本文转自雷锋网,如需转载请至雷锋网官网申请授权。
受到技术进步和开源数据集的推动,过去十年中人工智能经历了一次复兴,其进步之处主要集中在计算机视觉和自然语言处理(NLP)等领域。ImageNet在2010年制作了一个包含2万张内容标签的图片的公开语料库。谷歌于2006年发布了万亿词语料库(Trillion Word Corpus),并从大量的公共网页中获得了n-gram频率。NLP的进步使得机器翻译质量大幅提高,数字助理的应用也迅速扩大,诸如“人工智能是新的电力”和“人工智能将取代医生”之类的言论也越来越多。
像Allen Institute、Hugging Face和Explosion等组织也发布了开放源代码库和在大型语言语料库上预先训练的模型,这使得NLP领域飞速进展。最近,NLP技术通过发布公共注释研究数据集和创建公共响应资源促进了对COVID-19的研究。
然而,其实人工智能领域早已形成。艾伦·图灵(Alan Turing)在1950年就提出了“能思考的机器”的想法,这反映在人们当时对算法能力的研究上,当时人们希望研究出能够解决一些过于复杂而无法自动化的问题(例如翻译)的算法。在接下来的十年里,投资人看好 AI 研究并投入了大量资金,使得翻译、物体识别和分类等研究获得了很大进步。到了1954年,先进的机械词典已经能够进行基于词汇和短语的合理翻译。在一定条件下,计算机可以识别并解析莫尔斯电码。然而,到了20世纪60年代末,这些研究明显受到限制,实际用途有限。数学家詹姆斯·莱特希尔(James Lighthill)在1973年发表的一篇论文中指出,在将自己研究的系统应用于现实世界中的问题时,人工智能研究人员无法处理各种因素的“组合爆炸”。社会上批评声不断,投入资金日益枯竭,人工智能进入了第一个“冬天”,开发基本上停滞不前。
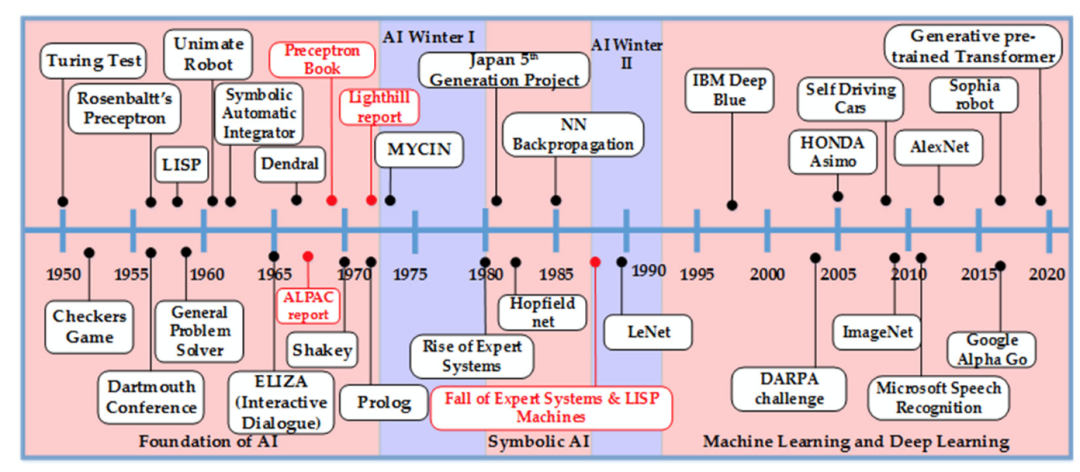
图注:AI 的发展时间线
在过去的几十年里,人们对人工智能的兴趣又复苏了,技术也突飞猛进。NLP最近的研究热点主要与基于 Transformer 的架构有关。然而实际应用的问题仍然值得提出,因为人们对于“这些模型真正在学习什么”感到担忧。2019年的一项研究使用BERT来解决论证理解(argument comprehension)的困难挑战,该模型必须根据一系列事实来确定一个说法是否合理。BERT的表现达到了SOTA,但进一步的研究发现,该模型利用的是语言中的特定线索,而这些线索与论证的“推理”无关。
