作者 | 马彬
针对视频数据,如何通过计算机视觉技术用相关数据,为用户和商家提供更好的服务,是一项重要的研发课题。本文将为大家分享短视频内容理解与生成技术在美团业务场景的落地实践。
1. 背景
美团围绕丰富的本地生活服务电商场景,积累了丰富的视频数据。
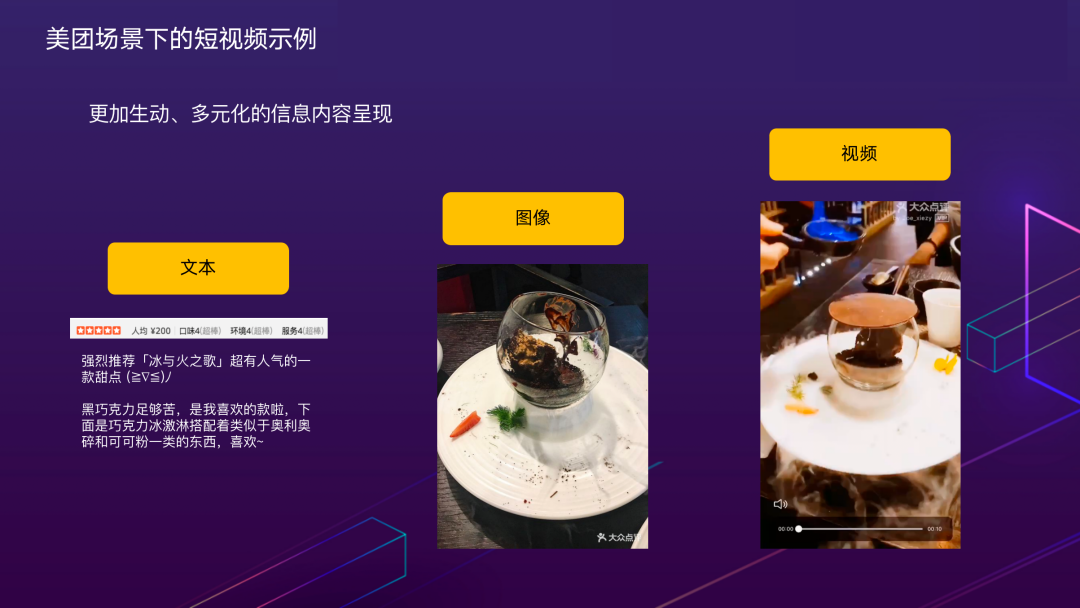
上面展示了美团业务场景下的一个菜品评论示例。可以看到,视频相较于文本和图像可以提供更加丰富的信息,创意菜“冰与火之歌”中火焰与巧克力和冰淇淋的动态交互,通过短视频形式进行了生动的呈现,进而给商家和用户提供多元化的内容展示和消费指引。
视频行业发展
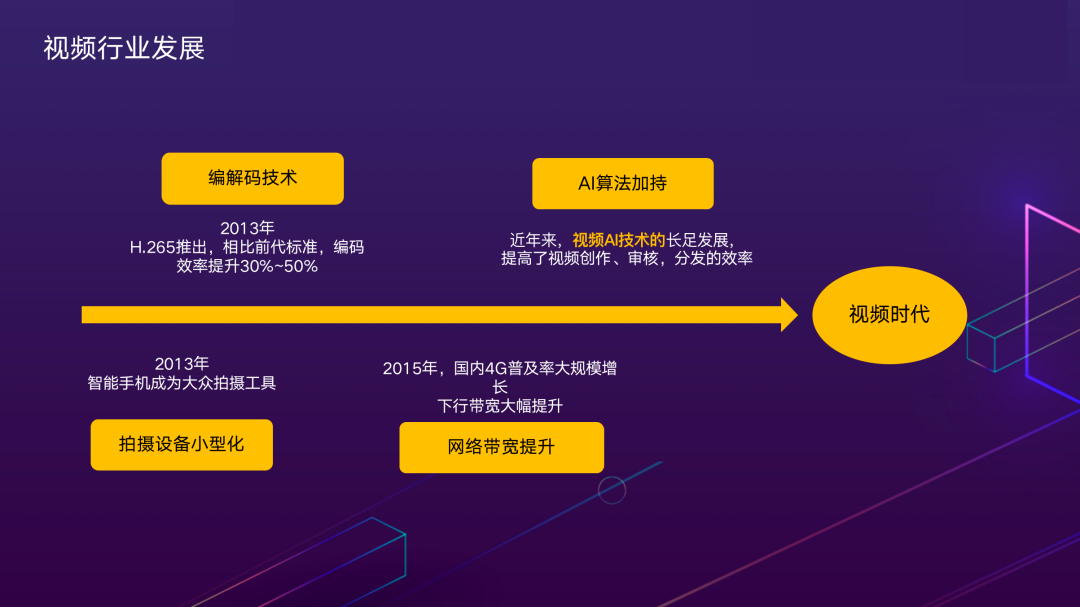
我们能够快速进入了视频爆炸的时代,是因为多个技术领域都取得了显著的进步,包括拍摄采集设备小型化、视频编解码技术的进步、网络通信技术的提升等。近年来,由于视觉AI算法不断成熟,在视频场景中被广泛应用。本文将主要围绕如何通过视觉AI技术的加持,来提高视频内容创作生产和分发的效率。美团AI——场景驱动技术
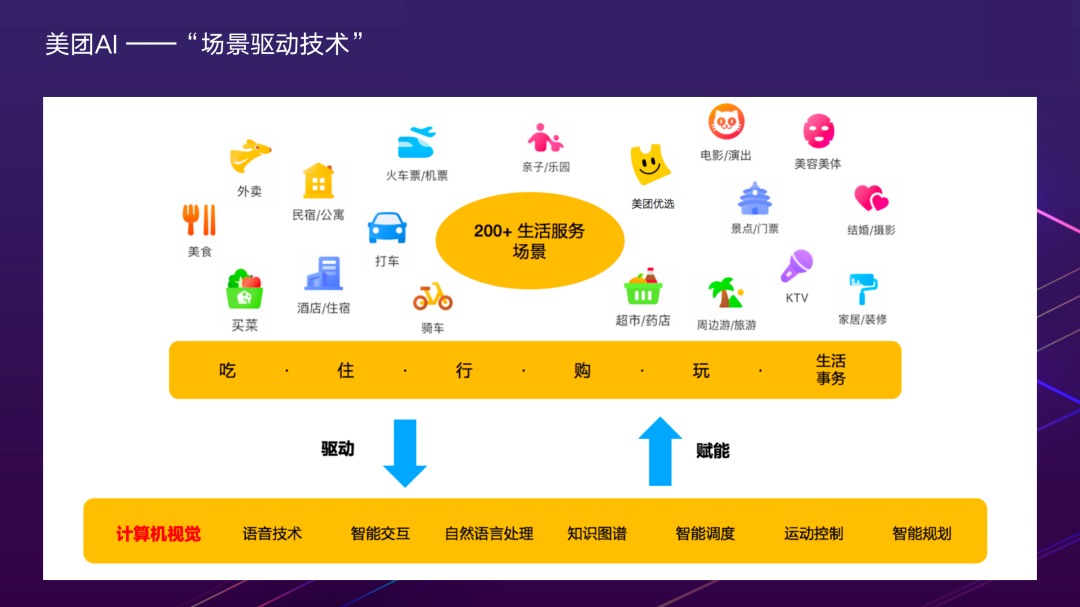
说到美团,大家首先会想到点外卖的场景,不过,除了外卖之外,美团还有其他200多项业务,涵盖了“吃”、“住”、“行”、“玩”等生活服务场景,以及“美团优选”“团好货”等零售电商。丰富的业务场景带来了多样化的数据以及多元化的落地应用,进而驱动底层技术的创新迭代。同时,底层技术的沉淀,又可以赋能各业务的数字化、智能化升级,形成互相促进的正向循环。美团业务场景短视频
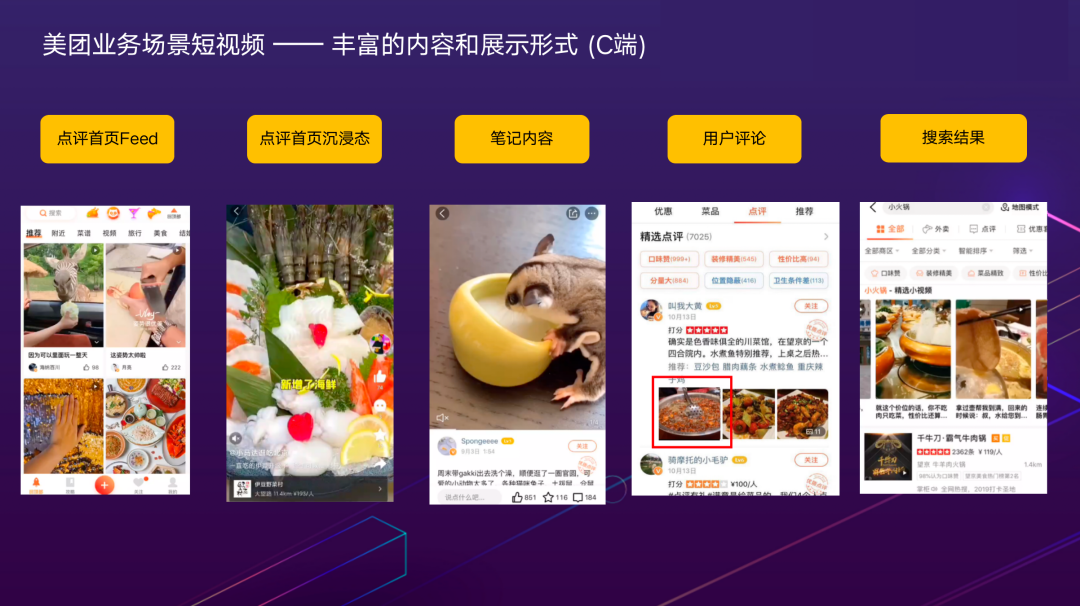
丰富的内容和展示形式(C端)本文分享的一些技术实践案例,主要围绕着“吃”来展开。美团在每个场景站位都有内容布局和展示形式,短视频技术在美团C端也有丰富的应用,例如:大家打开大众点评App看到的首页Feed流视频卡片、沉浸态视频、视频笔记、用户评论、搜索结果页等。这些视频内容在呈现给用户之前,都要先经过了很多算法模型的理解和处理。

丰富的内容和展示形式(B端)而在商家端(B端)的视频内容展示形式包括,景区介绍——让消费者在线上感受更立体的游玩体验;酒店相册速览——将相册中的静态图像合成视频,全面地展示酒店信息,帮助用户快速了解酒店全貌(其中自动生成的技术会在下文2.2.2章节进行介绍);
