














本文出自ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
【本期看点】
- 让你意想不到的 PNG 工作方式。
- 详解 MPEG 十八代隐秘关系。
- AV1 | H.266 王座之战,谁才是最终赢家。
- 不妨走走未曾设想的医学道路。
- 细胞神经网络也可以很疯狂。
- 懂了!原来这就是人眼视觉系统(HVS)。
【技术DNA】
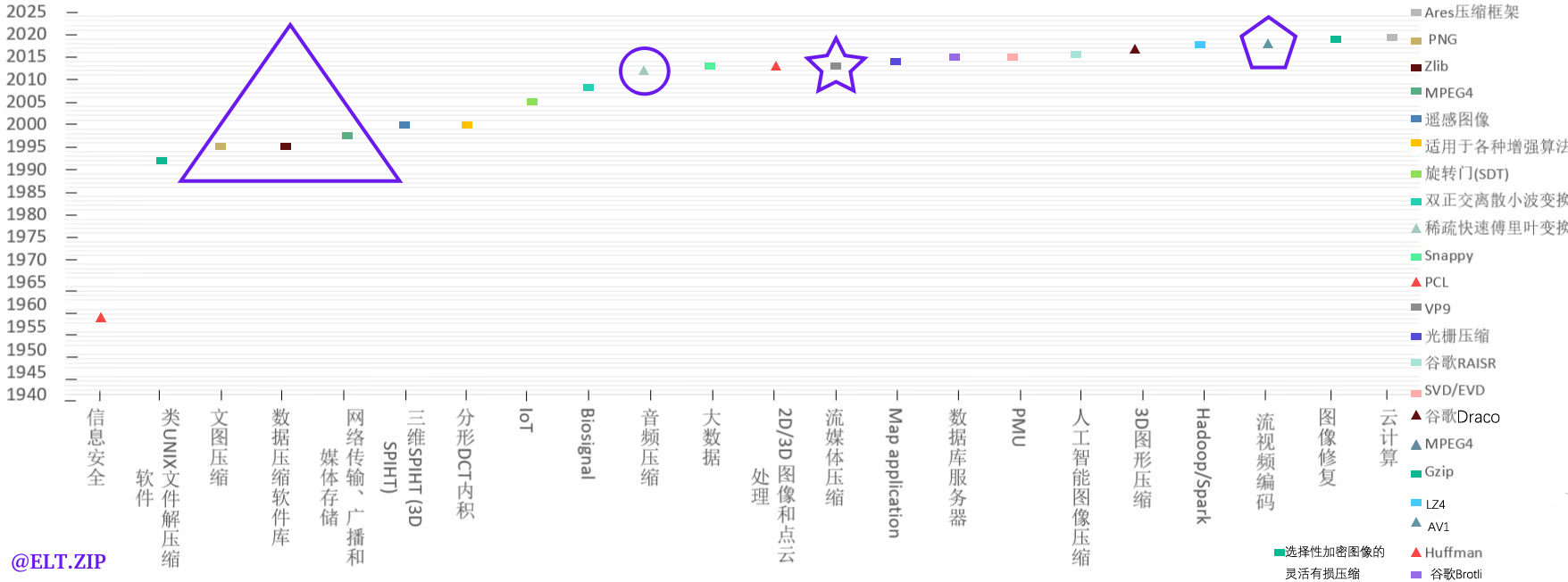
【智慧场景】
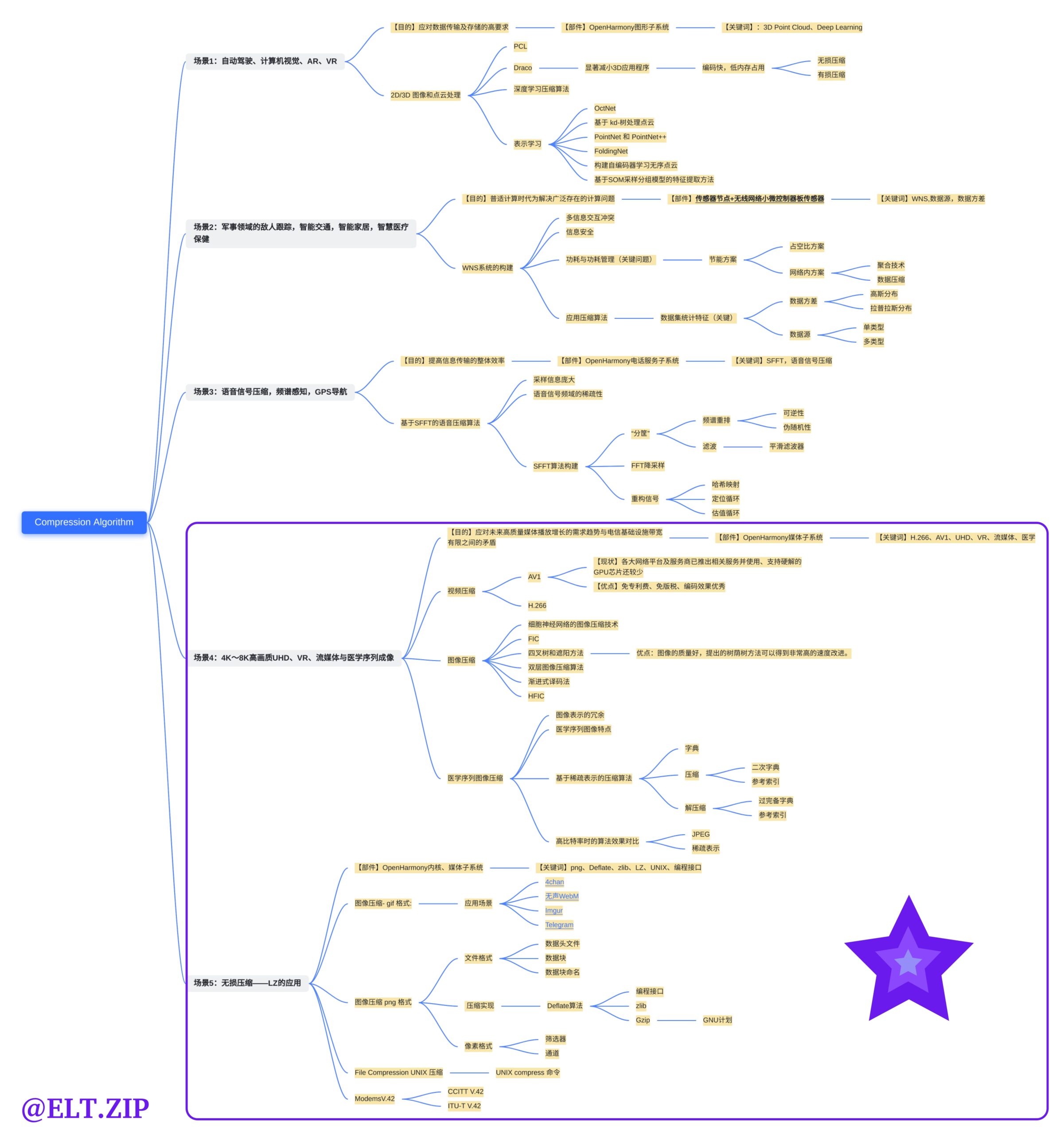
基于稀疏表示的医学序列图像压缩方法
背景
- 随着医学影像技术的发展,近年来,各种医学影像设备产生了大量的医学数字图像。医学数字图像具有内容丰富、形象直观的特点,能够很好地辅助医疗诊断。然而,因其数据量非常庞大,会占用大量的存储空间和传输带宽,所以有必要对医学数字图像数据进行压缩。
- 现有的图像压缩标准大都基于图像的正交变换,其中基于离散余弦变换的JPEG压缩标准最具代表性,JPEG算法具有优良的压缩性能,适用于各类图像的压缩。但是,JPEG算法使用固定的字典进行编码和解码,将其用于医学数字图像的压缩时,并没有考虑到医学数字图像本身的特点进一步提高压缩性能。此外,正交变换对于图像的表示并不是最优的,它不能稀疏地捕捉图像的规则性和轮廓特征,因此进一步研究图像压缩的突破点在于图像的表示方面。
- 近几年,稀疏表示成为图像处理领域的研究热点。稀疏表示理论表明,任何信号可以在过完备原子库上稀疏地分解,即使用过完备原子库中尽量少的原子的线性组合来表示原始信号。图像在过完备原子库上稀疏分解的结果十分简洁,而且在直观上也很符合人眼的视觉特性。图像稀疏表示的优良持性,使其成为解决医学数字图像压缩问题的新途径。
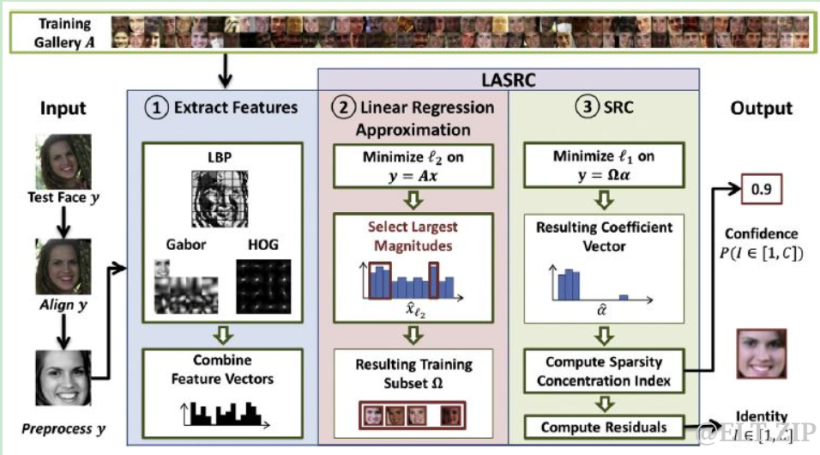
基于稀疏表示的人脸识别算法示意图
概念
图像表示的冗余
