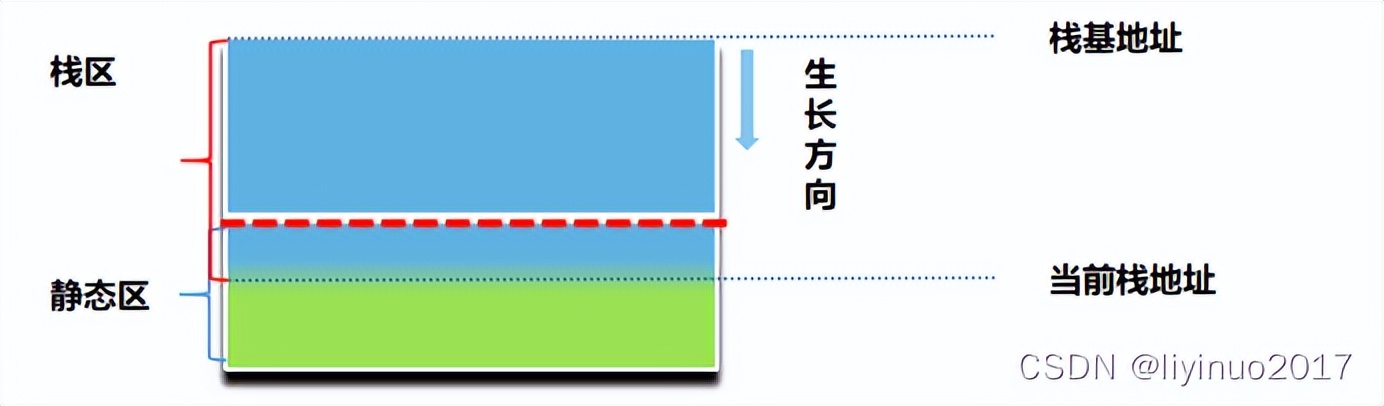
1.栈是什么
在计算机软件开发过程中,我们经常听到,看到,用到“栈”。那么到底“栈”是什么呢?“栈”的作用是什么呢?
不妨我们先看一下《新华字典》是如何定义的。
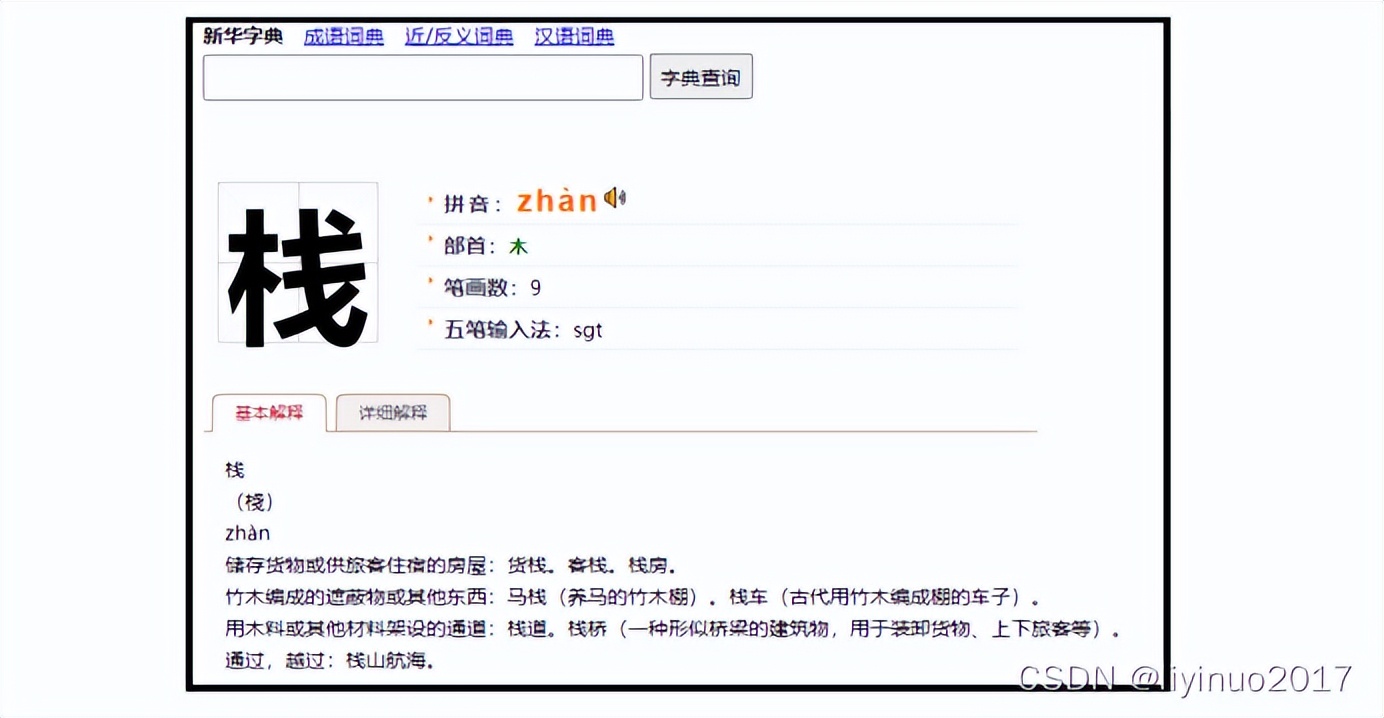
栈基本含义是储存货物或供旅客住宿的房屋,如货栈,客栈。
说到客栈又让我联想到一部著名的武侠电影“新龙门客栈”,客栈就是提供给各位大侠一个临时居住的房间。

既然客栈也是“栈”,说明栈的底层的含义一样,都是用来做存储的。在计算机中“栈”是数据存储空间中的一个区域,用于储存特定的数据。
栈的承载实体通常是随机存取存储器(RAM),CPU可以直接与RAM交换数据,RAM在工作状态下,可以随时从任何一个指定的地址写入(存入)或读出(取出)信息。

综上所述,在计算机中“栈”就是存储数据的一个存储区域。通常说的“堆栈”和“栈”,这两者意义相同。
2.栈的分类
