













译者 | 夏东威
审校 | 梁策 孙淑娟
在软件应用程序之间映射数据是一个耗时的过程,这需要进行深入的准备,对数据源和目标有较好的理解,并要根据方法进行实际开发。
在任何应用程序集成、数据迁移以及一般的数据管理计划中,数据映射都是最关键的步骤之一。甚至可以这么认为:集成项目的成功在很大程度上取决于源数据到目标数据的正确映射。
本文将探讨有关数据映射的优秀实践,包括类型、常用方法以及一些有用的数据映射工具。
一、开门见山:数据映射意味着什么?
本质上,数据映射是将数据字段从源系统(业务应用程序或数据库)连接到目标系统的过程。
许多应用程序在前端共享相同的公共字段命名模式,但在后台,这些相同的字段可以有完全不同的标签。拿“顾客”字段举例:在公司CRM系统的源代码中,它可能仍然有“顾客”的标签,但是你的ERP系统称它为“客户”,你的财务工具称它为“顾客”,而你的组织用于客户讯息的工具将完全映射它的“用户”。这样的标签难题可能正是最常见的一种数据映射示例。
更为复杂的是,如果一个系统输出的两个字段的数据被期望作为另一个系统的一个字段的数据输入(或相反),那么你该怎么办呢?“名字/姓氏”字段经常出现这种情况,比如电子商务系统中的某个客户“Allan”“McGregor”需要在您的ERP中成为“Allan McGregor”。或者通过公司网站提交的潜在客户电子邮件地址需要变成“名字:Steven”,以及客户关系管理工具中的“姓氏:Davis”和“公司:Rangers”。所以现在讨论不仅仅是映射相关的数据字段问题,还涉及数据转换。
想象一下,业务应用程序模块和流程(业务伙伴、领导人员、销售订单、付款单、发票、产品、客户数据等)有几十种,同时含有大量不同的数据字段,这些数据字段必须从一个系统无缝地流向下一个系统。那么,很容易理解为什么数据集成项目可能需要几个月才能完成,而且还会出现成本失控的情况。
二、数据映射的类型有哪些?
尤其是在涉及复杂项目时,有两种类型的数据映射需要考虑:
- 逻辑数据映射是项目的一个更高层次的概念阶段。
- 物理数据映射是一个面向实现的阶段,而不是实际操作阶段。
逻辑数据映射可以看作是数据建模的第一步。它可以是概念模型的一部分,在概念模型中,我们识别现实生活中的对象,并将其与组织相关的概念相匹配,例如,将产品信息、产品订单历史记录和产品可用性分组为单个概念“产品”。
在更复杂的数据管理项目中,逻辑阶段可以从概念模型中分离出来。在这种情况下,它将遵循后者的内容,而我们的任务将是在组织内定义逻辑实体,为每个实体分配属性,并在这些实体之间建立关系,从而构建代表其所有实体的整个业务的整体逻辑数据模型。
简单起见,我们将一直使用一个非常基本的场景,在这个场景中,我们只需要在一个源系统和一个目标系统之间映射数据。下图显示了在这种场景下逻辑数据模型的一个非常简化的版本。这一阶段定义的规则更多是应用于逻辑概念而不是实际实现,但它们可以作为更彻底的物理数据映射的基础。
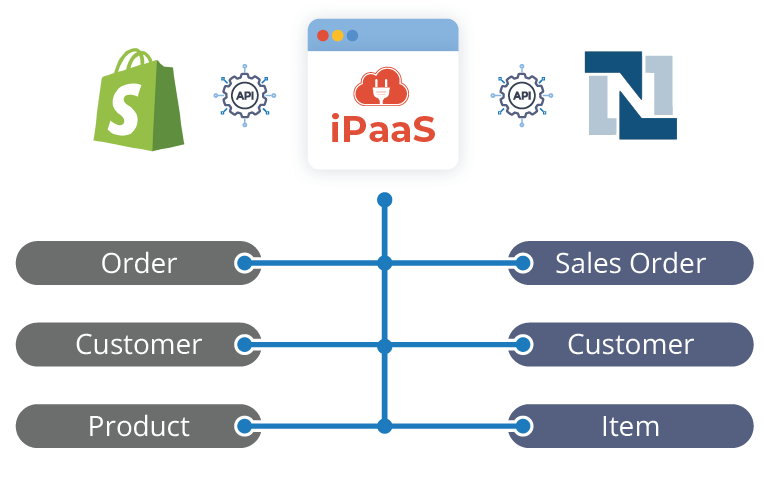