图像之所能够被压缩,是因为图像在表示的过程中存在冗余数据。包含重复信息或无关信息的数据称为冗余数据,不同的图像表示方法采用不同的数据形式也就存在不同的冗余数据。通常数字图像在表示中存在三种主要的数据冗余,即:编码冗余、空间和时间冗余、不相关信息。
编码冗余:
编码是用于表示信息实体或者事件集合的符号系统。每一个信息或者事件被赋予一个编 码符号的序列,这个序列称为码字。一个码字中符号的数量为该码字的长度。编码冗余指的就是当前表示给定信息的码字的平均长度可以通过某种编码策略而减少其长度。
空间和时间冗余:
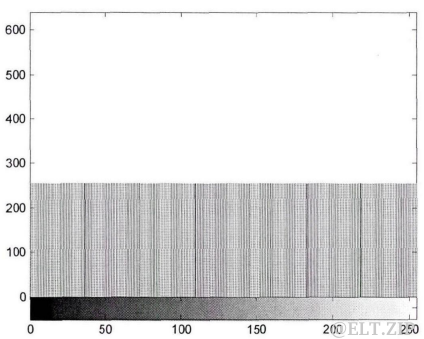
该图像中265种灰度是等概率出现的;横向来看,沿每条线的像素是相同的,所以水平方向上的像素是最大相关的;竖向来看,因为每条线的灰度是随机的,所以在垂直方向上相邻像素是彼此独立的。不能使用简单的变长编码来实现压缩,但在灰度矩阵中每一行的各个数据是完全相同的,若按照传统矩阵的形式来表示图像,则存在相当大的数据冗余。这也就是图像在空间上的冗余。图像数据在时间上的冗余与此类似,是指在时间上,相邻像素的相关性很大,例如序列图像前后间有较大的相关性。
不相关信息:
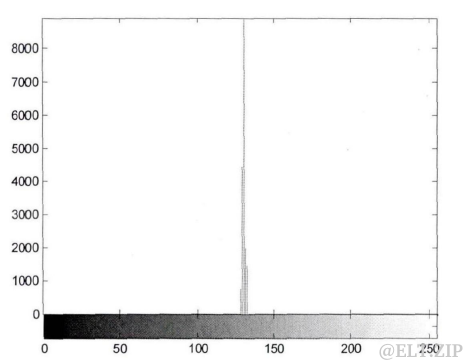
一些被人类视觉系统忽略的或者没有利用价值的信息,通常被称为不相关信息,这些信息在传统的表示方式中认为是冗余的。例如,图一是由计算机生成的图像,肉眼看上去可以认为它是由单一灰度组成的,这样,所有像素由一个灰度值来表示,原始的 2562568 比特的灰度矩阵可用单一的8比特数值来表示,从而达到很高的压缩比。图二显示的是图一的直方图,可以看出,实际上不是所有像素都是同一灰度的。所以上述的压缩方式会很小程度上破坏图像的原始质量,但是这种破坏很难被人类的视觉系统察觉到,也就是说图一中极少部分像素灰度值的不一致可以被忽略,从而去除这种不相关信息带来的冗余。
无损压缩