我们知道栈就是用来存储数据的,在实际使用中栈并不是只有唯一的一种形式,而是分为多种类型,接下来我们了解一下栈的分类。
根据栈在存储器中的增长方向,可以把栈分为递减栈和递增栈 :
递减栈(Descend) :向栈写入数据时,栈的生长方向是高地址到低地址。
递增栈(Increase) :向栈写入数据时,栈的生长方向是低地址到高地址。
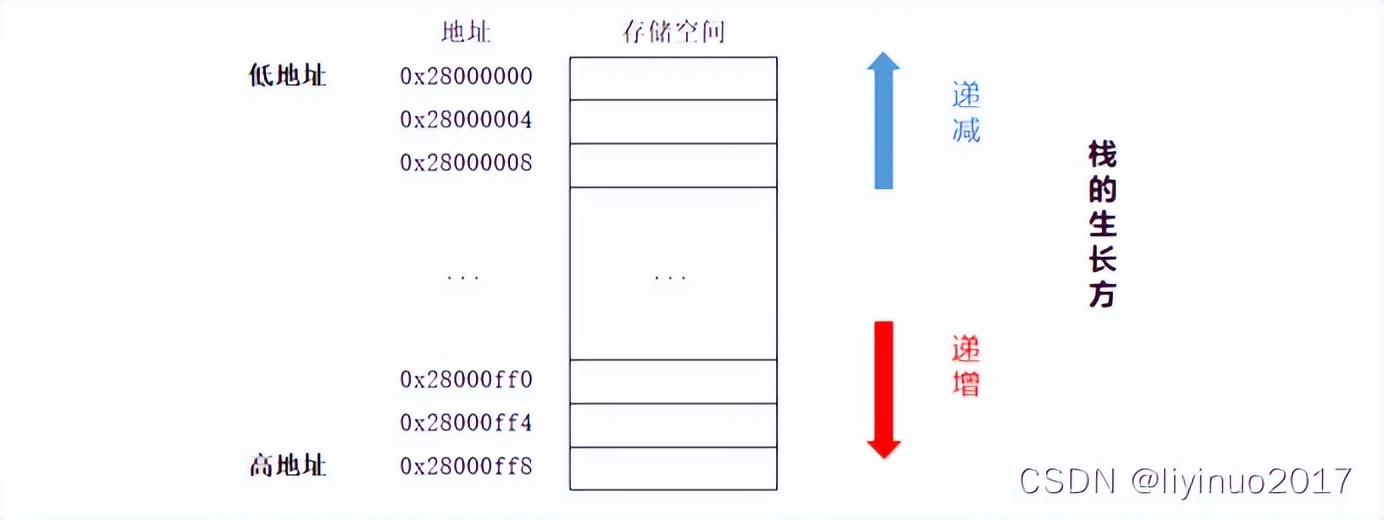
根据栈指针SP指向的位置,可以把栈分为满堆栈和空堆栈:
满堆栈(Full Stack):SP指针始终指向栈顶元素,向栈写入数据时先移动SP指针,再将数据放入SP指向的地址。
空堆栈(Empty Stack):SP指针始终指向下一个将要放入元素的位置,向栈写入数据时先将数据放入SP指向的地址,再移动SP指针。

根据栈的增长方向和栈指针的位置,栈可以分为以下4种基本类型:
- 满增栈(FA):栈指针指向最后压入的数据,栈的生长方向是低地址向高地址。