有时研究员能够在应用算法前就解决好系统里的一切问题,但有时AI系统还是会带有其不应有的学习模式。一个典型例子是COMPAS算法,这种算法在佛罗里达州用来确定一个罪犯是否会再次犯罪。ProPublica 在2016年的一项调查发现,这种算法预估黑人被告比白人被告犯下暴力犯罪的可能性高出77%。更令人担忧的是,高达48%再次犯罪的白人被告会被该算法标记为低风险,而黑人只有28%,两者相差20%。由于该算法是专用算法,其可能利用的线索的透明度有限。但由于这种算法当中不同种族之间的差异如此明显,这表明该算法“眼中”有种族不平等的嫌疑,这既不利于算法自身的性能,也不利于司法系统。

图注:COMPAS算法的应用
在人工智能领域,这种高调的失败并不少见。亚马逊最近废除了一种人工智能招聘算法,因为这种算法更有可能推荐男性担任技术职位,其原因可能是该算法利用了以往的招聘模式。而最顶尖的机器翻译也经常会遇到性别不平等问题和语言资源不足的问题。
现代NLP的缺陷有很多来由。本文将专注于几个代表性问题:在数据和NLP模型的发展中,什么人或物被代表了?这种不平等的代表是如何导致NLP技术利益的不平等分配的?
1 “大”就一定“好”?
一般来说,机器学习模型,尤其是深度学习模型,数据越多,其表现就会越好。Halevy等人(2009)解释说,对于翻译任务来说,与比较小的数据集上训练的更复杂的概率模型相比,在大型数据集上训练的简单模型的表现更好。Sun等人在2017年也重新审视了机器学习可扩展性的想法,指出视觉任务的性能随着提供的示例数量呈对数增长。
人工智能从业者已将这一原则牢记于心,特别是在NLP研究中。自监督目标的出现,如BERT的掩码语言模型(该模型可以根据上下文学习预测单词),基本上使整个互联网都可以用于模型训练。2019年的原始BERT模型是在16 GB的文本数据上训练的,而近期的模型,如GPT-3(2020)是在570 GB的数据上训练的(从45 TB的CommonCrawl中过滤)。Bender等人(2021)将“数据越多越好”这一格言作为模型规模增长背后的驱动思想。但他们的文章引起我的一个思考:这些大型数据集中包含了什么思维?
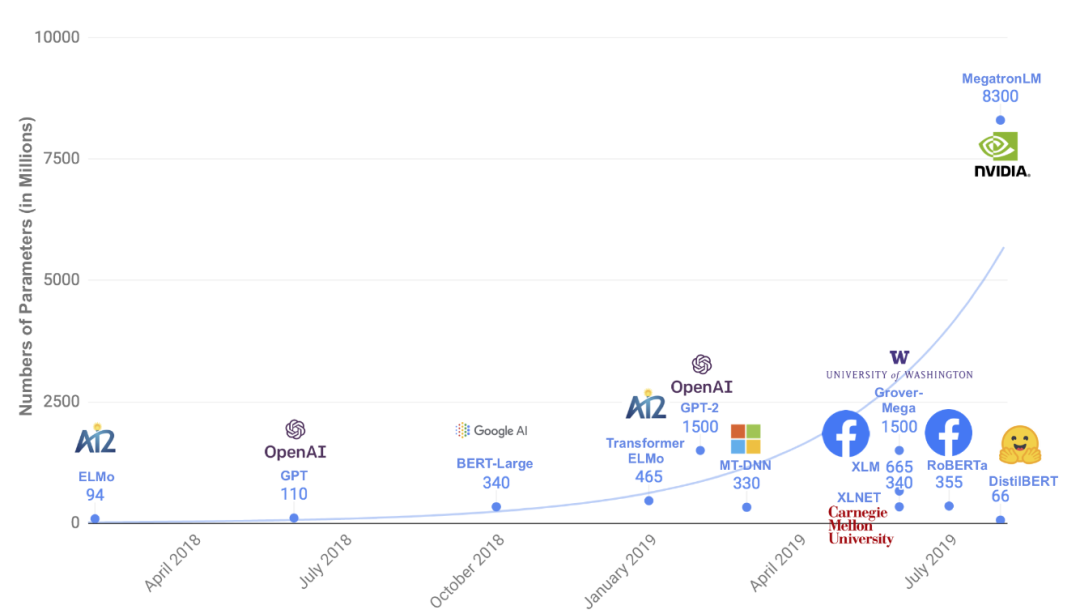
图注:语言模型的规模随时间的推移而增大
