













自从计算机诞生之初,人类就梦想着能够创造出会思考的机器。1956 年在达特茅斯学院组织的一个研讨会上,约翰 · 麦卡锡提出人工智能这个概念,一群数学家和科学家聚集在一起寻找如何让机器使用语言、形成抽象理解和概念、以解决现存的各种问题,当时研讨会参与者乐观地认为,在几个月的时间里这些问题能取得真正的进展。
人工智能是由约翰麦卡锡于 1956 年在达特茅斯学院组织的一个研讨会上创立的,一群数学家和科学家聚集在一起寻找如何让机器使用语言、形成抽象和概念、解决现在保留的各种问题,当时研讨会参与者乐观地认为,几个月的集中努力将在这些问题上取得真正的进展。

1956 年达特茅斯人工智能会议的参与者:马文 · 明斯基、克劳德 · 香农 、雷 · 所罗门诺夫和其他科学家。摄自:Margaret Minsky
事实证明,预留几个月的时间安排过于乐观。在接下来的 50 年里,创建人工智能系统的各种方法开始流行,但后来又遭遇过时,包括基于逻辑的系统、基于规则的专家系统和神经网络。
直到 2011 年左右,人工智能才开始进入发展关键阶段,取得了巨大的进步,这得益于深度学习中神经网络的复兴,这些技术的进步有助于提高计算机看、听和理解周围世界的能力,使得人工智能在科学以及人类探索的其他领域取得巨大进步。这其中有哪些原因呢?
近日,谷歌大牛 Jeff Dean 发表了一篇文章《 A Golden Decade of Deep Learning: Computing Systems & Applications 》,文章探索了深度学习在这黄金十年里,计算系统以及应用进步的原因都有哪些?本文重点关注三个方面:促成这一进步的计算硬件和软件系统;过去十年在机器学习领域一些令人兴奋的应用示例;如何创建更强大的机器学习系统,以真正实现创建智能机器的目标。
Jeff Dean 的这篇文章发表在了美国文理学会会刊 Dædalus 的 AI 与社会(AI & Society)特刊上。

文章地址:https://www.amacad.org/sites/default/files/publication/downloads/Daedalus_Sp22_04_Dean.pdf
深度学习的黄金十年
人工智能硬件和软件的进步
人工智能的硬件和软件:深度学习通过组合不同的线性代数(例如矩阵乘法、向量点积以及类似操作)进行运算,但这种运算方式会受到限制,因此我们可以构建专用计算机或加速器芯片来进行处理,相比于通用 CPU,这种专业化的加速器芯片能带来新的计算效率和设计选择。
专为支持此类计算而定制的计算机或加速器芯片。相对于必须运行更广泛种类的算法的通用 CPU,这种专业化实现了新的效率和设计选择。
早在 2000 年代初期,就有少数研究者开始探索使用 GPU 来实现深度学习算法。之后到了 2004 年,计算机科学家 Kyoung-Su Oh 和 Keechul Jung 展示了使用 GPU 对神经网络算法近 20 倍的速度提 sheng。2008 年,计算机科学家 Rajat Raina 及其同事演示了在某些非监督学习算法中,使用 GPU 与使用基于 CPU 的最佳实现相比,GPU 速度提升可达 72.6 倍。
随着计算硬件的改进,深度学习开始在图像识别、语音识别、语言理解等方面取得显著进步。深度学习算法有两个非常好的特性可以构建专门的硬件:首先,它们对精度的降低非常宽容;其次,深度学习的计算方式,其由密集矩阵或向量上的不同线性代数运算序列组成。
为了使深度学习和计算变得更容易,研究人员开发了开源软件框架,如今,开源框架帮助大量的研究人员、工程师等推进深度学习研究,并将深度学习应用到更广泛的领域。
早期的一些框架包括 Torch、Theano、DistBelief 、Caffe 等,还有谷歌在 2015 年开发、开源的 TensorFlow,它是一个允许表达机器学习计算的框架,并结合了 Theano 和 DistBelief 等早期框架的想法。到目前为止,TensorFlow 已被下载超过 5000 万次,是世界上最受欢迎的开源软件包之一。
TensorFlow 发布的一年后,PyTorch 于 2016 年发布,它使用 Python 可以轻松表达各种研究思想而受到研究人员的欢迎。JAX 于 2018 年发布,这是一个流行的面向 Python 的开源库,结合了复杂的自动微分和底层 XLA 编译器,TensorFlow 也使用它来有效地将机器学习计算映射到各种不同类型的硬件上。
TensorFlow 和 PyTorch 等开源机器学习库和工具的重要性怎么强调都不为过,它们允许研究人员可以快速尝试想法。随着世界各地的研究人员和工程师更轻松地在彼此的工作基础上进行构建,整个领域的进展速度将加快!