- 满减栈(FD):栈指针指向最后压入的数据,栈的生长方向是高地址向低地址。
- 空增栈(EA):栈指针指向下一个将要压入数据的地址,栈的生长方向是低地址向高地址生长。
- 空减栈(ED):栈指针指向下一个将要压入数据的地址,栈的生长方向是高地址向低地址生长。
其中满减栈是使用得最多的一种栈类型。
3.栈的操作
计算机的结构框图如下:
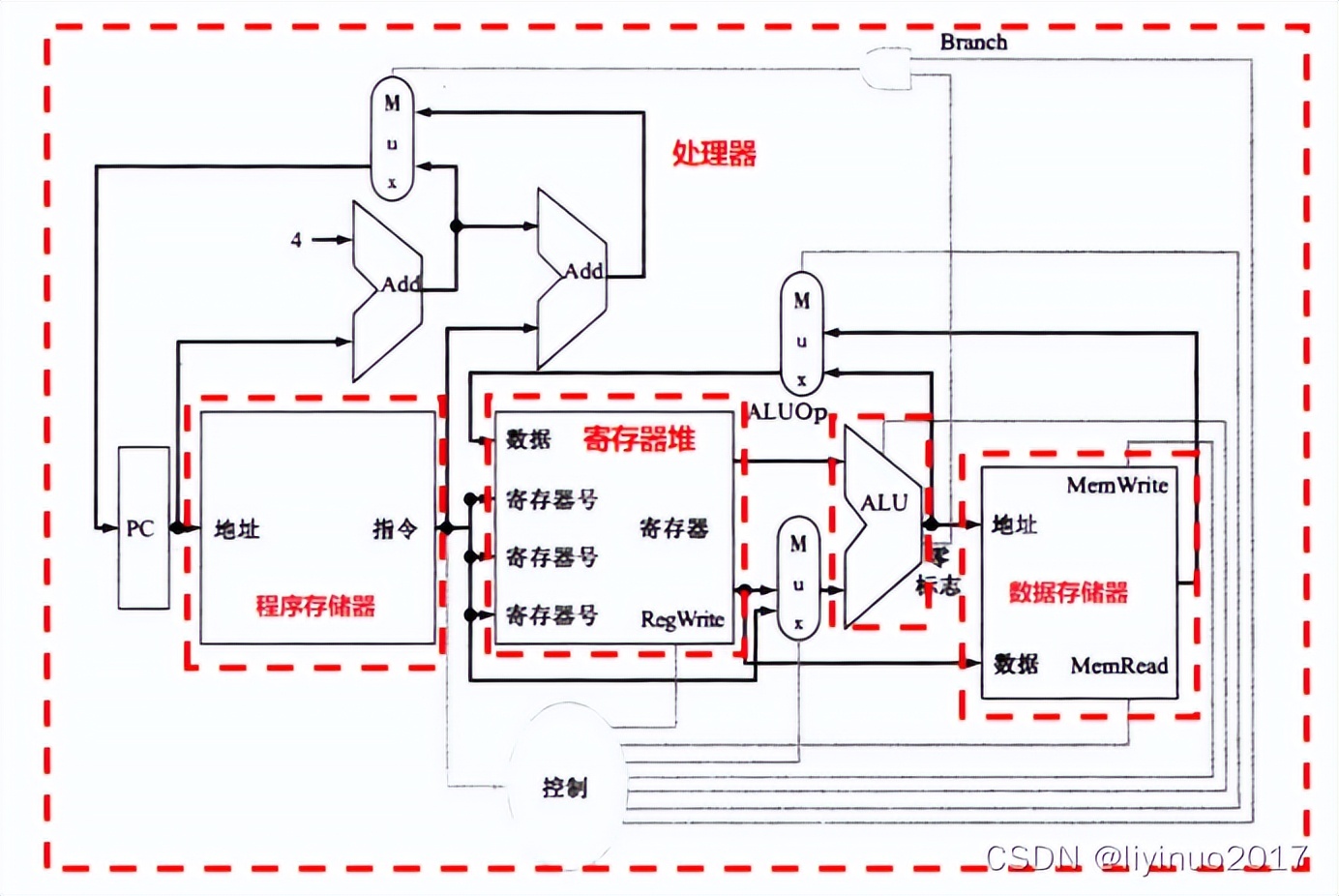
由图可知在处理器中直接参入运算的是寄存器堆中的寄存器,逻辑运算的结果可以输出到数据存储器的地址端口和寄存器堆的数据端口。
寄存器堆中的寄存器值可以输出到数据存储器的数据端口,实现暂存寄存器的值。
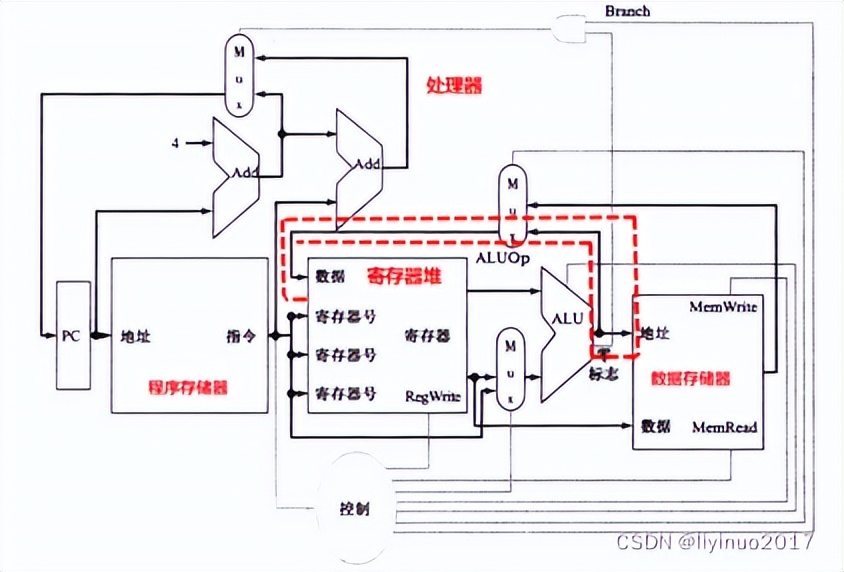
栈操作就是将寄存器的值存入数据存储器,或是将数据存储器中的数据回读到寄存器中。
重要的事情说三遍:
- 栈就是用来暂存处理器中寄存器的值!
- 栈就是用来暂存处理器中寄存器的值!
- 栈就是用来暂存处理器中寄存器的值!
