随着社交媒体、物联网和多媒体应用等各种来源产生的海量数据的诞生,大数据已经成为一个重要的研究领域。大数据在许多决策和预测领域发挥了关键作用,如推荐系统、商业分析、医疗保健、网络展示广告、临床医生、交通、欺诈检测和旅游营销。Hadoop、Storm、Spark、Flink、Kafka和Pig等各种大数据工具的研究和工业界的快速发展,使得大规模数据得以分发、交流和处理[1]。大数据应用程序使用大数据分析技术来高效地分析大数据。
然而,由于大数据在处理和应用方面的挑战,开发人员选择合适的大数据工具来开发大数据系统非常困难。因此,本文提出了一个分类方案,根据不同的数据处理方式对大数据工具进行分类。
大数据工具的分类
大数据计算主要有三种工具,即批处理工具、流处理工具和混合处理工具。大多数批处理数据分析框架都基于Apache Hadoop。流式数据分析框架主要是实时应用中使用的Storm、S4和Flink。混合处理工具利用批处理和流处理的优点来计算大量数据。
批处理工具
批处理建模并将数据湖的文件转换为批处理视图,为分析用例做好准备。它负责安排和执行批量迭代算法,如排序、搜索、索引或更复杂的算法,如PageRank、贝叶斯分类或遗传算法。批处理主要由MapReduce编程模型表示。
Apache Hadoop是一个众所周知的批处理框架,它支持在集群上分布式存储和处理大型数据。它是一个基于Java的开源框架,被Facebook、Yahoo和Twitter用于存储和处理大数据。Hadoop主要由两个组件组成:(1)Hadoop分布式文件系统(HDFS),其中集群节点之间的数据存储是分布式的;(2)Hadoop MapReduce引擎,它将数据处理分配给集群的节点[2]。
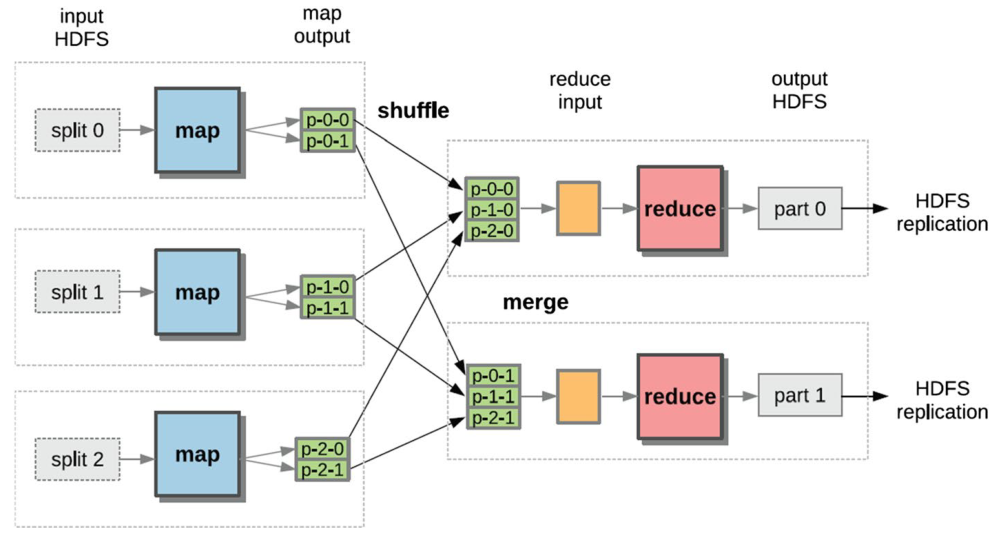
图 1 Hadoop的MapReduce
Apache Pig是Hadoop生态系统的一个不可或缺的组件,它通过在Hadoop上并行执行数据流来减少数据分析时间。Pig是一种结构化查询语言(SQL),被LinkedIn、Twitter、Yahoo等大型组织使用。该平台的脚本语言称为Pig Latin,它将MapReduce中的编程复杂性从其他语言(如Java)抽象为高级语言。Pig是一个最完整的平台,因为它可以通过直接调用用户定义函数(UDF)来调用JavaScript、Java、Jython和JRuby等多种语言的代码。因此,开发人员可以使用Pig在Hadoop中完成所有必需的数据操作。Pig可以作为一个具有相当多并行性的组件,用于构建复杂而繁重的应用程序。
Flume被用作向Hadoop提供数据的工具。与处理框架一起,需要一个消息传递层来访问和转发流数据。Apache Flume是提供这一功能的较为成熟的选项之一。Flume一直是数据馈送的著名应用程序。它很好地嵌入到整个Hadoop生态系统中,并获得了所有商业Hadoop发行版的支持。这使得Flume成为开发者的主要选择[3]。
流处理工具
Hadoop是为批处理而设计的。Hadoop是一个多用途引擎,但由于其延迟,它不是一个实时和高性能的引擎。在一些流数据应用中,如日志文件处理、工业传感器和远程通信,需要实时响应和处理流式大数据。因此,有必要对流处理进行实时分析。流式大数据需要实时分析,因为大数据具有高速、大容量和复杂的数据类型,对于Map/Reduce框架将是一个挑战。因此,Storm、S4、Splunk和Apache Kafka等流处理的实时大数据平台已被开发为第二代数据流处理平台用于实时分析数据,实时处理意味着连续数据处理需要极低的响应延迟[4]。