Wikipedia是BERT、GPT和许多其他语言模型的来源。但Wikipedia研究发现,其编辑所代表的观点存在问题。大约90%的文章编辑是男性,他们往往是来自发达国家的受过正规教育的白人。他们的身份可能会对维基百科的内容产生影响,比如只有17%的传记是关于女性的,可是被编辑提名删除的传记中却有41%是关于女性的,女性传记被删除内容明显高于常规比例。
NLP模型的另一个主要来源是Google News,包括原始的word2vec算法。从历史上看,新闻编辑室一直由白人男性主导,这种模式在过去十年中没有多大改变。实际上,在过去几十年,这种差异变得更大,这意味着当模型使用旧的新闻数据集时,这种被代表的问题只会变得更糟。
此外,互联网用户倾向于年轻、高收入和白人。GPT模型的来源之一CommonCrawl使用了Reddit的数据,Reddit有67%的用户是男性,70%是白人。Bender等人(2021)指出,GPT-2这样的模型有包容/排斥方法,可能会删除代表特定社区的语言(例如通过排除潜在的冒犯性词汇,就会将代表LGBTQ群体的语言排除在外)。
当前NLP中的许多先进性能都需要大型数据集,这种对数据如饥似渴的劲头已经盖过了人们对数据中所代表的观点看法的关注。然而,从上面的证据可以清楚地看出,有些数据源并不是“中立的”,反而放大了那些历史上、在社会上占据主导地位的人的声音。
而且,即便是有缺陷的数据源也不能平等地用于模型开发。绝大多数标记和非标记数据仅以7种语言存在,约占所有使用者的1/3。这使得世界上其他2/3的国家无法达到这种表现。为了弥补这一差距,NLP研究人员探索了在高资源语言中预训练的BERT模型和低资源语言微调(通常称为Multi-BERT),并使用“适配器”跨语言迁移学习。但是通常来说,这些跨语言方法的表现要比单语言方法差。
这些模型很难跨语言泛化,这一事实可能指向一个更大的问题。乔希等人(2021年)这样解释:“NLP系统接受训练和测试的少数几种语言通常是相关的……这会导致形成一种类型学的回声室。因此,我们的NLP系统从未看到过绝大多数类型多样化的语言现象。”
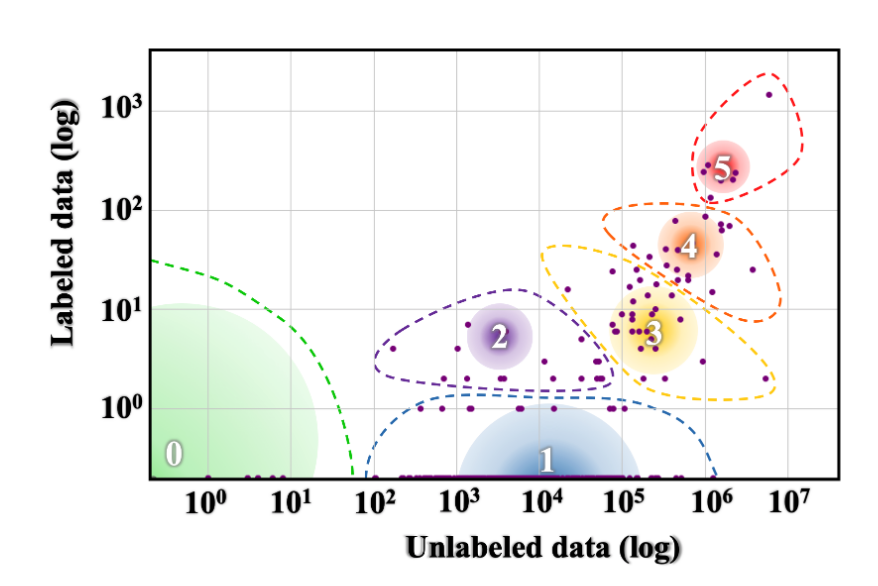
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
图注:语言多样性和包容性在自然语言处理领域的现状和命运
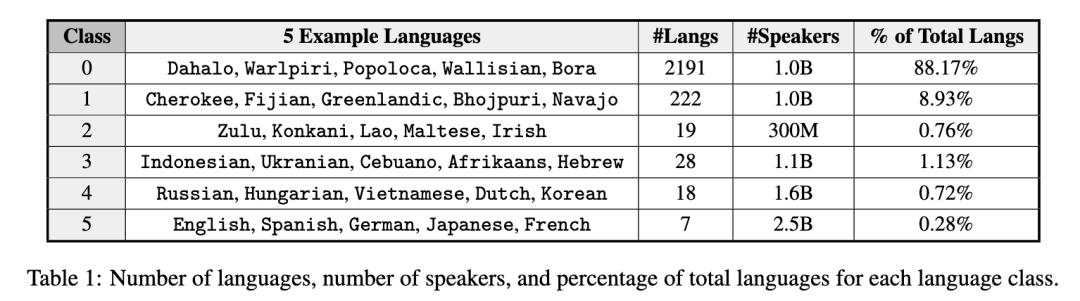
图注:语言多样性和包容性在自然语言处理领域的现状和命运
