前言
因为业务需要,很多文件需要在前端实现预览,今天就来了解一下吧。
Demo地址:https://zhuye1993.github.io/file-view/dist/index.html
实现方案
找了网上的实现方案,效果看起来不错,放在下面的表格里,里面有一些是可以直接通过npm在vue中引入使用。
文档格式 | 老的开源组件 | 替代开源组件 |
word(docx) | mammoth | docx-preview(npm) |
powerpoint(pptx) | pptxjs | pptxjs改造开发 |
excel(xlsx) | sheetjs、handsontable | exceljs(npm)、handsontable(npm)(npm) |
pdf(pdf) | pdfjs | pdfjs(npm) |
图片 | jquery.verySimpleImageViewer | v-viewer(npm) |
docx文件实现前端预览
代码实现
- 首先npm i docx-preview
- 引入renderAsync方法
- 将blob数据流传入方法中,渲染word文档
import { defaultOptions, renderAsync } from "docx-preview";
renderAsync(buffer, document.getElementById("container"), null,
options: {
className: string = "docx", // 默认和文档样式类的类名/前缀
inWrapper: boolean = true, // 启用围绕文档内容渲染包装器
ignoreWidth: boolean = false, // 禁止页面渲染宽度
ignoreHeight: boolean = false, // 禁止页面渲染高度
ignoreFonts: boolean = false, // 禁止字体渲染
breakPages: boolean = true, // 在分页符上启用分页
ignoreLastRenderedPageBreak: boolean = true,//禁用lastRenderedPageBreak元素的分页
experimental: boolean = false, //启用实验性功能(制表符停止计算)
trimXmlDeclaration: boolean = true, //如果为真,xml声明将在解析之前从xml文档中删除
debug: boolean = false, // 启用额外的日志记录
}
);
实现效果:
pdf实现前端预览
代码实现
- 首先npm i pdfjs-dist
- 设置PDFJS.GlobalWorkerOptions.workerSrc的地址
- 通过PDFJS.getDocument处理pdf数据,返回一个对象pdfDoc
- 通过pdfDoc.getPage单独获取第1页的数据
- 创建一个dom元素,设置元素的画布属性
- 通过page.render方法,将数据渲染到画布上
import * as PDFJS from "pdfjs-dist/legacy/build/pdf";
// 设置pdf.worker.js文件的引入地址
PDFJS.GlobalWorkerOptions.workerSrc = require("pdfjs-dist/legacy/build/pdf.worker.entry.js");
// data是一个ArrayBuffer格式,也是一个buffer流的数据
PDFJS.getDocument(data).promise.then(pdfDoc=>{
const numPages = pdfDoc.numPages; // pdf的总页数
// 获取第1页的数据
pdfDoc.getPage(1).then(page =>{
// 设置canvas相关的属性
const canvas = document.getElementById("the_canvas");
const ctx = canvas.getContext("2d");
const dpr = window.devicePixelRatio || 1;
const bsr =
ctx.webkitBackingStorePixelRatio ||
ctx.mozBackingStorePixelRatio ||
ctx.msBackingStorePixelRatio ||
ctx.oBackingStorePixelRatio ||
ctx.backingStorePixelRatio ||
1;
const ratio = dpr / bsr;
const viewport = page.getViewport({ scale: 1 });
canvas.width = viewport.width * ratio;
canvas.height = viewport.height * ratio;
canvas.style.width = viewport.width + "px";
canvas.style.height = viewport.height + "px";
ctx.setTransform(ratio, 0, 0, ratio, 0, 0);
const renderContext = {
canvasContext: ctx,
viewport: viewport,
};
// 数据渲染到canvas画布上
page.render(renderContext);
})
})
实现效果:

excel实现前端预览
代码实现
- 下载exceljs、handsontable的库
- 通过exceljs读取到文件的数据
- 通过workbook.getWorksheet方法获取到每一个工作表的数据,将数据处理成一个二维数组的数据
- 引入@handsontable/vue的组件HotTable
- 通过settings属性,将一些配置参数和二维数组数据传入组件,渲染成excel样式,实现预览
// 加载excel的数据
(new ExcelJS.Workbook().xlsx.load(buffer)).then(workbook=>{
// 获取excel的第一页的数据
const ws = workbook.getWorksheet(1);
// 获取每一行的数据
const data = ws.getRows(1, ws.actualRowCount);
})
// 渲染页面
import { HotTable } from "@handsontable/vue";
<hot-table :settings="hotSettings"></hot-table>
hotSettings = {
language: "zh-CN",
readOnly: true,
data: this.data,
cell: this.cell,
mergeCells: this.merge,
colHeaders: true,
rowHeaders: true,
height: "calc(100vh - 107px)",
// contextMenu: true,
// manualRowMove: true,
// 关闭外部点击取消选中时间的行为
outsideClickDeselects: false,
// fillHandle: {
// direction: 'vertical',
// autoInsertRow: true
// },
// afterSelectionEnd: this.afterSelectionEnd,
// bindRowsWithHeaders: 'strict',
licenseKey: "non-commercial-and-evaluation"
}
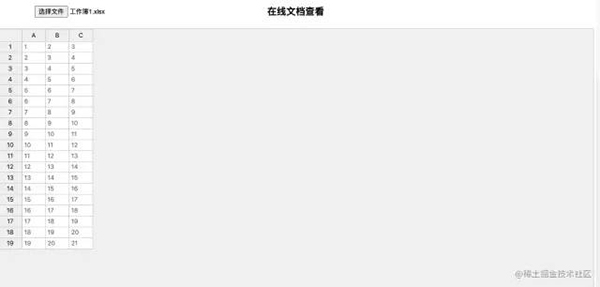
实现效果
pptx的前端预览
主要是通过jszip库,加载二进制文件,再经过一些列处理处理转换实现预览效果,实现起来比较麻烦,就不贴代码了,感兴趣的可以下载代码查看。
实现效果

总结
主要介绍了word、excel、pdf文件实现预览的方式,前端实现预览最好的效果还是PDF,不会出现一些文字错乱和乱码的问题,所以一般好的方案就是后端配合将不同格式的文件转换成pdf,再由前端实现预览效果,将会保留文件的一些样式的效果,对于图片、txt文件的实现,感兴趣的可以看下代码。
代码地址