












今天给大家来分享一个知识,那就是平时我们开发系统的时候,如何运用 Ehcache 这款本地缓存框架,把我们的查询性能大幅度提升优化,甚至让很多查询操作性能提升到 100 倍以上,下面就来讲讲这个话题。
业务场景
首先给大家引入一个场景,就是假设咱们写的一套 Java 系统要跑一个几百行的大 SQL 从 MySQL 里查询数据,这个查询是不是会速度非常的慢?
那肯定是了,这种几百行大 SQL 往往都是那种超级复杂的查询,可能涉及到了多表的关联,也有的是那种数据指标的查询,当然这种数据指标的查询其实是会常见一些,就是针对各种数据表关联起来查询和统计一些指标。
一般来说的话,遇到这种超级大 SQL,往往会导致查询 MySQL 性能很差,一般跑个 1s 甚至好几秒那是很常见的了。
比如下图:

所以 往往对于这种场景来说,如果想要优化一下这个查询的性能,我们一般会用缓存。
也就是说,这一次用几百行 SQL 语句查询出了结果,好不容易用了几秒钟特别特别慢,接着其实就把这个结果缓存起来,下次请求过来,直接就用这个缓存里的数据拿出来返回就可以了,从缓存里读结果以及返回,最多就是个 1ms 的事儿,根本不用几秒那么漫长了。
如何通过缓存优化查询接口
那么问题来了,这个缓存的结果是放哪里?可能很多兄弟说可以放 Redis 里啊!但是,一定要每次用缓存就立马上 Redis 吗?
毕竟 Redis 还得额外部署集群,一旦引入 Redis,你还得考虑 Redis 是否会有故障,他的一些接入问题,以及跟 Redis 进行网络通信毕竟也是要耗时的。
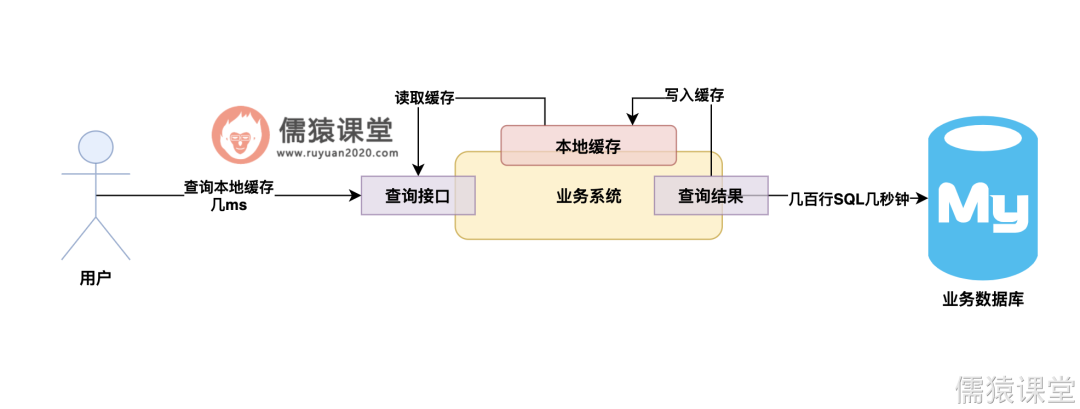
所以说,其实咱们优先啊,可以先上本地缓存,也就是说,在业务系统运行的 JVM 的堆内存里,来缓存我们的查询结果,下次请求来了,就从本地缓存里取出来直接返回就可以了。
如下图:
基于大数据离线平台进行缓存预热
那么下一个问题又来了,很多查询他可能当天第一次查的时候,本地缓存里是没有的,还是得去 MySQL 里花费几秒钟来查询,查完了以后才能放入到本地缓存里去,那这样岂不是每天都有一些人第一次查询很慢很慢吗?
有没有更好的办法呢?当然有了,那就是缓存预热,我们的业务系统可以把每天的查询请求和参数都记录下来。
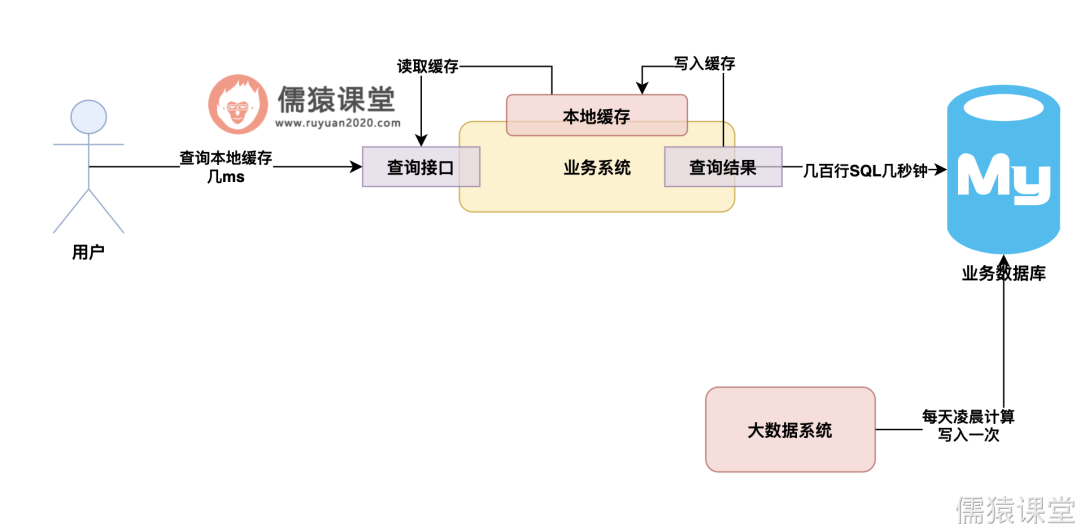
对于一些数据报表的复杂查询,其实每天的查询条件都是差不多的,只不过是当天的日期会有变化而已,另外就是对于一些数据报表的数据,往往是通过大数据平台进行离线计算的。
啥叫做离线计算呢?就是说可能有一个大数据系统每天凌晨的时候会把昨天的数据算一遍,算好的数据结果写入到 MySQL 里去,然后每天更新数据就这一次,接着当天就不更新数据了。
如下图:
然后呢,用户每天都会对我们的系统发起很多次复杂报表查询语句,但是这个 SQL 多表关联的一些逻辑,以及附加的一些查询条件几乎都是有规律的是差不多的,就是每天选择的当天日期是不太一样的。
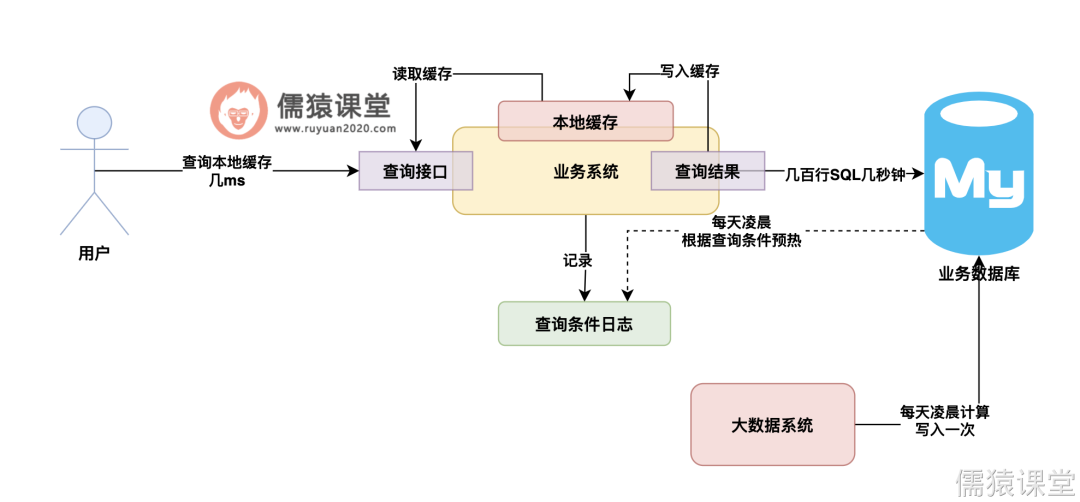
