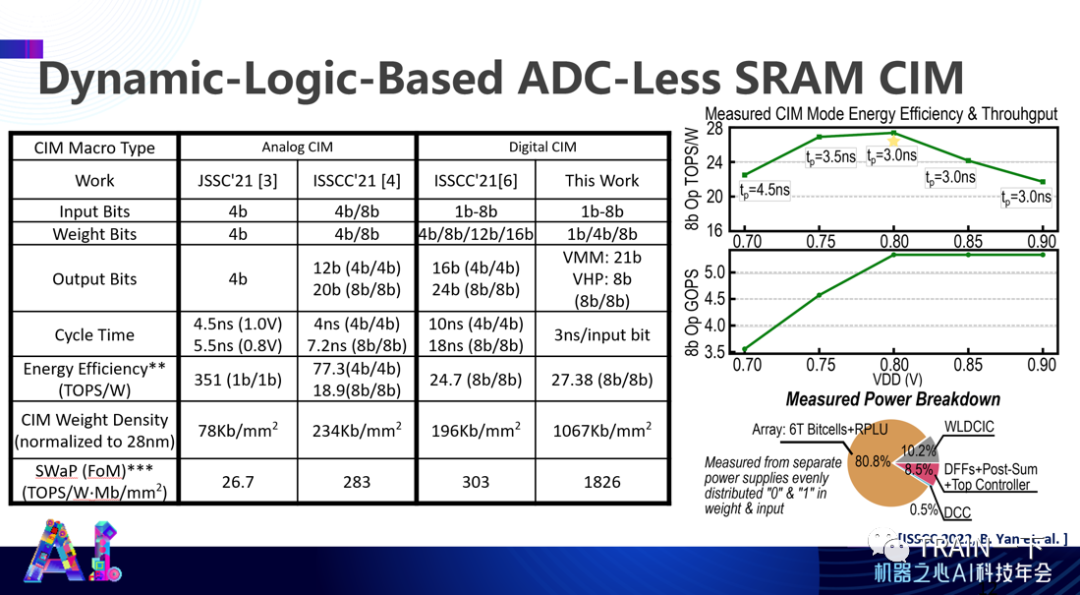
可以看到下面这张图 Digital CIM(最右边, This Work), 能效大概可以达到 27.4 ( TOPS/W,8 比特状态下 ),已经超过原先其他所有设计,整个 density 非常高,在 28 纳米工艺情况下,每平方毫米上差不多有上兆的晶体管。
除了电路,还要有架构跟编译器之间的支持才能够实现整个计算系统的设计。2014-2015 年之前,我们就开始做相关设计,比如设计编译器,找到可以用来加速的程序的一部分,同时在片上通过一些方式连接各种各样的阵列,把大的网络分成小的网络,或在不同网络层(layer)之间进行数值的转换。
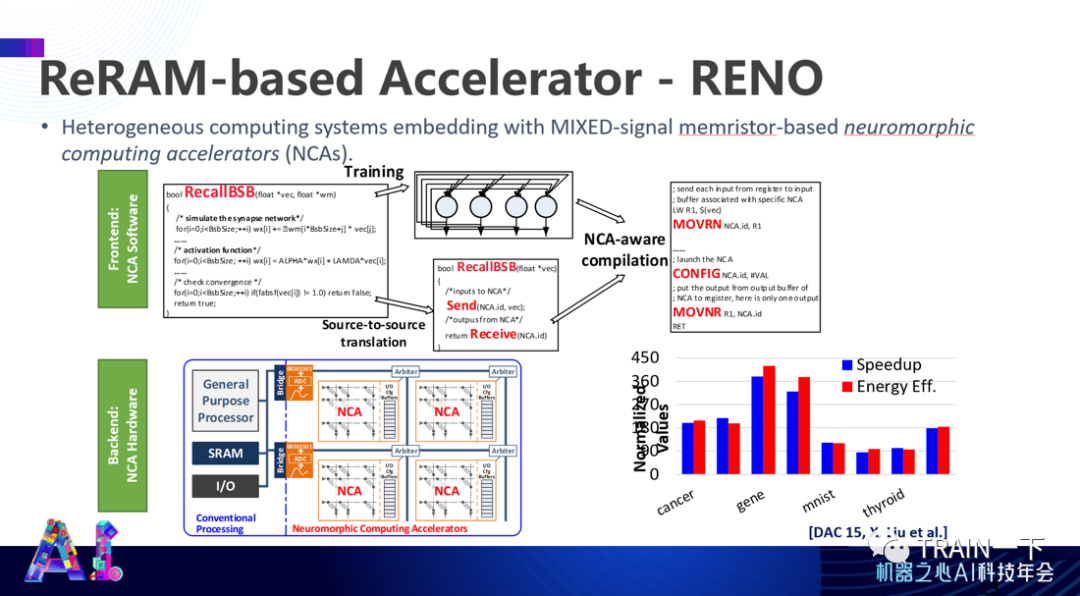
比较值得一提的是,我们经常会在一个大的网络里遇到很多阵列,至少存在两种网络并行计算的方式——数字并行和模型并行。所谓数字并行,是指有很多输入(input),些数据可以被并行的分到不同运算单元(PE)里面去。对于模型并行来说也是一样,大的模型可以被分块进行计算。
但是,这两种并行的方式并不排他。即使对于一个 Layer 来说,当你把这一个 layer 映射到不同 PE 上,在每个 PE 仍可能采用不同的并行方式。比如下图用黑点和白点来表达,大部分并行方式是通过模型并行的方式来操作,也有少部分是数字并行。
