本文转自雷锋网,如需转载请至雷锋网官网申请授权。
Google Brain的机器人团队(Robotics at Google)最近发布了一篇文章,介绍了他们如何将大规模语言模型的“说”的能力和机器人“行”的能力结合在一起,从而赋予机器人更适用于物理世界的推理能力(physically-grounded)。
1 动机
面对对方“我不小心洒了我的饮料,你可以帮我一下吗?”的问题的时候,你会怎么反应?
你评估一下当下的环境,可能会帮对方把饮料瓶收拾掉,如果周围有抹布,你会拿起抹布帮他收拾干净,当然这些一步一步的指令可能会在你的心中默念一遍。
当你没有观察到吸尘器在周围时候,你显然不会告诉对方要使用吸尘器收拾,因为那不符合当下的环境条件。
这样的行为决策已经体现了两个步骤:面对一个求助,你拥有一些可以解决当下问题的行为候选项,然后你还得实际下来,选择最符合现实的那个行为。
放在机器人的语境下,在前一个步骤,我们需要一个语言模型去理解一段人类语言发出的指令,并“说出”我们可能的种种解决方案;第二个步骤需要结合周围环境,挑出那些符合现实世界的方案。
这篇文章就是试图将这两个行为解耦出来,并以恰当的方式结合在一起。
首先是用于理解和生成可能的候选项的第一步。很自然地,文章使用了现在在自然语言处理领域很流行的大规模语言模型(LLM)。它可以是生成式的,即面对一个问题,生成可能的问答,如下图所示:

三个LLM给出的回应
可以看出这种生成式的结构并非适用在面对行为的机器人领域,一方面如FLAN模型输出的结果没有明确的行为指令;另一方面,即使像GPT3中给出了具体的做法,它仍然没有考虑到现实场景:万一当下没有吸尘器呢?
就像开头想表达的:会说什么并不重要,重要的是可行吗?
因此,第二个步就需要考虑机器人所处的环境、它能够完成的行为、它当下拥有的技能等等了,这些往往采用强化学习的value function(VF)或者affordance function进行评估。
如果将第一步的LLM视作是可以思考和讲话的“心和嘴”,后一步的affordance则充当了“眼和手”的功能。前一步“说”(Say),后一步判断“能”(Can)做什么,文章将这一模型起名为SayCan。
2 方法
从上文所述文章方法的关键是如何将没有与现实世界结合的“理想化”的LLM变得更加“现实”。只是根据一段指令,采用对话生成的方式产生一段虽然合理但是无关的语句并非我们所要的。因此,SayCan采用了prompt以及给特定行为打分的方式。
具体而言,机器人先观察周围环境,利用VF找出一些可行(actionable)的行为候选项。LLM根据问题和一小段prompt对于这些行为进行打分。
VF和LLM打出的两个分数的乘积作为最终选择该行为的置信度,挑选出最高得分的行为作为这一步选择的行为。
之后,将当前选择的行为在接到上一步的回答模板中,作为下一步的模板输入,继续重复上述的动作,递归式推断之后的行为,直到最终推断出一个结束的标志。这一过程,可以参考下图。
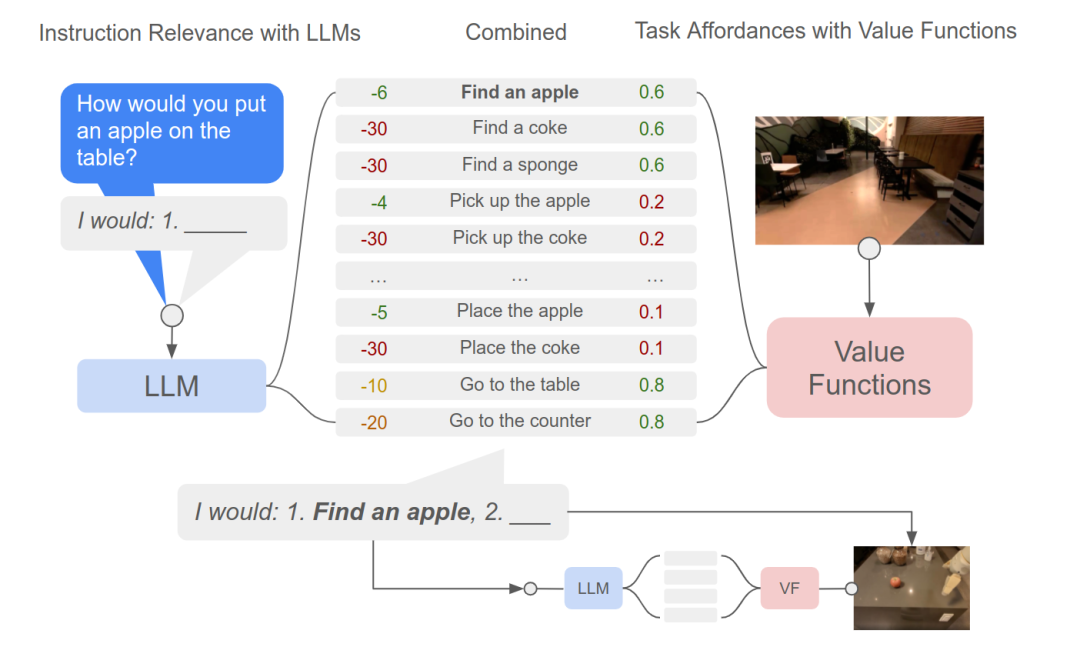
选择行为的流程示意图
具体LLM是如何做的呢?
如下图所示,LLM采用模板“I would:1.”作为回答“How would...”问题的命令词汇(prompt)。值得注意的是,文章中也提到,这样以比较标准的方式开头的对话都是在机器人语境下专门设计的,现实场景可能会更加复杂。除此之外,用于in-context learning的例子也由类似的语句构成,为了让模型生成语句时候有所参考,也就是图中的:prompt engineering的部分。
之后的LLM是针对预选好的行为进行打分,是一种类似分类或者检索的方式,而不是生成式的。
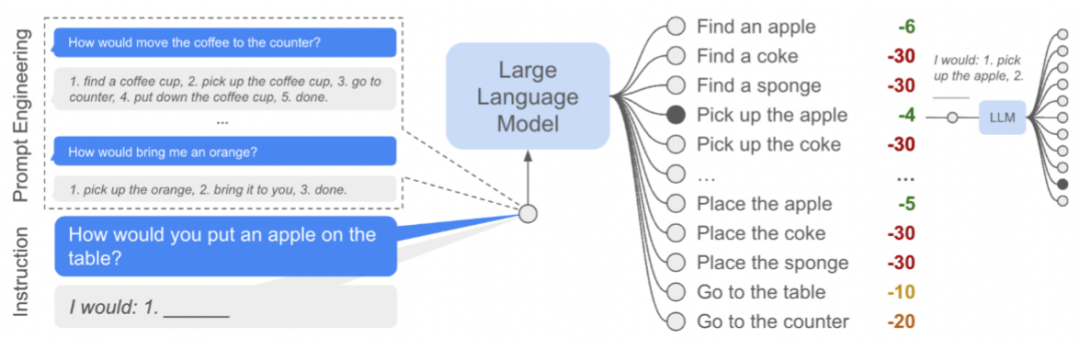
LLM的具体实现过程
整个实现可以参考如下的伪代码:

3 结果
文章在模拟的厨房和现实的厨房做了测试,这包括101个由不同语言指令构成的任务,下面展示了一些SayCan完成的例子,作为给出了人类的指令,右边则是机器人根据LLM和VF共同解码出来的指令序列。蓝色的条图表示LLM对于特定动作得到的概率打分,右边则是通过VF得到的分数。
场景一
人类:我洒了可乐,你能帮我用什么清理干净吗?
机器人:我会1)找到一块抹布。2)拿起这块抹布。3)把它带给你。4)完成。

示例场景一
场景二
人类:我洒了可乐,你能帮我重新拿一罐吗?
机器人:我会1)找到一罐可乐。2)拿起这罐可乐。3)把它带给你。4)完成。

示例场景二

示例场景三
场景三
人类:你会怎么把抹布放在衣柜上
机器人:我会1)找到一块抹布。2)拿起这块抹布。3)走到衣柜附近。4)完成。
其中场景三的第一步的选择尽管语言模型给出了“pick up the sponge”的最佳选项,但当机器人什么都没有看到时,VF则给这个选项很低的得分。这说明了SayCan的语言部分可以做出对于物理世界的推理。同时有趣的是,最后一个动作,“笨拙”的机器人还是没有做成功:它把海绵抹布掉到了地上。
更多视频可以参考网站:https://say-can.github.io/
4 结论
SayCan将使用强化学习的“行”的能力和大规模语言模型的“言”的能力结合在一起,突出了“行胜于言”的背后思想——仅仅发出可能的行为指令是不够的,还需要结合外在的周围环境,做可以做到的。不过,文章提出了如下的问题,作为未来的思考方向:
1)如何借鉴融合了真实世界的LLM,来进一步完善语言模型本身,如提高它对于世界知识的推理能力。
2)更为本质的,适用于人类的自然语言是否真的是用于机器人编程的本体(ontology)语言?
3)如何更好地在机器人领域融合自然语言理解技术?
可以来到,目前机器人的研究已经逐渐在“软件”算法层面发力了,而且上游的AI算法也很快地应用到这一领域,期待它的更好发展。