ARM构架处理器中的寄存器组如下:
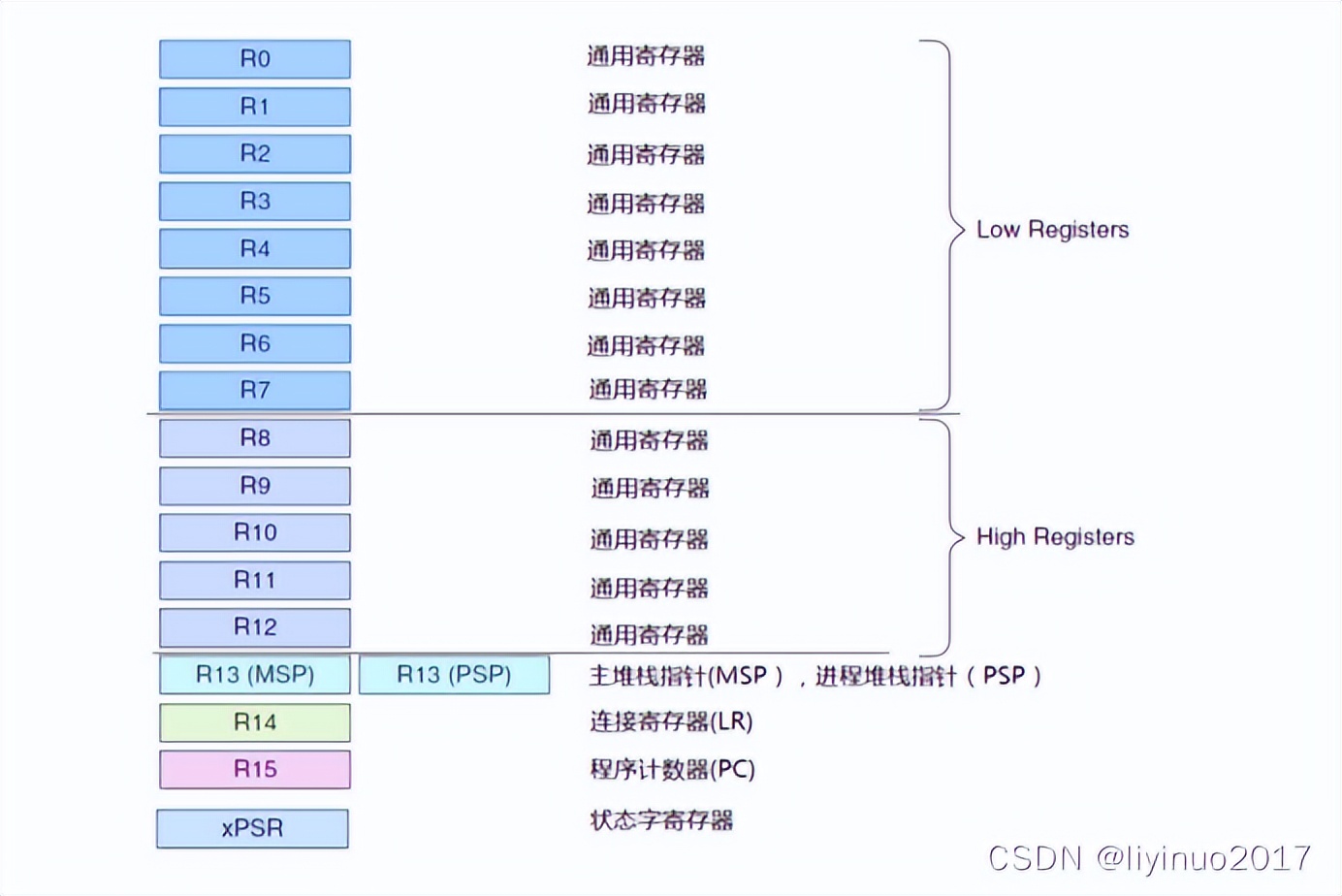
栈操作的两个指令:入栈PUSH和出栈POP。
对于PUSH操作,处理器先减小SP值,然后将指定寄存器存储到SP寄存器指向的存储器地址。
对于POP操作,处理器先将SP指向的存储器地址存储到指定寄存器中,然后将SP寄存器值增加。
栈的操作具有“先进后出”的特性,先存入栈的数据,在栈的底部,后存入栈的数据在顶部,栈中的数据只能从栈顶部读出,因此就有了“先进后出”。
以满减栈为例,下图展示了连续两次PUSH操作,SP寄存器和数据存储器中的数据变化。
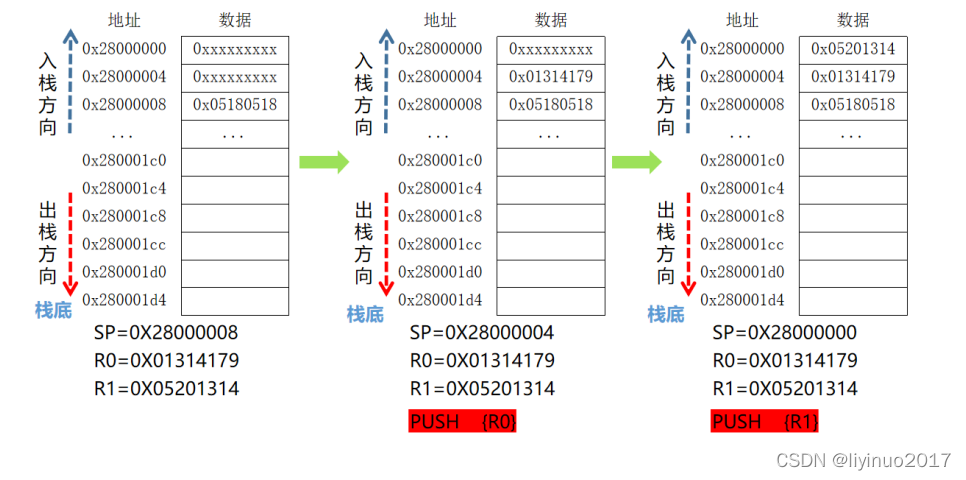
PUSH操作时处理器先减小SP值,然后将指定寄存器存储到SP寄存器指向的存储器地址。
注意:执行PUSH操作后数据存储器中(栈空间)的数据发生变化,但是指定寄存器的值还是原有的值(不会被清零)。
以满减栈为例,下图展示了连续两次POP操作,SP寄存器和指定寄存器的数据变化。
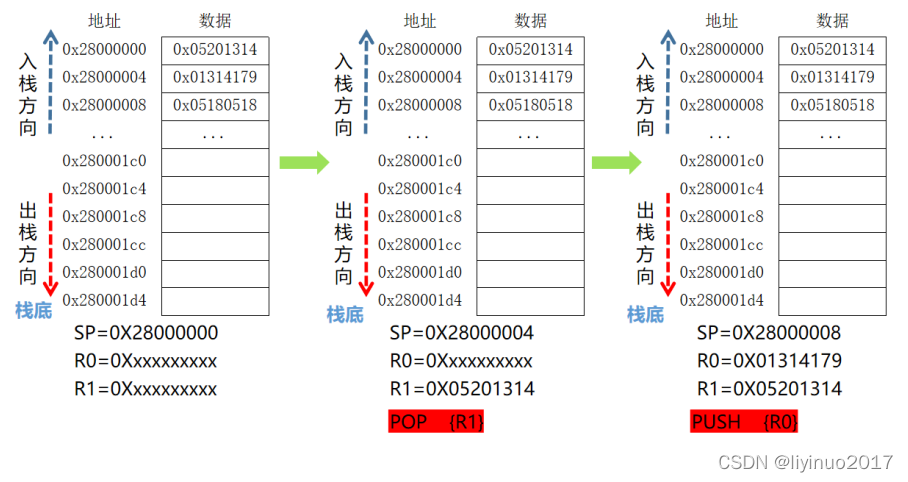
POP操作时处理器先将SP指向的存储器地址存储到指定寄存器中,然后将SP寄存器值增加。
注意:执行POP操作后指定寄存器的数据发生变化,但是数据存储器中(栈空间)的数值还是原有的值(不会被清零)。
PUSH操作后由于指定的寄存器的数据被保存,因此此后可以将该寄存器用于其它用途,当该寄存器完成其它操作后可以通过POP操作恢复原先数值。
由于在处理器中只有寄存器能直接参入运算,通常情况下寄存器的数量有限(通常为16个或者32个),栈操作相当于将寄存器的数量进行扩展。这种操作类似火影忍者中鸣人的影分身(一个真身多个假身)。
总结栈操作:
- 栈是一个数据存储空间(栈空间)。
- 栈有一个栈指针,指向当前栈地址。
- 每次执行PUSH操作后栈空间的数据发生变化,每次执行POP操作后指定寄存器的数据发生变化。
- 每次PUSH和POP操作后SP栈指针都会自动调整(无需用户介入)。
4.栈的作用
上文描述了栈空间本质上暂存处理器中寄存器的运算结果,具体来说栈用于如下4情况的数据存储:
1、用于保存函数执行前的寄存器的值,以便函数结束时恢复。
2、用于存储局部变量。
3、用于传递函数调用时的参数。
4、用于存储中断产生时的状态寄存器和通用寄存器的数值。
4.1函数调用前保存寄存器值
当被调用的函数需要使用寄存器进行数据处理时,需要使用栈临时保存寄存器的数值,当函数结束时恢复寄存器的数值。
测试代码如下:
/******************************************
* @作者 : liwei
* @Github : liyinuoman2017
*******************************************/
void test(void)
{
int l , m , n;
l = 9;
m = 8;
n = l+ m;
}
void stack_test(void)
{
int i , j , k;
i = 1;
