一、二叉堆分类
二叉堆根据排序不同可分为大根堆和小根堆。
大根堆
在是完全二叉树的前提下,其节点值大于其左右子节点值,称为大根堆。在大根堆中根节点是所有堆节点中的最大值。
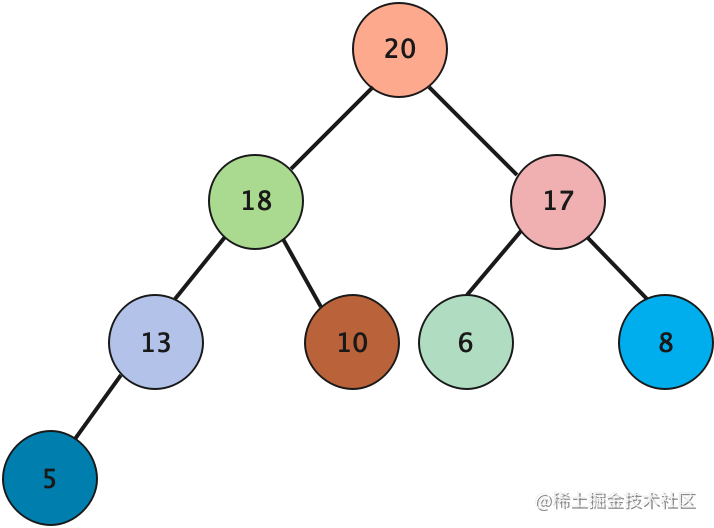
小根堆
在是完全二叉树的前提下,其节点值小于其左右子节点值,称为小根堆。在小根堆中根节点是所有堆节点中的最小值。
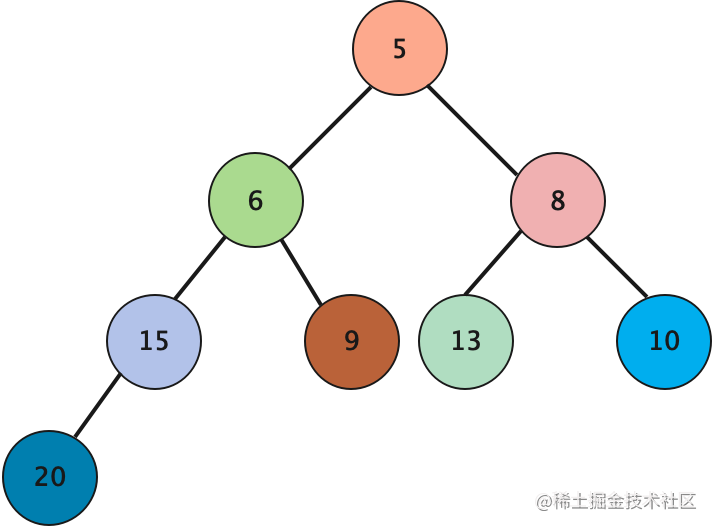
二、二叉堆的存储
上述阐述了二叉堆其实就是一棵完全二叉树,然后数据满足某些特性,那么在编程中应该如何存储这些数据呢?这些数据间满足那些关系呢?
1.以数组结构存储二叉堆
在编程中我们会以数组存储二叉堆,以上述的最大堆为例,存储到数组中为如下结构:

2.二叉堆中父子节点间满足何种关系
既然数据将存储到数组中,那么就必须知道父子节点之间的关系,即:
(1)在知道父节点的索引的时候必须找到其对应的子节点;
(2)在知道子节点的索引的时候找到其对应的父节点;
如下的二叉堆,设置其根节点索引为0,然后依次递增:
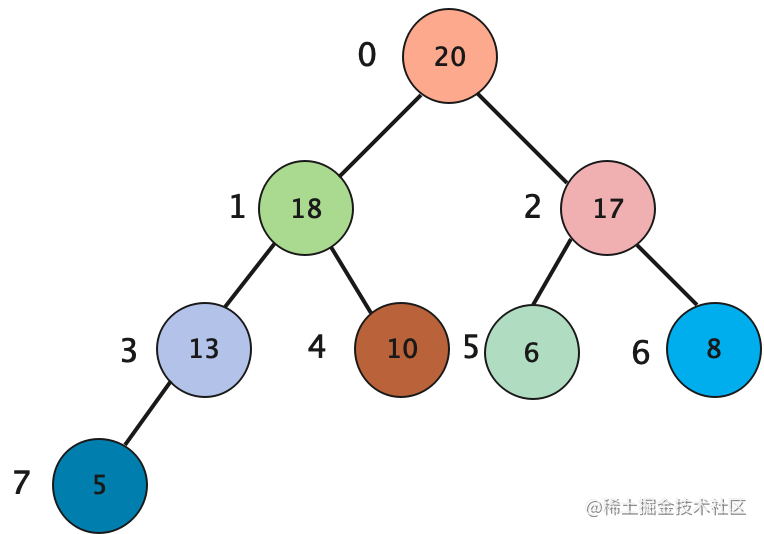
已知某节点的索引为i,则其左右子节点索引为:
- 左节点索引 = 2 * i + 1
- 右节点索引 = 左节点索引 + 1
已知某节点的索引为i,则其父节点索引为:
- 父节点 = parseInt((i - 1) / 2)
三、堆的基本操作
当遇到二叉堆的时候,我们应该学会如何构建一个大根堆(小根堆),这个时候就涉及到加堆和减堆的过程,下面让从加堆和减堆开始,从而使我们能够丝滑般的了解整个二叉堆的构建过程。(注:下面的例子以大根堆为例)
// 注:此处是封装的交换数组中元素的方法
// 数组中交换数据
function swap(arr, i, j) {
let temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
1.加堆
加堆的过程实际上就是再往堆里面加入一个新的元素,然后维护该堆结构的过程,实际上就是在数组尾部加入一个元素,然后通过不断上浮,使其又调整为二叉堆结构的过程。
// 大根堆加堆过程中
function heapInsert(arr, index) {
// 比较当前位置和其父位置,若大于其父位置,则进行交换,并将索引移动到其父位置进行循环,否则跳过
// 结束条件是比其父位置小或者到达根节点处
while (index > 0 && arr[index] > arr[parseInt((index - 1) / 2)]) {
swap(arr, index, parseInt((index - 1) / 2));
index = parseInt((index - 1) / 2);
}
return arr;
}
有了加堆的过程,很容易我们就可以实现创建二叉堆,如下所示:
// 创建二叉堆
function createBigTopHeap(arr) {
for (let i = 0; i < arr.length; i++) {
arr = heapInsert(arr, i);
}
return arr;
}
const arr = [1, 5, 9, 10, 8, 12];
console.log(createBigTopHeap(arr)); // [ 12, 9, 10, 1, 8, 5 ]
2.减堆
减堆的过程就是将堆顶元素A和最后元素B交换,然后删除A元素并将B元素调整到合适的位置的过程,实际上就是将堆顶数据交换后,下沉数据的过程
// 减堆过程