如上所述,这些系统非常擅长挖掘语言中的线索。因此,它们很可能是在利用一组特定的语言模式,所以当这些系统应用于资源较低的语言时,性能会崩溃。
2 输入的是垃圾,输出的也是垃圾
在上文中,我描述了现代NLP数据集和模型是如何为一组特定的视角「代言」的,这些视角往往是白人、男性和英语使用者的视角。但是,每一个数据集都必须从它的来源入手,解决数据代表的不均衡问题,比如ImageNet 在2019年的更新中删除了60万张图像。这种调整不仅仅是为了统计的稳健性,也是对那些倾向于对女性和有色人种使用性别歧视或种族主义标签的模型的一种回应。
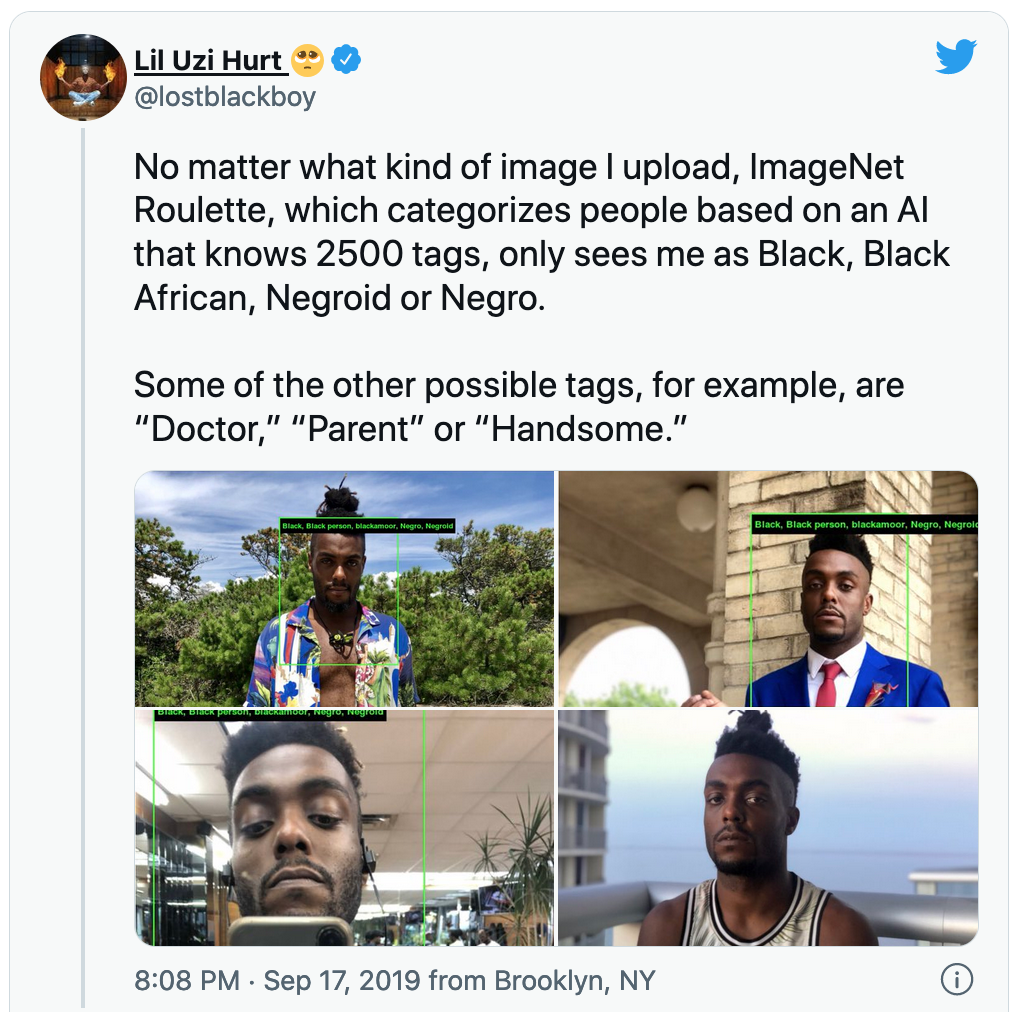
图注:一位Twitter用户在基于ImageNet的模型所生成的图像标签中发现偏见
无论我上传什么样的图片,使用拥有2500个标签的AI来进行分类的ImageNet Roulette,都会把我看成是「Black」(黑人)、「Black African」(非裔黑人)、「Negroid」(黑色人种的)、「Negro」(黑人)。
其它可能出现的标签还有「Doctor」(医生)、「Parent」(父亲)、「Handsome」(帅气的)。
所有的模型都会出错,所以在决定是否使用一个模型时,总是要权衡风险和收益。为了便于对这种风险效益进行评估,我们可以使用现有的常用性能指标,来获得「错误」的发生频率,比如准确率。但是我们非常缺乏了解的是,这些错误是如何分布的?如果一个模型在一个群体中的表现不如另一个群体,这意味着该模型可能会让一个群体受益,而牺牲另一个群体的利益。
我把这种不平等的风险收益分配称为「偏见」。统计偏差被定义为“结果的期望值与被估计的真正潜在定量参数之间的差异”。机器学习中存在许多类型的偏差,但我会主要讨论“历史偏差”和“表征偏差”。历史偏差是指世界上已经存在的偏差和社会技术问题在数据中得到的反映。例如,当一个在ImageNet上训练的模型输出种族主义或性别歧视标签时,它是在复制训练数据的种族主义和性别歧视。表征偏差是由我们从总体中定义和抽样的方式造成的。因为我们的训练数据来自于一个特定群体的视角,因而我们期望训练出的模型会代表这个群体的视角。
在NLP领域,存在于词嵌入模型word2vec和GloVe中的偏见已经被深入研究。这些模型是许多下游任务的基础,它们提供包含句法和语义信息的单词表示。它们都基于自监督技术,根据上下文来对单词进行表示。如果这些表示反映了一个词的真正“意义”,那么我们可以想象,与职业相关的词语(如“工程师”或“管家”)在性别和种族上具有中立性,因为职业类型并不与特定人群关联起来。