商家品牌广告——算法可以通过智能剪辑等功能,降低商家编辑创作视频的门槛;商家视频相册——商家可以自行上传各类视频内容,算法为视频打上标签,帮助商家管理视频;商品视频/动图——上文提到美团的业务范围也包括零售电商,这部分对于商品信息展示就非常有优势。举个例子,生鲜类商品,如螃蟹、虾的运动信息很难通过静态图像呈现,而通过动图可为用户提供更多商品参考信息。短视频技术应用场景
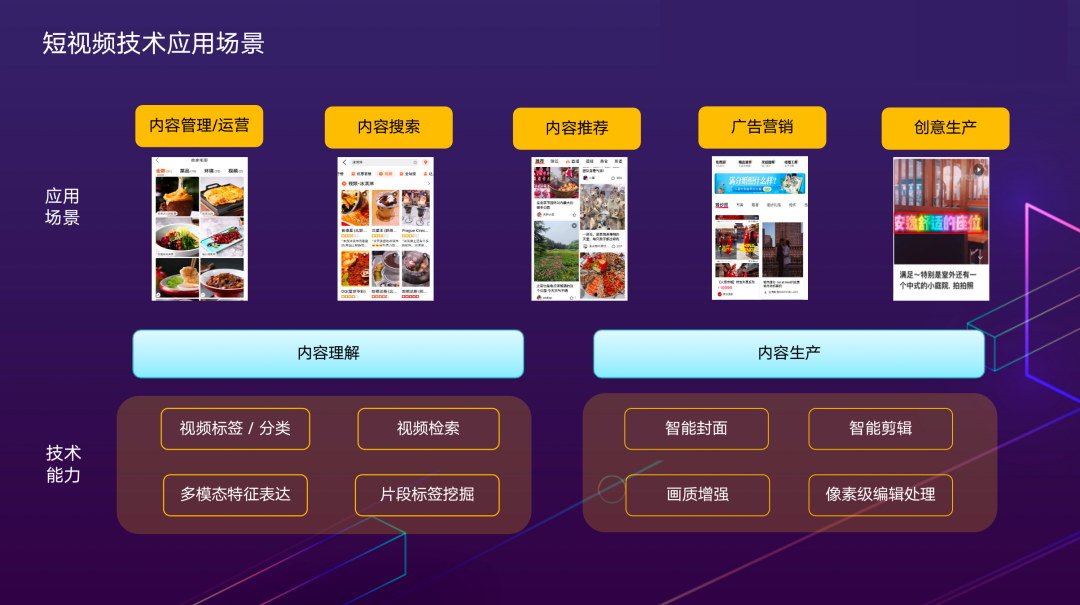
从应用场景来看,短视频在线上的应用主要包括:内容运营管理、内容搜索推荐、广告营销、创意生产。底层的支撑技术,主要可以分为两类:内容理解和内容生产。内容理解主要回答视频中什么时间点,出现什么样的内容的问题。内容生产通常建立在内容理解基础上,对视频素材进行加工处理。典型的技术包括,视频智能封面、智能剪辑。下面我将分别介绍这两类技术在美团场景下的实践。
2. 短视频内容理解和生成技术实践
2.1 短视频内容理解
2.1.1 视频标签
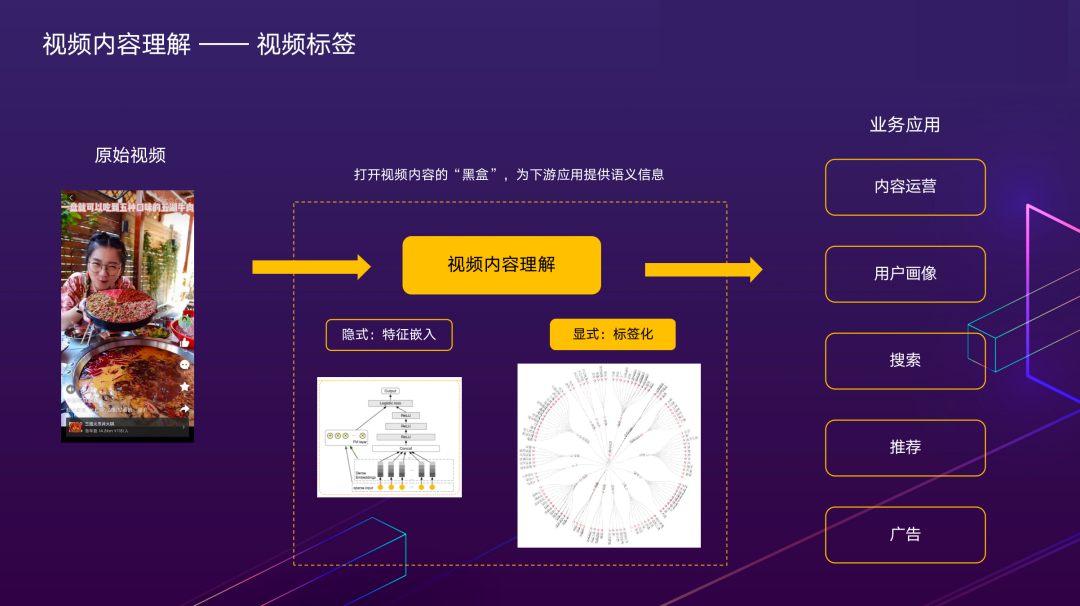
视频内容理解的主要目标是,概括视频中出现的重要概念,打开视频内容的“黑盒”,让机器知道盒子里有什么,为下游应用提供语义信息,以便更好地对视频做管理和分发。根据结果的形式,内容理解可以分为显式和隐式两种。
其中,显式是指通过视频分类相关技术,给视频打上人可以理解的文本标签。隐式主要指以向量形式表示的嵌入特征,在推荐、搜索等场景下与模型结合直接面向最终任务建模。可以粗略地理解为,前者主要面向人,后者主要面向机器学习算法。显式的视频内容标签在很多场景下是必要的,例如:内容运营场景,运营人员需要根据标签,开展供需分析,高价值内容圈选等工作。
上图中展示的是内容理解为视频打标签的概要流程,这里的每个标签都是可供人理解的一个关键词。通常情况下,为了更好地维护和使用,大量标签会根据彼此之间的逻辑关系,组织成标签体系。
2.1.2 视频标签的不同维度与粒度
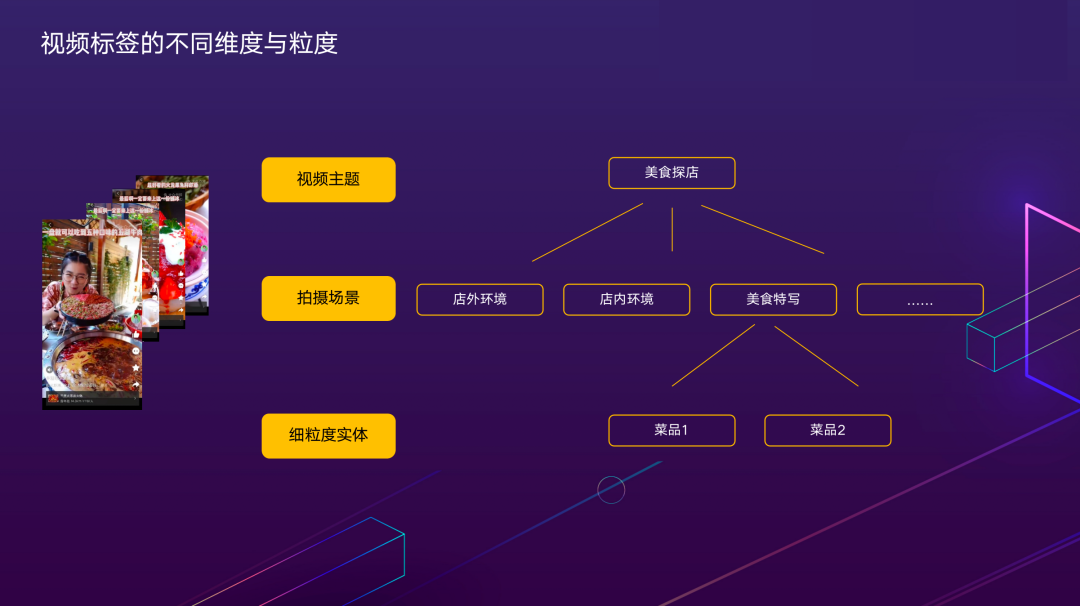
那么视频标签的应用场景有哪些?它背后的技术难点是什么?在美团场景下比较有代表性的例子——美食探店视频,内容非常丰富。标签体系的设定尤为关键,打什么样的标签来描述视频内容比较合适?首先,标签的定义需要产品、运营、算法多方面的视角共同敲定。在该案例中,共有三层标签,越上层越抽象。
其中,主题标签对整体视频内容的概括能力较强,如美食探店主题;中间层会进一步拆分,描述拍摄场景相关内容,如店内、店外环境;最底层拆分成细粒度实体,理解到宫保鸡丁还是番茄炒鸡蛋的粒度。不同层的标签有不同的应用,最上层视频主题标签可应用于高价值内容的筛选及运营手段。