为什么会这样?因为只有集成不同并行的分布方式,才能使得在整个算力全部被表达的情况下,所有数字跟数字正好达到一个稳态平衡,整体能效最高。如果是单一表达,有的地方就空了或者算得比较慢,拖累了整个计算。这是 2019 年发表的文章 HyPar。
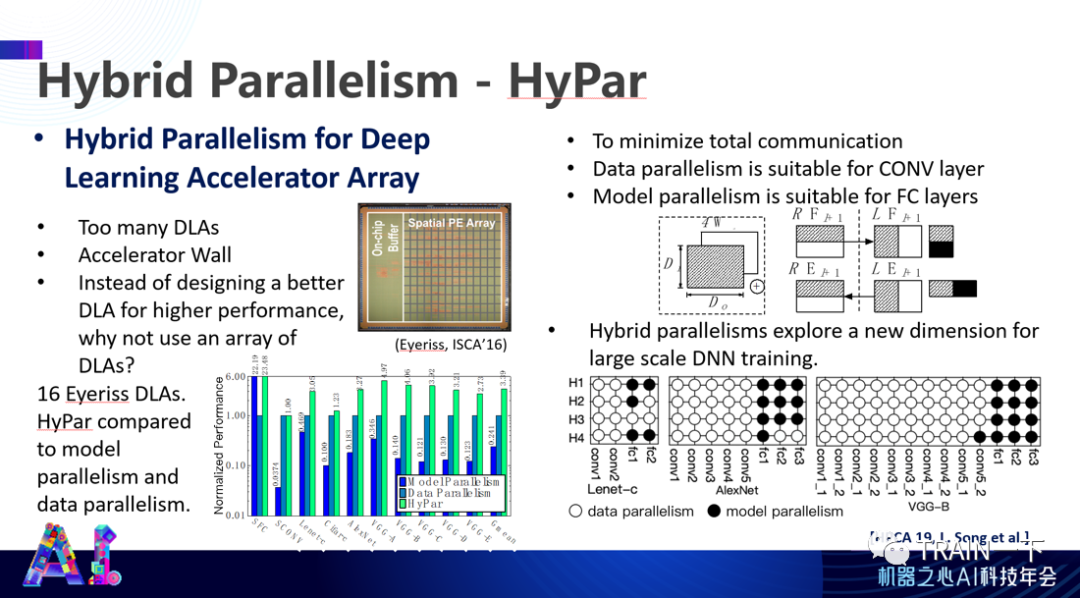
2020 年我们发现一个新问题,我们实际上没有太考虑卷积网络本身的表达,而你经常会在卷积层里一个层一个层地去计算,会有一些中间结果,直到最后才会被用到。这样一来会产生第三种并行方式,就是 Tensor 并行的方式,比如下图这种,输入和输出各有三种并行的可能。3 乘以 3,总共有 9 种表达方式。
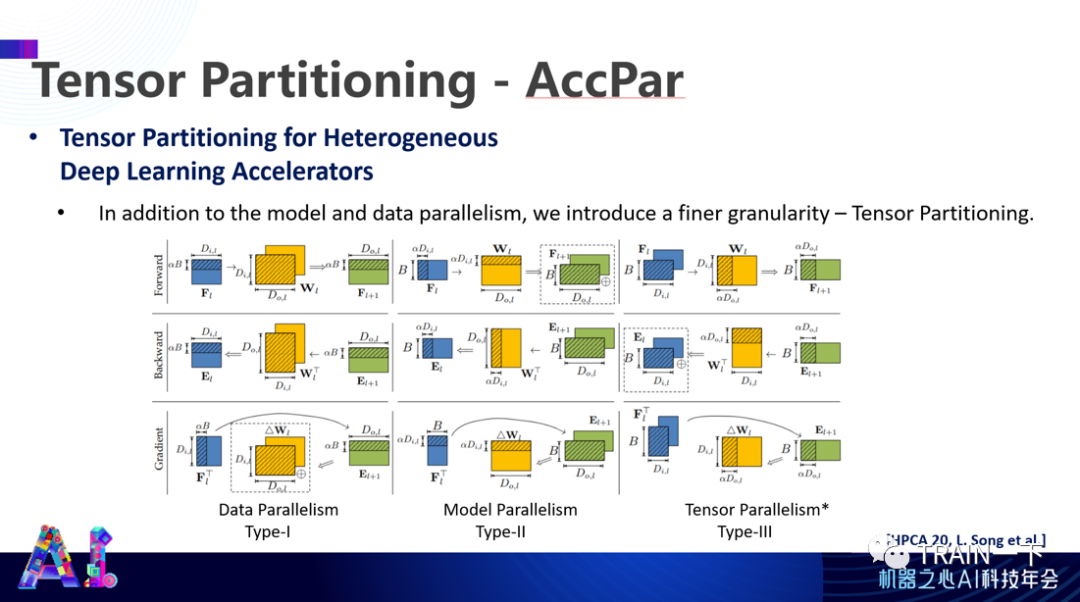
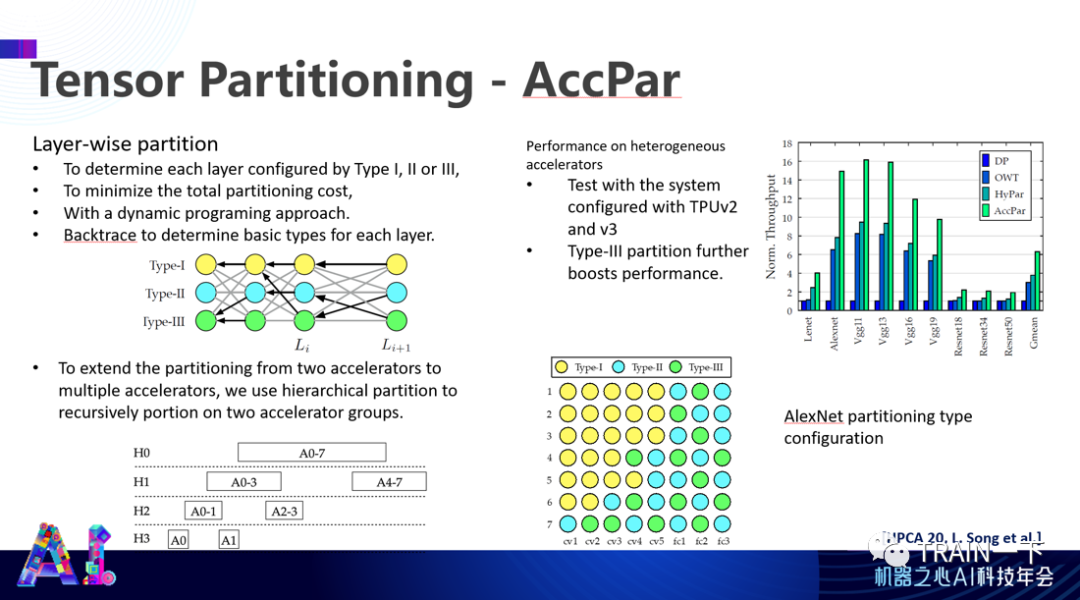
如果考虑到每个 PE 都有 9 种方式进行表达,就没有办法通过人工方式进行优化,必须通过自动化方式(比如线性规划)完成整个系统的表达。同时,你也不可能逐个去找这些表达方式,需要一些的层次化的方式。