然而,Garg等人(2019)发现,职业词汇的表示并非性别中立或种族中立的。与男性性别词汇相比,“管家”这类职业词汇与女性性别词汇(如“she”、“her”)关联更强,而“工程师”这类职业的嵌入词则更接近男性性别词汇。这些问题还延伸到了种族上,与西班牙裔有关的词汇更接近于“管家”,而与亚洲人有关的词汇与“教授”或“化学家”更接近。

图注:该表显示了分别与西班牙裔、亚裔、白人三个种族最密切相关的十大职业类型。引自Garg等(2019)论文“Word embeddings quantify 100 years of gender and ethnic stereotypes”(《词嵌入量化100年来的性别和种族刻板印象》)。
这些问题也存在于大型的语言模型中。比如,Zhao等人(2019)的工作表明,ELMo嵌入把性别信息纳入到职业术语中,并且对男性的性别信息编码比对女性做得更好。Sheng等人(2019)的工作也发现,在使用GPT-2来对完成含有人口统计信息(即性别、种族或性取向)的句子时,会对典型的边缘化群体(即女性、黑人和同性恋者)产生偏见性结果。

图注:该表显示了用OpenAI的GPT-2在给定的不同提示下生成的文本示例。引自Sheng等(2019)论文“The Woman Worked as a Babysitter: On Biases in Language Generation”(《当保姆的女人:论语言生成中的偏见》)。
词嵌入模型ELMo和GPT-2,都是在来自互联网的不同数据集上进行训练的。如上所述,互联网上所代表的观点往往来自那些在历史上处于优势地位并获得更多媒体关注的人。这些观点很可能是偏见问题的根源,因为模型已经内化了那些有偏见的观点。正如Ruha Benjamin在他的《追逐科技》(Race After Technology)一书中所言:
「将世界的美、丑和残忍喂给AI系统却期望它只反映美,这是一种幻想。」
这些NLP模型不仅复制了他们所训练的优势群体的观点,而且建立在这些模型上的技术也加强了这些群体的优势性。如上文所述,目前只有一部分语言拥有数据资源来开发有用的NLP技术(如机器翻译)。但即使是在那些资源丰富的语言中,如果口音不标准,机器翻译和语音识别之类的技术也表现不佳。