它的主要难点是抽象程度高,“美食探店”这个词概括程度很高,人在看过视频后可以理解,但从视觉特征建模的角度,需要具备什么特点才能算美食探店,对模型的学习能力提出了较大的挑战。
2.1.3 基础表征学习
解决方案主要关注两方面:一方面是与标签无关的通用基础表征提升,另一方面是面向特定标签的分类性能提升。初始模型需要有比较好基础表征能力,这部分不涉及下游最终任务(例如:识别是否是美食探店视频),而是模型权重的预训练。好的基础表征,对于下游任务的性能提升事半功倍。由于视频标签的标注代价非常昂贵,技术方案层面需要考虑的是:如何在尽量少用业务全监督标注数据的情况下学习更好的基础特征。
首先,在任务无关的基础模型表征层面,我们采用了在美团视频数据上的自监督预训练特征,相比在公开数据集上的预训练模型,更加契合业务数据分布。 其次,在语义信息嵌入层面(如上图所示),存在多源含标签数据可以利用。值得一提的是,美团业务场景下比较有特色的弱标注数据,例如:用户在餐厅中做点评,图片和视频上层抽象标签是美食,评论文本中大概率会提到具体在店里吃的菜品名称,这是可挖掘的优质监督信息,可以通过视觉文本相关性度量等技术手段进行清洗。这里展示了自动挖掘出的标签为“烤肉”的视频样本。
其次,在语义信息嵌入层面(如上图所示),存在多源含标签数据可以利用。值得一提的是,美团业务场景下比较有特色的弱标注数据,例如:用户在餐厅中做点评,图片和视频上层抽象标签是美食,评论文本中大概率会提到具体在店里吃的菜品名称,这是可挖掘的优质监督信息,可以通过视觉文本相关性度量等技术手段进行清洗。这里展示了自动挖掘出的标签为“烤肉”的视频样本。

视频样本
通过使用这部分数据做预训练,可以得到一个初始的Teacher Model,给业务场景无标注数据打上伪标签。这里比较关键的是由于预测结果不完全准确,需要基于分类置信度等信息做伪标签清洗,随后拿到增量数据与Teacher Model一起做业务场景下更好的特征表达,迭代清洗得到Student Model,作为下游任务的基础表征模型。在实践中,我们发现数据迭代相较于模型结构的改进收益更大。
2.1.4 模型迭代
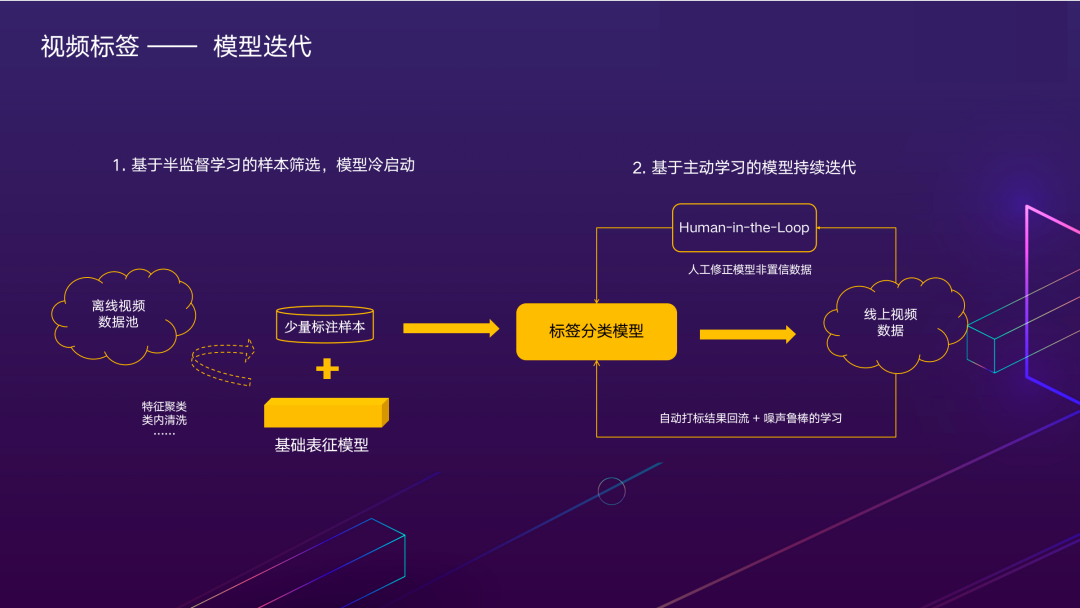 面向具体标签的性能提升主要应对的问题是,如何在基础表征模型的基础上,高效迭代目标类别的样本数据,提升标签分类模型的性能。样本的迭代分为离线和在线两部分,以美食探店标签为例,首先需要离线标注少量正样本,微调基础表征模型得到初始分类模型。这时模型的识别准确率通常较低,但即便如此,对样本的清洗、迭代也很有帮助。