MNIST 识别的准确率已经卷上 100% 了?近日,预印版平台 arXiv 中的一篇论文《Learning with Signatures》引起了人们的关注。
在这项工作中,作者研究了在学习环境中使用 Signature Transform。该论文提出了一个监督框架,使用很少的标签提供了最先进的分类准确性,无需信用分配(credit assignment),几乎没有过拟合。作者通过使用 Signature 和对数 Signature 来利用谐波分析工具,并将其用作评分函数 RMSE 和 MAE Signature 和对数 Signature。
研究人员使用一个封闭式方程来计算可能的最佳比例因子。最终实现的分类结果在 CPU 上的执行速度比其他方法快几个数量级。作者报告了在 AFHQ 数据集、Four Shapes、MNIST 和 CIFAR10 的结果,在所有任务上都实现了 100% 的准确率。
MNIST 被认为是机器学习的 Hello World,是大家入门时都会用到的数据集,其包含 7 万张手写数字图像,其中 6 万张用于训练,1 万用于测试。MNIST 中的图像是灰度的,分辨率仅 28×28 像素。尽管问题「简单」,但实现 100% 识别准确度的算法总是让人感觉不靠谱,让我们看看论文是怎么说的。

- 论文链接:https://arxiv.org/abs/2204.07953v1
- 代码:https://github.com/decurtoydiaz/learning_with_signatures
借助Signature,少量标记样本媲美深度学习收益
在上个世纪,让计算机具有学习能力一直是重要的研究方向。近年来,使用深度学习中的有监督和无监督学习已经成为 SOTA 解决方案代表。基于模型的解决方案占主导地位的领域已迅速转变为数据驱动的框架,并取得了前所未有的成功。然而,由于此类模型的超参数数量多,难以解释,且其鲁棒性缺乏收敛理论保证,因此在一些领域进展停滞不前。
近年来将 Signature Transform 集成到学习框架中已经取得不错进展,其主要作为 ML 范式中的特征提取器或作为深度网络内的池化层。由于 Signature 良好理论特性,不少研究者将其作为构建学习问题的一种方式。然而,关于 Signature 的通用框架尚未建立,这主要是因为没有一个正确定义的得分函数来指导学习机制。
近日,有研究者提出通过使用 Signature Transform 来研究一种新型的学习机制,这是一种最近开发的谐波分析工具,它提供了对不规则采样数据流的紧凑丰富的描述。研究者探索了这样一个观点,即通过将数据转换为一个紧凑而完整的域,该研究可以通过使用很少的标记样本来获得与深度学习相同的经验收益。
此外,Signature 的通用非线性属性,不受时间重新参数化影响,使其成为更适合计算机推理知识替代表示的理想候选者。毕竟,人类不需要成千上万的例子来学习简单的概念,而只需要少量精心挑选的例子来快速正确地猜测。Signatures 的出现实现了这一目标,计算机可以迅速地推断出信息,因为其表示形式容易理解、丰富且完整。不过这还需要一个得分函数,就像损失和信用分配给传统的学习框架提供了将优化引导到一个可能很好的解决方案的能力一样。