例如,Koenecke等人(2020年)发现,亚马逊和谷歌等公司的语音识别软件对非裔美国人的误差率几乎是白人的两倍。这会造成一些不便,因为谷歌助手(Google Assistant)或Alexa对非标准口音的用户来说表现得不太好。这也会对一个人的生活造成重大影响,比如移民工人很难与边境管理人员沟通。因为训练数据中表现出了偏见,所以可以预想,这些应用程序对具有数据「优势」的用户人群的帮助会比其他人群更大。
除了翻译和口译,一个流行的NLP使用场景是内容审核/管理。很难找到一个不包含至少一个垃圾邮件检测训练的NLP项目。但在现实世界中,内容审核意味着它要决定什么类型的言论是「可以接受的」。研究发现,Facebook和Twitter的算法在审核内容时,对非裔美国用户内容进行标记的可能性是白人用户的两倍。一名非裔美国脸书用户因为引用了电视剧《亲爱的白种人》中的一句台词而被冻结了账户,而她的白人朋友则没有受到任何惩罚。
从上面这些例子中,我们可以看到,数据训练中的代表性不均衡造成了不均衡的后果。这些后果更严重地落在了历史上从新技术中获益较少的人群(即女性和有色人种)身上。因此,除非对自然语言处理技术的发展和部署作出实质性的改变,否则它不仅不会给世界带来积极的变化,而且还会加强现有的不平等制度。
3 如何步上“正”轨
我在本文前面提到过,AI 领域现在被炒得很热,这在历史上其实已经出现过一次。在20世纪50年代,工业界和政府对这项令人兴奋的新技术寄予厚望。但是,当实际的应用开始达不到它的承诺时,人工智能的一个「寒冬」就会来临,这个领域得到的关注和资金投入都会变少。尽管现代社会受益于免费、广泛可用的数据集和巨大的处理能力,但如果人工智能仍然只关注全球人口中的一小部分,那么在这次热潮中,也将很难看到它如何兑现自己的承诺。
对于NLP来说,这种「包容性」需求更加迫切,因为大多数应用程序只关注7种最流行的语言。为此,专家们已经开始呼吁更多地关注低资源语言。DeepMind的科学家Sebastian Ruder在2020年发出了一项呼吁,指出“如果技术只面向标准口音的英语使用者,那么它就无法普及”。计算语言学协会(ACL)最近也宣布了2022年会议的「语言多样性」分主题。