设想如果标注员从存量样本池里漫无目的地筛选,可能看了成百上千个视频都很难发现一个目标类别的样本,而通过初始模型做预筛选,可以每看几个视频就能筛出一个目标样本,对标注效率有显著的提升。第二步如何持续迭代更多线上样本,提升标签分类模型准确率至关重要。我们对于模型线上预测的结果分两条回流路径。线上模型预测结果非常置信,或是若干个模型认知一致,可以自动回流模型预测标签加入模型训练,对于高置信但错误的噪声标签,可以通过模型训练过程中的一些抵抗噪声的技术,如:置信学习进行自动剔除。更有价值的是,我们在实践中发现对于模型性能提升ROI更高的是人工修正模型非置信数据,例如三个模型预测结果差异较大的样本,筛出后交给人工确认。这种主动学习的方式,可以避免在大量简单样本上浪费标注人力,针对性地扩充对模型性能提升更有价值的标注数据。
面向具体标签的性能提升主要应对的问题是,如何在基础表征模型的基础上,高效迭代目标类别的样本数据,提升标签分类模型的性能。样本的迭代分为离线和在线两部分,以美食探店标签为例,首先需要离线标注少量正样本,微调基础表征模型得到初始分类模型。这时模型的识别准确率通常较低,但即便如此,对样本的清洗、迭代也很有帮助。设想如果标注员从存量样本池里漫无目的地筛选,可能看了成百上千个视频都很难发现一个目标类别的样本,而通过初始模型做预筛选,可以每看几个视频就能筛出一个目标样本,对标注效率有显著的提升。第二步如何持续迭代更多线上样本,提升标签分类模型准确率至关重要。我们对于模型线上预测的结果分两条回流路径。线上模型预测结果非常置信,或是若干个模型认知一致,可以自动回流模型预测标签加入模型训练,对于高置信但错误的噪声标签,可以通过模型训练过程中的一些抵抗噪声的技术,如:置信学习进行自动剔除。更有价值的是,我们在实践中发现对于模型性能提升ROI更高的是人工修正模型非置信数据,例如三个模型预测结果差异较大的样本,筛出后交给人工确认。这种主动学习的方式,可以避免在大量简单样本上浪费标注人力,针对性地扩充对模型性能提升更有价值的标注数据。
2.1.5 视频主题标签应用——高价值内容筛选聚合

上图展示了点评推荐业务视觉主题标签的应用案例,最具代表性的即为高价值内容的圈选:在点评App首页信息流的达人探店Tab中,运营同学通过标签筛选出有「美食探店」标签的视频进行展示。可以让用户以沉浸式地体验方式更全面地了解到店内的信息,同时也为商家提供了一个很好的窗口,起到宣传引流的作用。
2.1.6 视频标签的不同维度与粒度
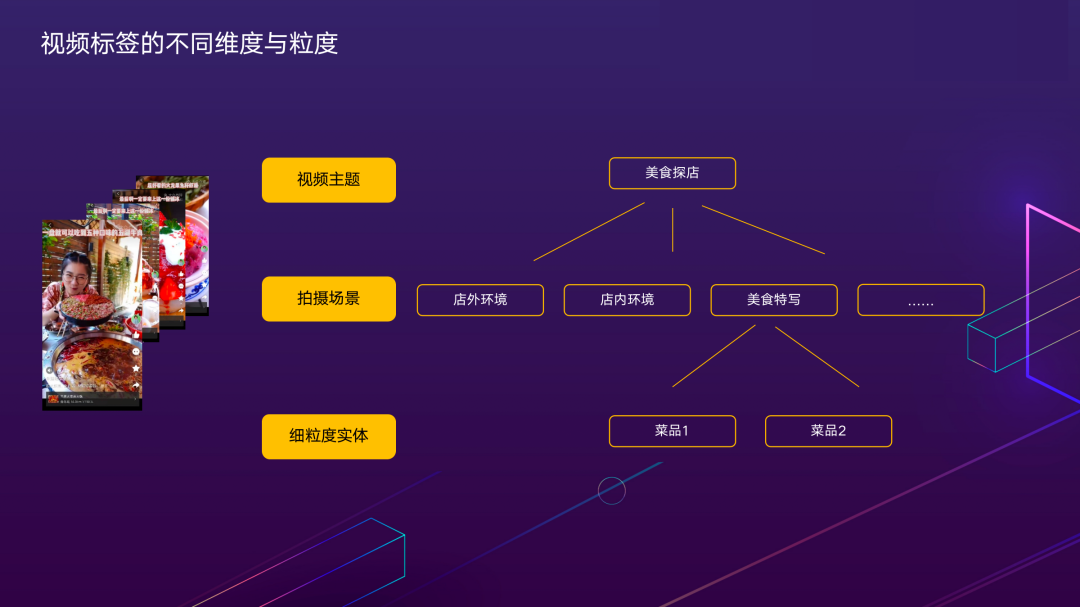