图像无损压缩是使图像信息没有任何丢失的情况下,对表示图像的数据某种编码的方式进行编码 来减少所需要的比特数。比较经典的无损压缩方法有哈弗曼编码、游程编码、算术编码等,对于不同的图像,根据图像特性,采取合适的编码方式会取得更优的压缩效果。图像无损压缩方法对于恢复后的图像没有任何信息损失,也就是说重建效果极好,但是这类方法对图像的压缩能力有限。
有损压缩
图像有损压缩是指在图像压缩过程中允许损失一定的信息,解压后不能完全恢复原始图像数据,但是所损失的部分对图像质量影响很小,不会干扰人类对图像内容的理解。也正是因为此,有损压缩通常会带来较高的图像压缩比。目前较成熟有损压缩方法是基于离散余弦变换和基于小波变换的方法,其中基于离散余弦变换的压缩方法以 JPEG 为代表,基于小波变换的压缩方法以 JPEG2000 和多级树集合分裂算法(Set Partitioning In Hierarchical Trees, SPIHT)为代表,这几种算法具有优秀的压缩性能。 JPEG2000 由于版权与技术问题,目前尚未在实际中广泛使用。JPEG是当今最流行的图像压缩算法。

字典
在信号处理领域,字典是对数据的一种高度概括,字典可以以字典原子线性组合的方式表示数据的绝大部分信息,即使这部分数据丢失了,我们仍然可以想办法从字典中重构或近似恢复这部分数据。字典分别可以通过预定义和学习来获得。预定义字典如DCT字典、小波字典等,构造起来简单方便,但是对信号的适应性一般不好。学习字典一般可以从信号中学得特征,充分表示信号,被字典稀疏表示的信号可以用于许多信号处理的任务,比如压缩感知、特征提取、图像分类、图像去噪、压缩。

算法
经过多年的研究,随着许多基于离散余弦变换和基于小波变换的图像压缩方法的诞生,图像压缩问题达到了一个重要的里程碑,同时也是个研究瓶颈。基于正交变换的图像压缩方法虽然能取得良好的压缩效果,但仍然存在一些不足之处,例如正交变换不能很好地表示出图像的轮廓,使用固定字典对医学数字图像压缩不会考虑医学图像自身的特点,压缩速率较慢等等。图像稀疏表示是近几年兴起的一种新的图像表示方法,基于稀疏表示的图像压缩为解决医学数字图象压缩问题提供了一种新的研究思路。
医学序列图像特点