j = 2;
test();
k = i+ j;
}
int main(void)
{
int a0,a1,a2,a3,a4,a5,a6,a7,a8,a9;
a0 = 1;
a1 = 3;
a2 = 1;
a3 = 4;
a4 = 1;
a5 = 7;
a6 = 9;
a7 = 5;
a8 = 2;
a9 = 0;
/***调用测试函数**/
stack_test();
a0 = a1 + a2;
a3 = a4 + a5;
}
mian函数中定义了较多变量从而占用了大量寄存器,stack_test函数定义了3个变量,在调用stack_test函数前处理器的寄存器已经被全部占用,为了提供寄存器给stack_test函数使用,就必须先将部分寄存器保存到栈中,当stack_test函数执行结束后从栈中恢复部分寄存器的值。
main函数反汇编后的结果如下:

stack_test函数反汇编后的结果如下:
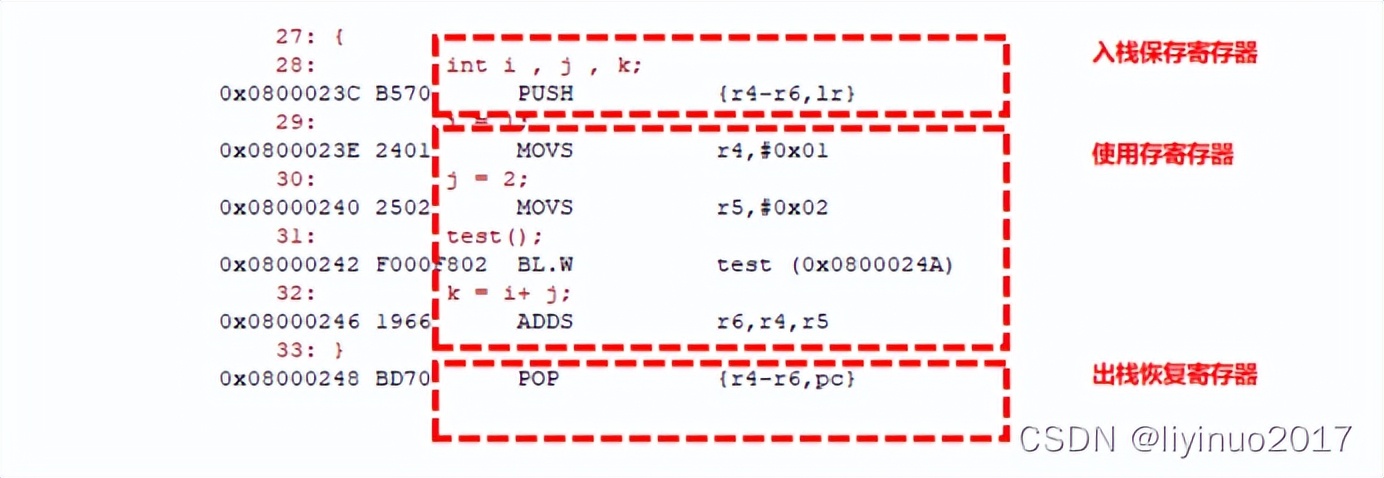
根据stack_test函数汇编代码可知:由于stack_test函数需要使用R4,R5,R6而这3个寄存器,由于这3个寄存器已经被占用,因此stack_test函数在使用R4,R5,R6前,必须先将这3个寄存器保存到栈中,并在stack_test函数执行结束返回前从栈中恢复R4,R5,R6这3个寄存器的数值。
总结:调用子函数时,子函数内需要使用寄存器,由于寄存器已经被占用,因此需要将函数调用者使用的寄存器保存到栈中,待调用函数结束后再恢复寄存器。
4.2存储局部变量
局部变量可以直接存储到寄存器中,但是当局部变量比较多时,一部分变量将会保存到栈中。
测试代码如下:
/******************************************
* @作者 : liwei
* @Github : liyinuoman2017
*******************************************/
int main(void)
{
int a0,a1,a2,a3,a4,a5,a6,a7,a8,a9,a10,a11,a12,a13,a14,a15;
a0 = 1;
a1 = 3;
a2 = 1;
a3 = 4;
a4 = 1;
a5 = 7;
a6 = 9;
a7 = 5;
a8 = 2;
a9 = 1;
a10 = 3;
a11 = 1;
a12 = 4;
a13 = 1;
a14 = 7;
a15 = 9;
a0 = a1 + a2;
a3 = a4 + a5;
a6 = a7 + a8;
a9 = a10 + a11;
a12 = a13 + a14;
a15 = a1 + a2;
}
main函数反汇编后的结果如下:

根据反汇编可知,当使用的局部变量较多时,部分局部变量会被保存到栈中。
4.3保存子函数参数
ARM体系结构的过程调用标准AAPCS (Procedure Call Standard for the ARM Architecture),它规定了子程序的调用规则,其中ARM寄存器在子程序调用中的参数传递规则如下:
当子程序参数不超过4个时,使用寄存器R0-R3来传递参数,当参数超过4个时,超出的参数使用栈来传递参数。
调用有2个参数的子函数的测试代码如下:
/******************************************
* @作者 : liwei
* @Github : liyinuoman2017
*******************************************/
int sum(int a , int b)
{
return ( a + b );
}
int main(void)
{
int a0 = 0;
a0 = sum( 3 , 4 );
while(1);
}
代码反汇编如下:

由反汇编可知,在跳转到sum函数前使用R0,R1保存了sum函数的2个参数。
调用有6个参数的子函数的测试代码如下:
/******************************************
* @作者 : liwei
* @Github : liyinuoman2017
*******************************************/
int sum(int a , int b, int c, int d, int e, int f)
{
return ( a + b + c + d + e + f );
}
int main(void)
{
int a0 = 0;
a0 = sum( 1 , 3 , 2 , 4 , 7 , 9 );
while(1);
}
代码反汇编如下:

由反汇编可知,在跳转到sum函数前使用R0,R1,R2,R3保存了后4个函数参数,同时将第一个和第二个参数存入栈中,在sum函数中从栈中加载参数带入计算。
因此在很多编程规范规定函数参数不能超过3个。原因是利用栈传递参数影响程序执行效率。
4.4中断时存储寄存器
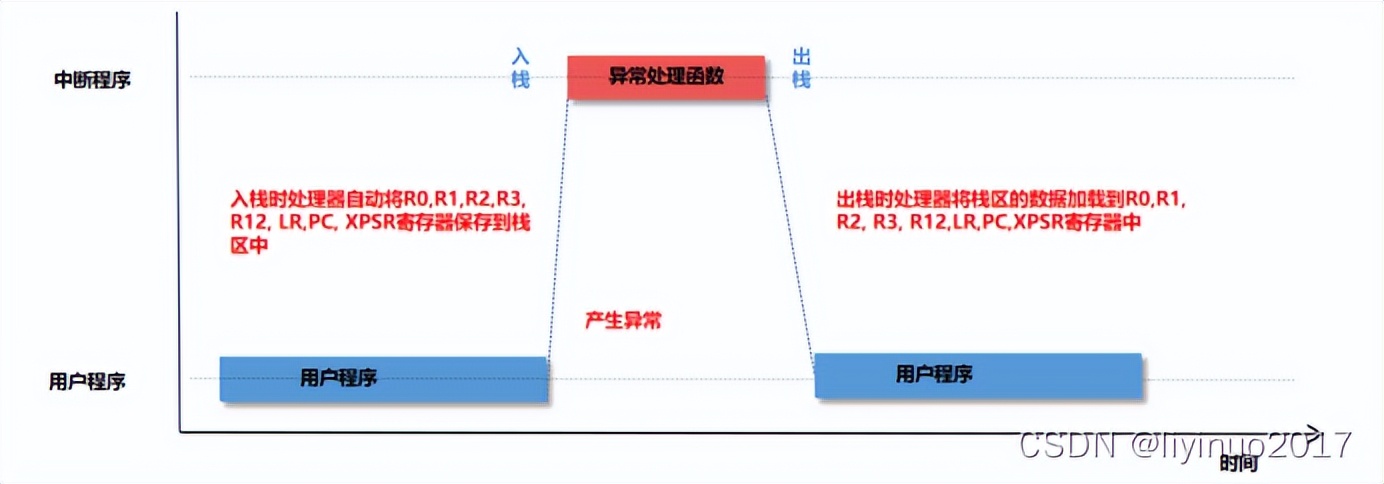
当处理器产生异常或中断时,在进入异常函数前,处理器硬件会自动保存部分寄存器,待异常函数执行完毕后,执行异常返回时,处理器硬件会自动恢复之前保存的寄存器的值。
ARM构架处理器中断时序图如下:
5.栈区的优势
计算机中的内存分区通常如下:
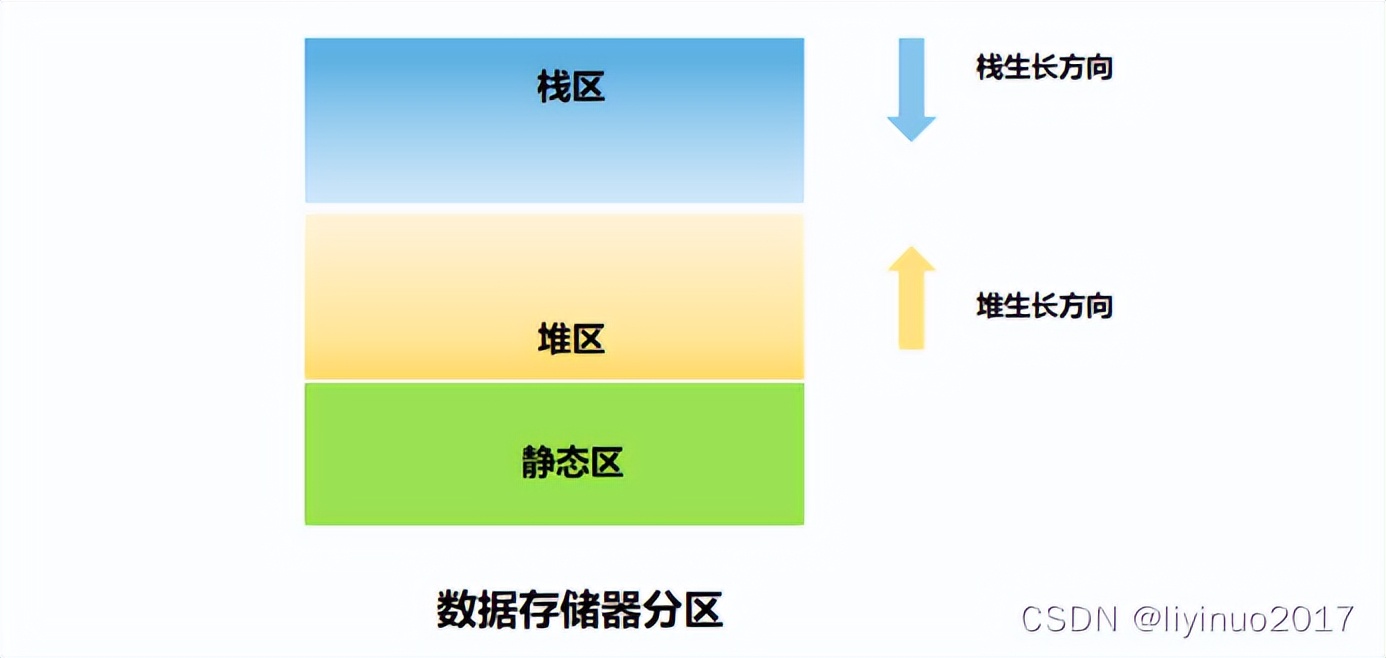
数据存储器通常分为:栈区,堆区,静态区。
栈区用于存储特定用法的变量,栈区内的变量是临时的变化的,栈区使用大小是动态变化的。
堆区用于用户主动分配存储数据。
静态区用于存储静态变量,静态区内的变量的使用周期是整个程序运行周期,每个变量对应一个地址,“一个萝卜一个坑”。
堆区在本文不进行描述,本节重点对比栈区和静态区。栈区的优势是什么?栈区能用静态区代替吗?
5.1栈区的优势
假设现在有如下一个函数:
void test(void)
{
char buff[100];
...
}
函数test中定义了一个100字节的数组buff,因此运行程序执行到test函数时会临时占用100字节的栈区。假设把buff该成静态类型static char buff[100] ,此时程序会使用100字节静态区一直保存数组buff。