上图展示了,不同维度标签对于技术有不同要求,其中细粒度实体理解,需要识别具体是哪道菜,与上层粗粒度标签的问题不同,需要考虑如何应对技术挑战。首先是细粒度识别任务,需要对视觉特征进行更精细的建模;其次,视频中的菜品理解相较于单张图像中的菜品识别更有挑战,需要应对数据的跨域问题。
2.1.7 菜品图像识别能力向视频领域的迁移
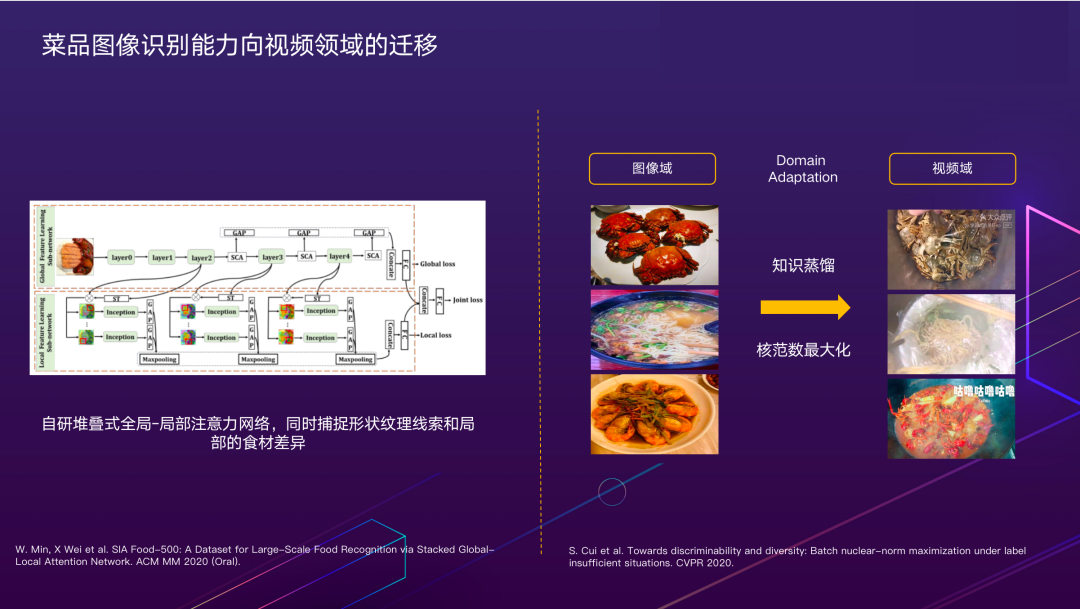
抽象出关键问题后,我们来分别应对。首先在细粒度识别问题上,菜品的视觉相似性度量挑战在于不同食材的特征及位置关系没有标准化的定义,同一道菜不同的师傅很可能做出两种完全不同的样子。这就需要模型既能够聚焦局部细粒度特征,又能够融合全局信息进行判别。为了解决这个问题,我们提出了一种堆叠式全局-局部注意力网络,同时捕捉形状纹理线索和局部的食材差异,对菜品识别效果有显著提升,相关成果发表在ACM MM国际会议上(ISIA Food-500: A Dataset for Large-Scale Food Recognition via Stacked Global-Local Attention Network)。
上图(右)中展示的是第二部分的挑战。图像和视频帧中的相同物体常常有着不同的外观表现,例如:图片中的螃蟹常常是煮熟了摆在盘中,而视频帧中经常出现烹饪过程中鲜活的螃蟹,它们在视觉层面差别很大。我们主要从数据分布的角度去应对这部分跨域差异。
业务场景积累了大量有标注的美食图像,这些样本预测结果的判别性通常较好,但由于数据分布差异,视频帧中的螃蟹则不能被很确信地预测。对此我们希望提升视频帧场景中预测结果的判别性。一方面,利用核范数最大化的方法,获取更好的预测分布。另一方面,利用知识蒸馏的方式,不断通过强大的模型来指导轻量化网络的预测。再结合视频帧数据的半自动标注,即可在视频场景下获得较好的性能。
2.1.8 细粒度菜品图像识别能力

基于以上在美食场景内容理解的积累,我们在ICCV2021上举办了Large-Scale Fine-Grained Food Analysis比赛。菜品图像来自美团的实际业务场景,包含1500类中餐菜品,竞赛数据集持续开放:https://foodai-workshop.meituan.com/foodai2021.html#index,欢迎大家下载使用,共同提升挑战性场景下的识别性能。
2.1.9 菜品细粒度标签应用——按搜出封面
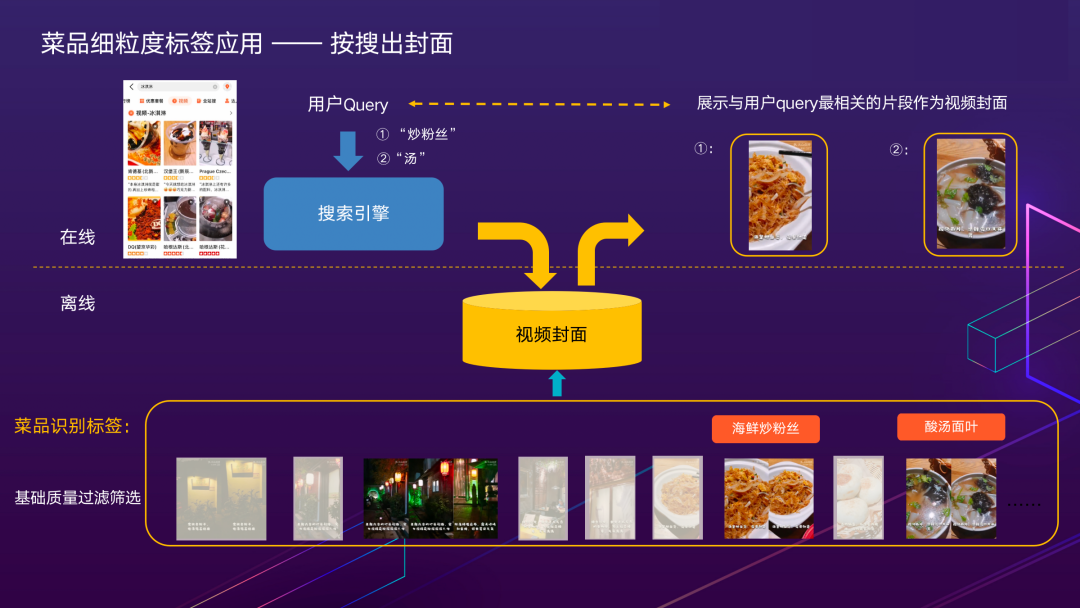
