使用Photoshop类的软件算是创造性工作还是重复性工作?
对于用PS的人来说,重复性工作如抠图可能是一大噩梦,尤其是头发丝、不规则的图形、与背景颜色贴近的,更是难上加难。

如果有AI模型能帮你抠图,还能帮你做一些如替换纹理、添加素材等工作,那岂不是能节省大把时间用来创作?
一些专注于视觉效果(VFX)的从业者对图像和视频合成方面的新工作和创新很感兴趣,但他们同时也会感觉到威胁,担心AI的快速发展是否会替代他们,毕竟现在AI从绘画到生成视频,简直无所不能。
比如让一个新手生成一个伪造视频需要大量的学习和操作时间,如果使用deepfake的话则不需要什么门槛,而且效率也高得多。
不过好消息是,AI目前并非全知全能,一个模型只能做软件内的一点点工作;如果要把多个模型组装成一个Pipeline,那还得需要人来操作才行;对于更复杂的任务,那还需要人类的创造力。
魏茨曼科学研究学院和英伟达的研究人员就提出了一个模型Text2Live,用户只需要输入自然语言文本作为命令,就能对给定的图片和视频进行处理。模型的目标是编辑现有物体的外观(如物体的纹理)或以语义的方式增加场景的视觉效果(如烟、火等)。

论文链接:https://arxiv.org/pdf/2204.02491.pdf
Text2Live能够用复杂的半透明效果增强输入场景,而不改变图像中的无关内容。
比如对模型念出咒语「烟」或者「火」,就可以给图片合成上相应的效果,十分真实;

对着面包图片说「冰」,就可以变成一个冰面包,甚至「奥利奥蛋糕」也不在话下;

或是对着视频说「给长颈鹿戴个围脖」,它也能精确识别出来长颈鹿的脖子,并在每一帧都给它戴上一个围脖,还能换各种不同的效果。

用自然语言P图
受视觉语言模型(Vision-Language models)强大的语义表达能力启发,研究人员想到,为什么我们不能用自然语言命令来P图呢?这样用户就可以轻松而直观地指定目标外观和要编辑的对象和区域,而开发出的模型需要具备识别出给定文本提示的局部、语义编辑的能力。
多模态的话,在4亿个文本-图像对上学习过的CLIP模型就是现成的,并且其内包含巨大的视觉和文本空间丰富性已经被各种图像编辑方法所证明了!

但还有一个困难,就是在所有真实世界的图像中想用CLIP达到完美性能还是不容易的。
大多数现有方法都是将预训练好的生成器(例如GAN或Diffusion模型)与CLIP结合起来。但用GANs的话,图像的域是受限制的,需要将输入图像反转到GAN的潜空间,本身就是一个具有挑战性的任务。而扩散模型虽然克服了这些障碍,但在满足目标编辑和保持对原始内容的高保真度之间面临着权衡。但将这些方法扩展到视频中也并不简单。
Text2LIVE采取了一条不同的路线,提出从单一的输入(图像或视频和文本提示)中学习一个生成器。

新问题来了:如果不使用外部生成式的先验,该如何引导生成器走向有意义的、高质量的图像编辑操作?
Text2LIVE主要设计了两个关键部分来实现这一目标:
1. 模型中包含一种新颖的文字引导的分层编辑(layered editing),也就是说,模型不是直接生成编辑过的图像,而是通过在输入的图层上合成RGBA层(颜色和不透明度)来表示编辑。
这也使得模型可以通过一个新的目标函数来指导生成的编辑内容和定位,包括直接应用于编辑层的文本驱动的损失。
比如前面的例子中使用文本提示「烟」,不仅输出最终的编辑图像,还表达了编辑层所代表的目标效果。
2. 模型通过对输入的图像和文本进行各种数据增强,在一个由不同的图像-文本训练实例组成的「内部数据集」上训练生成器。实验结果也表明,这种「内部学习方法」可以作为一个强大的regularization,能够高质量地生成复杂的纹理和半透明的效果。
文本增强主要使用预定义的14个模板提示符,能够提供CLIP向量的多样性。

图像数据的Pipeline由一个在单一输入图像上训练的生成器和目标文本提示组成。

左侧就是生成内部数据集的过程,即由不同训练实例组成的内部(图像,文本)对和数据增强后得到的数据集。
右测是生成器将图像作为输入,并输出一个RGBA的可编辑层(颜色+透明度),在输入的基础上进行合成,从而形成最终的编辑过的图像。
生成器的的优化函数为多个损失项之和,每个损失项都是在CLIP空间中定义,包括主要的目标Composition loss,能够反映图像和目标文本提示之间的匹配程度;Screen loss,应用于生成的编辑层中,主要技术是在纯绿色背景上合成一个噪音背景图像,判断抠图准确度;Structure loss,保证替换的纹理和显示效果能够保持原始目标的空间分布和形状。

除了图像外,研究人员还将Text2LIVE扩展到了文本指导的视频编辑领域。
现实世界的视频通常由复杂的物体和摄像机运动组成,包括了关于场景的丰富信息。然而,想实现一致的视频编辑是很困难的,不能只是简单地对图片的每一帧都使用相同操作。
因此,研究人员提出将视频分解为一组二维图集(atlases)。每个图集可以被视为一个统一的二维图像,代表了整个视频中的一个前景物体或背景。这种表示方法大大简化了视频编辑的任务。应用于单个二维图集的编辑会以一种一致的方式映射到整个视频中。
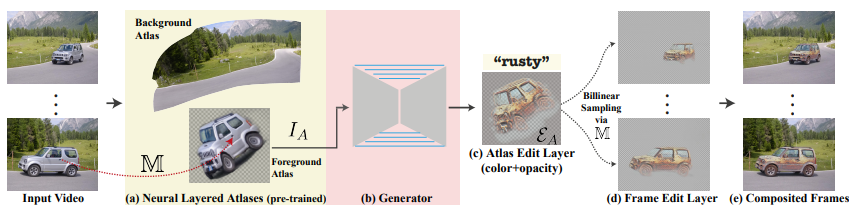
视频的训练Pipeline包括(a)一个预训练的固定分层神经图集模型,可以用作「视频渲染器」,包括了一组二维图集、从像素到图集的映射函数,以及每个像素的前景/背景透明值;(b)框架训练一个生成器,将选定的离散图集IA作为输入,并输出;(c)一个图集编辑层EA;(d)使用预训练映射网络M把编辑过的图集渲染回每一帧;(e)在原始视频上进行合成。
在实验的量化评估中,研究人员选择人类感知评估的方式,参与者会看到一个参考图像和一个目标编辑提示,以及两个备选方案。
参与者必须选择「哪张图片能更好地根据文本提示来编辑参考图像」?
实验数据包括了82个(图像,文本)对,收集了12450个用户对图像编辑方法的判断,投票结果可以看到Text2LIVE在很大程度上超过了所有的基线模型。

在视频的实验中,参与者需要选择「质量更好、更能体现文本的视频」,实验数据包含19个(视频,文本)对和2400个用户的判断结果。结果可以看到,Frames基线模型产生了时间线不一致的结果,而Atlas基线的结果更一致,但在生成高质量纹理方面表现不佳,经常产生模糊的结果。