所以此时我们就可以把这些查询条件记录下来,然后每天凌晨的时候,趁着大家都睡觉了,就根据经常查询的条件和当天日期,提前去查询数据,查询结果提前写入本地缓存。
这样用户第一次来访问,就可以直接从本地缓存里拿到最新的数据了,如下图:
本地缓存框架:Ehcache
接着给大家讲讲咱们常用的本地缓存框架,Ehcache,这是大名鼎鼎的一个本地缓存框架,基本上 Ehcache 和 Guava 两款本地缓存框架,用的是最多的,我们以 Ehcache 举例来讲讲本地缓存框架是怎么用的。
首先得在咱们的项目 pom.xml 里引入对应的依赖,如下所示:
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.10.2</version>
</dependency>
接着就恶意引入一个 ehcache.xml 这种配置文件,对我们的缓存框架进行一定的配置了。
如下所示:
下面给大家解释一下 ehcache 框架运行起来以后上述那些参数对他的影响,首先 maxElementsInMemory 说的就是他在内存里可以缓存多少条数据。
eternal 意思是说这个缓存是否是永久有效的,如果要是永久有效了那么 timeToLiveSeconds 也就没用了。
但是如果不是永久有效的,就可以设置 timeToLiveSeconds 了,比如说可以设置缓存数据生存 24 小时,然后就自动过期,接着就必须要强制从数据库里来查询了。
overflowToDisk 是说如果缓存的数据要是超过了 maxElementsInMemory 的时候,是不是把多余的数据刷写到磁盘里去。
diskPersistent 是说在 JVM 重启的时候,要不要把内存里缓存的数据刷写到磁盘里去,然后 JVM 重启后再把磁盘里的数据恢复到内存里来,这俩参数,如果要是缓存的数据特别多的话,其实还是可以开启的。
一方面是内存缓存不下了可以刷写到磁盘去,一方面是内存里的数据重启的时候还是持久化一下,然后重新加载到内存里来。
还有一个是 memoryStoreEvictionPolixy 是缓存的回收策略,因为如果要是缓存数据量过多了,导致内存和磁盘都放不下了,这个时候就必须回收掉一部分的数据了,一般都是用 LRU,最近最少使用策略来回收的。
下面是 Ehcache 在代码里的使用示例:
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd">
<cache name="report"
maxElementsInMemory="1000"
eternal="false"
timeToLiveSeconds="86400"
overflowToDisk="false"
disPersistent="false"
memoryStoreEvictionPolicy="LRU" />
</ehcache>
希望今天给大家分享的本地缓存知识可以帮助到大家以后遇到类似的复杂报表数据查询场景的时候,可以利用这个知识点去优化自己系统的性能!