比如,先有些大的区分,再由小的区分一直到最后单个表达。如果用三种颜色来做表达,会发现即使在一个层次的映射下也有不同 PE 有不同运行表达来满足整体上数据流动的最优。这样,能效就能再推进一倍。
同样的思路不仅仅可以用到深度学习里面。深度学习只是一个图计算特例。而任何可用图方式来表达数据流动的计算都是图计算,深度学习虽然很丰富但仍然只是图计算的一种特殊表达。所以,你可以用存内计算方式来进行图计算。
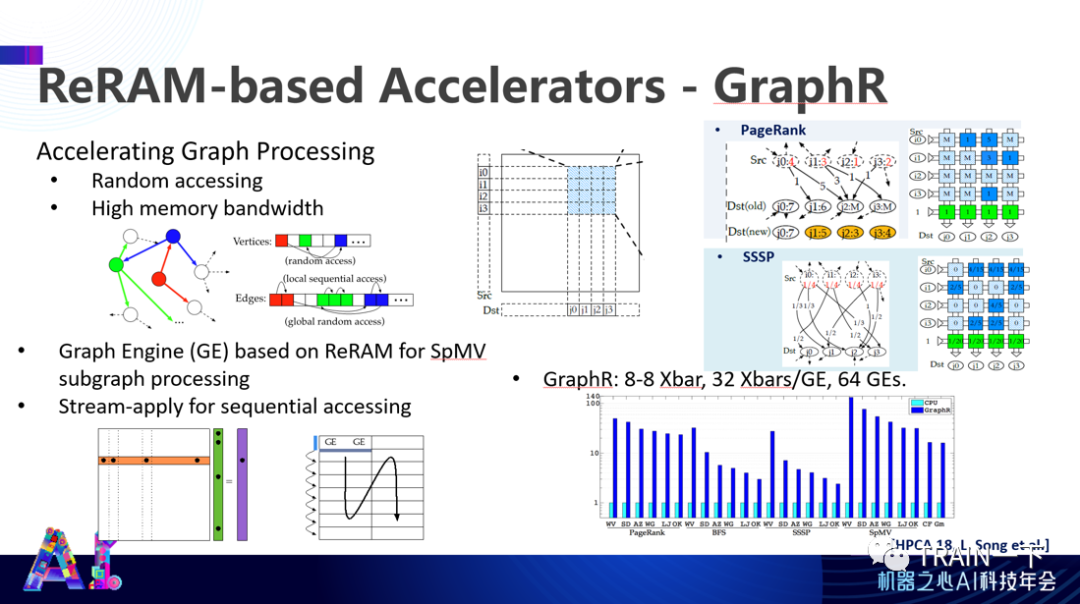
这是我们另外一个 HPCA 2018 上的工作。我们发现是图计算,尤其是深度优先或者网络优先搜索这类算法,可以把他们在矩阵上的表达,用图计算的方式来实现。相对于在传统 CPU 平台上的计算,能效会有上百倍提高。
讲完整个架构设计,在算法上如何继续优化计算能效?下一个例子是结构稀疏化。稀疏化早就被熟知,当神经网络的一些权重很小或者近乎于零,无论输入多大,对输出没有影响,这个时候,你根本不需要算结果,直接丢掉这个结果(其实是零)就可以了。
2016 年以前,所有针对神经网络的稀疏化操作基本都是非结构稀疏化,只要你看到一个零,就把它去掉。这就带来一个问题——所有数据在计算机存储的时候有一个 locality(局域性),因为有时域跟空域的局域性,当用到一个数,基本上会有一个预期,这个数字会不断被用到,或者存储在其周围的数也会在未来被不断用到。