在视频中识别出细粒度的菜品名称有什么应用呢?这里再跟大家分享一个点评搜索业务场景的应用——按搜出封面。实现的效果是根据用户输入的搜索关键词,为同一套视频内容展示不同的封面。图中的离线部分展示了视频片段的切分和优选过程,首先通过关键帧提取,基础质量过滤筛选出适合展示的画面;再通过菜品细粒度标签识别理解到在什么时间点出现什么菜品,作为候选封面素材,存储在数据库中。线上用户对感兴趣内容进行搜索时,根据视频的多个封面候选与用户查询词的相关性,为用户展现最契合的封面,提升搜索的体验。
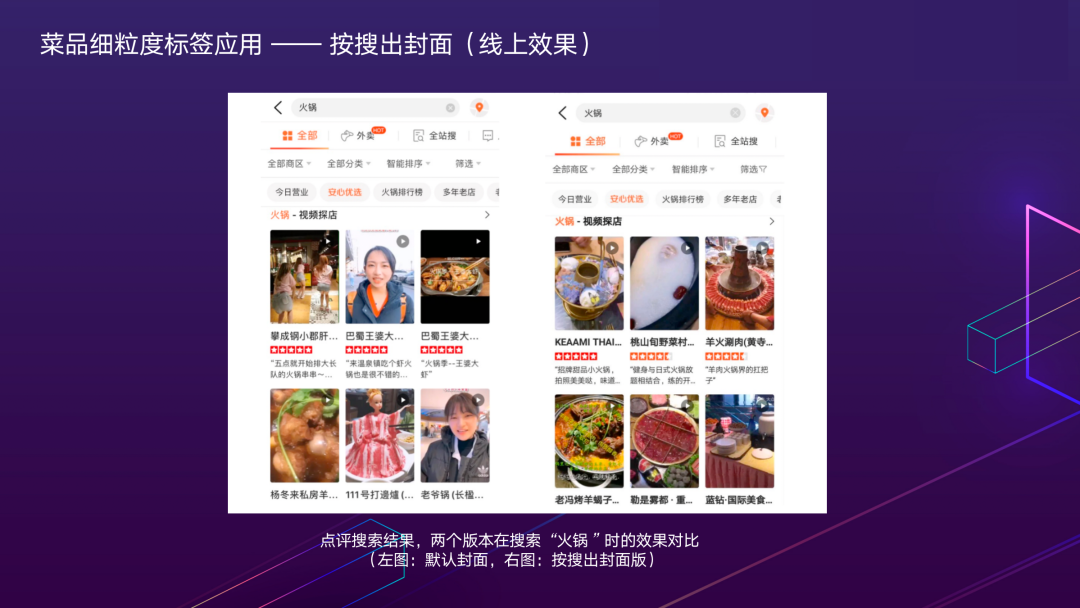
比如,同样是搜索“火锅”,左图是默认封面,右图是“按搜出封面”的结果。可以看到,左边的结果有一些以人物为主体的封面,与用户搜索火锅视频预期看到的内容不符,直观感觉像是不相关的Bad Case。而按搜出封面的展示结果,搜索到的内容都是火锅画面,体验较好。这也是对视频片段理解到细粒度标签,在美团场景下的创新应用。
2.1.10 挖掘更为丰富的视频片段标签
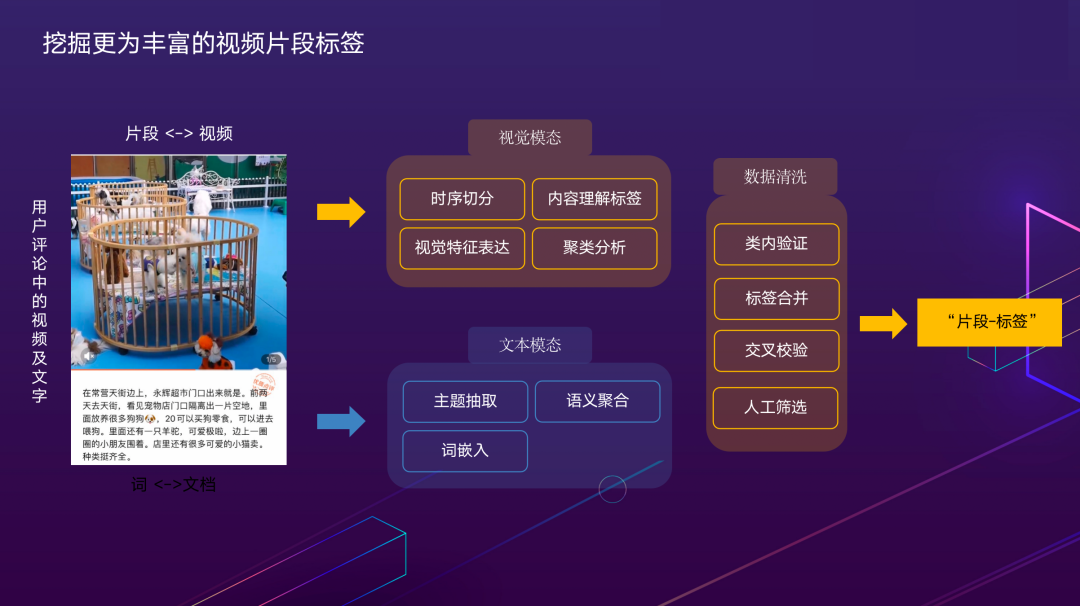
以上都是围绕美食视频展开,但美团还有很多其他的业务场景。如何自动挖掘更为丰富的视频标签,让标签体系本身能够自动扩展,而不是全部依赖人工整理定义,是一个重要的课题。我们基于点评丰富的用户评论数据开展相关工作。上图中的例子是用户的笔记,可以看到内容中既包含视频又包含若干张图片,还有一大段描述,这几个模态具有关联性,存在共性的概念。通过一些统计学习的方式,在视觉和文本两个模态之间做交叉验证,可以挖掘出视频片段和标签的对应关系。
2.1.11 视频片段语义标签挖掘结果示例


例如,通过算法自动挖掘出视频片段和标签,左图展示了标签出现的频率,呈现出明显的长尾分布。但值得注意的是,通过这种方式,算法能够发掘到粒度较细的有意义标签,比如“丝巾画”。通过这种方式可以在尽量减少人工参与的前提下,发现美团场景更多重要的标签。
2.2 短视频内容生成
下面,我们来讲讲如何在内容理解的基础上做内容生产。内容生产是在短视频AI应用场景非常重要的部分,以下分享更多涉及到的是视频素材的解构与理解。
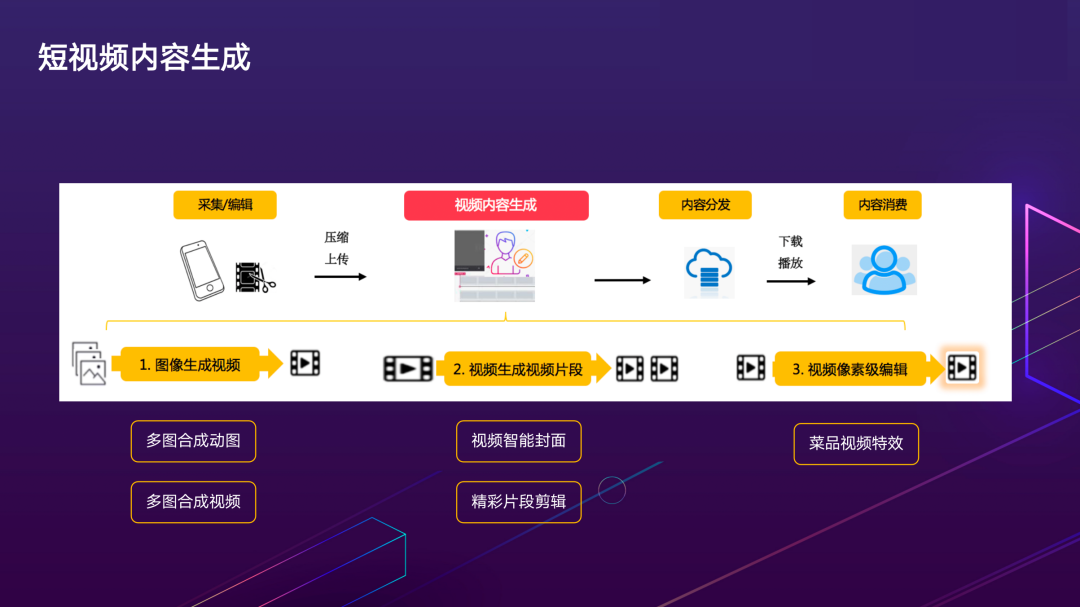
视频内容生产的流程链路(如上图所示),其中内容生成环节主要是原始视频上传到云端后,作为素材,通过算法进行剪辑加工,更好地发挥出内容的潜在价值。比如在广告场景,通过算法识别并剪辑出原始视频中展示商家环境,菜品效果的精华片段,提升信息的密度与质量。另外,视频内容生产根据应用形式可分为三类:
- 图片生成视频,常见的形式有相册速览视频自动生成;
- 视频生成视频片段,典型案例是长视频精彩片段剪辑,变成更精简的短视频做二次分发;
- 视频像素级编辑,主要涉及精细化的画面特效编辑。
下面,我们就三类应用形式展开说明。
2.2.1 图像生成视频——餐饮场景 美食动图生成
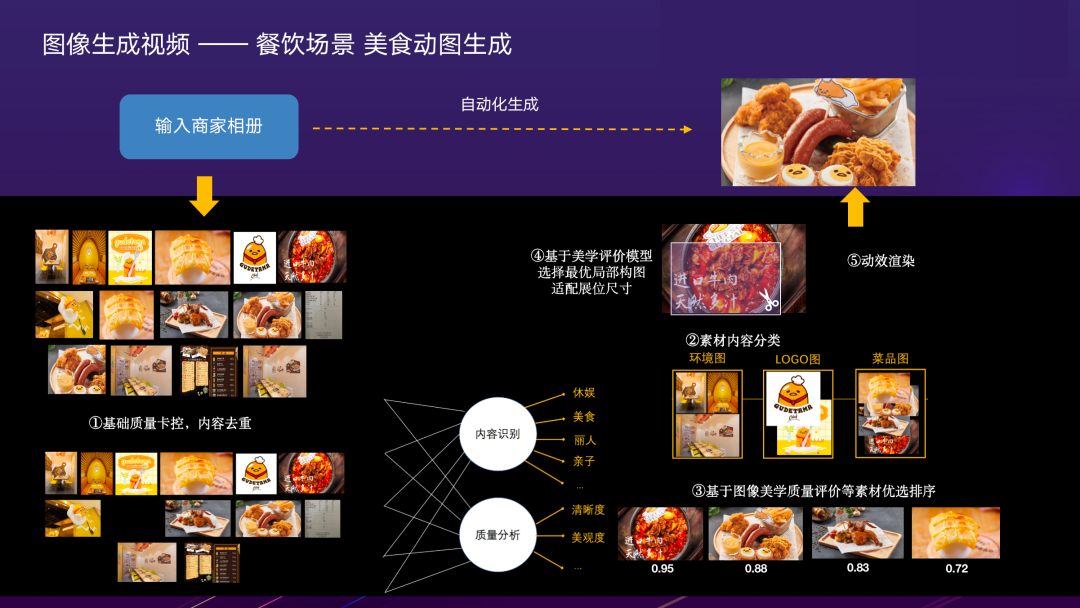
第一类,图像生成视频。该部分要做的更多是针对图像素材的理解和加工,使用户对技术细节无感的前提下,一键端到端生成理想素材。如上图所示,商家只需要输入生产素材的图像相册,一切交给AI算法:首先算法会自动去除拍摄质量较差的,不适合展示的图片;然后做内容识别,质量分析。内容识别包括内容标签,质量分析包括清晰度、美学分;由于原始图像素材的尺寸难以直接适配目标展位,需要根据美学评价模型,对图像进行智能裁切;最终,叠加Ken-Burns、转场等特效,得到渲染结果。商家即可获得一个编排精美的美食视频。
2.2.2 图像生成视频——酒店场景 相册速览视频生成
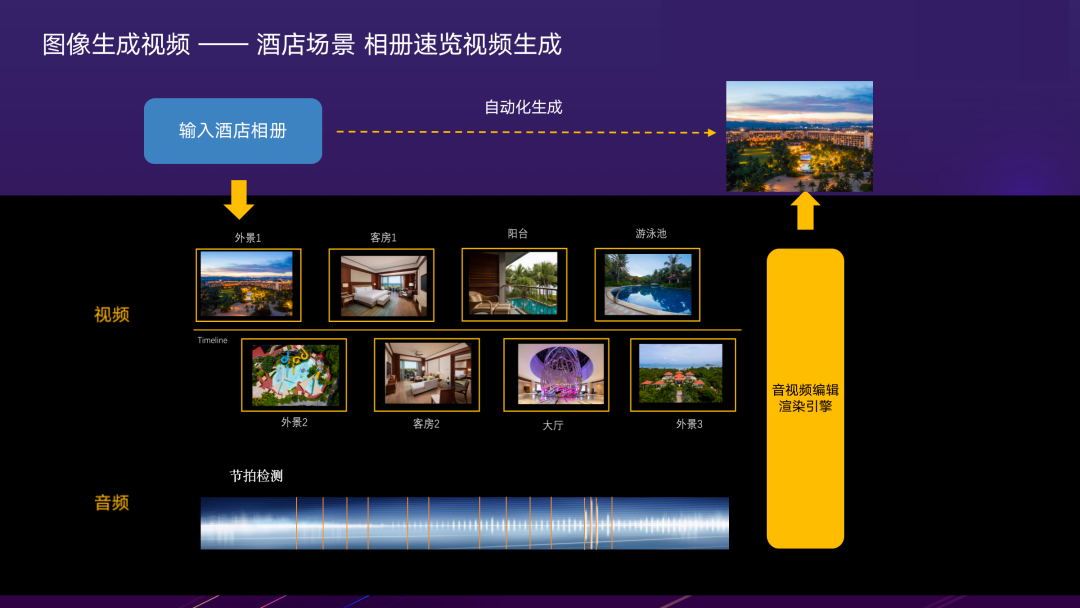
还有酒店场景下相册速览视频生成的例子,相比动图,需要结合音频与转场特效的配合。同时,视频对优先展示什么样的内容有更高要求,需要结合业务场景的特点,根据设计师制定的脚本模板,通过算法自动筛选特定类型的图像填充到模板相应位置。
2.2.3 视频生成视频片段
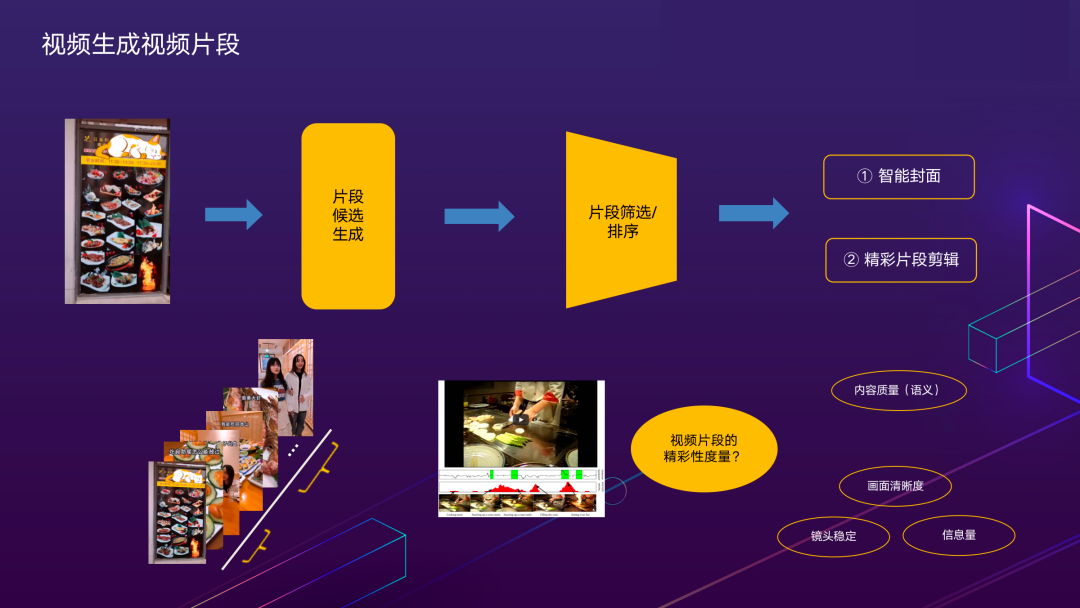
第二类,视频生成视频片段。主要是将长视频切分并优选出若干个更精彩、符合用户预期的内容作展示。从算法阶段划分为片段生成和片段筛选排序。片段生成部分,通过时序切分算法,获取镜头片段及关键帧。片段排序部分,比较关键,它决定了视频优先顺序。这也是比较困难的部分,它有两个维度:
- 通用质量维度,包含清晰度,美学分等;
- 语义维度,例如:在美食视频中,菜品成品展示,制作过程等通常是比较精彩的片段。语义维度的理解主要是采用前面介绍的内容理解模型来支持。
2.2.3.1 智能封面与精彩片段


原始封面


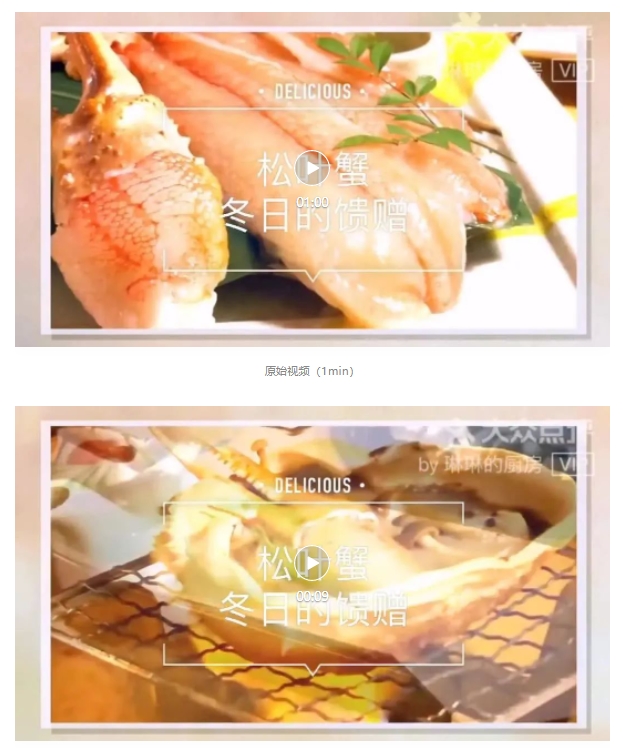
算法剪辑视频(10s)
我们通过视频生成视频片段,实现了两种应用场景。一是智能动态封面,主要基于通用基础质量优选出清晰度更高、有动态信息量、无闪烁卡顿的视频片段作为视频的封面,相比于默认片段的效果更好。
2.2.4 视频像素级编辑处理——菜品视频特效