Storm是实时分析中最受认可的数据流处理程序之一,专注于可靠的消息处理。Storm是一个免费、开源的分布式流媒体处理环境,用于开发和运行分布式程序,处理源源不断的数据流。因此,可以说Storm是一个开源、通用、分布式、可扩展和部分容错的平台,可以可靠地处理无限的数据流以进行实时处理。Storm的一个优点是,开发人员可以专注于使用稳定的分布式进程,同时将分布式/并行处理的复杂性和技术挑战(如构建复杂的恢复机制)委托给框架。Storm是一个复杂的事件处理器和分布式计算框架,基本上是用Clojure编程语言编写的。它是一个分布式实时计算系统,用于快速处理大数据流。Storm是一个分布式/并行框架,由Nimbus、Supervisor和Zookeeper组成,如图2所示。Storm集群主要由主节点和工作节点组成,由Zookeeper进行协调。
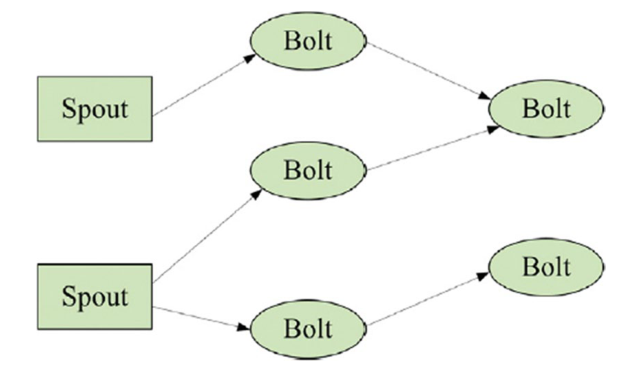
图2 Storm拓扑的示例
S4是一个受MapReduce模型启发的分布式流处理平台。流的操作由用户代码和用XML描述的配置作业指定。S4是一个通用的、容错的、可扩展的、分布式的、可插拔的计算框架,程序员可以轻松地开发用于处理连续无界数据流的应用程序。它最初由Yahoo 2010年发布,并从2011年起成为Apache孵化器项目。S4允许程序员基于几个有竞争力的特性开发应用程序,包括可伸缩性、分散性、健壮性、可扩展性和集群管理。S4是用Java编写的。S4作业的任务是模块化和可插拔,以便于动态处理大规模流数据。S4使用Apache ZooKeeper来管理集群,就像Storm一样。
Kafka是一个开源的分布式流媒体框架,最初由LinkedIn在2010年开发。它是一个灵活的发布-订阅消息传递系统,旨在快速、可扩展,并通常用于日志收集。Kafka是用Scala和Java编写的。它有一个多生产者管理系统,能够从多个来源获取消息。通常,Kafka的数据分区和保留功能使其成为容错事务收集的有用工具。这是因为应用程序可以开发和订阅记录流,具有容错保证,并且可以在记录流出现时对其进行处理。
Flink是一个流式处理工具,旨在解决微批量模型衍生的问题。Flink还支持使用Scala和Java中的编程抽象进行批处理数据处理,尽管它被视为流处理的特例。在Flink中,每个作业都作为流计算执行,每个任务都作为循环数据流执行,并进行多次迭代。Flink还提供了一种复杂的容错机制,以一致地恢复数据流应用程序的状态。该机制生成分布式数据流和操作员状态的一致快照。如果出现故障,系统可以退回到这些快照。FlinkML的目标是为Flink用户提供一套可伸缩的机器学习算法和直观的API。
Apache Spark是Hadoop最新的替代方案。它包括一个名为MLlib的额外组件,这是一个面向机器学习算法的库,例如:聚类、分类、回归,甚至数据预处理[6]。由于Spark的容量,批量和流式分析可以在同一平台上完成。Spark的开发是为了克服Hadoop的缺点,即它没有针对迭代算法和交互式数据分析进行优化,后者对同一组数据执行多个操作。Spark被定义为下一代分布式计算框架的核心,由于其内存密集型方案,它可以在内存中快速处理大容量数据集。
