












一、总体架构
粗排是介于召回和精排之间的一个模块 。它从召回获取上万的候选item,输出几百上千的item给精排,是典型的精度与性能之间trade-off的产物。对于推荐池不大的场景,粗排是非必选的。粗排 整体架构 如下:
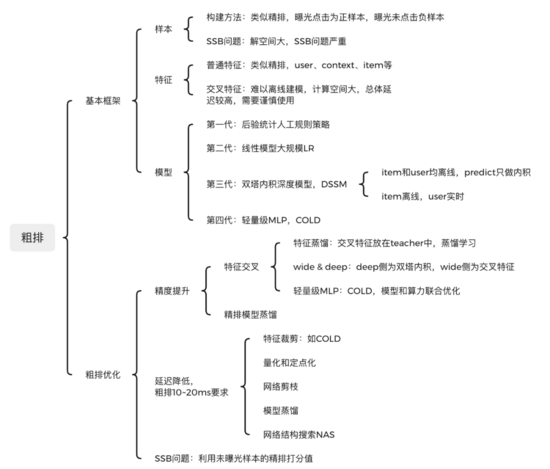
二、粗排基本框架:样本、特征、模型
目前粗排一般模型化了,基本框架也是包括数据样本、特征工程、深度模型三部分。
1.数据样本
目前粗排一般也都模型化了,其训练样本类似于精排,选取曝光点击为正样本,曝光未点击为负样本。但由于粗排一般面向上万的候选集,而精排只有几百上千,其解空间大很多。只使用曝光样本作为训练,但却要对曝光和非曝光同时预测,存在严重的样本选择偏差(SSB问题),导致训练与预测不一致。相比精排,显然粗排的SSB问题更严重。
2.特征工程
粗排的特征也可以类似于精排,由于其计算延迟要求高,只有10ms~20ms,故一般可以粗分为两类:
- 普通特征:类似精排,user、context、item三部分。有哪些特征,以及特征如何处理,可以参看精排的特征工程部分。
- 交叉特征:user和item之间的交叉特征,对提升模型精度很有帮助。但由于交叉特征枚举过多,难以离线计算和存储。实时打分时又不像user特征只用计算一次,延迟较高。故对于交叉特征要谨慎使用。
3.深度模型
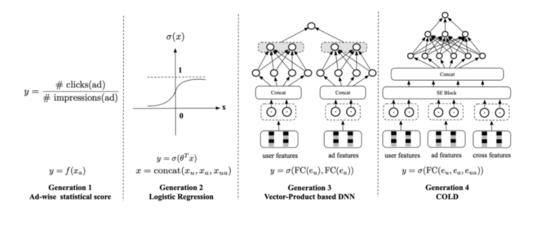
粗排目前已经基本模型化,其发展历程主要分为四个阶段:
第一代 :人工规则策略,可以基于后验统计,构建一个人工规则。比如融合item的历史CTR、CVR、类目价格档、销量等比较核心的因子。人工规则准确率低,也没有个性化,也不可能实时更新。
第二代 :LR线性模型,有一定的个性化和实时性能力,但模型过于简单,表达能力偏弱。
第三代 :DSSM双塔内积深度模型。它将user和item进行解耦合,分别通过两个Tower独立构建。从而可以实现item向量离线存储,降低线上predict延迟。主要有两种范式:
- item和user均离线存储。 这个方案只需要计算user和item的内积即可,计算延迟低。 由于user是离线存储的,故可以使用复杂的模型,提升表达能力。 但user侧的实时性较差,对于用户行为不能实时捕捉。
- item离线,user实时。 item相对user,实时性要求没那么高。 由于一次打分是针对同一个用户的,故user侧只需要实时计算一次即可,速度也很快。 目前这个方案使用较多。
第四代 :item和user隔离,导致二者没有特征交叉能力,模型表达能力弱。故又提出了以COLD为代表的第四代模型,轻量级MLP粗排模型。它通过SE block实现特征裁剪,并配合网络剪枝和工程优化,可以实现精度和性能之间的trade-off。
三、粗排优化
粗排的几个主要问题:
- 精度和特征交叉问题:经典的DSSM模型优点很多,目前在粗排上广泛应用,其最核心的缺点就是缺乏特征交叉能力。正所谓成也萧何败萧何,正是由于user和item分离,使得DSSM性能很高。但反过来也是由于二者缺乏交叉,导致模型表达能力不足,精度下降。典型的精度和性能之间的trade-off。
- 低延迟要求:粗排延迟要求高,一般只有10ms~20ms,远低于精排的要求。
- SSB 问题: 粗排解空间比精排大很多,和精排一样只使用曝光样本,导致严重的样本选择偏差问题。
1.精度提升
精度提升的方案主要有精排蒸馏和特征交叉,主要还是要优化特征交叉问题。
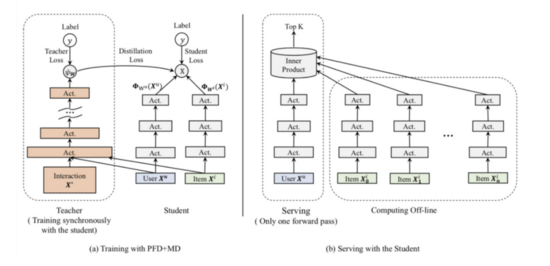
- 精排蒸馏
精排模型作为teacher,对粗排模型进行蒸馏学习,从而提升粗排效果,这已经成为了目前粗排训练基本范式
- 特征交叉
特征交叉可以在特征层面,也可以在模型层面实现。特征层面就是手工构造交叉特征,作为模型底层输入,仍然可以在独立的Tower中。模型层面则使用FM或者MLP等实现自动交叉。主要方法有:
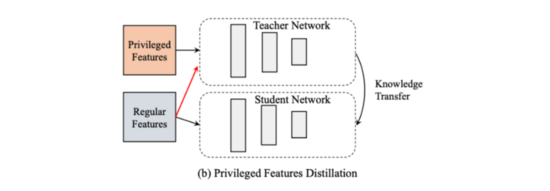
特征蒸馏 :teacher和student使用相同的网络结构,teacher模型使用普通特征和交叉特征,student则只使用普通特征。student从teacher中可以学到交叉特征的高阶信息。
加入交叉特征 :特征层面构建手工交叉特征,独立的Tower中使用。由于交叉特征难以离线存储,实时计算空间也很大,故这个独立的Tower不能过于复杂。那我们第一时间就想到了wide&deep模型。deep部分仍然使用DSSM双塔,wide部分则为交叉特征。
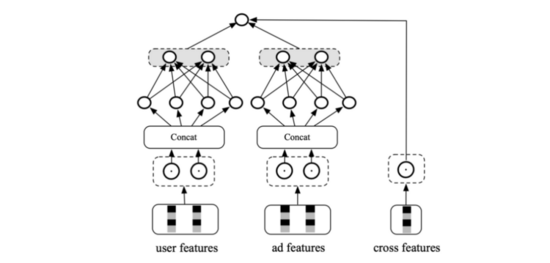
轻量级MLP :模型层面实现特征交叉,不进行独立分塔。比如COLD,通过特征裁剪、网络剪枝、工程优化等方式降低时延,而不是靠独立分塔。
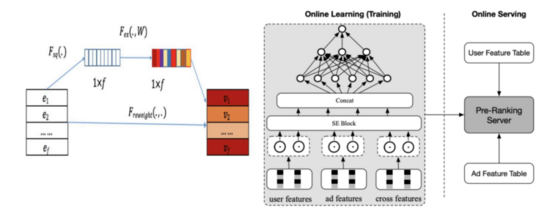
2.延迟降低
精度和性能一直以来都是一个trade-off,很多方案都是在二者之间寻找平衡。粗排的性能要求更高,其延迟必须控制在10ms~20ms以内。性能优化 有很多常见方法 。
主要有以下方法:
- 特征裁剪:如COLD,不重要的特征先滤掉,自然就降低了整体延迟。这一层可以做在模型内,从而可以个性化和实时更新。
- 量化和定点化:比如32bit降低为8bit,可以提升计算和存储性能。
- 网络剪枝:network pruning,包括突触剪枝、神经元剪枝、权重矩阵剪枝等方法,不展开了。
- 模型蒸馏:model distillation,上文已经提到了,不展开了。
网络结构搜索NAS:使用更轻量级,效果更好的模型。可以尝试网络结构搜索NAS。
3.SSB问题
粗排解空间比精排大很多,和精排一样只使用曝光样本,导致严重的样本选择偏差问题。可以把未曝光样本的精排打分给利用起来,缓解SSB问题。
作者简介

谢杨易
腾讯应用算法研究员
腾讯应用算法研究员,毕业于中国科学院,目前在腾讯负责视频推荐算法工作,有丰富的自然语言处理和搜索推荐算法经验。