当你把很多零去掉后,会产生很多洞。当你找到一个数之后,会期待下一个数,但你根本没有存。整个缓存会陷入一个状态:不断到很远地方把数字弄过来,结果你发现这不是需要的,然后继续去找。
怎么解决这个问题?做稀疏化的时候,仍然希望把去掉的这些零或者计算,以某种局域性来做表达,比如整行或者整列全部去掉。这样就可以在满足存储局域性的前提下,仍然达到计算优化。

说起来容易,关键是怎么做?我们 2016 年 NeurIPS 有篇文章讲了结构稀疏化,这篇文章后来也变得很有名。(文章讲的是)基本上可以找到这些参数,对应了某种存储结构,这种结构使得这些数以一块一块方式进行存储。这样在清零时,把整个行或者列全部清零,仍然能够在满足优化条件的前提下同时满足 局域性。这个可以用在 CNN、LSTM、RNN 甚至一些更复杂计算。这项技术现在基本上已经是神经网络优化的一个标配。

另一个常用的神经网络优化是量化. 网络训练需要高精度,但推理时并不需要高精度。这就产生了一个很有趣的事情:究竟什么样的精度,优化是最好的,而且这个精度用什么方式去表达。
传统上,大家可以逐个去找最佳结果。比如,一个 bit、两个 bit、四个 bit...... 去找就对了。但你会发现,还要考虑到这个 bit 怎么在存储进行表达。比如,对这个 layer 来讲,当有某个 bit 于所有数字来说都是零,那就不需要存这一整个 bit。举个例子,只要保证你只要这四个 bit 里的第二个和第四个存在,而不是每个都需要,这就丰富了整个精度的优化。这也是我们第一次将结构稀疏化运用到 bit 水平的稀疏化研究上。

我们用 Group LASSO 的方式,把数据表达里面整个 column 或者整个结构为零的 bit 全部去掉,这样就极大降低存储成本。这是我们 2021 年的一篇文章。

再往下就是训练,这是一个很复杂的事情。我们经常教学生 loss function 要趋近于饱和。但在公司,永远不可能有足够的算力让你算到饱和,基本上给你一百台机器训练 24 小时,无论你训练成什么样,你都得结束,这使得训练本身要非常高效。
传统上我们采取分布式服务器的做法,把模型复制很多遍,但每个复制的模型只用一部分数据来训练。那么怎么保证最后得到的结果考虑到所有的数据?你就需要把这些神经网络在训练中禅城的梯度送到参数服务器里面,做平均之后再发回去来更新本地的神经网络。这就产生了一个问题:当节点服务器特别多的时候,最后整个系统就完全的被梯度传输产生的数据流所占据。