研究成果激增
研究不断取得进步、面向 ML 硬件(GPU、TPU 等)的计算能力不断增强、开源机器学习工具(TensorFlow、PyTorch 等)被广泛采用,这一系列进展使得机器学习及其应用领域的研究成果急剧增加。其中一个强有力的指标是发布到 arXiv 上关于机器学习领域的论文数量,arXiv 是一个广受欢迎的论文预印本托管服务,2018 年发布的论文预印本数量是 2009 年的 32 倍以上(每两年增长一倍以上)。通过与气候科学和医疗保健等关键领域的专家合作,机器学习研究人员正在帮助解决对社会有益、促进人类进步的重要问题。可以说我们生活在一个激动人心的时代。
科学和工程应用激增
计算能力的变革性增长、机器学习软硬件的进步以及机器学习研究成果的激增,都使得机器学习应用在科学和工程领域的激增。通过与气候科学和医疗健康等关键领域的合作,机器学习研究人员正在帮助解决对社会有益并促进人类发展的重要问题。这些科学和工程领域包括如下:
- 神经科学
- 分子生物学
- 医疗健康
- 天气、环境和气候挑战
- 机器人
- 可访问性
- 个性化学习
- 计算机辅助的创造性
- 重要的构建块
- Transformers
- 计算机系统的 ML
每个细分的详细内容请参考原文。
机器学习的未来
ML 研究社区正在出现一些有趣的研究方向,如果将它们结合起来可能会更加有趣。
首先,研究稀疏激活模型,比如稀疏门控专家混合模型(Sparsely-Gated MoE),展示了如何构建非常大容量的模型,其中对于任何给定的实例(如 2048 个专家中的两至三个),只有一部分模型被「激活」。
其次,研究自动化机器学习(AutoML),其中神经架构搜索(NAS)或进化架构搜索(EAS)等技术可以自动学习 ML 模型或组件的高效结构或其他方面以对给定任务的准确率进行优化。AutoML 通常涉及运行很多自动化实验,每个实验都可能包含巨量计算。
最后,以几个到几十个相关任务的适当规模进行多任务训练,或者从针对相关任务的大量数据训练的模型中迁移学习然后针对新任务在少量数据上进行微调,这些方式已被证明在解决各类问题时都非常有效。
一个非常有趣的研究方向是把以上三个趋势结合起来,其中在大规模 ML 加速器硬件上运行一个系统。目标是训练一个可以执行数千乃至数百个任务的单一模型。这种模型可能由很多不同结构的组件组成,实例(example)之间的数据流在逐实例的基础上是相对动态的。模型可能会使用稀疏门控专家混合和学习路由等技术以生成一个非常大容量的模型,但其中一个任务或实例仅稀疏激活系统中总组件的一小部分。