该研究使用 RMSE、MAE Signature 和 log-signature 来评估图像分布之间的视觉相似性,以确定 GAN 收敛。从另一个角度来看,RMSE、MAE Signature 和对数 signature 确实是正确定义的得分函数,可用于分类、聚类等任务。在此假设下,本研究旨在进一步研究这种学习框架的行为、性质及其在若干任务上的泛化能力。
在 Signature 情况下,该研究建议使用基于 Signature Transform 相似性度量。该框架在 CPU 上的工作速度比深度学习方法快几个数量级,并且避免了在 GPU 上以高计算和环境成本完成的数百万超参数的繁琐信用分配。这些度量可以捕获详细的视觉线索,它们可用于内存占用非常小、执行速度快、准确度高的分类任务。
关于信用分配,例如反向传播,一直是现代自动化学习技术的基础;仅通过一次(pass)(即使用一个 epoch)从数据中提取所有后续信息在理论上是可行的。但实际上,由于学习机制的限制,很多方法使用不止一次的训练数据传递,这些特点不能归结为其优势。给定一个适当的得分函数,signatures 提供一种紧凑表示,计算机可以使用它来推断细粒度信息,而无需使用反向传播,因此避免优化数百万个超参数。
与其他训练机制相比,使用带有 signatures 的学习具有计算优势,因为标记示例的数量可以大大减少,并且训练被逐元素均值所取代,这赋予了良好泛化所需的统计鲁棒性。
给定一组 signature 顺序为
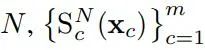
元素均值定义为:
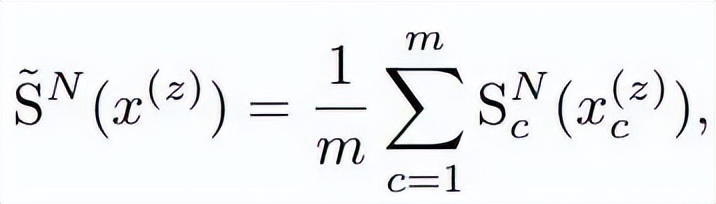
则 RMSE 和 MAE signature 可定义为:
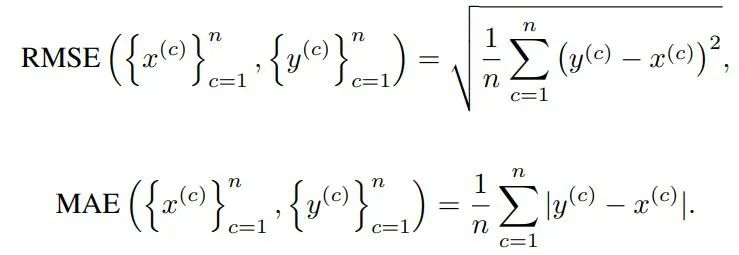
使用 Signature 的 Few-shot 分类
作者认为,可以使用 signature 和定义分数函数对比测试样本(在可选的增强和计算元素平均值之后),从而实现 Few-shot 样本分类。实现极高分类准确率所需的 Signature 数量可能取决于任务的复杂性,某些类别可能只需要一个,具有更多可变性的类别可能需要数万到数千个训练样本。
为了进一步研究通过对同一测试实例的多个变换版本进行平均而引入的多重性的影响,作者使用特定增强技术(如随机对比)展示了可视化结果。

)图 1:在 AFHQ 的 300 张图像上带有签名的 PCA 自适应 t-SNE,类别:猫(红色)、狗(绿色)和野生(蓝色)。
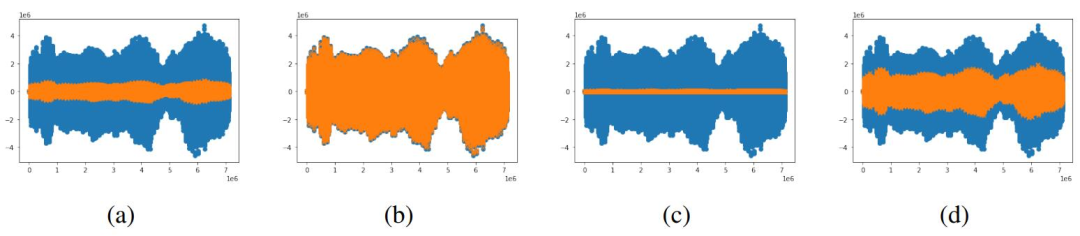
图 2:给定 AFQH 样本的特征变换光谱及其对应变换与随机对比度 (a)-(d) 的比较。
通常,人们会认为在训练集上实现 100% 准确率肯定是出现了数据泄露问题。对于该研究,社交网络中的质疑声较多。
在 reddit 上,有网友表示:「MNIST 数据集中有几个图人类的分类方式与标签不同。100% 的测试集准确率表明网络实际上比那些错误率的 99.7% 的网络还要差。所以正如其他人所说,100% 准确率的数字非常可疑。」