混合处理工具
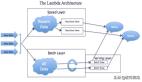
混合处理使大数据平台进入第三代成为可能,因为它是大数据应用中许多领域所必需的。该范例综合了基于Lambda架构的批处理和流处理范例。Lambda体系结构是一种数据处理体系结构,旨在通过利用批处理和流处理方法来处理大量数据。这个范例的高级架构包含三层。批处理层管理已存储在分布式系统中且不可更改的主数据集,服务层加载并在数据存储中公开批处理层的视图以供查询,而速度层只处理低延迟的新数据。最后,通过批处理和实时视图的组合,将完整的结果合并[7]。
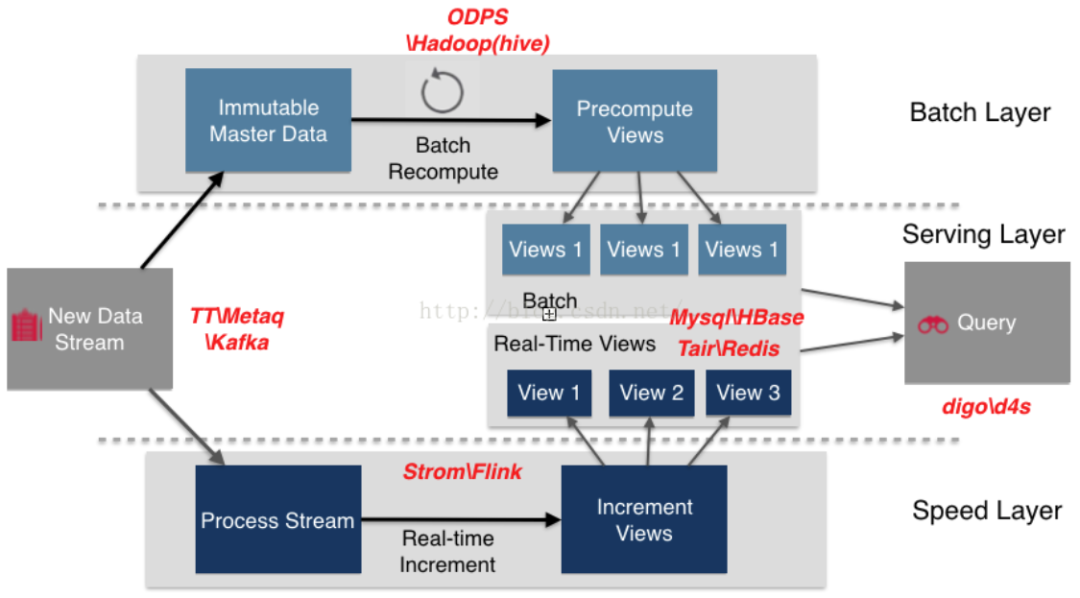
图3 Lambda架构
引 用
[1] Mohamed A, Najafabadi M K, Wah Y B, et al. The state of the art and taxonomy of big data analytics: view from new big data framework[J]. Artificial Intelligence Review, 2020, 53(2): 989-1037.
[2] Singh H, Bawa S. A MapReduce-based scalable discovery and indexing of structured big data[J]. Future generation computer systems, 2017, 73: 32-43.
[3] Bharti S K, Vachha B, Pradhan R K, et al. Sarcastic sentiment detection in tweets streamed in real time: a big data approach[J]. Digital Communications and Networks, 2016, 2(3): 108-121.
[4] Manco G, Ritacco E, Rullo P, et al. Fault detection and explanation through big data analysis on sensor streams[J]. Expert Systems with Applications, 2017, 87: 141-156.
[5] Tennant M, Stahl F, Rana O, et al. Scalable real-time classification of data streams with concept drift[J]. Future Generation Computer Systems, 2017, 75: 187-199.
[6] Ai W, Li K, Li K. An effective hot topic detection method for microblog on spark[J]. Applied Soft Computing, 2018, 70: 1010-1023.
[7] Hasani Z, Kon-Popovska M, Velinov G. Lambda architecture for real time big data analytic[J]. ICT Innovations, 2014: 133-143.