怎么办?我们后来发现,当参数足够多的情况下,产生的梯度会满足某一个分布,根本不需要传输原始数据,只需要算分布的一些参数和一些诸如数据多还是少之类的,把他们传过去,就可以完全在另外一端复制这个分布,得到相应结果。
我们在手机端就完成了这样一个操作,联合很多手机进行训练,同时还可以做推理。
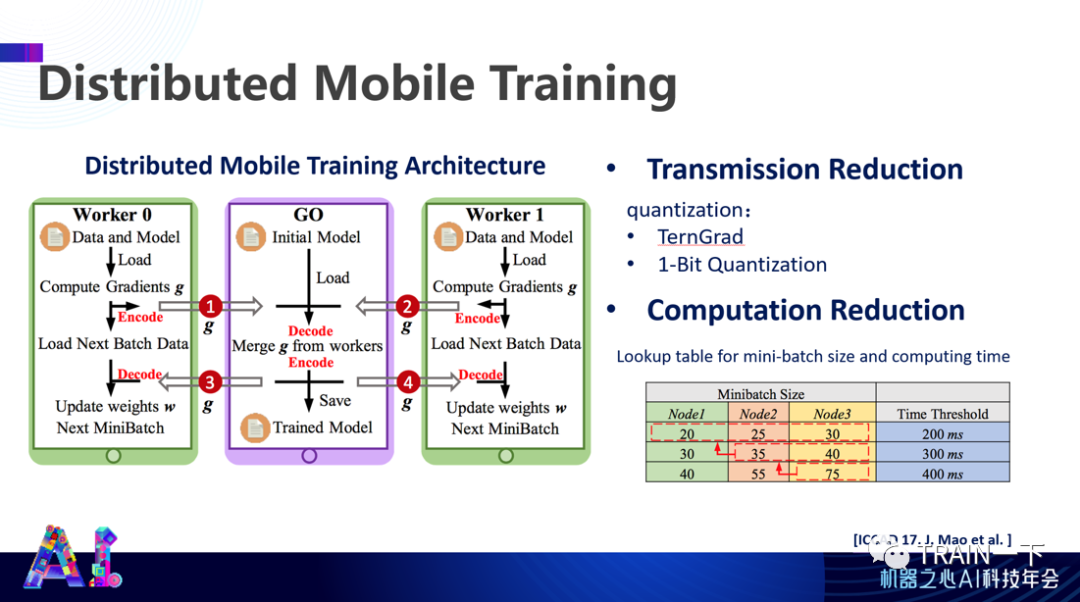
做推理的时候,我们采取了聚类的方式,将那些非零的数字尽量以行列变换的方式调整到一块儿,然后发到手机上集中进行计算,减少手机间的通信,提高运算效率。

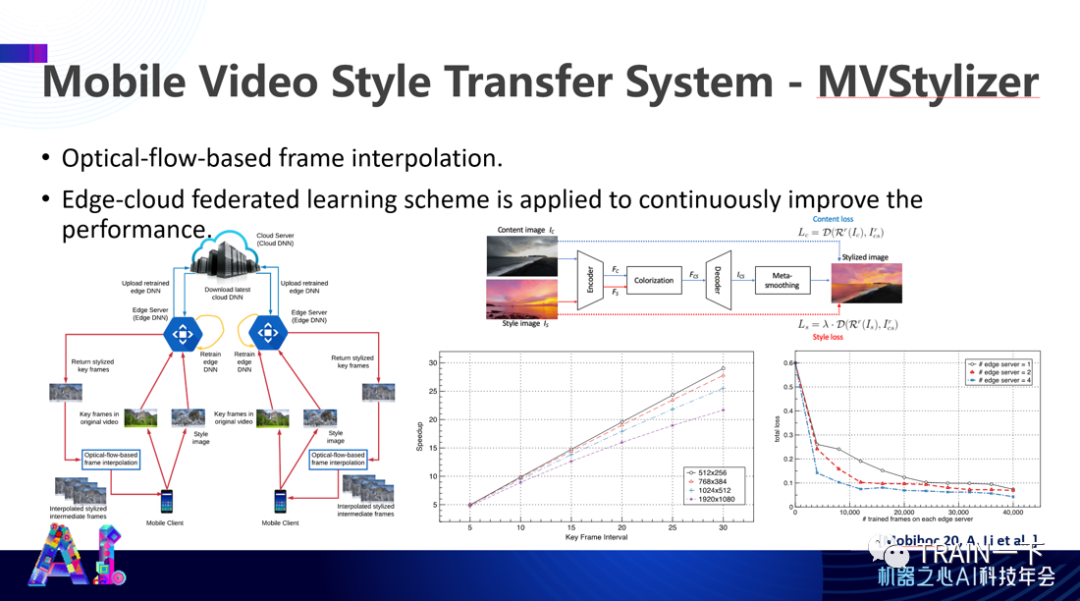
我们曾经跟一家公司做测试,在全球找了几千个 CDN 网络服务器,搞了一个 Style Transfer(风格转换)应用,通过分布计算跟表达完成整个计算,效果非常好。基本上可以即时通过手机跟服务器联动,完成整个训练和推理。
刚才讲了这么多,实际上有一个问题:所有这些东西都需要一些非常有经验、非常贵的工程师来设计相应的神经网络。这也是现在神经网络落地成本中非常大的一部分。我们可以通过自动化方式,比如增强学习、优化方式来优化整个神经网络,因为可以将它模拟成某种优化过程,但这些传统的优化过程非常昂贵。
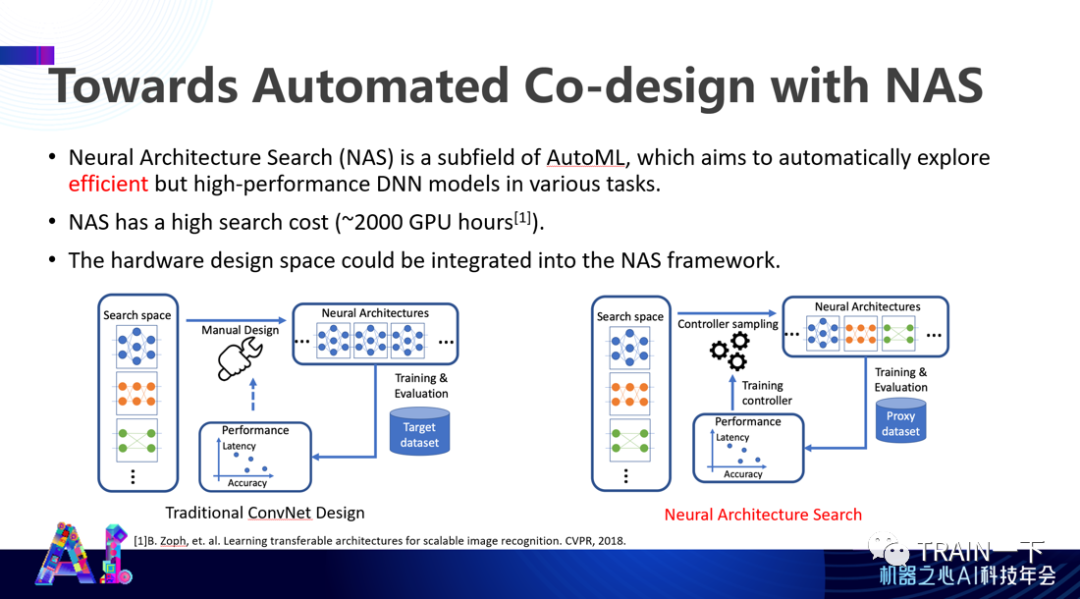