然而,包容性不应仅仅被视为数据采集问题。2006年,微软发布了智利土著马普切人(Mapuche)的语言版本的Windows。然而,这项工作是在没有马普切人参与或同意的情况下进行的,马普切部落的人们一点也没有觉得自己被微软的倡议所「接纳」,因为微软未经许可使用他们的语言,他们起诉了微软。要解决NLP技术覆盖范围方面的差距,就需要更多地关注代表性不足的群体。这些群体已经加入了NLP社区,并且已经启动了他们自己的倡议,以扩大NLP技术的效用。像这样的举措,不仅可以将NLP技术应用于更加多样化的数据集,还可以让各种语言的母语人士参与该技术的开发。
正如我之前提到的,当前用于确定什么是「最先进」的NLP的指标,在估计一个模型可能会犯多少错误方面会很有用。然而,它们并不能衡量这些错误在不同人群中是否分布不均(即是否存在偏见)。对此,麻省理工学院的研究人员发布了一个数据集StereSet,用于测量语言模型在多个维度上的偏差。这项工作的结果是一套衡量模型总体表现的指标,以及它与偏好刻板印象关联的倾向性,这很容易让它本身成为一个“排行榜”框架。Drivennda在其Deon ethics checklist(Deon伦理清单)中提出了一种更注重过程的方法。
然而,我们仍在处理一些始终困扰着技术的重大问题:进步往往会让强者受益,并加剧强者与弱者的现有「分野」。要想实现NLP技术的革命性进步,就需要将它变得更好,并与现在不同。Bender等人(2021年)提出了一种更具「价值敏感性」的设计,在这种研究的设计中,可以实现监控哪些观点被纳入,哪些被排除,以及该混合观点的风险效益计算。因此,「成功」并不在于准确率多高,而是在于技术能否推动体现利益相关者的价值观。
这是一个非常有力的建议,但这意味着,如果一项倡议不太可能促进关键价值观的进步,那么它可能就不值得追求。Paullada等人(2020年)指出,“一个映射可以被学习并不意味着它有意义”。如上文所举例,一种算法会被用来确定一个罪犯是否可能再次实施犯罪。据报道,该算法的AUC分数很高,但是,它学到了什么?如上所述,模型是它的训练数据的产物,因此它很可能会重现司法系统中已经存在的任何一种偏见。这就对这种特殊算法的价值提出了质疑,也对判决算法的大规模使用提出了挑战。而我们会看到,对价值敏感的设计可能会带来一种非常不同的方法。
归功于研究人员、开发人员和整个开源社区的努力,NLP最近取得了令人震惊的进步。从机器翻译到语音助手,再到病毒研究(如COVID-19),NLP从根本上改变了我们所使用的技术。但要取得进一步的进展,不仅需要整个NLP社区的工作,还需要跨职能团体和学科的工作。我们不应该追求指标上的边际收益,而应该着眼于真正具有「变革性」的改变,这意味着我们要去理解谁正在被「落在后面」,并在研究中纳入他们的价值观。