医学序列图像是指在相同的成像设备下,对同一研究对象,在不同断层的扫描切片集合或不同时间的扫描切片集合。根据切片集合的不同来源,可分为时间序列图像和空间序列图像。时间序列图像是指患者延时间轴获得的图像集,记录患者在一段时间内的病患信息,例如,一位SARS病人在发病期间,每天都要拍摄胸腔CT影像,这些在时间上离散的影像,就构成了一组相同类型的医学时间序列图像。空间序列图像是指成像设备对病人某个器官的不同断层的扫描切片,利用这些连续的扫描切片,通过三维重建技术,将人体器官以“三维”的形式真实地显示出来,实现其三维可视化。

图三.医学序列图像示例
医学序列图像有其自身的特点,即背景比较单一,序列中相邻的图像包含的大部分信息是相同的, 也就是说表示这些图像会存在大量的重复信息,图三展示了展示了某个病例的部分颅脑 CT 图像序列,可以看出,这些图像序列是渐变的,即相邻图像的变化很小。因此,本文提出的基于稀疏表示的医学序列图像压缩方法,就是首先减少序列图像之间的相关冗余信息,然后采用稀疏表示的方法压缩图像数据,从而达到图像压缩的目的。
基于稀疏表示的压缩方法
从医学序列图像(图三)的特点可以看出,序列中相邻图像存在很强的相似性,若将图像划分为指定大小的图像块,在这一系列的图像块中,会存在很多相似的图像块。
基于此,本文提出基千稀疏表示的医学序列图像压缩方法,首先将一例序列图像分块,然后根据所有图像块之间的相似性,选择一些图像块作为基准块,就是说,其他的图像块与基准块集合中的某一块非常相似,可直接用该基准块来代替。在进行相似性衡量之时,一一记录下所有图像块与基准块之间的对应关系。然后只用对基准块集合进行稀疏分解,将基准块集合分解得到的稀疏系数矩阵作为二次字典。
待表示的信号是稀疏表示模型中字典的某几列的线性组合,而这里的二次字典,待表示的信号仅仅根据二次字典的某一列来重建,且不要求二次字典的过完备性。图像压缩过程中,由一系列的图像块计算相似性后,对一组互为相似的图像块只用考虑其中一个,并将其设为基准块,其他的图像块则被认为是副本,副本不用存储。对于所有的图像块,需要依次为每个图像块存储与之相似的基准块的序号,即参考索引。基准块的序号和二次字典的列号是一一对应的,也就是说需要指明在图像块重建时,它是使用二次字典中哪一列的系数来重建。