我们曾经想通过图表达的方式来做这个。通过一个有向图而且是一个没有环路的有向图来表达深度神经网络架构,它有很多个 cell,不同 cell 叠加在一起完成整个神经网络架构。我们要找的是这个 cell 里面的拓扑结构,来看最后这个神经网络设计是否满足要求。这就是一个对拓扑结构比较敏感的研究。
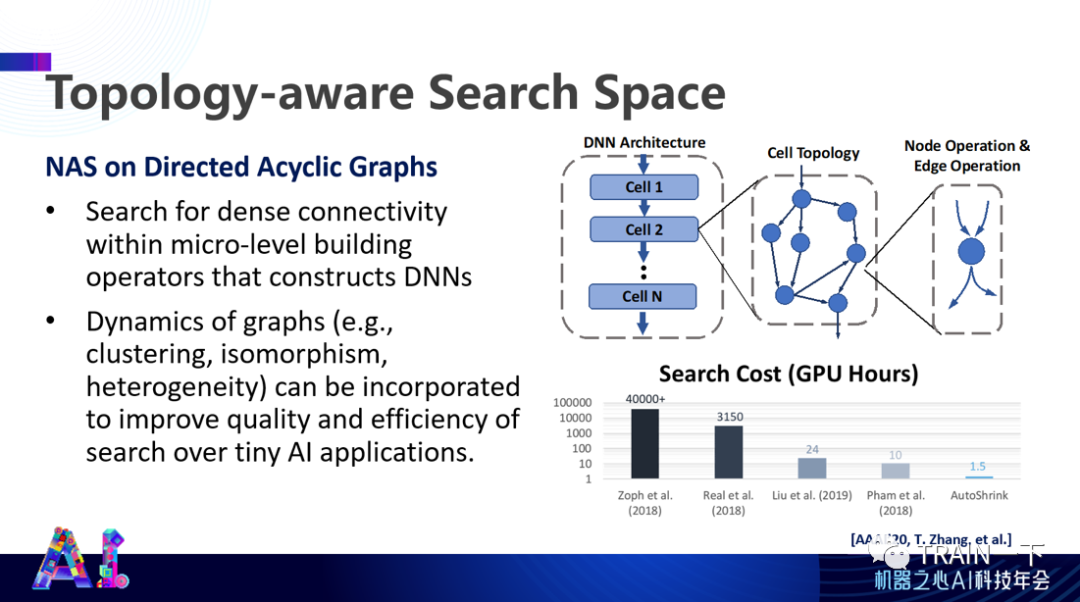
另外,你会发现:当做这些事情的时候,拓扑结构比较相似的神经网络的准确度也都差不多,有相关性,相关系数虽然不是 1,但基本上也是一个比较高的数。因此,可以通过架构预测这样一个架构是不是可以满足我们的性能要求,这种预测可以指引完成整个神经网络架构的搜索。
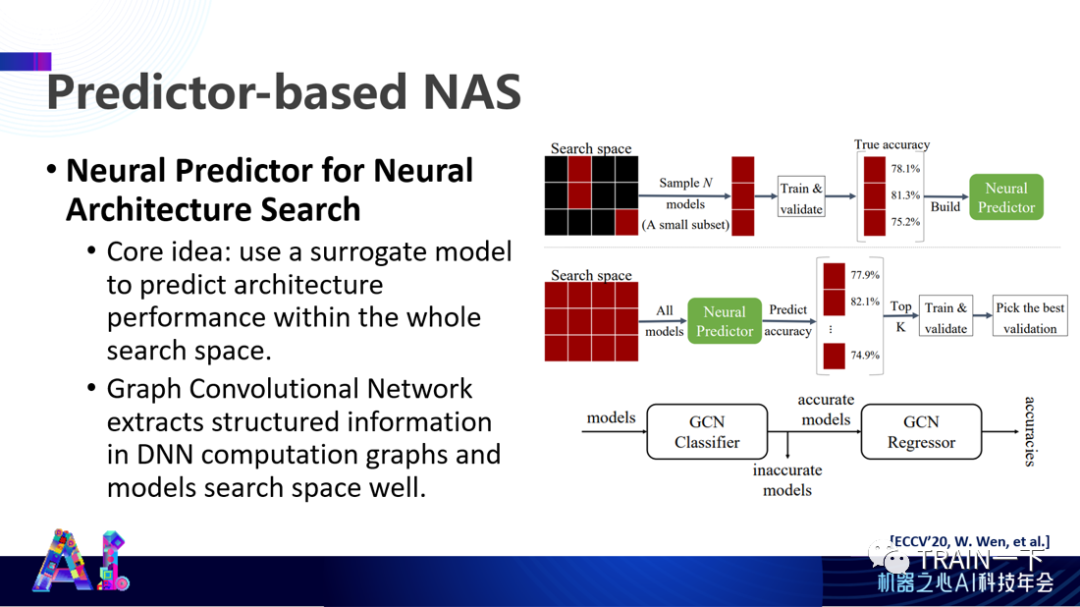
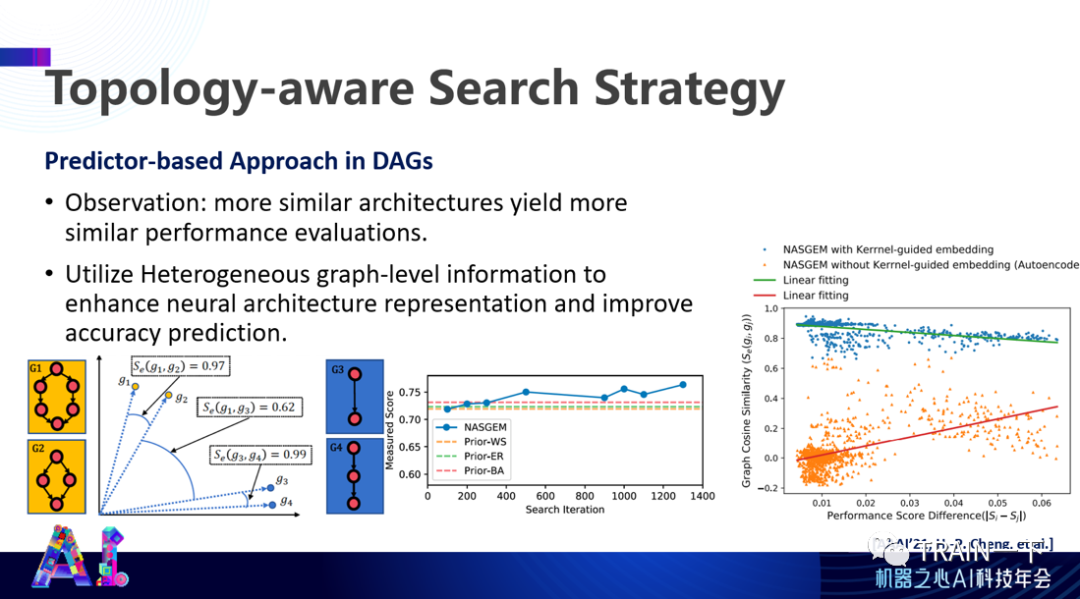
这是一些具体结果。我们把一些离散态的架构或者拓扑结构映射到连续态的空间里,产生向量之间的夹角(相似性)作为一个性能的关键表达,可以通过这样方式预测得到优化是什么样的,不断接近优化结果。