下图 1 描述了一个多任务、稀疏激活的机器学习模型。
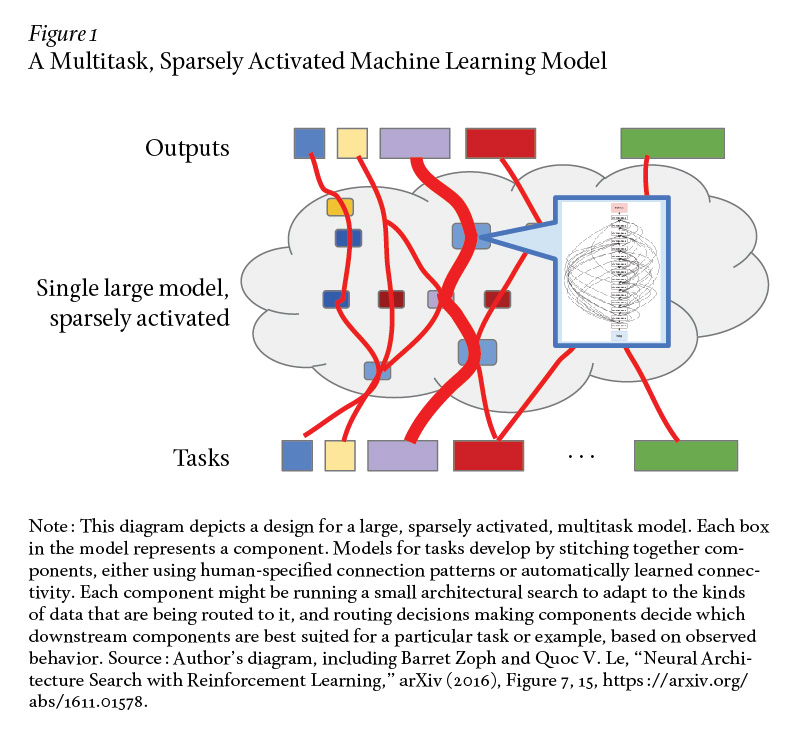
每个组件本身可能正在运行一些类 AutoML 的架构搜索,以使组件的结构适应路由到它的数据类型。新的任务可以利用在其他任务上训练的组件,只要它有用就行。Jeff Dean 希望通过非常大规模的多任务学习、共享组件和学习路由,模型可以迅速地以高准确率来完成新任务,即使每个新任务的新实例相对较少。原因在于模型能够利用它在完成其他相关任务时已经获得的专业知识和内部表示。
构建一个能够处理数百万任务并学习自动完成新任务的单一机器学习是人工智能和计算机系统工程领域真正面临的巨大挑战。这需要机器学习算法、负责任的 AI(如公平性和可解释性)、分布式系统和计算机架构等很多领域的专业知识,从而通过构建一个能够泛化以在机器学习所有应用领域中独立解决新任务的系统,来推动人工智能领域的发展。
负责任的 AI 开发
虽然 AI 有能力在人们日常生活的方方面面提供帮助,但所有研究人员和从业人员应确保以负责任的方式开发相关方法,仔细审查偏见、公平性、隐私问题以及其他关于 AI 工具如何运作并影响他人的社会因素,并努力以适当的方式解决所有这些问题。
制定一套明确的原则来指导负责任的 AI 发展也很重要。2018 年,谷歌发布了一套 AI 准则,用于指导企业与 AI 相关的工作和使用。这套 AI 准则列出了需要考虑的重要领域,包括机器学习系统中的偏见、安全、公平、问责、透明性和隐私。近年来,其他机构和政府也纷纷效仿这一模式,发布了自己的 AI 使用准则。Jeff Dean 希望这种趋势能够延续下去,直到它不再是一种趋势,而成为所有机器学习研究和开发中遵循的标准。
Jeff Dean 对未来的展望
2010 年代的确是深度学习研究和取得进展的黄金十年。1956 年达特茅斯人工智能研讨会上提出的一些最困难的问题在这十年取得了长足进步。机器能够以早期研究人员希望的方式看到、听到和理解语言。核心领域的成功促使很多科学领域迎来重大进展,不仅智能手机更加智能,而且随着人们继续创建更复杂、更强大且对日常生活有帮助的深度学习模型,未来有了更多的可能性。得益于强大机器学习系统提供的帮助,人们将在未来变得更有创造力和拥有更强的能力。


