第三类,视频像素级编辑。比如这里展示了一个基于视频物体分割(VOS,Video Object Segmentation)技术的菜品创意特效,背后的关键技术,是美团自研的高效语义分割方法,该方法已在CVPR 2021发表了论文(Rethinking BiSeNet For Real-time Semantic Segmentation),感兴趣的同学,可以了解一下。
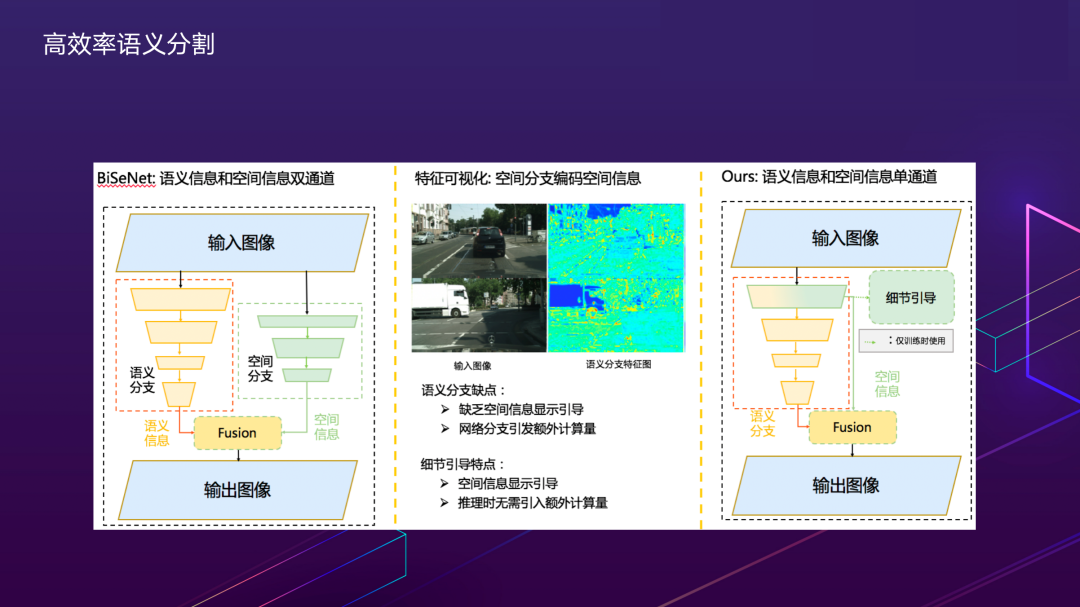
像素级编辑处理最重要的技术之一是语义分割,在应用场景中面临的主要技术挑战是既要保证分割模型时效性,也要保证分辨率,保持高频细节信息。我们对于经典的BiSeNet方法做出了进一步改进,提出了基于细节引导的高效语义分割方法。
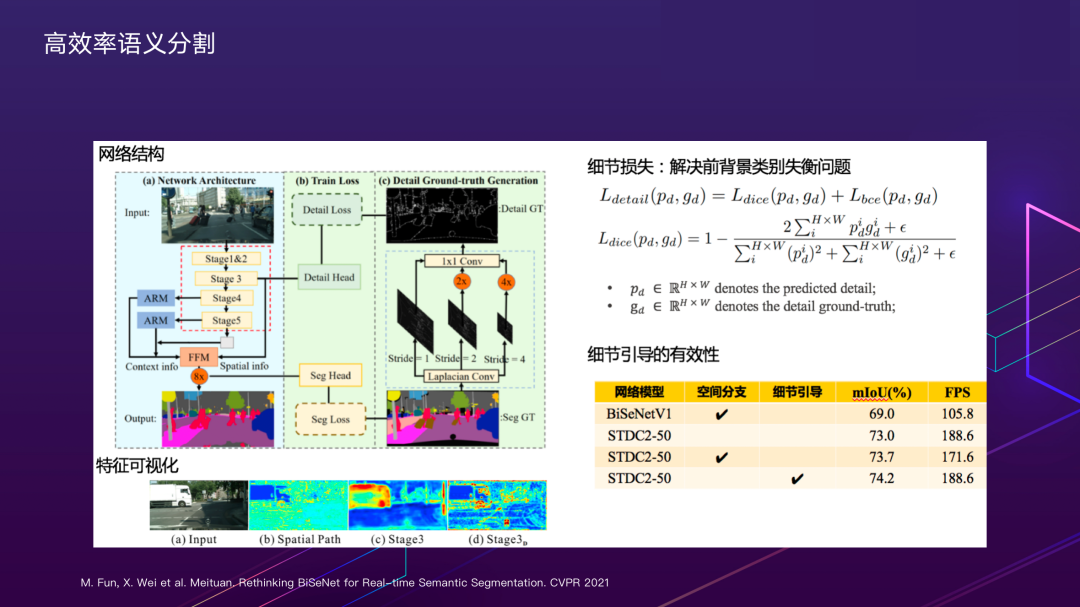
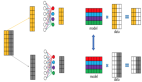
具体的做法如网络结构所示,左边浅蓝色部分是网络的推理框架,沿用了BiSeNet Context分支的设计,Context分支的主干选用了我们自研的主干STDCNet。与BiSeNet不同的是,我们对Stage3进行一个细节引导的训练,如右边的浅绿色部分所示,引导Stage3学习细节特征;浅绿色部分只参与训练,不参与模型推理,因此不会造成额外的时间消耗。
首先对于分割的Ground Truth,我们通过不同步长的Laplacian卷积,获取一个富集图像边缘和角点信息的细节真值;之后通过细节真值和设计的细节Loss来引导Stage3的浅层特征学习细节特征。由于图像的细节真值前后背景分布严重不均衡,因此我们采用的是DICE loss和BCE loss联合训练的方式;为了验证细节引导的有效性,我们做了这个实验,从特征可视化的结果中可以看出多尺度获取的细节真值对网络进行细节引导能获得最好的结果,细节信息引导对模型的性能也有所提升。
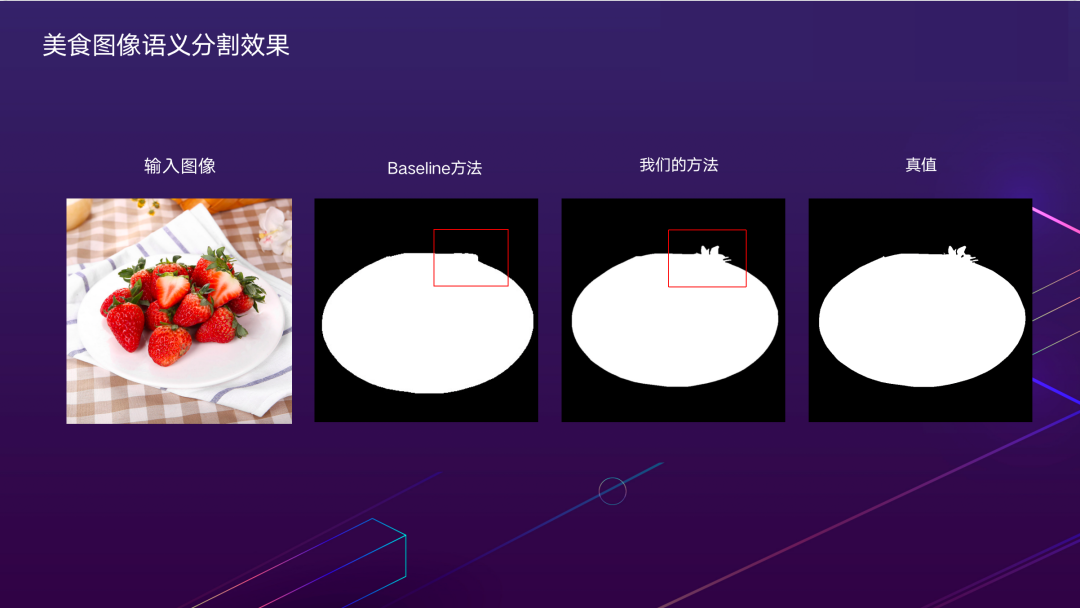
效果方面,通过对比可以看出我们的方法对于分割细节的高频信息保持具有较大的优势。
3. 总结展望

以上分享了美团在视频标签、视频封面与剪辑、视频细粒度像素级编辑技术领域,通过与业务场景的结合期望为商家和用户提供更加智能的信息展示和获取方式。未来,短视频技术应用方面,在美团丰富的业务场景包括本地生活服务、零售电商,都会发挥更大的潜在价值。视频理解技术方面,多模态自监督训练,对于缓解标注数据依赖,提升模型在复杂业务场景的泛化性能方面非常有价值,我们也在做一些尝试和探索。
4. 本文作者
马彬,美团视觉智能部工程师。