显然,这个方式是跟人的设计是相反的,人不是这么设计神经网络的。人是看哪里有小模型能不能满足要求,满足不了再往上加。我们也做过这样的尝试,叫 Automated network depth discovery , 设计一些规则,使得你可以从最小网络不断往上加,每个层里加不同 layer,或者加很多层,看到什么样架构最后满足这个要求。当然,你要设计一些具体规则或者做一些尝试。
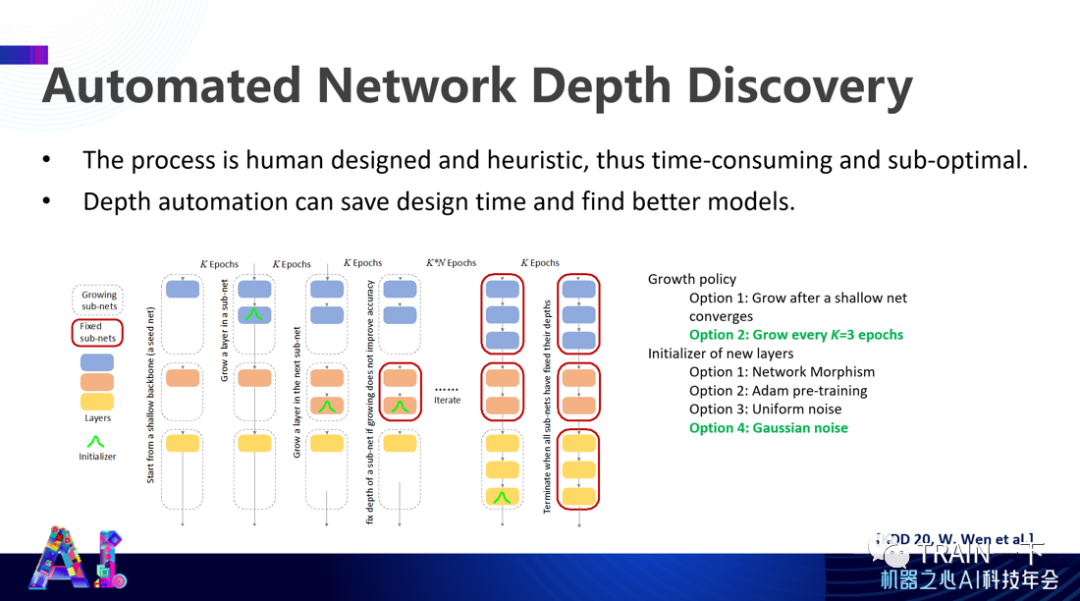
这些尝试还挺有意思。最后你总能优化到设计平衡前沿面的某一个点上,但没有办法固定优化到某一个点,你只能到这个前沿面上的某个点,慢慢让它自由流动。我们还是没有足够的理解,使得我们完全可以控制优化的方向跟范围。所以,这个工作还需要更深一步研究,我们只是证明了可行性,但没有对规则的完备性做更多研究。

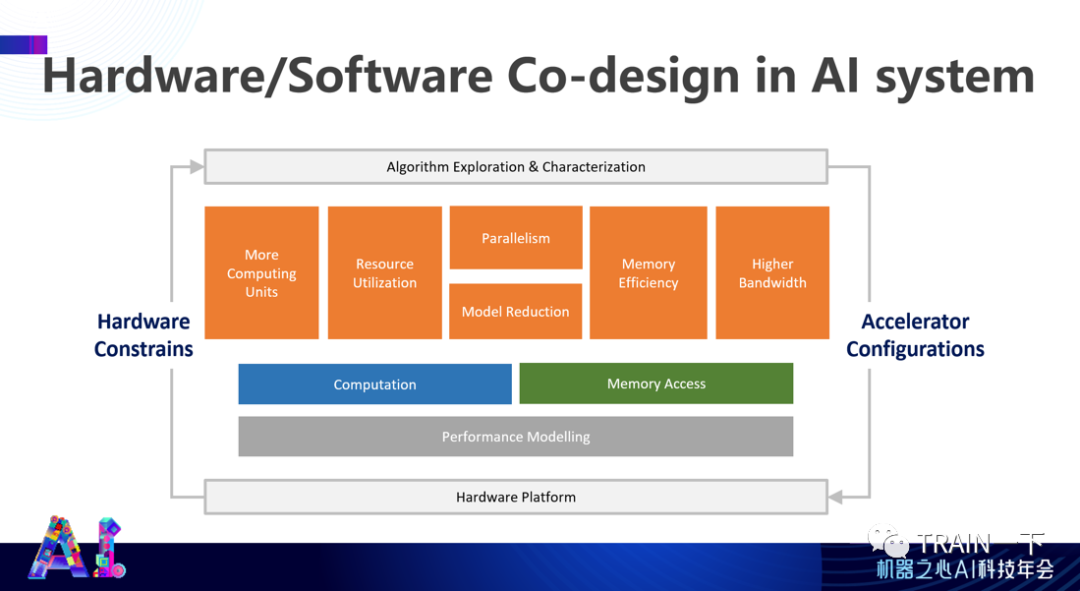
最后,硬件跟软件协同设计,有很多参数需要考虑,包括软硬协同、具体电路跟架构设计、以及算法本身针对硬件的优化。
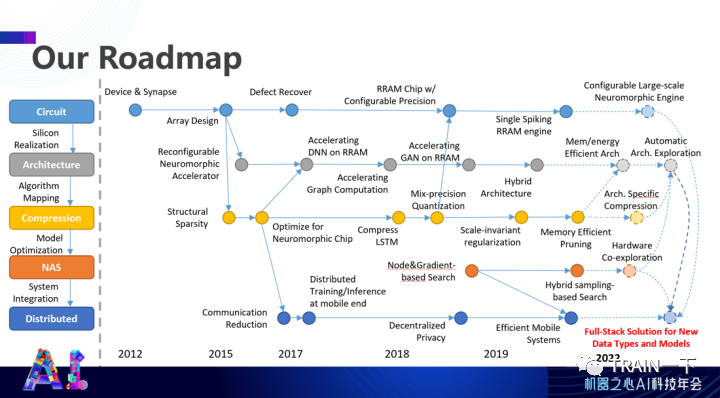
我们团队内部做了很多年的积累,从 2012 年开始研究神经网络在不同硬件上的表达,到后来做架构设计、分布式设计,到自动化设计等,做了非常多的尝试。大概看到了如何从一个最简单的表达,一直最后只需到按一个钮,完成了 AI 软硬件结合的建设。
谢谢大家!