感觉好像没啥优势呢,静态区和栈区都会消耗100字节。
如果现在有50个类似test的函数,每个函数中需要使用100字节,如果全部使用静态变量,程序将使用5000字节静态区。
如果函数不使用静态变量,而是使用临时变量,此时程序将临时占用最少100字节(50个函数不发生嵌套调用),最大5000字节(50个函数全部嵌套),事实上很难出现50个函数全部嵌套的情况,按照嵌套10层算只需要1000字节栈区即可满足程序对栈的消耗。
因此在函数较多的情况下,栈区可以显著减少数据存储区消耗量!
5.2栈区的不可替代性
前文讲了栈区可以显著减少内存消耗量,拿我们在不考虑内存消耗的情况下,取消栈区只使用静态区,这样可以让数据存储器中的分区更单一,更方便管理,这样可以吗?
假设现在有如下函数:
/******************************************
* @作者 : liwei
* @Github : liyinuoman2017
*******************************************/
double factorial(double n)
{
double s;
if(n >= 2)
{
s = n*factorial( n - 1 );
}
else if(n ==1)
{
s = 1;
}
return s;
}
factorial是一个递归函数实现阶乘功能,递归函数将调用自身。这样情况下递归函数中的变量如果使用静态变量将无法正常运行,递归函数中的变量只能使用局部变量,局部变量存储在栈区。
假设现在有如下代码:
/******************************************
* @作者 : liwei
* @Github : liyinuoman2017
*******************************************/
void main(void)
{
...
sum();
}
int sum(int a , int b)
{
int c;
c = a + b;
return c;
}
/* 中断函数 */
void irq_handler(void)
{
...
sum();
}
假设main函数在调用sum函数期间,处理器产生了中断,此时程序跳转并执行irq_handler函数,在irq_handler函数中也调用了sum函数,此时sum函数出现被重复调用两次,sum函数中的变量也必须使用局部变量。不仅仅只有递归函数中的变量必须使用局部变量,在一些特殊使用场景下只能使用局部变量,此时体现了栈区的不可替代性。
综上所述,使用栈区可以节省数据存储空间,同时一些特殊使用场景只能使用栈区。

6.every coin has two sides
前文指出栈区的使用有不可替代性,同时可节省数据存储空间。那么栈区使用是不是就是一种完美的方案呢?
every coin has two sides(每个硬币都有两面)
任何事物都有两面性,有优点就会有缺点。使用栈的缺点是:栈溢出!