在逻辑数据模型架构完成之后,我们可以从物理数据模型开始,它基于源系统和目标系统中数据对象的实际命名。尤其是在大型团队中,这些信息应该尽可能具体和详细,以避免不必要的错误和项目延迟。这就是我们以上的逻辑数据映射案例在进入下一阶段时呈现的样子:
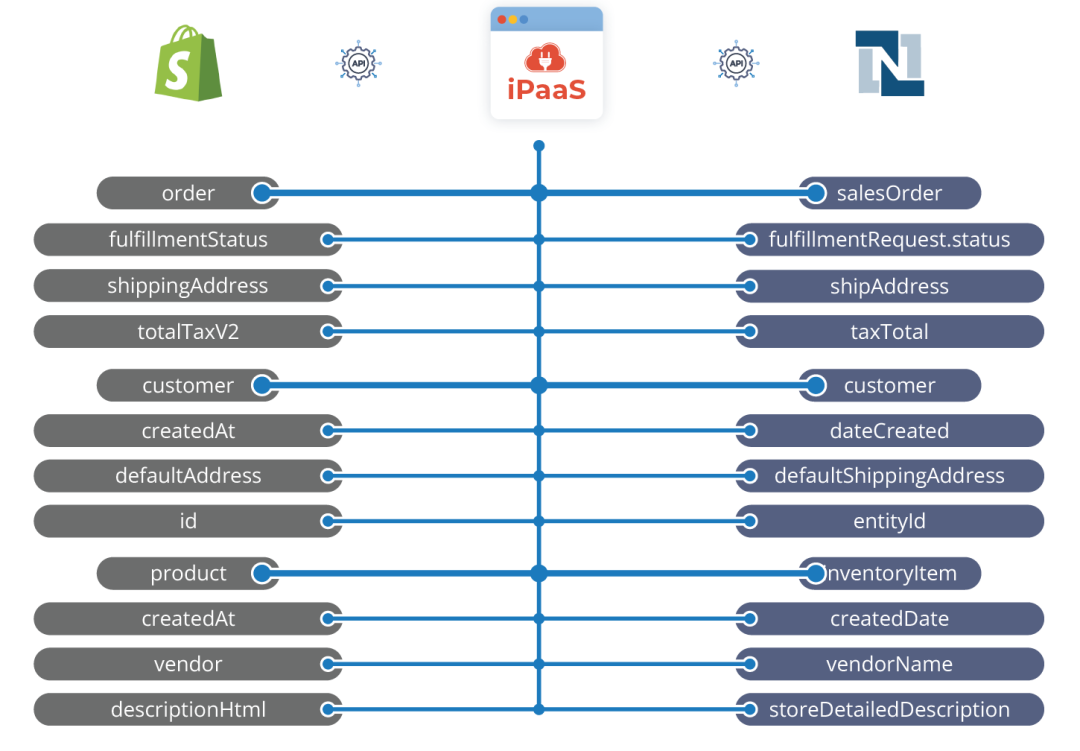
关于这个话题,有几个有趣的资源可以参考。我们可以推荐的一本书是《数据仓库设计的数据映射》 (Data Mapping for Data Warehouse Design),尽管它不能1:1地转换为业务应用程序之间的映射。通常,按这些阶段实施数据映射项目应被视为数据映射优秀实践。这一过程规划得越好,记录得越完备,执行起来就越容易、越迅速。
三、三种常见的数据映射方法
正如上文所示,数据映射多少需要一些技术理解,具体取决于数据映射方法。大体来说,有三种方法可供选择:
- 手动
- 半自动化
- 全自动
每种方法都有其优缺点。
1.手动数据映射
手动数据映射本身就是一门学问。因为它不仅需要很好地理解转换规则和编程语言,还需要足够的人力和时间资源来创建地图、记录步骤,并随着连接的软件系统数量的增加而执行后续的更新和更改。
优点:通过这种方法,您可以百分之百地确定实施过程完全符合业务需求。此外,也不需要依赖任何第三方工具。
缺点:它非常耗时,代码非常繁重,而且容易出错。假如专门数据映射人员从团队离职,那么他们的继任者可能很难理解映射完成的过程。
2.半自动数据映射
有时也称为模式映射,在这种方法中,您可以使用一个软件工具,在无需开发人员参与的情况下,将类似的数据模式链接在一起。为此,该工具将比较源系统和目标系统的模式,并生成一个关系图,随后,开发者将审查这个关系图,并做出必要修改。与手动数据映射方法类似,半自动映射工具可以用相关的编码语言生成输出代码。
优点:这种方法仍然为开发人员提供了很大的灵活性,但与手动数据映射方法相比,这种方法的耗时不见得少很多。
缺点:它同样要求人员有相当高水平的编码技能,同时手动和自动操作之间的切换仍然是资源密集型的。
3.全自动数据映射
全自动数据映射可能是最主流的方法,这意味着有一整套产品和工具可以促进数据集成的自动化低代码/无代码方法,从而实现数据映射。这类工具具有拖放或点击选择的图形界面,这种图形界面易于理解使用,不仅适用于经验丰富的程序员和IT架构师,也适用于初级开发人员甚至业务线用户,使数据映射过程对所有人都不再有门槛。一些现代工具甚至具有自然语言处理 (NLP) 功能,可以完全自动匹配数据字段。
优点:全自动数据映射为开发人员节省了大量时间,且因为需要的高深技术知识较少,它可供范围更广的IT员工使用;全自动数据映射易于扩展,并为数据集成项目提供了许多有用的功能(安排日程、各种部署、预构建模板等)。
缺点:它是一个组织将依赖的第三方工具,入门通常至少需要一定程度的培训,且成本可能会迅速增加,具体取决于各个供应商的定价模式。
四、哪些工具用于数据映射?