// size指的是这个数组前多少个数构成一个堆
// 如果想把堆顶弹出,则把堆顶和最后一个数交换,把size减1,然后从0位置经历一次heapify,调整一下,剩余部分变成大顶堆
function heapify(arr, index, size) {
// 获取其左节点索引
let left = 2 * index + 1;
while (left < size) {
// 判断一下左右子节点哪个值最大,获取其最大值
let largest = (left + 1 < size && arr[left] < arr[left + 1]) ? left + 1 : left;
// 判断左右子节点最大值与当前要比较的节点哪个大
largest = arr[index] > arr[largest] ? index : largest;
// 如果最大值索引和传进来的索引一样,则该值到达指定位置,直接结束循环
if (index === largest) {
break;
}
// 进行交换,改变索引及其左子节点
swap(arr, index, largest);
index = largest;
left = 2 * index + 1;
}
return arr;
}
const arr = [1, 5, 9, 10, 8, 12];
console.log(createBigTopHeap(arr));
// 交换堆顶数据与最后位置数据
swap(arr, 0, arr.length - 1);
// 通过下沉的方式获取新的堆结果
console.log(heapify(arr, 0, arr.length - 1));
四、叉堆的用途
因为二叉堆能够高效的找出最大值和最小值,所以可用于堆排序和构建优先队列。
1.堆排序
堆排序是常见的一种排序算法,整个堆排序过程如下所示:
- 让数组变成大根堆。
- 把最后一个位置和堆顶交换。
- 则最大值在最后,则剩余部分做heapify,则重新调整为大根堆,则堆顶位置和该部分最后位置做交换。
- 重复进行,直到减完,则这样最后就调整完毕,整个数组排完序(为一个升序)。
function heapSort(arr) {
if (arr === null || arr.length === 0) {
return [];
}
// 首先创建大根堆
for (let i = 0; i < arr.length; i++) {
arr = heapInsert(arr, i);
}
let size = arr.length; // 这个值用来指定多少个数组构成堆
// 由于当前已经是大根堆,所以直接交换
swap(arr, 0, --size);
while (size > 0) {
// 重新变成大顶堆
heapify(arr, 0, size);
// 进行交换
swap(arr, 0, --size);
}
return arr;
}
const arr = [1, 5, 9, 10, 8, 12];
console.log(heapSort(arr)); // [ 1, 5, 8, 9, 10, 12
2.优先队列
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。通常采用堆数据结构来实现。
优先队列的插入
优先队列中元素的插入就是上述heapInsert过程,通过将元素添加到数组末尾,然后通过上浮的方式将内容插入到合适位置。
优先队列中元素的删除
优先队列中元素的删除就是将根节点的元素与最后元素交换,然后将交换后的根节点下沉,调整到合适位置,重新构成二叉堆。