此算法分为两部分:
二次字典,字典中的每一列为稀疏系数向量,采取逐列存储的方式,列中的数据为稀疏系数,每个系数分别存储位置索引和幅值两个信息;
参考索引,因为参考索引其实就是二次字典的列号,而二次字典的列数就是基准块的数量,假设相似性计算之后得到N个基准块,则参考索引的数据范围是O~N-1。
压缩流程如下:
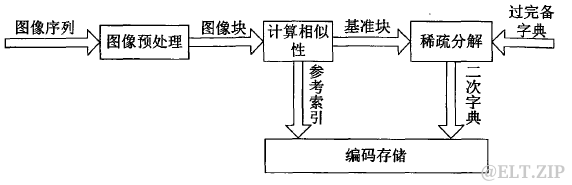
图四.基于稀疏表示的序列图像压缩流程
解压缩流程如下:
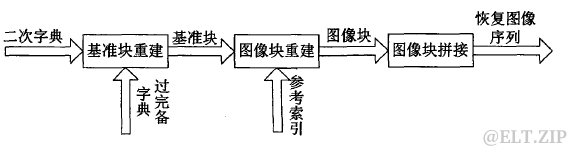
图五.基于稀疏表示的序列图像解压缩流程
所谓过完备字典即其基底一般是冗余的,也就是基元素的个数比维数要大。图像在过完备基下的表示比完备正交基更加稀疏,图像中的干净部分可以利用少量的非零稀疏表示系数进行线性表示,而噪声一般认为不具有稀疏性,因此可以根据它们之间的区别实现去除噪声的目的。
算法测试
将上述提出的基于稀疏表示的序列图像压缩方法与传统的基于稀疏表示的图像压缩方法、JPEG 压缩方法作对比,图六展示了这几种不同方法的压缩效果。可以看出,本文方法的压缩效果优于传统的基于稀疏表示的图像压缩方法,在低比特率时 JPEG 压缩效果优于本文方法,在高比特率时该方法压缩效果优于JPEG。考虑到医学图像对图像质量要求很高,也就要求其峰值信噪比较高,基于稀疏表示序列图像的方法在高峰值信噪比的情况下,能够达到优于JPEG的压缩效果。
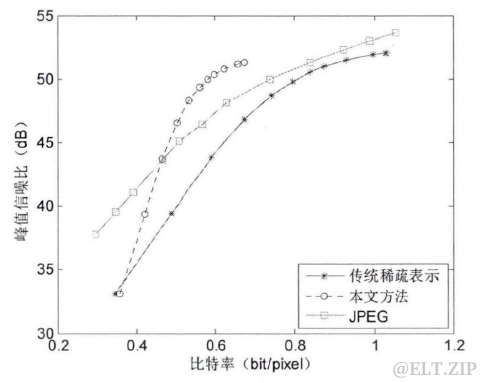
图六.不同压缩方法的压缩效果比较
总结
本文介绍了基于稀疏表示的医学序列图像压缩方法,该方法利用医学序列图像之间的相似性,建立了二次字典和参考索引,实验结果表明,这种对序列图像进行整体压缩的方法在高峰值信噪比时其压缩效果优于 JPEG 压缩标准。