这个问题的答案取决于所用的方法。
1.半自动方法
如果您决定采用半自动化或模式映射方法,以下是一些数据映射工具,在多个社区讨论和研究论文中它们吸引了人们的眼球:
(1)Clio
这一原型研究工具由IBM的阿尔马登研究中心开发,它允许在关系模式和XML模式之间进行映射,并支持XQuery、XSLT 1.0、SQL和SQL/XML语言。
(2)MapForce2005
它是Altova的XML工具套件的一部分,与Clio一样,MapForce2005是专门为模式映射和生成转换查询而设计的。
(3)Stylus Studio 6
它是Progress Software的XML开发环境,聚焦于XQuery/XSLT可视化和转换。
(4)Oracle Warehouse Builder 10g Release 1
它是基于Oracle 10g数据库系统的数据仓库开发工具。ETL(提取、转换、加载)过程是这个工具的其中一部分,有一个模式映射步骤。该工具代表了目前市场上许多可用的ETL解决方案。
2、全自动方法
这一类的数据映射工具从来都不是孤单一个。意思是说,数据映射只是在一个产品内提供的一整套工具里的一种功能。理由是,如果您想自动化数据映射过程,为什么还要让数据管理任务中的其他元素采用手动?
考虑到这一点,当你采用低代码/无代码的方法进行数据映射和数据管理时,在对任何工具评估之前,你应该问自己两个问题,即:谁将是目标用户?在数据交换自动化方面,未来计划是什么?
这些问题的答案将在很大程度上影响你的搜索策略。您可以为您的业务线用户或非常基本的自动化场景选择100%无代码解决方案,比如Zapier。而对于复杂的自动化任务和你的IT团队来说,可能你更偏好低代码的iPaaS解决方案,它提供高水平的自动化,但也为灵活性和自由度留出了余地。
五、在数据映射工具中寻找什么
在结束讨论之前,我们简要介绍一下优秀的数据映射工具应该具有的主要功能和特性:
- 直观的无代码或低代码映射界面,记住:这不是说谁优于谁,而是取决于你的个性需求和目标用户。
- 支持各种结构化数据格式(CSV、XML、JSON等),理想情况下,还应该支持非结构化和半结构化数据格式。
- 验证过程中能进行语法和错误检查。
- 支持条件映射(例如基于内容的映射)和基于规则的映射。
- 映射过程中支持内置的数据转换功能。
- 用样本数据运行测试和调试的能力。
六、结论
在软件应用程序之间映射数据是一个耗时的过程,需要深入准备并制定周密策略、对源数据和目标数据有一定知识了解,以及根据自身的方法展开实际开发。必须要承认,即使使用所谓的“全自动”方法,数据映射也不是真正的“全自动”。例如,可能仍然需要开发人员验证和更正映射结果。但是,这些工具仍然可以将人工参与降至最低,从而为其他关键型任务释放宝贵资源。
原文链接:https://dzone.com/articles/data-mapping-best-practices-a-brief-guide-to-types
译者介绍
夏东威,51CTO社区编辑,信息系统项目师,中国人民大学传播学硕士。具有复合型知识结构,有20多年IT上市公司市场总监、资深研究员、IT项目负责人经验。目前任职北京北信源软件股份有限公司资深研究员,担任《东威智库》和《东哥安全观》公众号主编。
