相信大家都遇到过栈溢出的情况吧,栈溢出会让程序产生表现形式多变的BUG,这类型的BUG通常让人很难定位。
下图展示了栈溢出的情况:
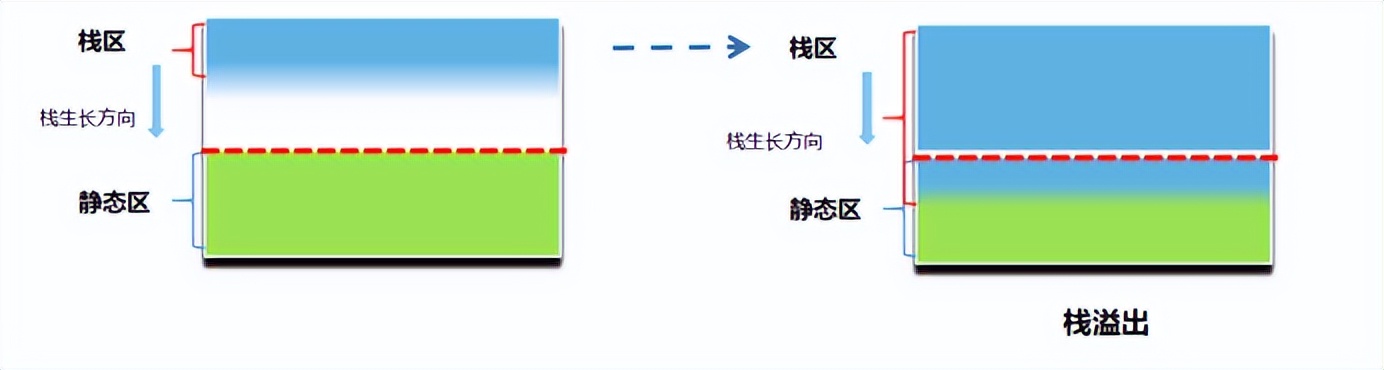
由图可知当栈溢出时,可能会错误的修改静态区的变量的数值,导致程序出现BUG。而且栈溢出后修改的静态区的数值体现出随机性,因此会让程序产生表现形式多变的BUG。
既然栈溢出会造成严重BUG,那么有没有方法来检测栈溢出?
第一种方法是采用的做法是栈区初始化时,在栈的末端填充固定的标记字符(比如0x5a5a5a5a),如果发生了"栈溢出",那么栈区末端填充的标记字符则有可能会被更改。
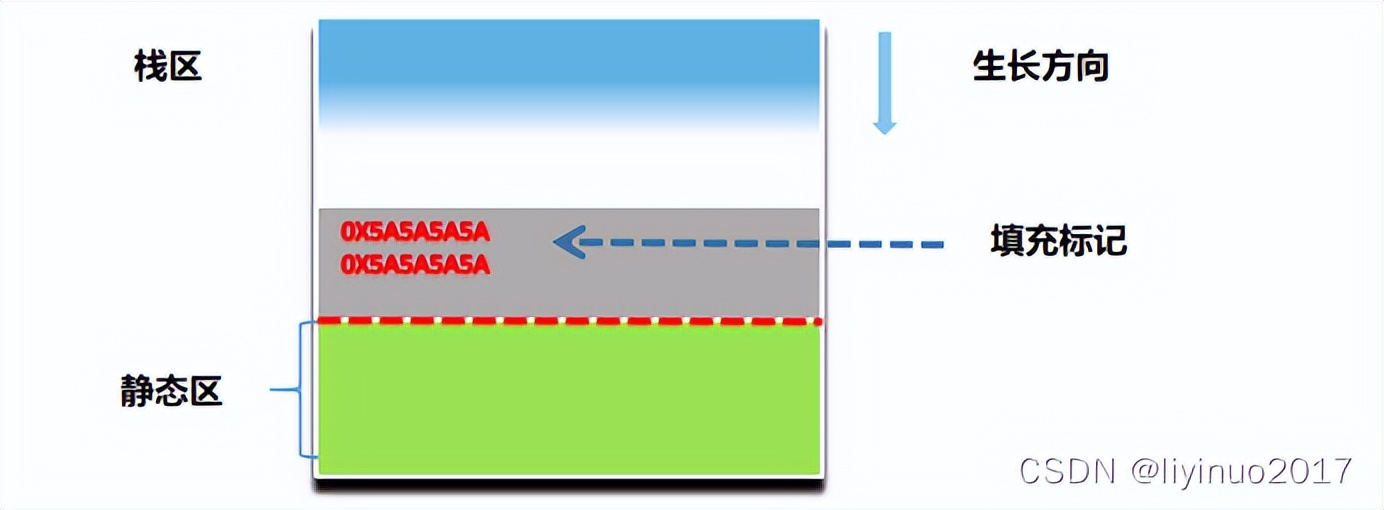
这样通过检测栈区末端标记字符是否被更改来判断是否有"栈溢出",这种检测方法并不是100%有效的,是因为末端的标记字符有可能被跳过。
第二种方法是通过栈基地址和当前栈地址计算当前栈的大小,栈基地址减当前栈地址即可求出栈的使用大小,若计算出的栈大小大于系统分配的栈大小则"栈溢出"。